 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Scale Knowledge Distillation via Dynamic Importance Sampling
Dec 03, 2018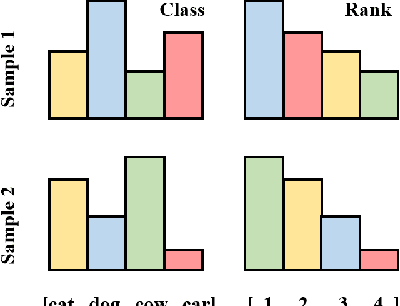
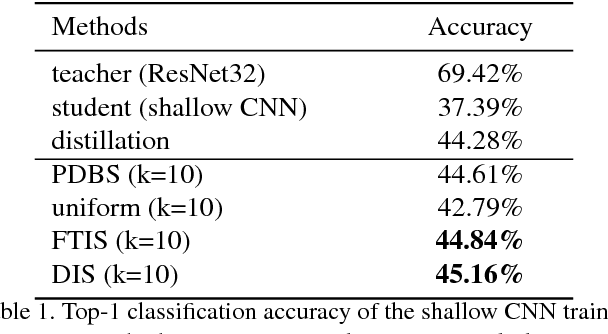
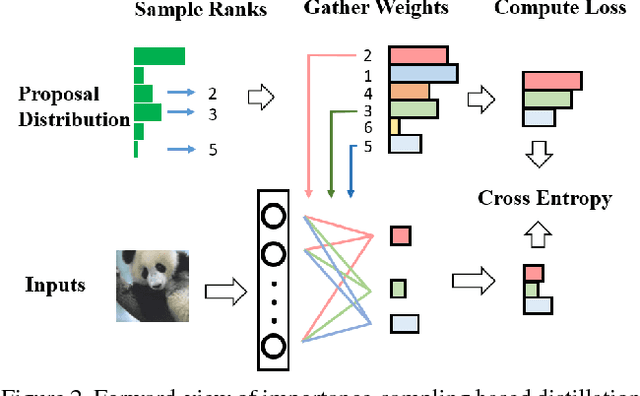
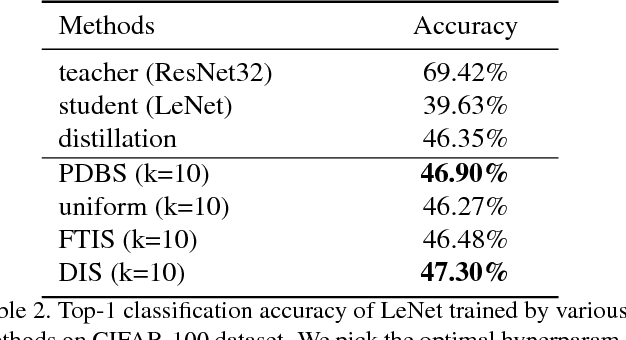
Knowledge distillation is an effective technique that transfers knowledge from a large teacher model to a shallow student. However, just like massive classification, large scale knowledge distillation also imposes heavy computational costs on training models of deep neural networks, as the softmax activations at the last layer involve computing probabilities over numerous classes. In this work, we apply the idea of importance sampling which is often used in Neural Machine Translation on large scale knowledge distillation. We present a method called dynamic importance sampling, where ranked classes are sampled from a dynamic distribution derived from the interaction between the teacher and student in full distillation. We highlight the utility of our proposal prior which helps the student capture the main information in the loss function. Our approach manages to reduce the computational cost at training time while maintaining the competitive performance on CIFAR-100 and Market-1501 person re-identification datasets.
An Off-policy Policy Gradient Theorem Using Emphatic Weightings
Nov 22, 2018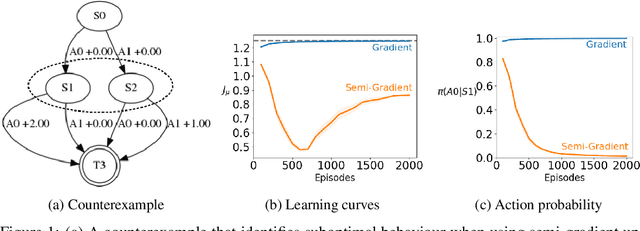
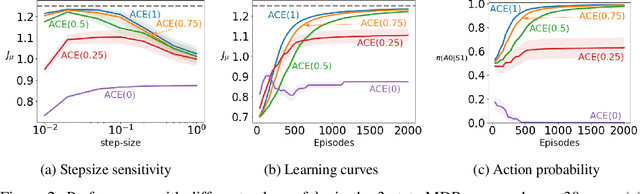
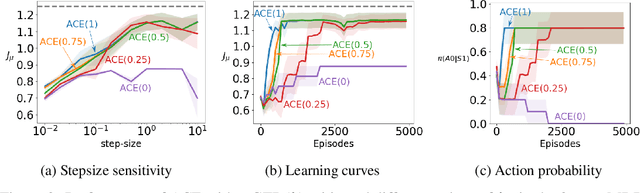
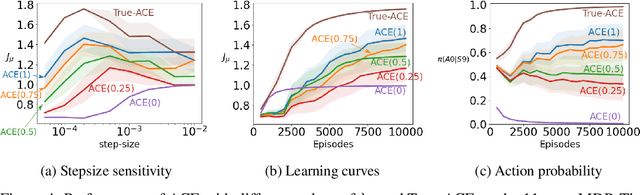
Policy gradient methods are widely used for control in reinforcement learning, particularly for the continuous action setting. There have been a host of theoretically sound algorithms proposed for the on-policy setting, due to the existence of the policy gradient theorem which provides a simplified form for the gradient. In off-policy learning, however, where the behaviour policy is not necessarily attempting to learn and follow the optimal policy for the given task, the existence of such a theorem has been elusive. In this work, we solve this open problem by providing the first off-policy policy gradient theorem. The key to the derivation is the use of $emphatic$ $weightings$. We develop a new actor-critic algorithm$\unicode{x2014}$called Actor Critic with Emphatic weightings (ACE)$\unicode{x2014}$that approximates the simplified gradients provided by the theorem. We demonstrate in a simple counterexample that previous off-policy policy gradient methods$\unicode{x2014}$particularly OffPAC and DPG$\unicode{x2014}$converge to the wrong solution whereas ACE finds the optimal solution.
The Barbados 2018 List of Open Issues in Continual Learning
Nov 16, 2018We want to make progress toward artificial general intelligence, namely general-purpose agents that autonomously learn how to competently act in complex environments. The purpose of this report is to sketch a research outline, share some of the most important open issues we are facing, and stimulate further discussion in the community. The content is based on some of our discussions during a week-long workshop held in Barbados in February 2018.
Context-Dependent Upper-Confidence Bounds for Directed Exploration
Nov 15, 2018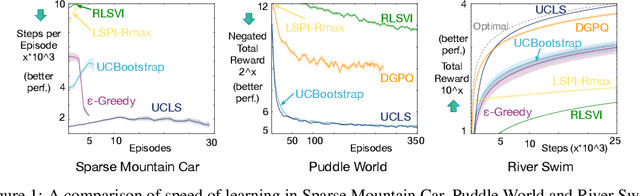
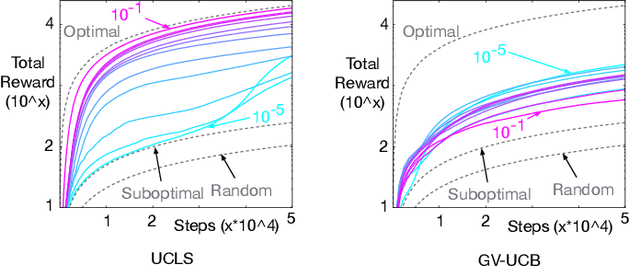
Directed exploration strategies for reinforcement learning are critical for learning an optimal policy in a minimal number of interactions with the environment. Many algorithms use optimism to direct exploration, either through visitation estimates or upper confidence bounds, as opposed to data-inefficient strategies like \epsilon-greedy that use random, undirected exploration. Most data-efficient exploration methods require significant computation, typically relying on a learned model to guide exploration. Least-squares methods have the potential to provide some of the data-efficiency benefits of model-based approaches -- because they summarize past interactions -- with the computation closer to that of model-free approaches. In this work, we provide a novel, computationally efficient, incremental exploration strategy, leveraging this property of least-squares temporal difference learning (LSTD). We derive upper confidence bounds on the action-values learned by LSTD, with context-dependent (or state-dependent) noise variance. Such context-dependent noise focuses exploration on a subset of variable states, and allows for reduced exploration in other states. We empirically demonstrate that our algorithm can converge more quickly than other incremental exploration strategies using confidence estimates on action-values.
The Utility of Sparse Representations for Control in Reinforcement Learning
Nov 15, 2018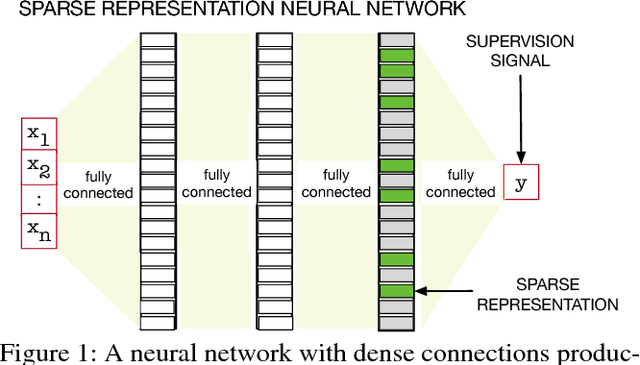
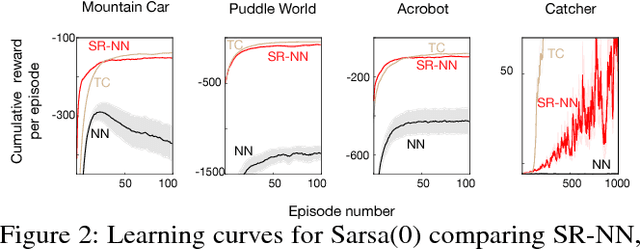
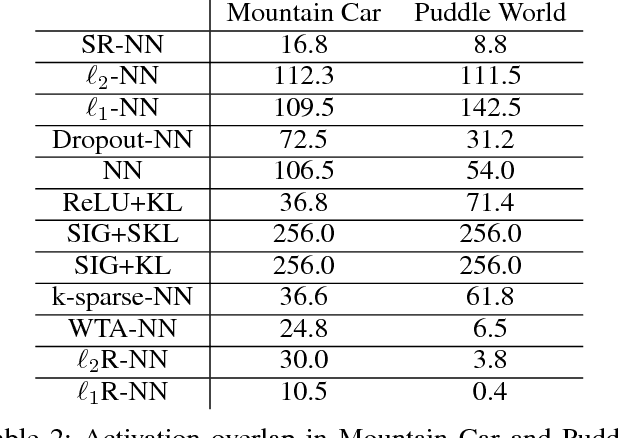
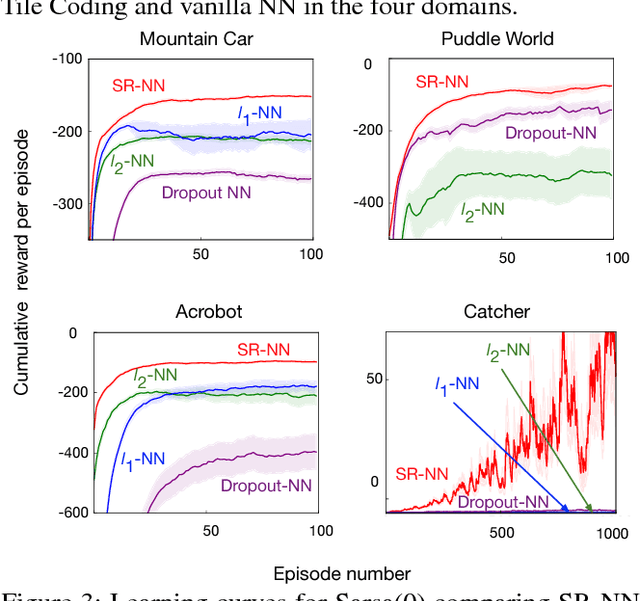
We investigate sparse representations for control in reinforcement learning. While these representations are widely used in computer vision, their prevalence in reinforcement learning is limited to sparse coding where extracting representations for new data can be computationally intensive. Here, we begin by demonstrating that learning a control policy incrementally with a representation from a standard neural network fails in classic control domains, whereas learning with a representation obtained from a neural network that has sparsity properties enforced is effective. We provide evidence that the reason for this is that the sparse representation provides locality, and so avoids catastrophic interference, and particularly keeps consistent, stable values for bootstrapping. We then discuss how to learn such sparse representations. We explore the idea of Distributional Regularizers, where the activation of hidden nodes is encouraged to match a particular distribution that results in sparse activation across time. We identify a simple but effective way to obtain sparse representations, not afforded by previously proposed strategies, making it more practical for further investigation into sparse representations for reinforcement learning.
Online Off-policy Prediction
Nov 06, 2018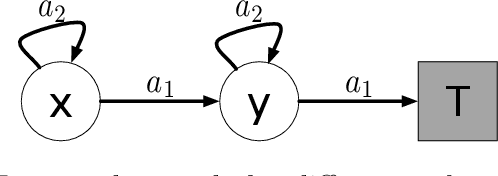
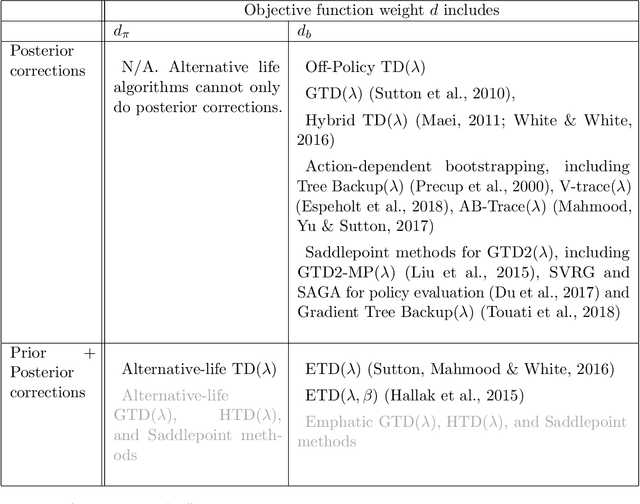

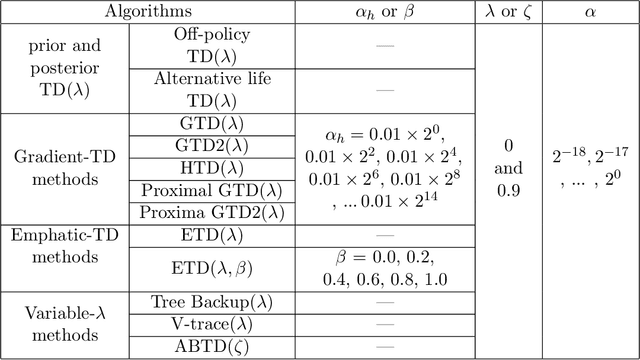
This paper investigates the problem of online prediction learning, where learning proceeds continuously as the agent interacts with an environment. The predictions made by the agent are contingent on a particular way of behaving, represented as a value function. However, the behavior used to select actions and generate the behavior data might be different from the one used to define the predictions, and thus the samples are generated off-policy. The ability to learn behavior-contingent predictions online and off-policy has long been advocated as a key capability of predictive-knowledge learning systems but remained an open algorithmic challenge for decades. The issue lies with the temporal difference (TD) learning update at the heart of most prediction algorithms: combining bootstrapping, off-policy sampling and function approximation may cause the value estimate to diverge. A breakthrough came with the development of a new objective function that admitted stochastic gradient descent variants of TD. Since then, many sound online off-policy prediction algorithms have been developed, but there has been limited empirical work investigating the relative merits of all the variants. This paper aims to fill these empirical gaps and provide clarity on the key ideas behind each method. We summarize the large body of literature on off-policy learning, focusing on 1- methods that use computation linear in the number of features and are convergent under off-policy sampling, and 2- other methods which have proven useful with non-fixed, nonlinear function approximation. We provide an empirical study of off-policy prediction methods in two challenging microworlds. We report each method's parameter sensitivity, empirical convergence rate, and final performance, providing new insights that should enable practitioners to successfully extend these new methods to large-scale applications.[Abridged abstract]
Actor-Expert: A Framework for using Action-Value Methods in Continuous Action Spaces
Oct 22, 2018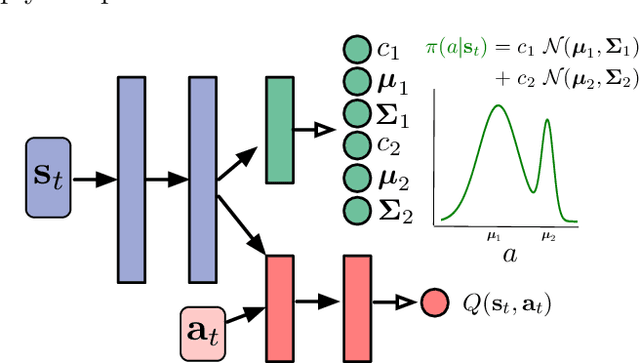

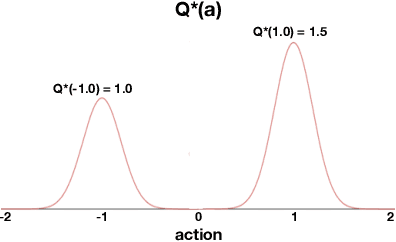
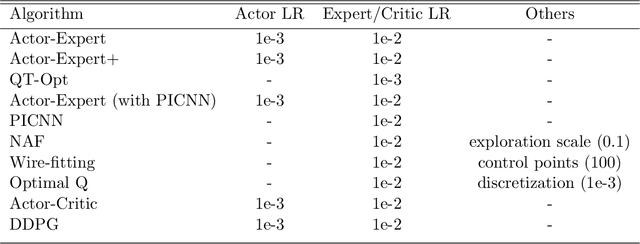
Value-based approaches can be difficult to use in continuous action spaces, because an optimization has to be solved to find the greedy action for the action-values. A common strategy has been to restrict the functional form of the action-values to be convex or quadratic in the actions, to simplify this optimization. Such restrictions, however, can prevent learning accurate action-values. In this work, we propose the Actor-Expert framework for value-based methods, that decouples action-selection (Actor) from the action-value representation (Expert). The Expert uses Q-learning to update the action-values towards the optimal action-values, whereas the Actor (learns to) output the greedy action for the current action-values. We develop a Conditional Cross Entropy Method for the Actor, to learn the greedy action for a generically parameterized Expert, and provide a two-timescale analysis to validate asymptotic behavior. We demonstrate in a toy domain with bimodal action-values that previous restrictive action-value methods fail whereas the decoupled Actor-Expert with a more general action-value parameterization succeeds. Finally, we demonstrate that Actor-Expert performs as well as or better than these other methods on several benchmark continuous-action domains.
High-confidence error estimates for learned value functions
Aug 28, 2018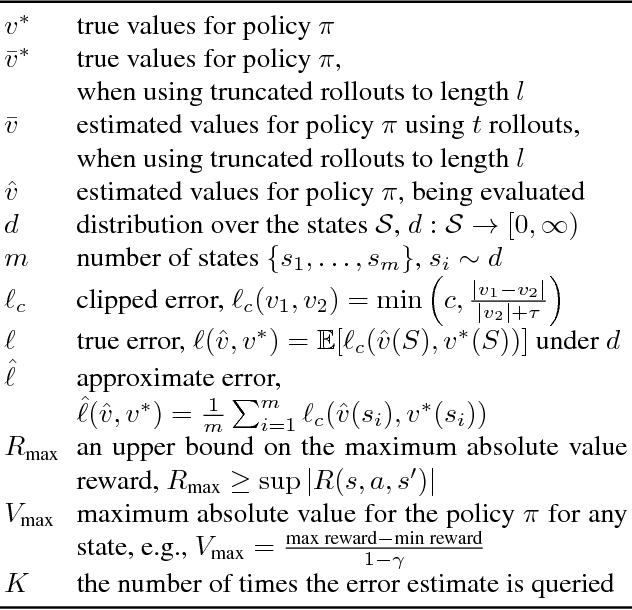
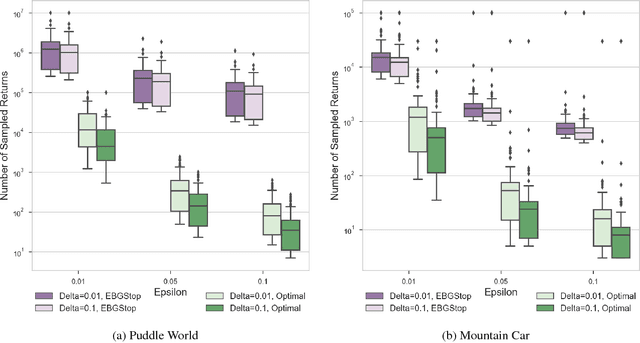
Estimating the value function for a fixed policy is a fundamental problem in reinforcement learning. Policy evaluation algorithms---to estimate value functions---continue to be developed, to improve convergence rates, improve stability and handle variability, particularly for off-policy learning. To understand the properties of these algorithms, the experimenter needs high-confidence estimates of the accuracy of the learned value functions. For environments with small, finite state-spaces, like chains, the true value function can be easily computed, to compute accuracy. For large, or continuous state-spaces, however, this is no longer feasible. In this paper, we address the largely open problem of how to obtain these high-confidence estimates, for general state-spaces. We provide a high-confidence bound on an empirical estimate of the value error to the true value error. We use this bound to design an offline sampling algorithm, which stores the required quantities to repeatedly compute value error estimates for any learned value function. We provide experiments investigating the number of samples required by this offline algorithm in simple benchmark reinforcement learning domains, and highlight that there are still many open questions to be solved for this important problem.
General Value Function Networks
Jul 18, 2018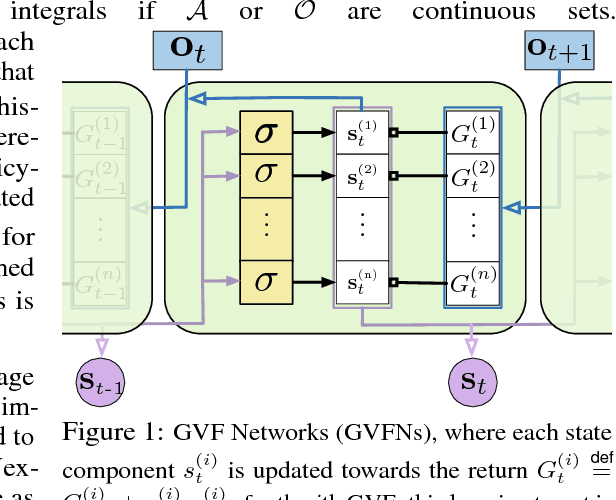
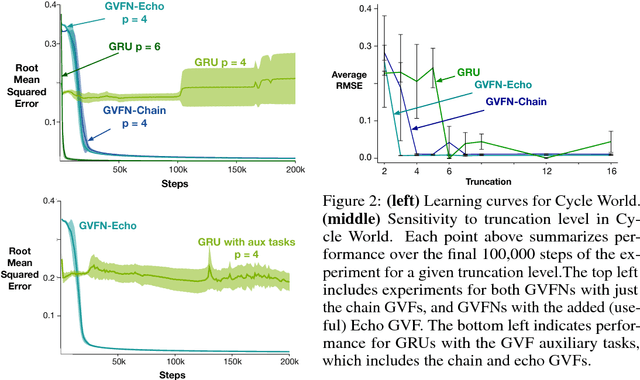
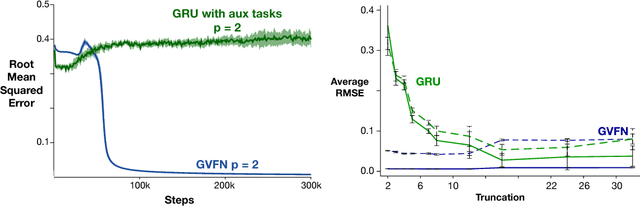
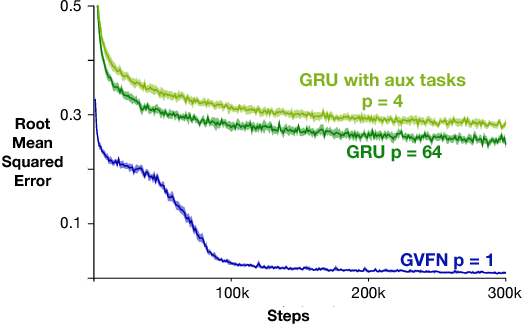
In this paper we show that restricting the representation-layer of a Recurrent Neural Network (RNN) improves accuracy and reduces the depth of recursive training procedures in partially observable domains. Artificial Neural Networks have been shown to learn useful state representations for high-dimensional visual and continuous control domains. If the the tasks at hand exhibits long depends back in time, these instantaneous feed-forward approaches are augmented with recurrent connections and trained with Back-prop Through Time (BPTT). This unrolled training can become computationally prohibitive if the dependency structure is long, and while recent work on LSTMs and GRUs has improved upon naive training strategies, there is still room for improvements in computational efficiency and parameter sensitivity. In this paper we explore a simple modification to the classic RNN structure: restricting the state to be comprised of multi-step General Value Function predictions. We formulate an architecture called General Value Function Networks (GVFNs), and corresponding objective that generalizes beyond previous approaches. We show that our GVFNs are significantly more robust to train, and facilitate accurate prediction with no gradients needed back-in-time in domains with substantial long-term dependences.
Reinforcement Learning with Function-Valued Action Spaces for Partial Differential Equation Control
Jun 13, 2018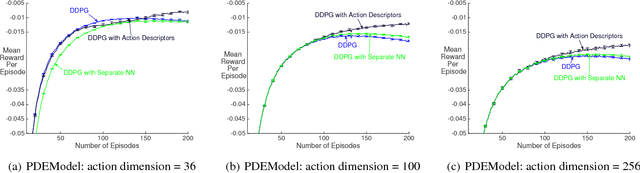
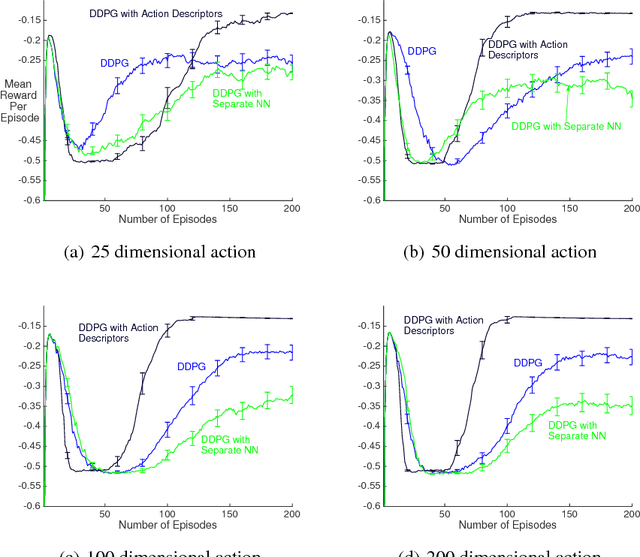
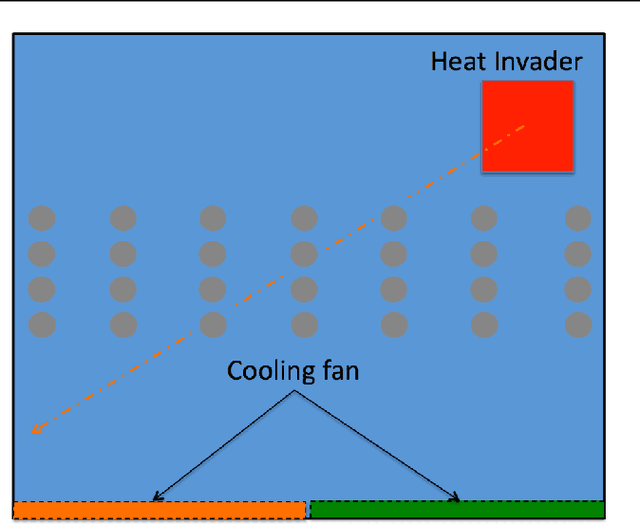
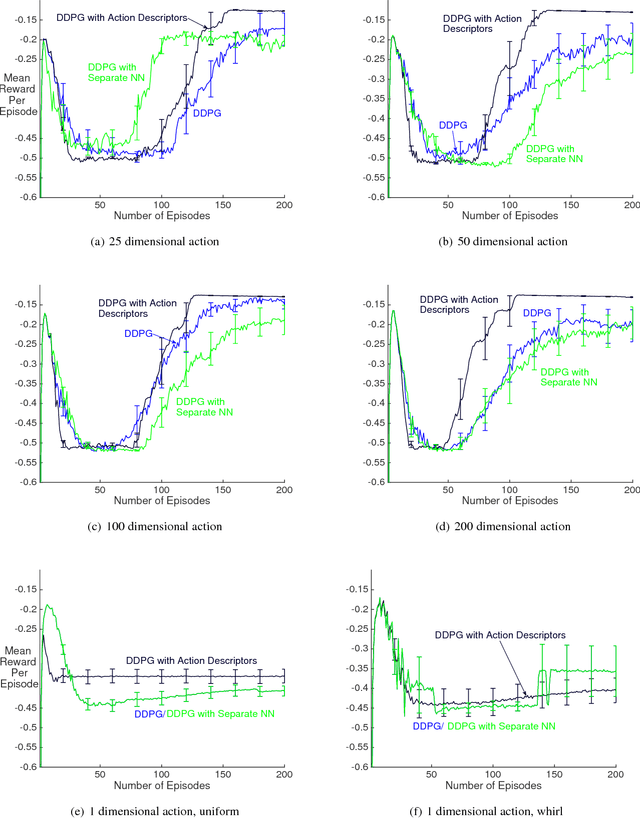
Recent work has shown that reinforcement learning (RL) is a promising approach to control dynamical systems described by partial differential equations (PDE). This paper shows how to use RL to tackle more general PDE control problems that have continuous high-dimensional action spaces with spatial relationship among action dimensions. In particular, we propose the concept of action descriptors, which encode regularities among spatially-extended action dimensions and enable the agent to control high-dimensional action PDEs. We provide theoretical evidence suggesting that this approach can be more sample efficient compared to a conventional approach that treats each action dimension separately and does not explicitly exploit the spatial regularity of the action space. The action descriptor approach is then used within the deep deterministic policy gradient algorithm. Experiments on two PDE control problems, with up to 256-dimensional continuous actions, show the advantage of the proposed approach over the conventional one.