 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal policy evaluation using kernel-based temporal difference methods
Sep 24, 2021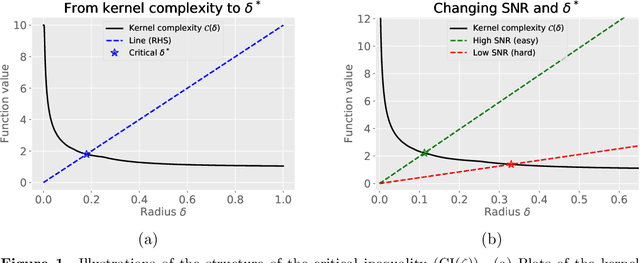
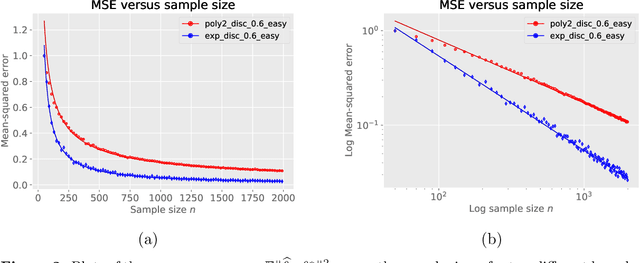
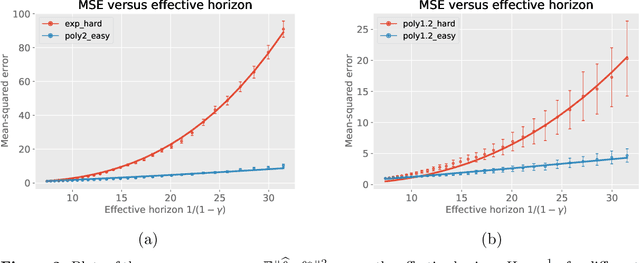
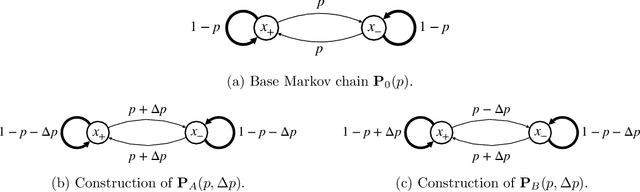
We study methods based on reproducing kernel Hilbert spaces for estimating the value function of an infinite-horizon discounted Markov reward process (MRP). We study a regularized form of the kernel least-squares temporal difference (LSTD) estimate; in the population limit of infinite data, it corresponds to the fixed point of a projected Bellman operator defined by the associated reproducing kernel Hilbert space. The estimator itself is obtained by computing the projected fixed point induced by a regularized version of the empirical operator; due to the underlying kernel structure, this reduces to solving a linear system involving kernel matrices. We analyze the error of this estimate in the $L^2(\mu)$-norm, where $\mu$ denotes the stationary distribution of the underlying Markov chain. Our analysis imposes no assumptions on the transition operator of the Markov chain, but rather only conditions on the reward function and population-level kernel LSTD solutions. We use empirical process theory techniques to derive a non-asymptotic upper bound on the error with explicit dependence on the eigenvalues of the associated kernel operator, as well as the instance-dependent variance of the Bellman residual error. In addition, we prove minimax lower bounds over sub-classes of MRPs, which shows that our rate is optimal in terms of the sample size $n$ and the effective horizon $H = (1 - \gamma)^{-1}$. Whereas existing worst-case theory predicts cubic scaling ($H^3$) in the effective horizon, our theory reveals that there is in fact a much wider range of scalings, depending on the kernel, the stationary distribution, and the variance of the Bellman residual error. Notably, it is only parametric and near-parametric problems that can ever achieve the worst-case cubic scaling.
Provable Benefits of Actor-Critic Methods for Offline Reinforcement Learning
Aug 19, 2021Actor-critic methods are widely used in offline reinforcement learning practice, but are not so well-understood theoretically. We propose a new offline actor-critic algorithm that naturally incorporates the pessimism principle, leading to several key advantages compared to the state of the art. The algorithm can operate when the Bellman evaluation operator is closed with respect to the action value function of the actor's policies; this is a more general setting than the low-rank MDP model. Despite the added generality, the procedure is computationally tractable as it involves the solution of a sequence of second-order programs. We prove an upper bound on the suboptimality gap of the policy returned by the procedure that depends on the data coverage of any arbitrary, possibly data dependent comparator policy. The achievable guarantee is complemented with a minimax lower bound that is matching up to logarithmic factors.
Near-optimal inference in adaptive linear regression
Jul 14, 2021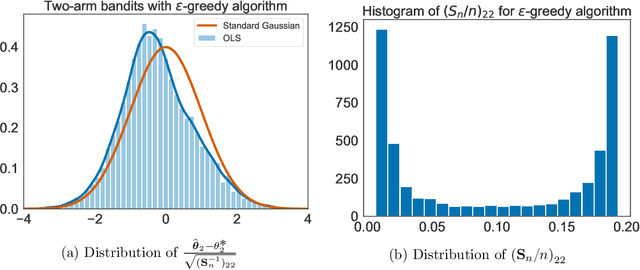
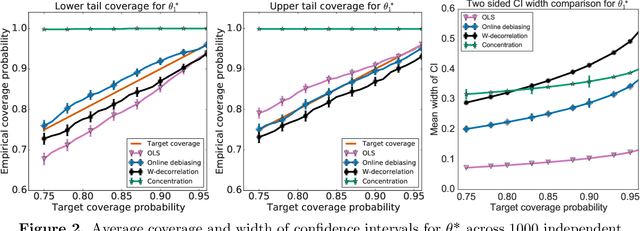
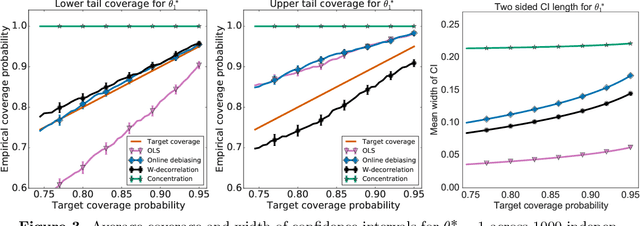
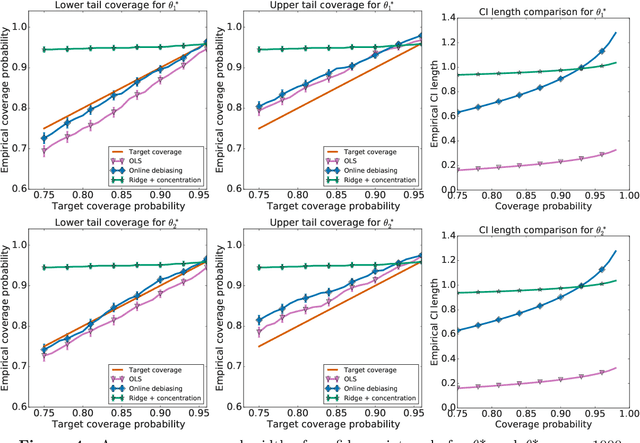
When data is collected in an adaptive manner, even simple methods like ordinary least squares can exhibit non-normal asymptotic behavior. As an undesirable consequence, hypothesis tests and confidence intervals based on asymptotic normality can lead to erroneous results. We propose an online debiasing estimator to correct these distributional anomalies in least squares estimation. Our proposed method takes advantage of the covariance structure present in the dataset and provides sharper estimates in directions for which more information has accrued. We establish an asymptotic normality property for our proposed online debiasing estimator under mild conditions on the data collection process, and provide asymptotically exact confidence intervals. We additionally prove a minimax lower bound for the adaptive linear regression problem, thereby providing a baseline by which to compare estimators. There are various conditions under which our proposed estimator achieves the minimax lower bound up to logarithmic factors. We demonstrate the usefulness of our theory via applications to multi-armed bandit, autoregressive time series estimation, and active learning with exploration.
Instance-optimality in optimal value estimation: Adaptivity via variance-reduced Q-learning
Jun 28, 2021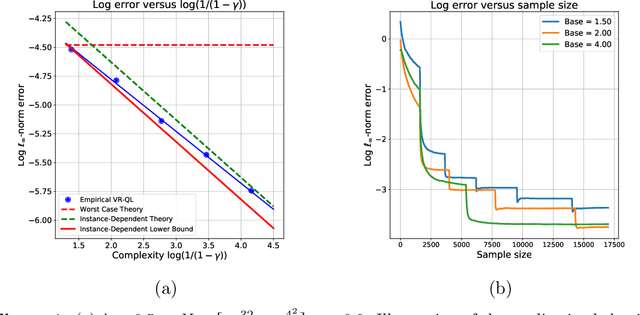
Various algorithms in reinforcement learning exhibit dramatic variability in their convergence rates and ultimate accuracy as a function of the problem structure. Such instance-specific behavior is not captured by existing global minimax bounds, which are worst-case in nature. We analyze the problem of estimating optimal $Q$-value functions for a discounted Markov decision process with discrete states and actions and identify an instance-dependent functional that controls the difficulty of estimation in the $\ell_\infty$-norm. Using a local minimax framework, we show that this functional arises in lower bounds on the accuracy on any estimation procedure. In the other direction, we establish the sharpness of our lower bounds, up to factors logarithmic in the state and action spaces, by analyzing a variance-reduced version of $Q$-learning. Our theory provides a precise way of distinguishing "easy" problems from "hard" ones in the context of $Q$-learning, as illustrated by an ensemble with a continuum of difficulty.
Preference learning along multiple criteria: A game-theoretic perspective
May 05, 2021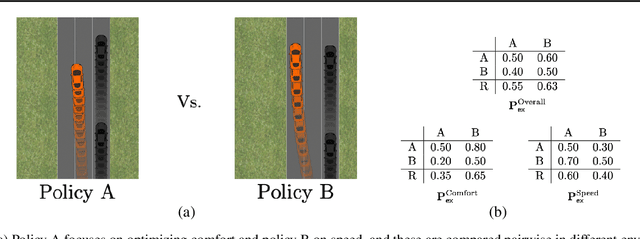
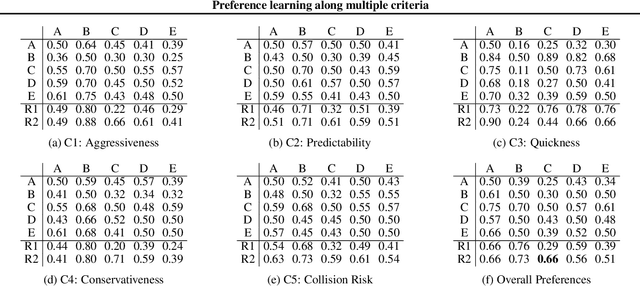
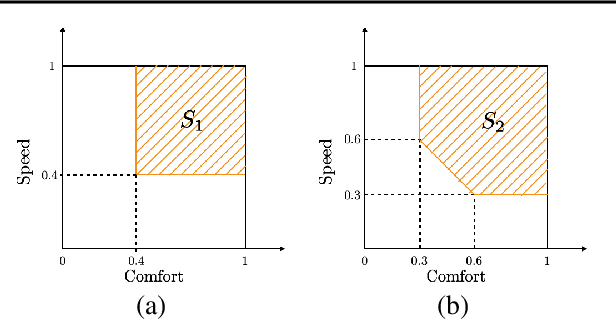
The literature on ranking from ordinal data is vast, and there are several ways to aggregate overall preferences from pairwise comparisons between objects. In particular, it is well known that any Nash equilibrium of the zero sum game induced by the preference matrix defines a natural solution concept (winning distribution over objects) known as a von Neumann winner. Many real-world problems, however, are inevitably multi-criteria, with different pairwise preferences governing the different criteria. In this work, we generalize the notion of a von Neumann winner to the multi-criteria setting by taking inspiration from Blackwell's approachability. Our framework allows for non-linear aggregation of preferences across criteria, and generalizes the linearization-based approach from multi-objective optimization. From a theoretical standpoint, we show that the Blackwell winner of a multi-criteria problem instance can be computed as the solution to a convex optimization problem. Furthermore, given random samples of pairwise comparisons, we show that a simple plug-in estimator achieves near-optimal minimax sample complexity. Finally, we showcase the practical utility of our framework in a user study on autonomous driving, where we find that the Blackwell winner outperforms the von Neumann winner for the overall preferences.
Minimax Off-Policy Evaluation for Multi-Armed Bandits
Jan 19, 2021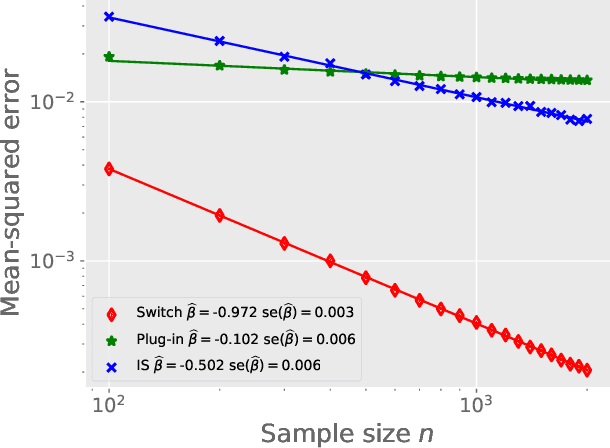
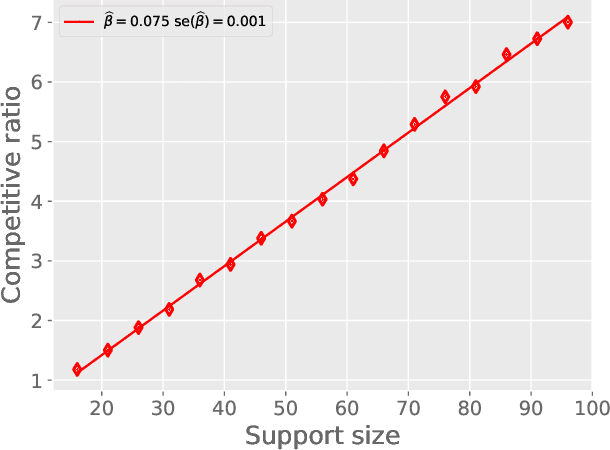
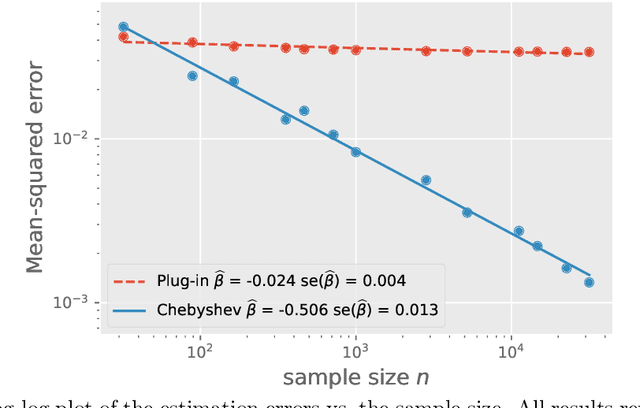
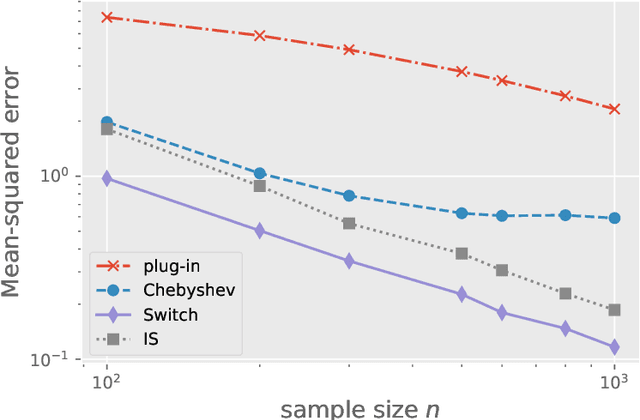
We study the problem of off-policy evaluation in the multi-armed bandit model with bounded rewards, and develop minimax rate-optimal procedures under three settings. First, when the behavior policy is known, we show that the Switch estimator, a method that alternates between the plug-in and importance sampling estimators, is minimax rate-optimal for all sample sizes. Second, when the behavior policy is unknown, we analyze performance in terms of the competitive ratio, thereby revealing a fundamental gap between the settings of known and unknown behavior policies. When the behavior policy is unknown, any estimator must have mean-squared error larger -- relative to the oracle estimator equipped with the knowledge of the behavior policy -- by a multiplicative factor proportional to the support size of the target policy. Moreover, we demonstrate that the plug-in approach achieves this worst-case competitive ratio up to a logarithmic factor. Third, we initiate the study of the partial knowledge setting in which it is assumed that the minimum probability taken by the behavior policy is known. We show that the plug-in estimator is optimal for relatively large values of the minimum probability, but is sub-optimal when the minimum probability is low. In order to remedy this gap, we propose a new estimator based on approximation by Chebyshev polynomials that provably achieves the optimal estimation error. Numerical experiments on both simulated and real data corroborate our theoretical findings.
Optimal oracle inequalities for solving projected fixed-point equations
Dec 09, 2020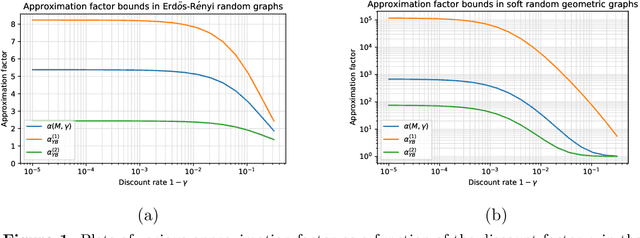
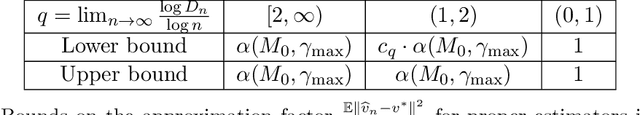
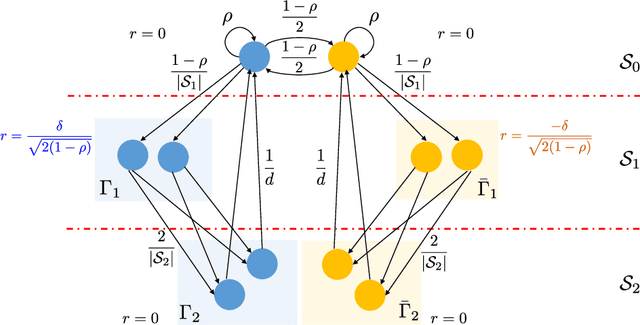
Linear fixed point equations in Hilbert spaces arise in a variety of settings, including reinforcement learning, and computational methods for solving differential and integral equations. We study methods that use a collection of random observations to compute approximate solutions by searching over a known low-dimensional subspace of the Hilbert space. First, we prove an instance-dependent upper bound on the mean-squared error for a linear stochastic approximation scheme that exploits Polyak--Ruppert averaging. This bound consists of two terms: an approximation error term with an instance-dependent approximation factor, and a statistical error term that captures the instance-specific complexity of the noise when projected onto the low-dimensional subspace. Using information theoretic methods, we also establish lower bounds showing that both of these terms cannot be improved, again in an instance-dependent sense. A concrete consequence of our characterization is that the optimal approximation factor in this problem can be much larger than a universal constant. We show how our results precisely characterize the error of a class of temporal difference learning methods for the policy evaluation problem with linear function approximation, establishing their optimality.
ROOT-SGD: Sharp Nonasymptotics and Asymptotic Efficiency in a Single Algorithm
Aug 28, 2020
The theory and practice of stochastic optimization has focused on stochastic gradient descent (SGD) in recent years, retaining the basic first-order stochastic nature of SGD while aiming to improve it via mechanisms such as averaging, momentum, and variance reduction. Improvement can be measured along various dimensions, however, and it has proved difficult to achieve improvements both in terms of nonasymptotic measures of convergence rate and asymptotic measures of distributional tightness. In this work, we consider first-order stochastic optimization from a general statistical point of view, motivating a specific form of recursive averaging of past stochastic gradients. The resulting algorithm, which we refer to as \emph{Recursive One-Over-T SGD} (ROOT-SGD), matches the state-of-the-art convergence rate among online variance-reduced stochastic approximation methods. Moreover, under slightly stronger distributional assumptions, the rescaled last-iterate of ROOT-SGD converges to a zero-mean Gaussian distribution that achieves near-optimal covariance.
Revisiting complexity and the bias-variance tradeoff
Jun 17, 2020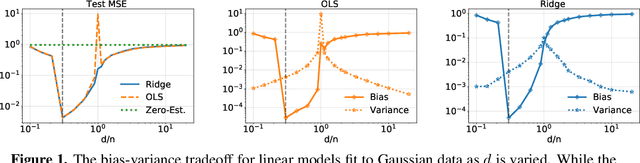
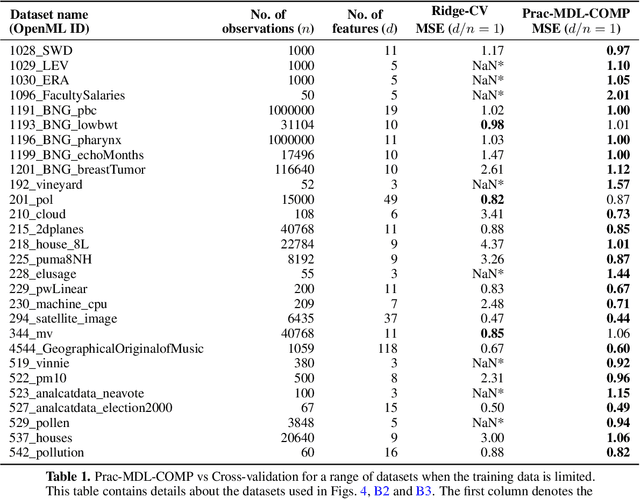
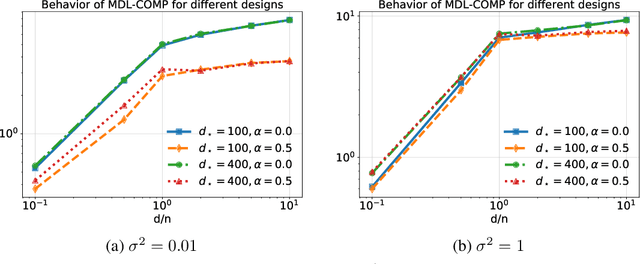
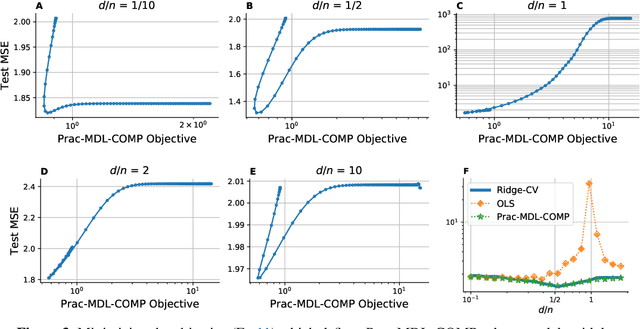
The recent success of high-dimensional models, such as deep neural networks (DNNs), has led many to question the validity of the bias-variance tradeoff principle in high dimensions. We reexamine it with respect to two key choices: the model class and the complexity measure. We argue that failing to suitably specify either one can falsely suggest that the tradeoff does not hold. This observation motivates us to seek a valid complexity measure, defined with respect to a reasonably good class of models. Building on Rissanen's principle of minimum description length (MDL), we propose a novel MDL-based complexity (MDL-COMP). We focus on the context of linear models, which have been recently used as a stylized tractable approximation to DNNs in high-dimensions. MDL-COMP is defined via an optimality criterion over the encodings induced by a good Ridge estimator class. We derive closed-form expressions for MDL-COMP and show that for a dataset with $n$ observations and $d$ parameters it is \emph{not always} equal to $d/n$, and is a function of the singular values of the design matrix and the signal-to-noise ratio. For random Gaussian design, we find that while MDL-COMP scales linearly with $d$ in low-dimensions ($d<n$), for high-dimensions ($d>n$) the scaling is exponentially smaller, scaling as $\log d$. We hope that such a slow growth of complexity in high-dimensions can help shed light on the good generalization performance of several well-tuned high-dimensional models. Moreover, via an array of simulations and real-data experiments, we show that a data-driven Prac-MDL-COMP can inform hyper-parameter tuning for ridge regression in limited data settings, sometimes improving upon cross-validation.
Instability, Computational Efficiency and Statistical Accuracy
May 22, 2020
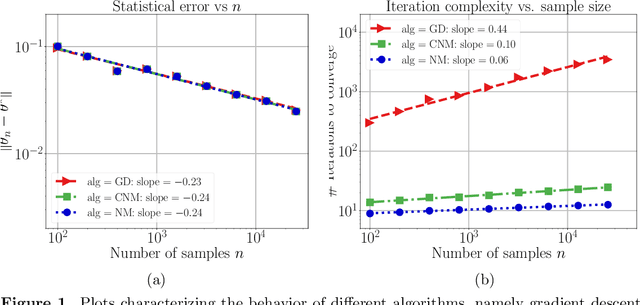
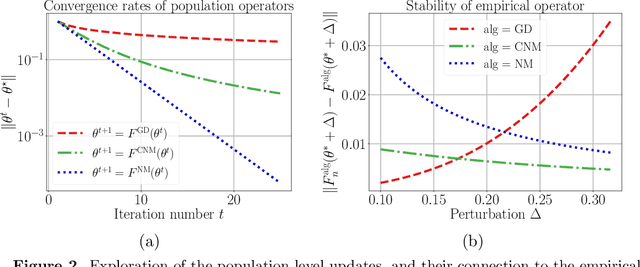

Many statistical estimators are defined as the fixed point of a data-dependent operator, with estimators based on minimizing a cost function being an important special case. The limiting performance of such estimators depends on the properties of the population-level operator in the idealized limit of infinitely many samples. We develop a general framework that yields bounds on statistical accuracy based on the interplay between the deterministic convergence rate of the algorithm at the population level, and its degree of (in)stability when applied to an empirical object based on $n$ samples. Using this framework, we analyze both stable forms of gradient descent and some higher-order and unstable algorithms, including Newton's method and its cubic-regularized variant, as well as the EM algorithm. We provide applications of our general results to several concrete classes of models, including Gaussian mixture estimation, single-index models, and informative non-response models. We exhibit cases in which an unstable algorithm can achieve the same statistical accuracy as a stable algorithm in exponentially fewer steps---namely, with the number of iterations being reduced from polynomial to logarithmic in sample size $n$.