 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeeling the Bern: Adaptive Estimators for Bernoulli Probabilities of Pairwise Comparisons
Mar 22, 2016
We study methods for aggregating pairwise comparison data in order to estimate outcome probabilities for future comparisons among a collection of n items. Working within a flexible framework that imposes only a form of strong stochastic transitivity (SST), we introduce an adaptivity index defined by the indifference sets of the pairwise comparison probabilities. In addition to measuring the usual worst-case risk of an estimator, this adaptivity index also captures the extent to which the estimator adapts to instance-specific difficulty relative to an oracle estimator. We prove three main results that involve this adaptivity index and different algorithms. First, we propose a three-step estimator termed Count-Randomize-Least squares (CRL), and show that it has adaptivity index upper bounded as $\sqrt{n}$ up to logarithmic factors. We then show that that conditional on the hardness of planted clique, no computationally efficient estimator can achieve an adaptivity index smaller than $\sqrt{n}$. Second, we show that a regularized least squares estimator can achieve a poly-logarithmic adaptivity index, thereby demonstrating a $\sqrt{n}$-gap between optimal and computationally achievable adaptivity. Finally, we prove that the standard least squares estimator, which is known to be optimally adaptive in several closely related problems, fails to adapt in the context of estimating pairwise probabilities.
Asymptotic behavior of $\ell_p$-based Laplacian regularization in semi-supervised learning
Mar 02, 2016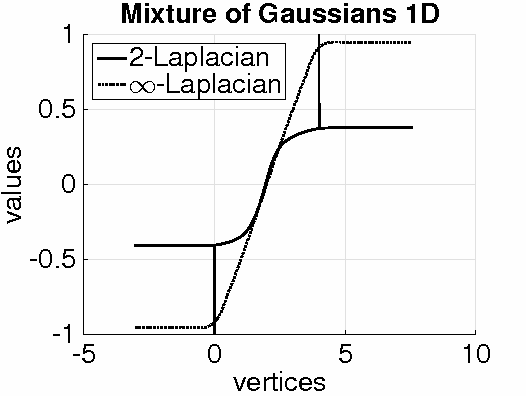
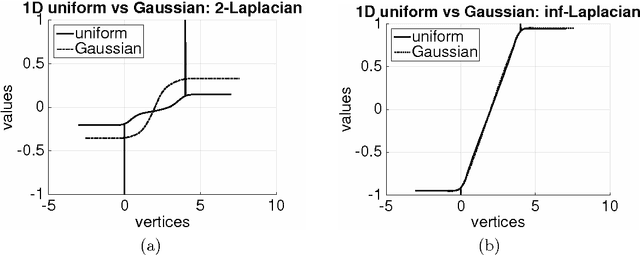
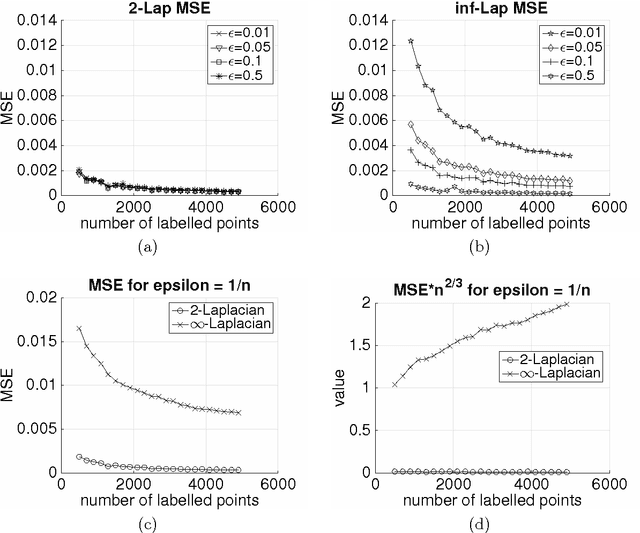
Given a weighted graph with $N$ vertices, consider a real-valued regression problem in a semi-supervised setting, where one observes $n$ labeled vertices, and the task is to label the remaining ones. We present a theoretical study of $\ell_p$-based Laplacian regularization under a $d$-dimensional geometric random graph model. We provide a variational characterization of the performance of this regularized learner as $N$ grows to infinity while $n$ stays constant, the associated optimality conditions lead to a partial differential equation that must be satisfied by the associated function estimate $\hat{f}$. From this formulation we derive several predictions on the limiting behavior the $d$-dimensional function $\hat{f}$, including (a) a phase transition in its smoothness at the threshold $p = d + 1$, and (b) a tradeoff between smoothness and sensitivity to the underlying unlabeled data distribution $P$. Thus, over the range $p \leq d$, the function estimate $\hat{f}$ is degenerate and "spiky," whereas for $p\geq d+1$, the function estimate $\hat{f}$ is smooth. We show that the effect of the underlying density vanishes monotonically with $p$, such that in the limit $p = \infty$, corresponding to the so-called Absolutely Minimal Lipschitz Extension, the estimate $\hat{f}$ is independent of the distribution $P$. Under the assumption of semi-supervised smoothness, ignoring $P$ can lead to poor statistical performance, in particular, we construct a specific example for $d=1$ to demonstrate that $p=2$ has lower risk than $p=\infty$ due to the former penalty adapting to $P$ and the latter ignoring it. We also provide simulations that verify the accuracy of our predictions for finite sample sizes. Together, these properties show that $p = d+1$ is an optimal choice, yielding a function estimate $\hat{f}$ that is both smooth and non-degenerate, while remaining maximally sensitive to $P$.
Statistical and Computational Guarantees for the Baum-Welch Algorithm
Dec 27, 2015
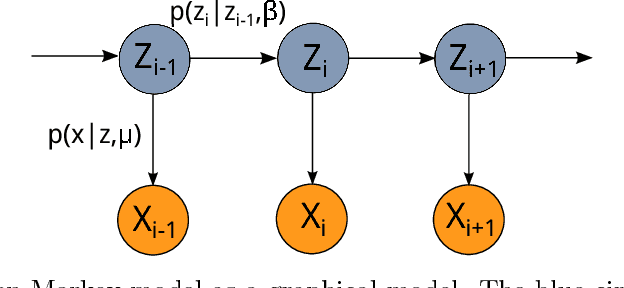
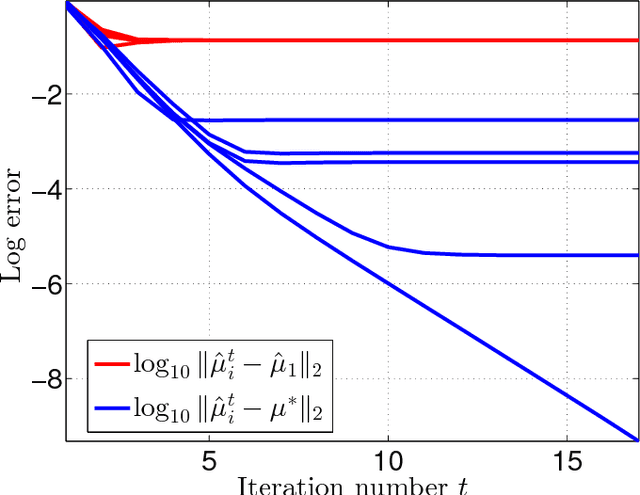
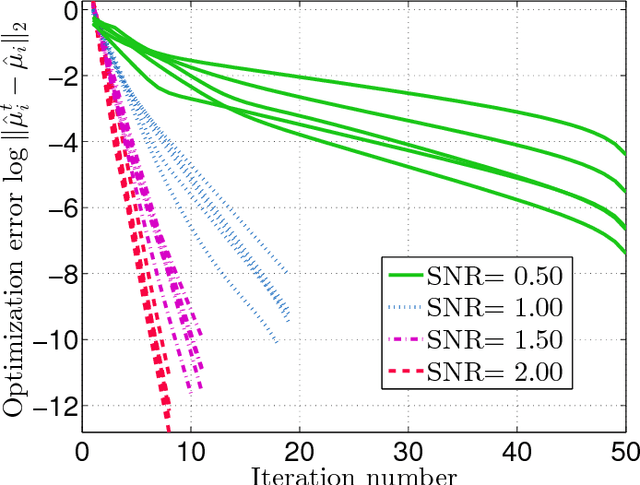
The Hidden Markov Model (HMM) is one of the mainstays of statistical modeling of discrete time series, with applications including speech recognition, computational biology, computer vision and econometrics. Estimating an HMM from its observation process is often addressed via the Baum-Welch algorithm, which is known to be susceptible to local optima. In this paper, we first give a general characterization of the basin of attraction associated with any global optimum of the population likelihood. By exploiting this characterization, we provide non-asymptotic finite sample guarantees on the Baum-Welch updates, guaranteeing geometric convergence to a small ball of radius on the order of the minimax rate around a global optimum. As a concrete example, we prove a linear rate of convergence for a hidden Markov mixture of two isotropic Gaussians given a suitable mean separation and an initialization within a ball of large radius around (one of) the true parameters. To our knowledge, these are the first rigorous local convergence guarantees to global optima for the Baum-Welch algorithm in a setting where the likelihood function is nonconvex. We complement our theoretical results with thorough numerical simulations studying the convergence of the Baum-Welch algorithm and illustrating the accuracy of our predictions.
Optimal prediction for sparse linear models? Lower bounds for coordinate-separable M-estimators
Nov 30, 2015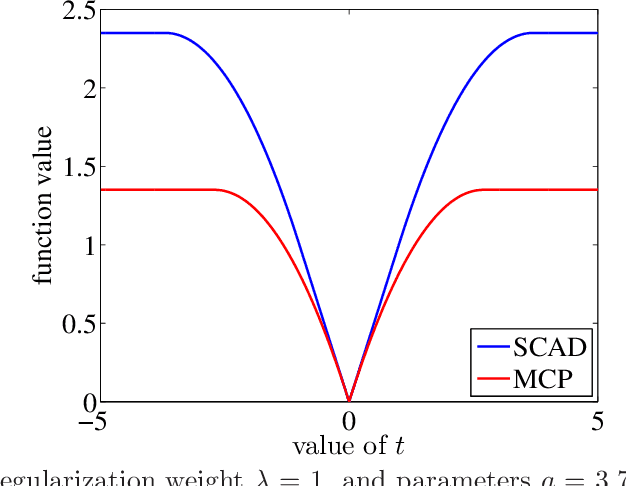
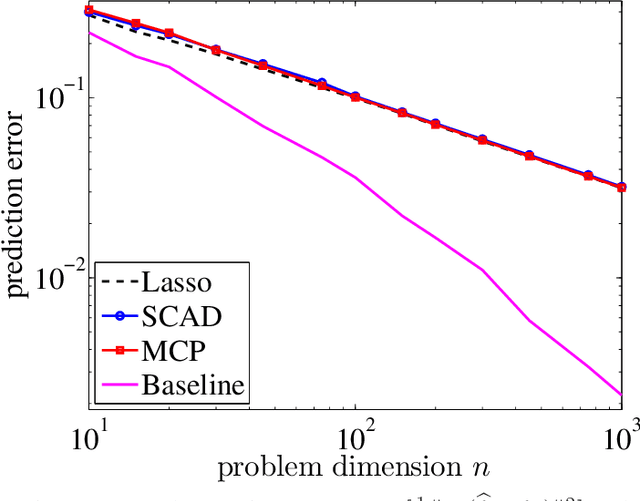
For the problem of high-dimensional sparse linear regression, it is known that an $\ell_0$-based estimator can achieve a $1/n$ "fast" rate on the prediction error without any conditions on the design matrix, whereas in absence of restrictive conditions on the design matrix, popular polynomial-time methods only guarantee the $1/\sqrt{n}$ "slow" rate. In this paper, we show that the slow rate is intrinsic to a broad class of M-estimators. In particular, for estimators based on minimizing a least-squares cost function together with a (possibly non-convex) coordinate-wise separable regularizer, there is always a "bad" local optimum such that the associated prediction error is lower bounded by a constant multiple of $1/\sqrt{n}$. For convex regularizers, this lower bound applies to all global optima. The theory is applicable to many popular estimators, including convex $\ell_1$-based methods as well as M-estimators based on nonconvex regularizers, including the SCAD penalty or the MCP regularizer. In addition, for a broad class of nonconvex regularizers, we show that the bad local optima are very common, in that a broad class of local minimization algorithms with random initialization will typically converge to a bad solution.
Learning Halfspaces and Neural Networks with Random Initialization
Nov 25, 2015
We study non-convex empirical risk minimization for learning halfspaces and neural networks. For loss functions that are $L$-Lipschitz continuous, we present algorithms to learn halfspaces and multi-layer neural networks that achieve arbitrarily small excess risk $\epsilon>0$. The time complexity is polynomial in the input dimension $d$ and the sample size $n$, but exponential in the quantity $(L/\epsilon^2)\log(L/\epsilon)$. These algorithms run multiple rounds of random initialization followed by arbitrary optimization steps. We further show that if the data is separable by some neural network with constant margin $\gamma>0$, then there is a polynomial-time algorithm for learning a neural network that separates the training data with margin $\Omega(\gamma)$. As a consequence, the algorithm achieves arbitrary generalization error $\epsilon>0$ with ${\rm poly}(d,1/\epsilon)$ sample and time complexity. We establish the same learnability result when the labels are randomly flipped with probability $\eta<1/2$.
A More Powerful Two-Sample Test in High Dimensions using Random Projection
Sep 13, 2015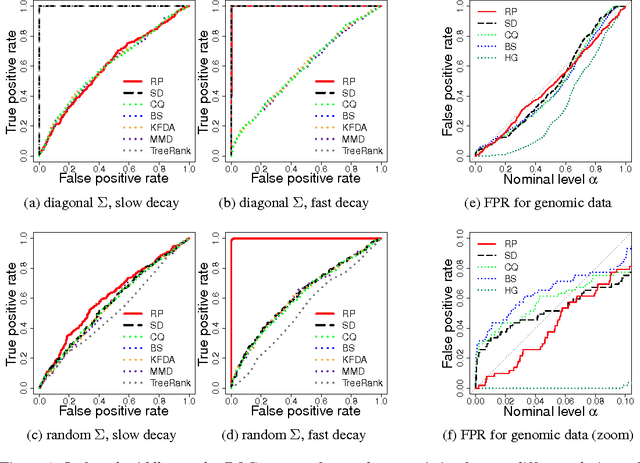
We consider the hypothesis testing problem of detecting a shift between the means of two multivariate normal distributions in the high-dimensional setting, allowing for the data dimension p to exceed the sample size n. Specifically, we propose a new test statistic for the two-sample test of means that integrates a random projection with the classical Hotelling T^2 statistic. Working under a high-dimensional framework with (p,n) tending to infinity, we first derive an asymptotic power function for our test, and then provide sufficient conditions for it to achieve greater power than other state-of-the-art tests. Using ROC curves generated from synthetic data, we demonstrate superior performance against competing tests in the parameter regimes anticipated by our theoretical results. Lastly, we illustrate an advantage of our procedure's false positive rate with comparisons on high-dimensional gene expression data involving the discrimination of different types of cancer.
Fast low-rank estimation by projected gradient descent: General statistical and algorithmic guarantees
Sep 10, 2015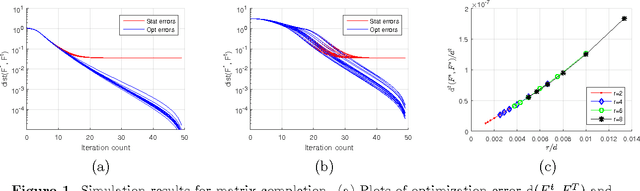
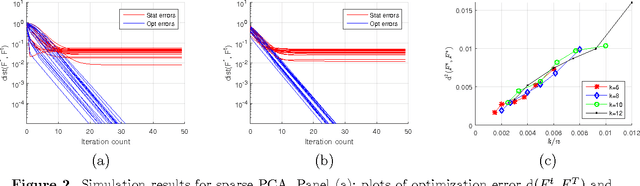
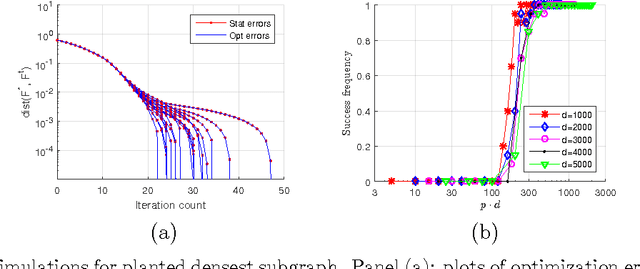
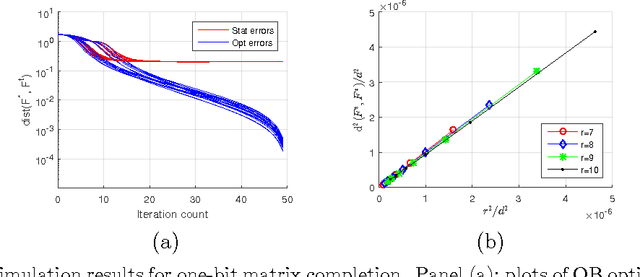
Optimization problems with rank constraints arise in many applications, including matrix regression, structured PCA, matrix completion and matrix decomposition problems. An attractive heuristic for solving such problems is to factorize the low-rank matrix, and to run projected gradient descent on the nonconvex factorized optimization problem. The goal of this problem is to provide a general theoretical framework for understanding when such methods work well, and to characterize the nature of the resulting fixed point. We provide a simple set of conditions under which projected gradient descent, when given a suitable initialization, converges geometrically to a statistically useful solution. Our results are applicable even when the initial solution is outside any region of local convexity, and even when the problem is globally concave. Working in a non-asymptotic framework, we show that our conditions are satisfied for a wide range of concrete models, including matrix regression, structured PCA, matrix completion with real and quantized observations, matrix decomposition, and graph clustering problems. Simulation results show excellent agreement with the theoretical predictions.
On the Computational Complexity of High-Dimensional Bayesian Variable Selection
May 29, 2015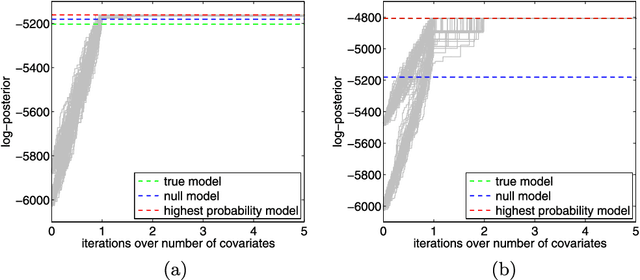
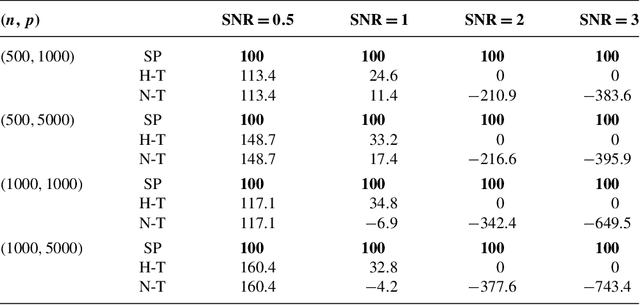
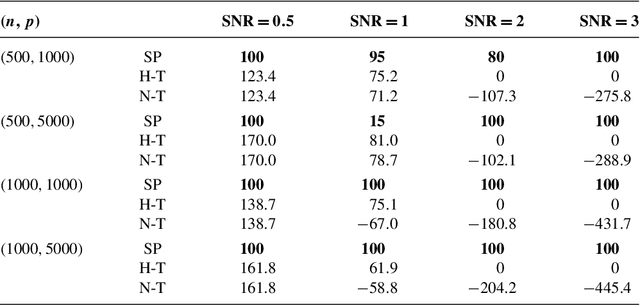
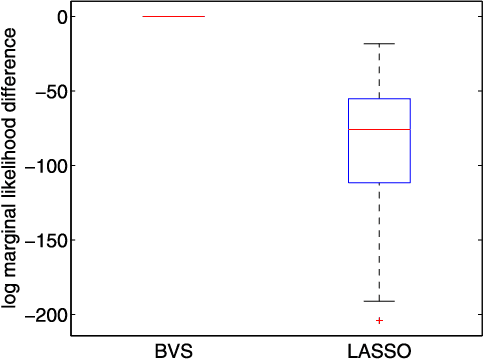
We study the computational complexity of Markov chain Monte Carlo (MCMC) methods for high-dimensional Bayesian linear regression under sparsity constraints. We first show that a Bayesian approach can achieve variable-selection consistency under relatively mild conditions on the design matrix. We then demonstrate that the statistical criterion of posterior concentration need not imply the computational desideratum of rapid mixing of the MCMC algorithm. By introducing a truncated sparsity prior for variable selection, we provide a set of conditions that guarantee both variable-selection consistency and rapid mixing of a particular Metropolis-Hastings algorithm. The mixing time is linear in the number of covariates up to a logarithmic factor. Our proof controls the spectral gap of the Markov chain by constructing a canonical path ensemble that is inspired by the steps taken by greedy algorithms for variable selection.
Newton Sketch: A Linear-time Optimization Algorithm with Linear-Quadratic Convergence
May 09, 2015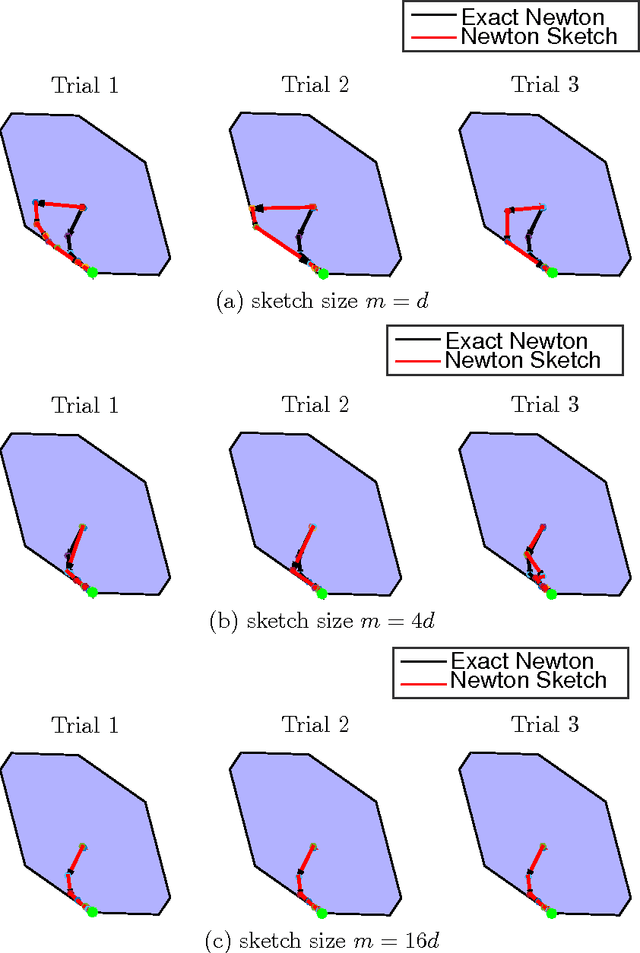
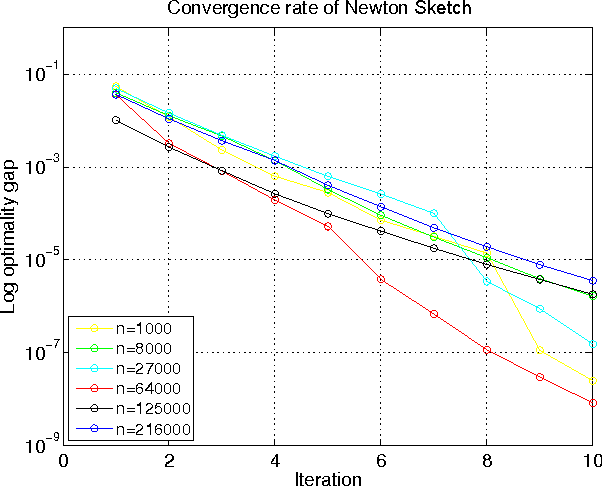
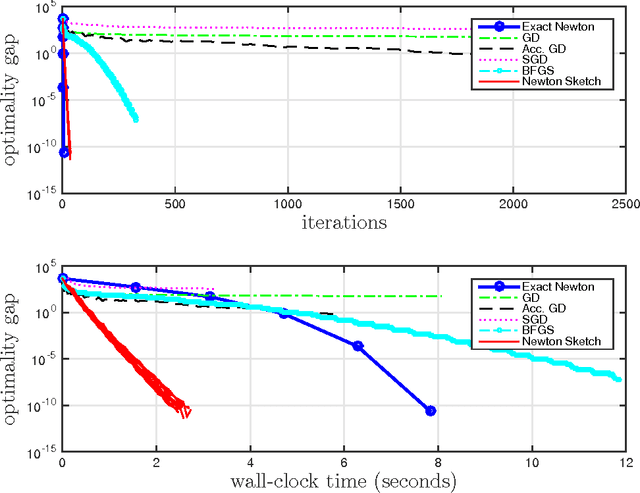
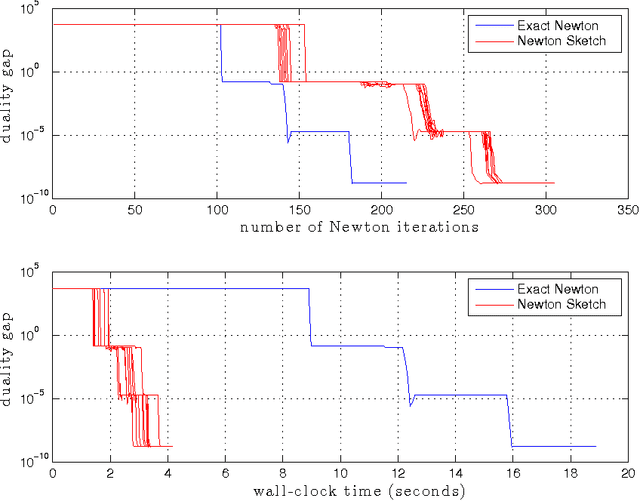
We propose a randomized second-order method for optimization known as the Newton Sketch: it is based on performing an approximate Newton step using a randomly projected or sub-sampled Hessian. For self-concordant functions, we prove that the algorithm has super-linear convergence with exponentially high probability, with convergence and complexity guarantees that are independent of condition numbers and related problem-dependent quantities. Given a suitable initialization, similar guarantees also hold for strongly convex and smooth objectives without self-concordance. When implemented using randomized projections based on a sub-sampled Hadamard basis, the algorithm typically has substantially lower complexity than Newton's method. We also describe extensions of our methods to programs involving convex constraints that are equipped with self-concordant barriers. We discuss and illustrate applications to linear programs, quadratic programs with convex constraints, logistic regression and other generalized linear models, as well as semidefinite programs.
Estimation from Pairwise Comparisons: Sharp Minimax Bounds with Topology Dependence
May 06, 2015
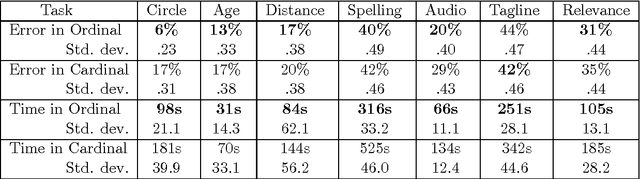
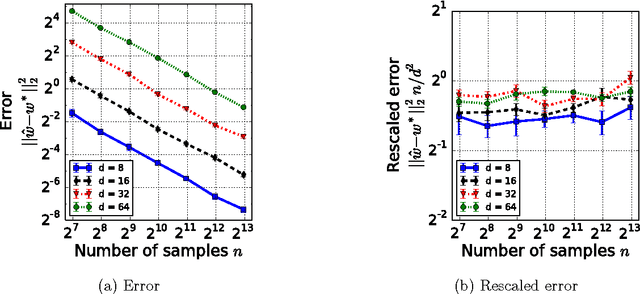

Data in the form of pairwise comparisons arises in many domains, including preference elicitation, sporting competitions, and peer grading among others. We consider parametric ordinal models for such pairwise comparison data involving a latent vector $w^* \in \mathbb{R}^d$ that represents the "qualities" of the $d$ items being compared; this class of models includes the two most widely used parametric models--the Bradley-Terry-Luce (BTL) and the Thurstone models. Working within a standard minimax framework, we provide tight upper and lower bounds on the optimal error in estimating the quality score vector $w^*$ under this class of models. The bounds depend on the topology of the comparison graph induced by the subset of pairs being compared via its Laplacian spectrum. Thus, in settings where the subset of pairs may be chosen, our results provide principled guidelines for making this choice. Finally, we compare these error rates to those under cardinal measurement models and show that the error rates in the ordinal and cardinal settings have identical scalings apart from constant pre-factors.