 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Field Guide to Federated Optimization
Jul 14, 2021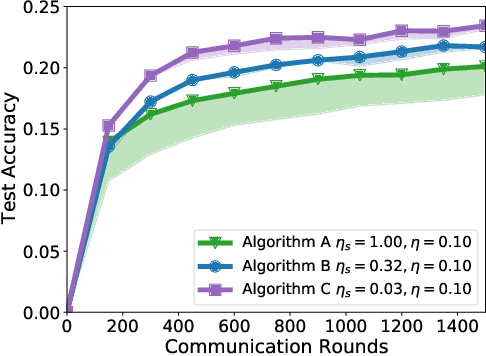


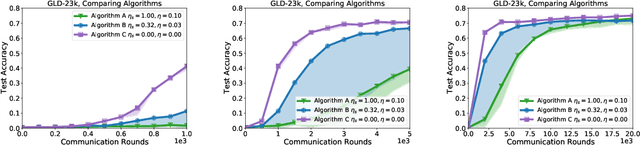
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
IFedAvg: Interpretable Data-Interoperability for Federated Learning
Jul 14, 2021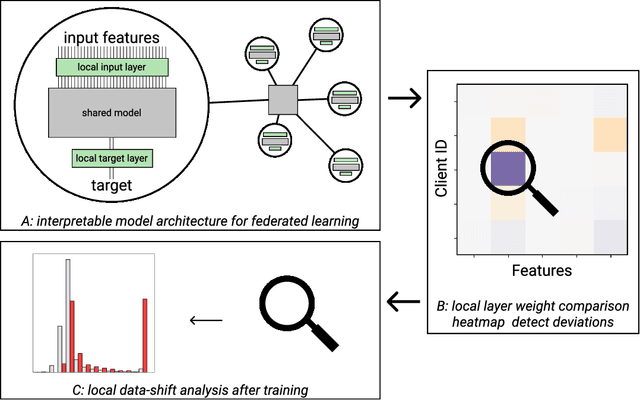
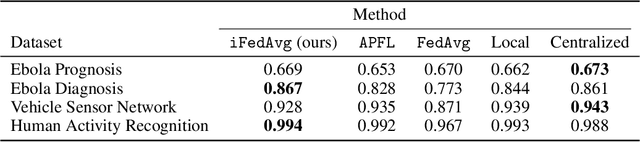
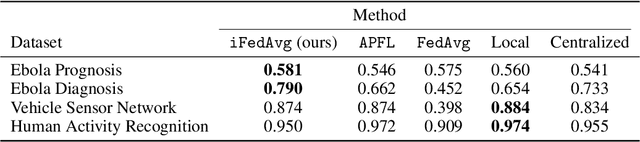
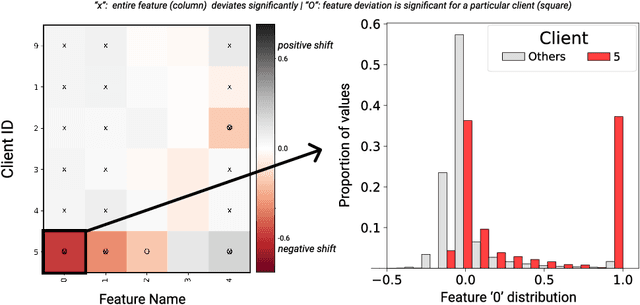
Recently, the ever-growing demand for privacy-oriented machine learning has motivated researchers to develop federated and decentralized learning techniques, allowing individual clients to train models collaboratively without disclosing their private datasets. However, widespread adoption has been limited in domains relying on high levels of user trust, where assessment of data compatibility is essential. In this work, we define and address low interoperability induced by underlying client data inconsistencies in federated learning for tabular data. The proposed method, iFedAvg, builds on federated averaging adding local element-wise affine layers to allow for a personalized and granular understanding of the collaborative learning process. Thus, enabling the detection of outlier datasets in the federation and also learning the compensation for local data distribution shifts without sharing any original data. We evaluate iFedAvg using several public benchmarks and a previously unstudied collection of real-world datasets from the 2014 - 2016 West African Ebola epidemic, jointly forming the largest such dataset in the world. In all evaluations, iFedAvg achieves competitive average performance with negligible overhead. It additionally shows substantial improvement on outlier clients, highlighting increased robustness to individual dataset shifts. Most importantly, our method provides valuable client-specific insights at a fine-grained level to guide interoperable federated learning.
Implicit Gradient Alignment in Distributed and Federated Learning
Jun 25, 2021
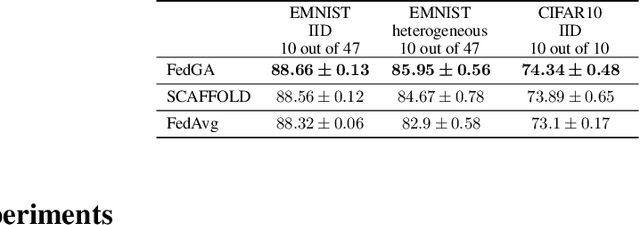
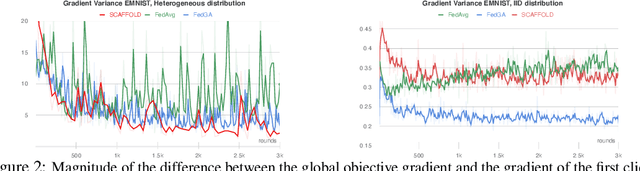
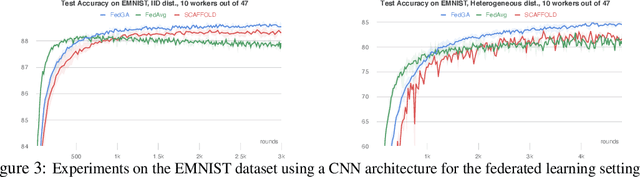
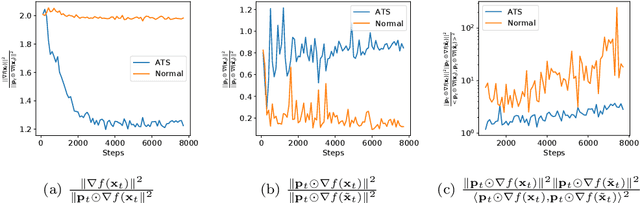
A major obstacle to achieving global convergence in distributed and federated learning is the misalignment of gradients across clients, or mini-batches due to heterogeneity and stochasticity of the distributed data. One way to alleviate this problem is to encourage the alignment of gradients across different clients throughout training. Our analysis reveals that this goal can be accomplished by utilizing the right optimization method that replicates the implicit regularization effect of SGD, leading to gradient alignment as well as improvements in test accuracies. Since the existence of this regularization in SGD completely relies on the sequential use of different mini-batches during training, it is inherently absent when training with large mini-batches. To obtain the generalization benefits of this regularization while increasing parallelism, we propose a novel GradAlign algorithm that induces the same implicit regularization while allowing the use of arbitrarily large batches in each update. We experimentally validate the benefit of our algorithm in different distributed and federated learning settings.
Simultaneous Training of Partially Masked Neural Networks
Jun 16, 2021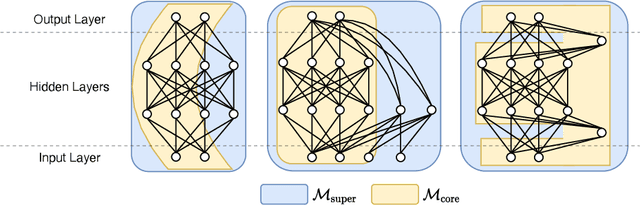


For deploying deep learning models to lower end devices, it is necessary to train less resource-demanding variants of state-of-the-art architectures. This does not eliminate the need for more expensive models as they have a higher performance. In order to avoid training two separate models, we show that it is possible to train neural networks in such a way that a predefined 'core' subnetwork can be split-off from the trained full network with remarkable good performance. We extend on prior methods that focused only on core networks of smaller width, while we focus on supporting arbitrary core network architectures. Our proposed training scheme switches consecutively between optimizing only the core part of the network and the full one. The accuracy of the full model remains comparable, while the core network achieves better performance than when it is trained in isolation. In particular, we show that training a Transformer with a low-rank core gives a low-rank model with superior performance than when training the low-rank model alone. We analyze our training scheme theoretically, and show its convergence under assumptions that are either standard or practically justified. Moreover, we show that the developed theoretical framework allows analyzing many other partial training schemes for neural networks.
Lightweight Cross-Lingual Sentence Representation Learning
Jun 12, 2021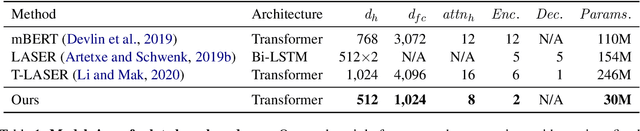
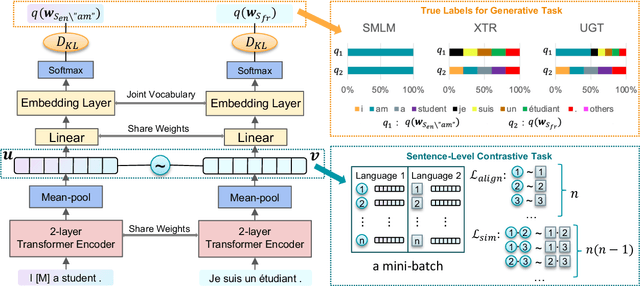
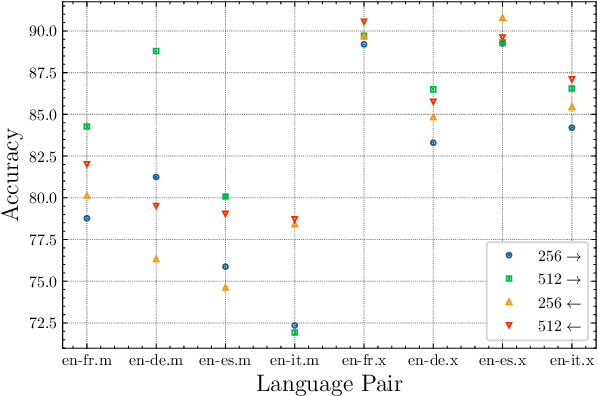
Large-scale models for learning fixed-dimensional cross-lingual sentence representations like LASER (Artetxe and Schwenk, 2019b) lead to significant improvement in performance on downstream tasks. However, further increases and modifications based on such large-scale models are usually impractical due to memory limitations. In this work, we introduce a lightweight dual-transformer architecture with just 2 layers for generating memory-efficient cross-lingual sentence representations. We explore different training tasks and observe that current cross-lingual training tasks leave a lot to be desired for this shallow architecture. To ameliorate this, we propose a novel cross-lingual language model, which combines the existing single-word masked language model with the newly proposed cross-lingual token-level reconstruction task. We further augment the training task by the introduction of two computationally-lite sentence-level contrastive learning tasks to enhance the alignment of cross-lingual sentence representation space, which compensates for the learning bottleneck of the lightweight transformer for generative tasks. Our comparisons with competing models on cross-lingual sentence retrieval and multilingual document classification confirm the effectiveness of the newly proposed training tasks for a shallow model.
Obtaining Better Static Word Embeddings Using Contextual Embedding Models
Jun 08, 2021
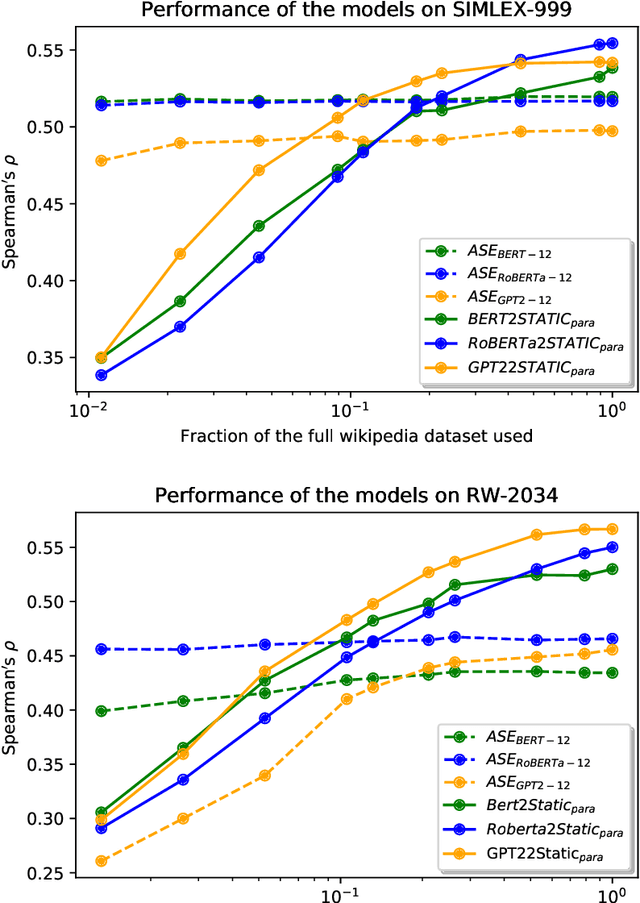

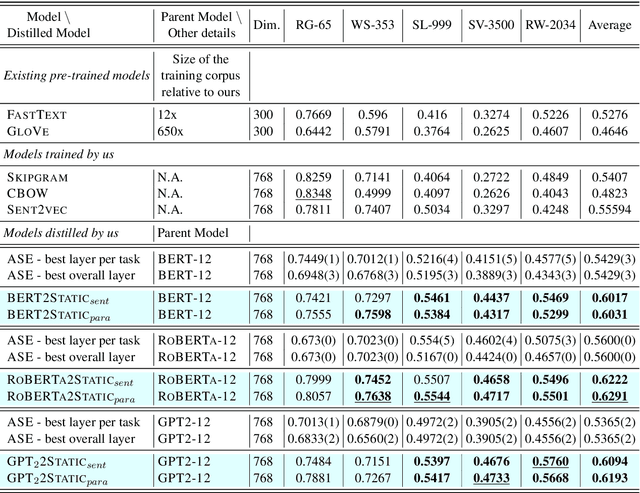
The advent of contextual word embeddings -- representations of words which incorporate semantic and syntactic information from their context -- has led to tremendous improvements on a wide variety of NLP tasks. However, recent contextual models have prohibitively high computational cost in many use-cases and are often hard to interpret. In this work, we demonstrate that our proposed distillation method, which is a simple extension of CBOW-based training, allows to significantly improve computational efficiency of NLP applications, while outperforming the quality of existing static embeddings trained from scratch as well as those distilled from previously proposed methods. As a side-effect, our approach also allows a fair comparison of both contextual and static embeddings via standard lexical evaluation tasks.
Federated Learning for Malware Detection in IoT Devices
Apr 15, 2021
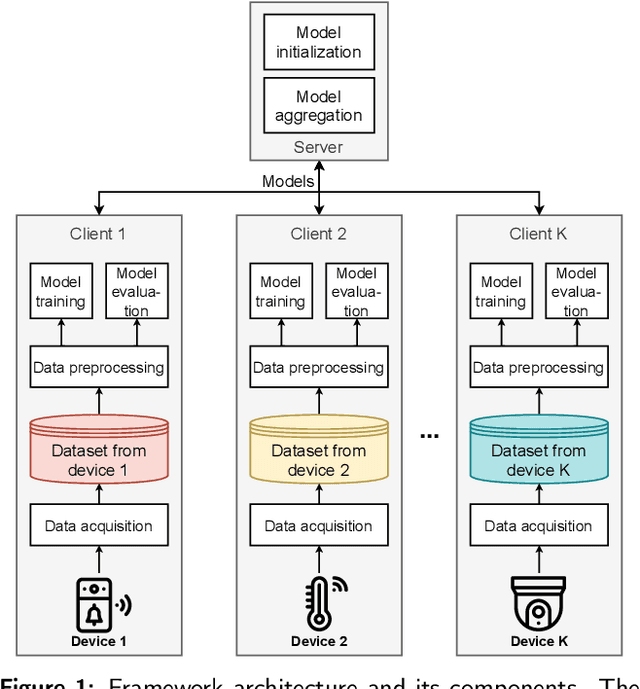
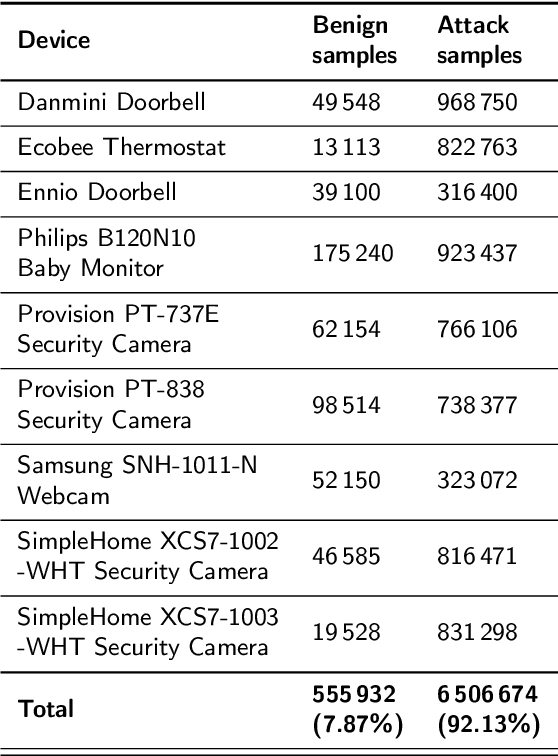
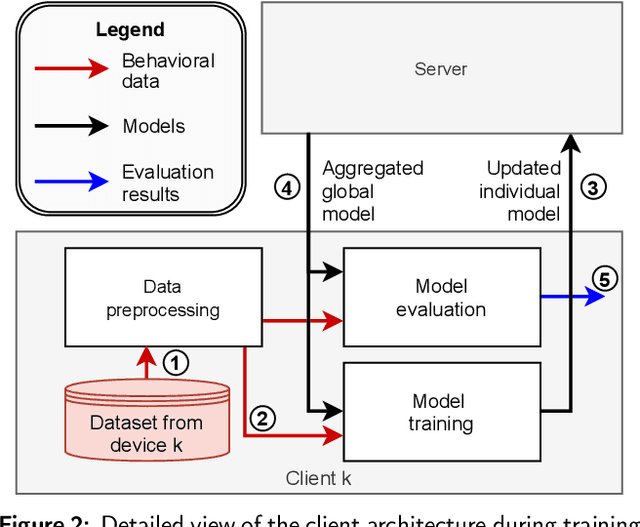
This work investigates the possibilities enabled by federated learning concerning IoT malware detection and studies security issues inherent to this new learning paradigm. In this context, a framework that uses federated learning to detect malware affecting IoT devices is presented. N-BaIoT, a dataset modeling network traffic of several real IoT devices while affected by malware, has been used to evaluate the proposed framework. Both supervised and unsupervised federated models (multi-layer perceptron and autoencoder) able to detect malware affecting seen and unseen IoT devices of N-BaIoT have been trained and evaluated. Furthermore, their performance has been compared to two traditional approaches. The first one lets each participant locally train a model using only its own data, while the second consists of making the participants share their data with a central entity in charge of training a global model. This comparison has shown that the use of more diverse and large data, as done in the federated and centralized methods, has a considerable positive impact on the model performance. Besides, the federated models, while preserving the participant's privacy, show similar results as the centralized ones. As an additional contribution and to measure the robustness of the federated approach, an adversarial setup with several malicious participants poisoning the federated model has been considered. The baseline model aggregation averaging step used in most federated learning algorithms appears highly vulnerable to different attacks, even with a single adversary. The performance of other model aggregation functions acting as countermeasures is thus evaluated under the same attack scenarios. These functions provide a significant improvement against malicious participants, but more efforts are still needed to make federated approaches robust.
Critical Parameters for Scalable Distributed Learning with Large Batches and Asynchronous Updates
Mar 03, 2021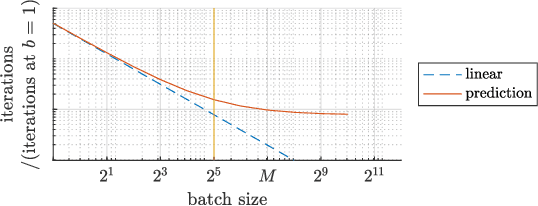

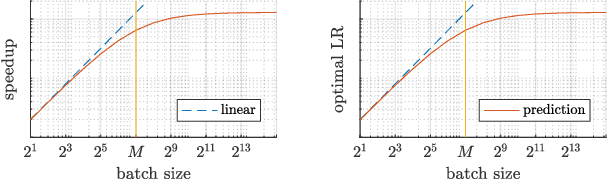
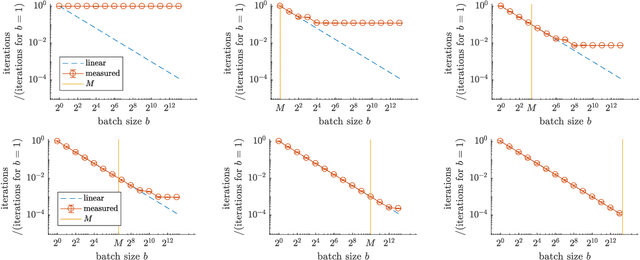
It has been experimentally observed that the efficiency of distributed training with stochastic gradient (SGD) depends decisively on the batch size and -- in asynchronous implementations -- on the gradient staleness. Especially, it has been observed that the speedup saturates beyond a certain batch size and/or when the delays grow too large. We identify a data-dependent parameter that explains the speedup saturation in both these settings. Our comprehensive theoretical analysis, for strongly convex, convex and non-convex settings, unifies and generalized prior work directions that often focused on only one of these two aspects. In particular, our approach allows us to derive improved speedup results under frequently considered sparsity assumptions. Our insights give rise to theoretically based guidelines on how the learning rates can be adjusted in practice. We show that our results are tight and illustrate key findings in numerical experiments.
Consensus Control for Decentralized Deep Learning
Feb 09, 2021
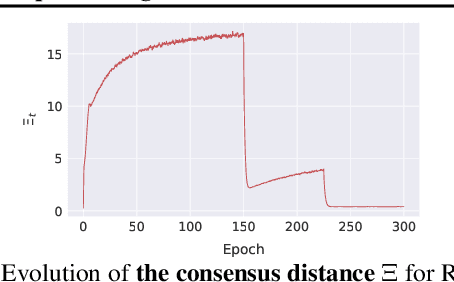
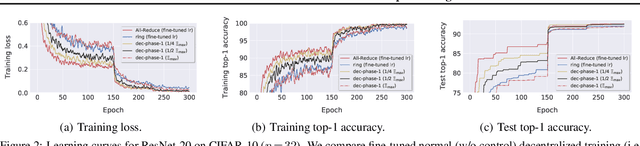

Decentralized training of deep learning models enables on-device learning over networks, as well as efficient scaling to large compute clusters. Experiments in earlier works reveal that, even in a data-center setup, decentralized training often suffers from the degradation in the quality of the model: the training and test performance of models trained in a decentralized fashion is in general worse than that of models trained in a centralized fashion, and this performance drop is impacted by parameters such as network size, communication topology and data partitioning. We identify the changing consensus distance between devices as a key parameter to explain the gap between centralized and decentralized training. We show in theory that when the training consensus distance is lower than a critical quantity, decentralized training converges as fast as the centralized counterpart. We empirically validate that the relation between generalization performance and consensus distance is consistent with this theoretical observation. Our empirical insights allow the principled design of better decentralized training schemes that mitigate the performance drop. To this end, we propose practical training guidelines for the data-center setup as the important first step.
Quasi-Global Momentum: Accelerating Decentralized Deep Learning on Heterogeneous Data
Feb 09, 2021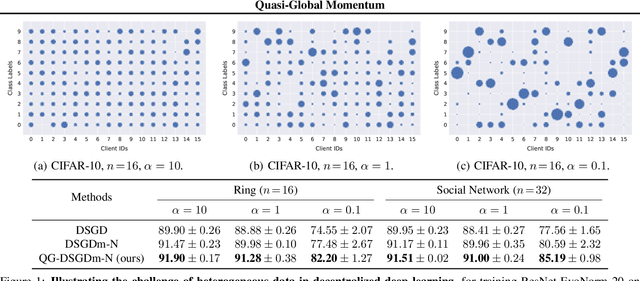
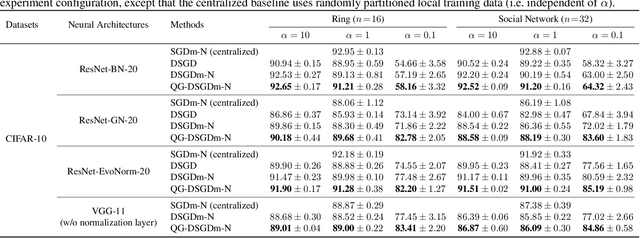
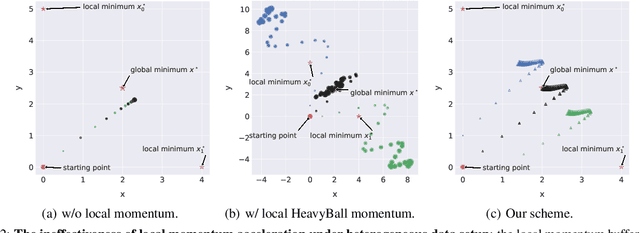
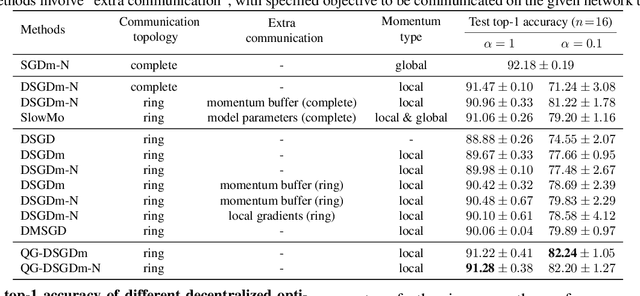
Decentralized training of deep learning models is a key element for enabling data privacy and on-device learning over networks. In realistic learning scenarios, the presence of heterogeneity across different clients' local datasets poses an optimization challenge and may severely deteriorate the generalization performance. In this paper, we investigate and identify the limitation of several decentralized optimization algorithms for different degrees of data heterogeneity. We propose a novel momentum-based method to mitigate this decentralized training difficulty. We show in extensive empirical experiments on various CV/NLP datasets (CIFAR-10, ImageNet, AG News, and SST2) and several network topologies (Ring and Social Network) that our method is much more robust to the heterogeneity of clients' data than other existing methods, by a significant improvement in test performance ($1\% \!-\! 20\%$).