 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking in Optimization: Best Practice and Open Issues
Jul 07, 2020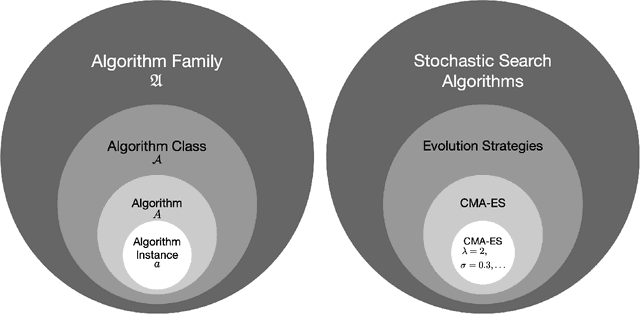
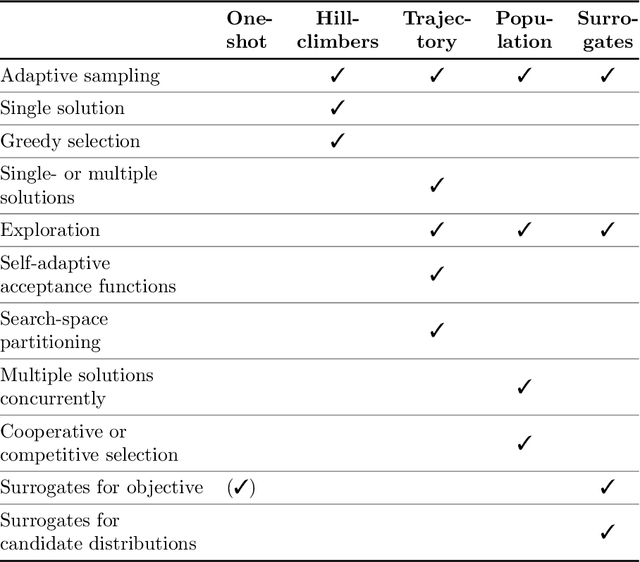
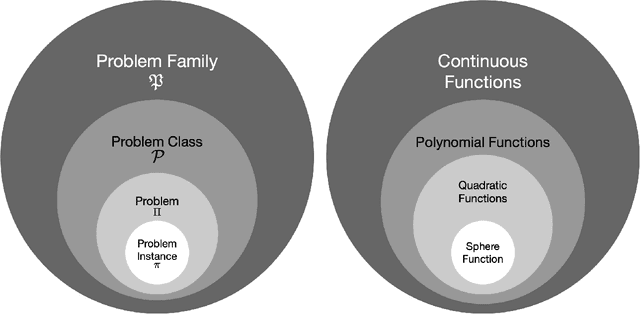

This survey compiles ideas and recommendations from more than a dozen researchers with different backgrounds and from different institutes around the world. Promoting best practice in benchmarking is its main goal. The article discusses eight essential topics in benchmarking: clearly stated goals, well-specified problems, suitable algorithms, adequate performance measures, thoughtful analysis, effective and efficient designs, comprehensible presentations, and guaranteed reproducibility. The final goal is to provide well-accepted guidelines (rules) that might be useful for authors and reviewers. As benchmarking in optimization is an active and evolving field of research this manuscript is meant to co-evolve over time by means of periodic updates.
The Dynamic Travelling Thief Problem: Benchmarks and Performance of Evolutionary Algorithms
May 10, 2020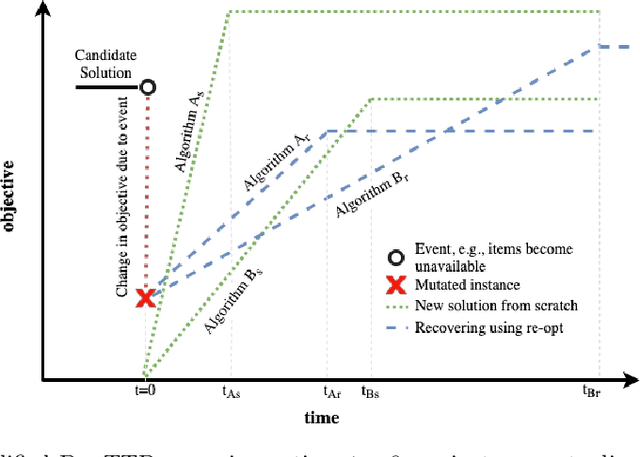
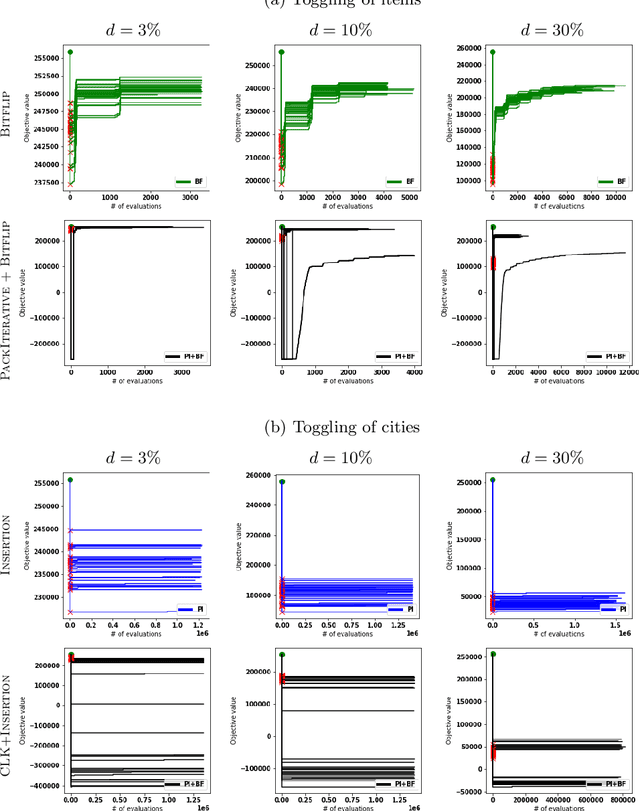
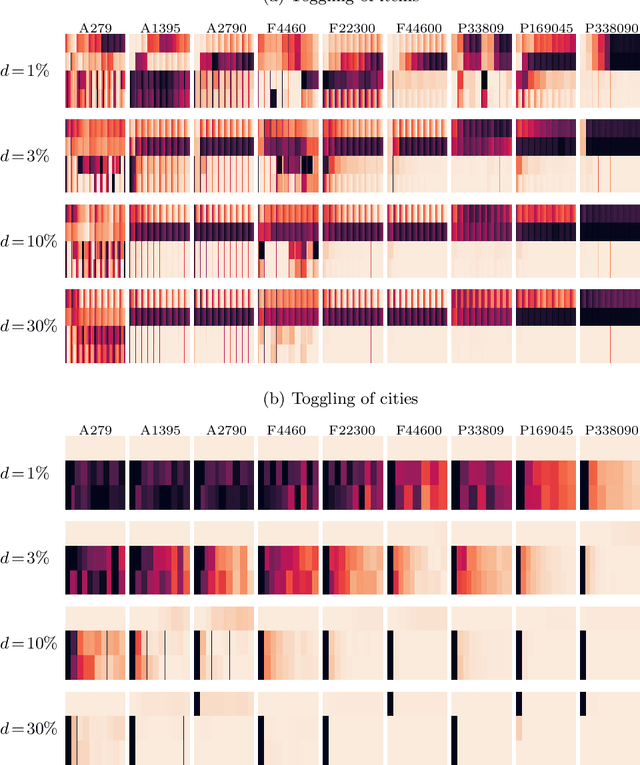
Many real-world optimisation problems involve dynamic and stochastic components. While problems with multiple interacting components are omnipresent in inherently dynamic domains like supply-chain optimisation and logistics, most research on dynamic problems focuses on single-component problems. With this article, we define a number of scenarios based on the Travelling Thief Problem to enable research on the effect of dynamic changes to sub-components. Our investigations of 72 scenarios and seven algorithms show that -- depending on the instance, the magnitude of the change, and the algorithms in the portfolio -- it is preferable to either restart the optimisation from scratch or to continue with the previously valid solutions.
An Annotated Dataset of Stack Overflow Post Edits
May 06, 2020
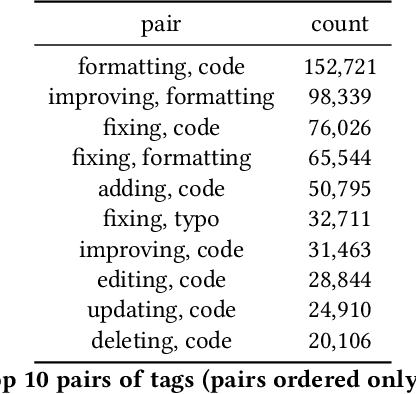
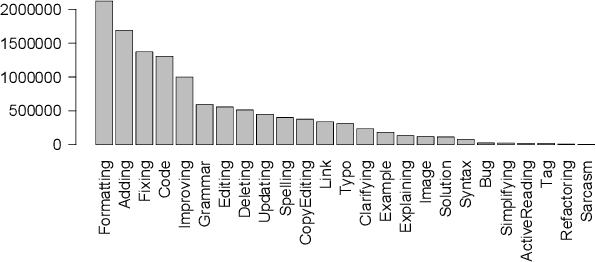
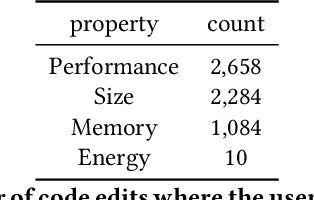
To improve software engineering, software repositories have been mined for code snippets and bug fixes. Typically, this mining takes place at the level of files or commits. To be able to dig deeper and to extract insights at a higher resolution, we hereby present an annotated dataset that contains over 7 million edits of code and text on Stack Overflow. Our preliminary study indicates that these edits might be a treasure trove for mining information about fine-grained patches, e.g., for the optimisation of non-functional properties.
Fitness Landscape Analysis of Dimensionally-Aware Genetic Programming Featuring Feynman Equations
Apr 27, 2020



Genetic programming is an often-used technique for symbolic regression: finding symbolic expressions that match data from an unknown function. To make the symbolic regression more efficient, one can also use dimensionally-aware genetic programming that constrains the physical units of the equation. Nevertheless, there is no formal analysis of how much dimensionality awareness helps in the regression process. In this paper, we conduct a fitness landscape analysis of dimensionallyaware genetic programming search spaces on a subset of equations from Richard Feynmans well-known lectures. We define an initialisation procedure and an accompanying set of neighbourhood operators for conducting the local search within the physical unit constraints. Our experiments show that the added information about the variable dimensionality can efficiently guide the search algorithm. Still, further analysis of the differences between the dimensionally-aware and standard genetic programming landscapes is needed to help in the design of efficient evolutionary operators to be used in a dimensionally-aware regression.
MATE: A Model-based Algorithm Tuning Engine
Apr 27, 2020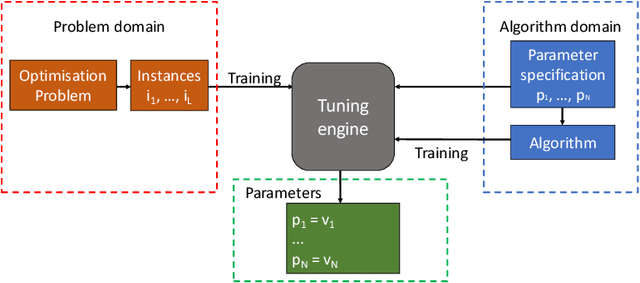
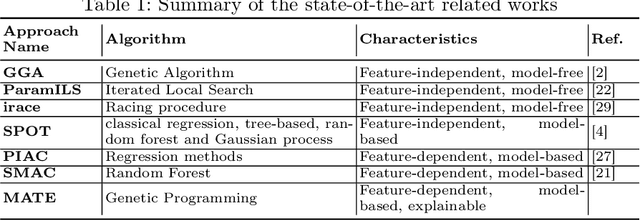
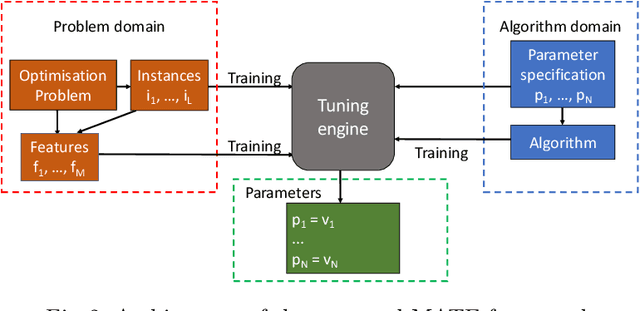
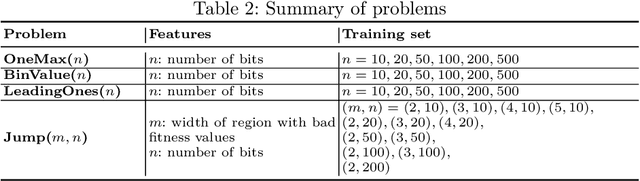
In this paper, we introduce a Model-based Algorithm Turning Engine, namely MATE, where the parameters of an algorithm are represented as expressions of the features of a target optimisation problem. In contrast to most static (feature-independent) algorithm tuning engines such as irace and SPOT, our approach aims to derive the best parameter configuration of a given algorithm for a specific problem, exploiting the relationships between the algorithm parameters and the features of the problem. We formulate the problem of finding the relationships between the parameters and the problem features as a symbolic regression problem and we use genetic programming to extract these expressions. For the evaluation, we apply our approach to configuration of the (1+1) EA and RLS algorithms for the OneMax, LeadingOnes, BinValue and Jump optimisation problems, where the theoretically optimal algorithm parameters to the problems are available as functions of the features of the problems. Our study shows that the found relationships typically comply with known theoretical results, thus demonstrating a new opportunity to consider model-based parameter tuning as an effective alternative to the static algorithm tuning engines.
Ants can orienteer a thief in their robbery
Apr 15, 2020
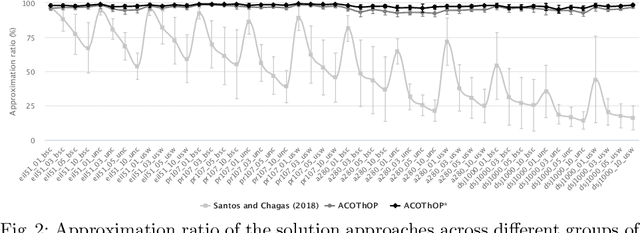
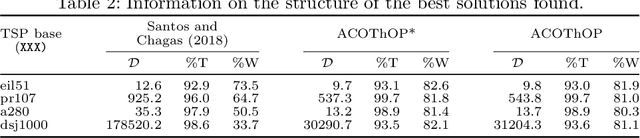
We address the Thief Orienteering Problem (ThOP), a multi-component problem that combines features of two classic combinatorial optimization problems, namely the Orienteering Problem and Knapsack Problem. Due to the given time constraint and the interaction of the load-dependent movement speed with the chosen route, the ThOP is complex and challenging. We propose a two-phase, swarm-intelligence based approach together with a new randomized packing heuristic. To identify the impact of the respective components, we use automated algorithm configuration. The resulting configurations outperform existing work on more than 90% of the benchmarking instances, with an average improvement of over 300%.
Hybrid Neuro-Evolutionary Method for Predicting Wind Turbine Power Output
Apr 02, 2020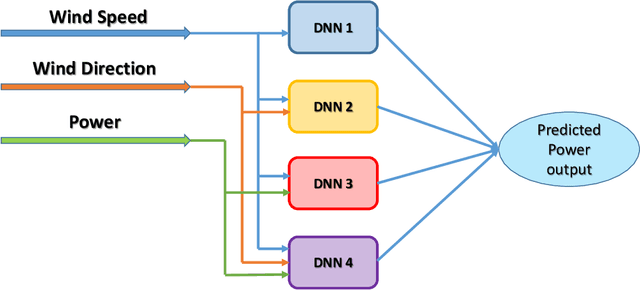

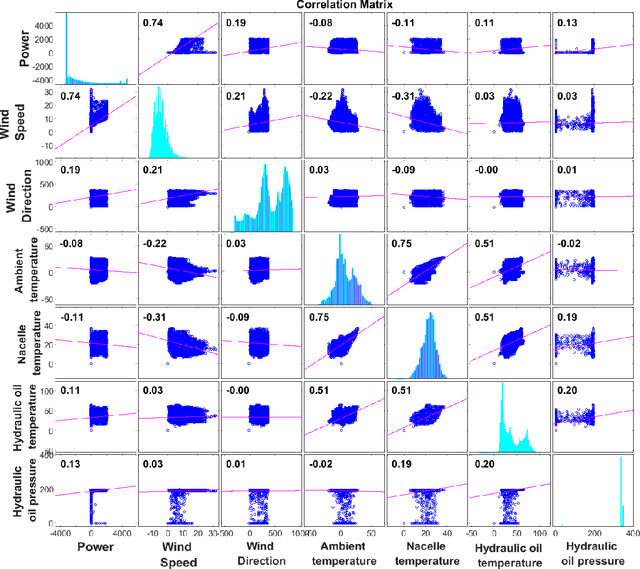
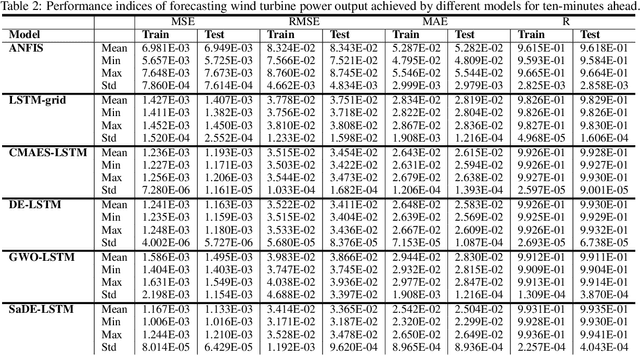
Reliable wind turbine power prediction is imperative to the planning, scheduling and control of wind energy farms for stable power production. In recent years Machine Learning (ML) methods have been successfully applied in a wide range of domains, including renewable energy. However, due to the challenging nature of power prediction in wind farms, current models are far short of the accuracy required by industry. In this paper, we deploy a composite ML approach--namely a hybrid neuro-evolutionary algorithm--for accurate forecasting of the power output in wind-turbine farms. We use historical data in the supervisory control and data acquisition (SCADA) systems as input to estimate the power output from an onshore wind farm in Sweden. At the beginning stage, the k-means clustering method and an Autoencoder are employed, respectively, to detect and filter noise in the SCADA measurements. Next, with the prior knowledge that the underlying wind patterns are highly non-linear and diverse, we combine a self-adaptive differential evolution (SaDE) algorithm as a hyper-parameter optimizer, and a recurrent neural network (RNN) called Long Short-term memory (LSTM) to model the power curve of a wind turbine in a farm. Two short time forecasting horizons, including ten-minutes ahead and one-hour ahead, are considered in our experiments. We show that our approach outperforms its counterparts.
Optimisation of Large Wave Farms using a Multi-strategy Evolutionary Framework
Mar 21, 2020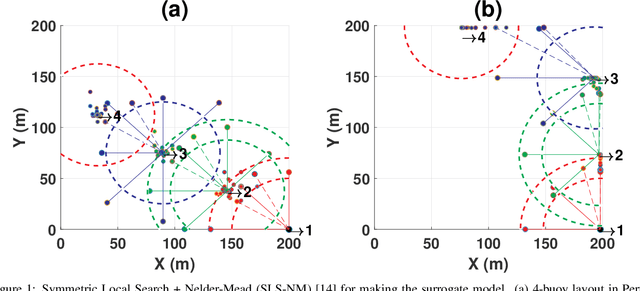
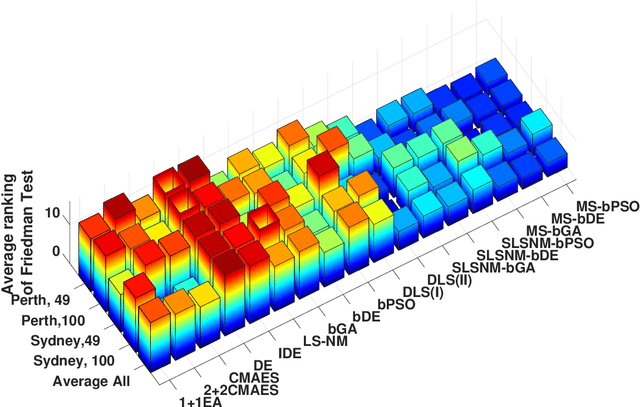
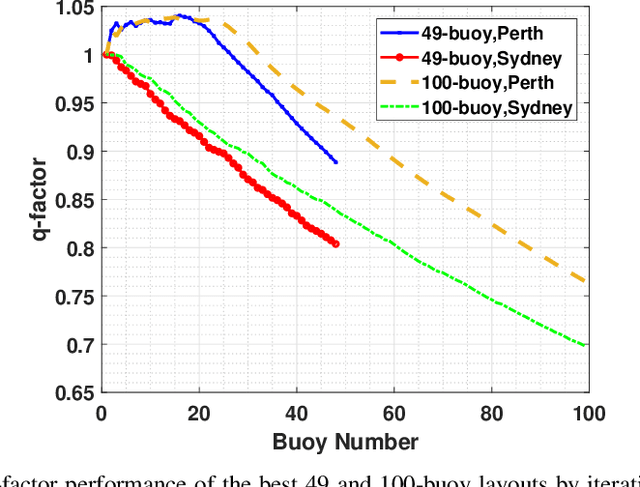
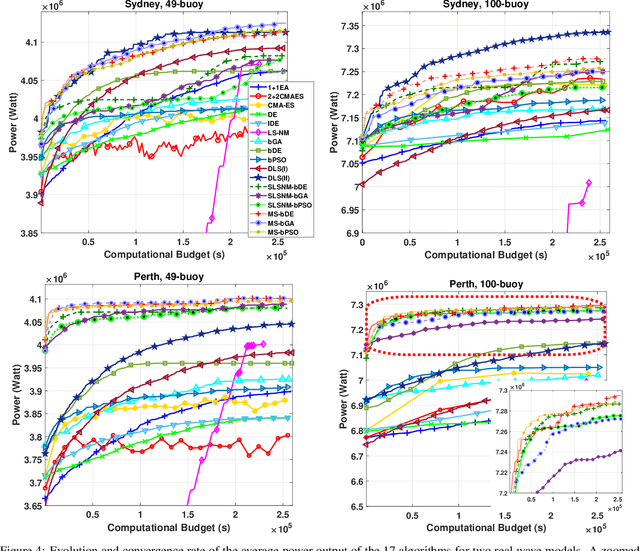
Wave energy is a fast-developing and promising renewable energy resource. The primary goal of this research is to maximise the total harnessed power of a large wave farm consisting of fully-submerged three-tether wave energy converters (WECs). Energy maximisation for large farms is a challenging search problem due to the costly calculations of the hydrodynamic interactions between WECs in a large wave farm and the high dimensionality of the search space. To address this problem, we propose a new hybrid multi-strategy evolutionary framework combining smart initialisation, binary population-based evolutionary algorithm, discrete local search and continuous global optimisation. For assessing the performance of the proposed hybrid method, we compare it with a wide variety of state-of-the-art optimisation approaches, including six continuous evolutionary algorithms, four discrete search techniques and three hybrid optimisation methods. The results show that the proposed method performs considerably better in terms of convergence speed and farm output.
An Evolutionary Deep Learning Method for Short-term Wind Speed Prediction: A Case Study of the Lillgrund Offshore Wind Farm
Feb 21, 2020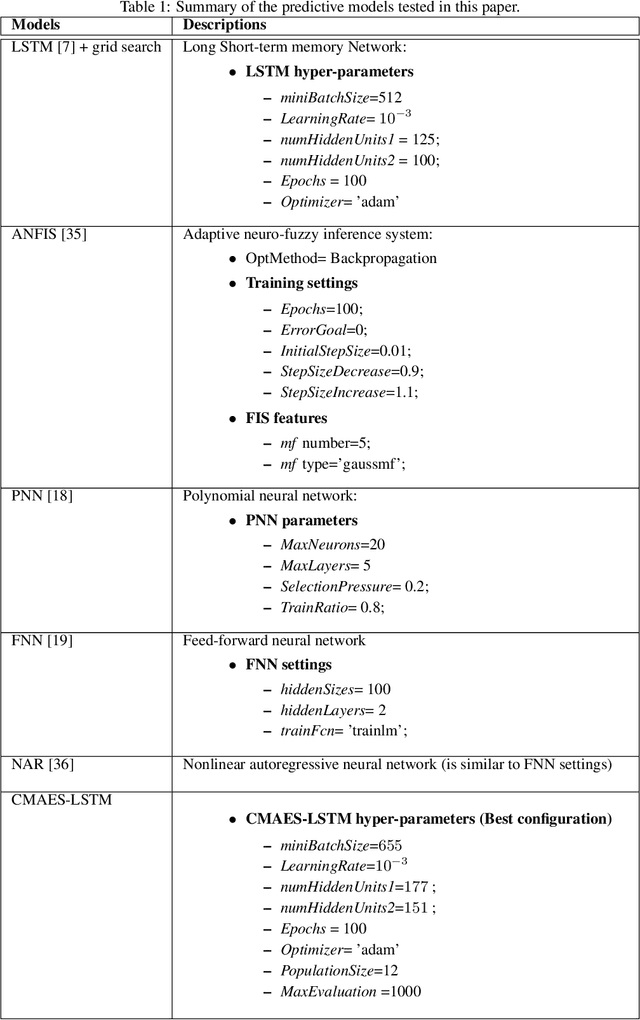
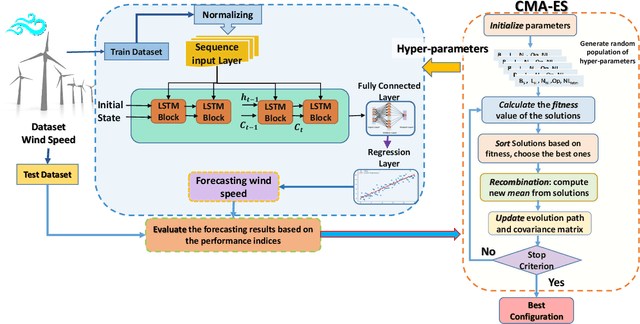
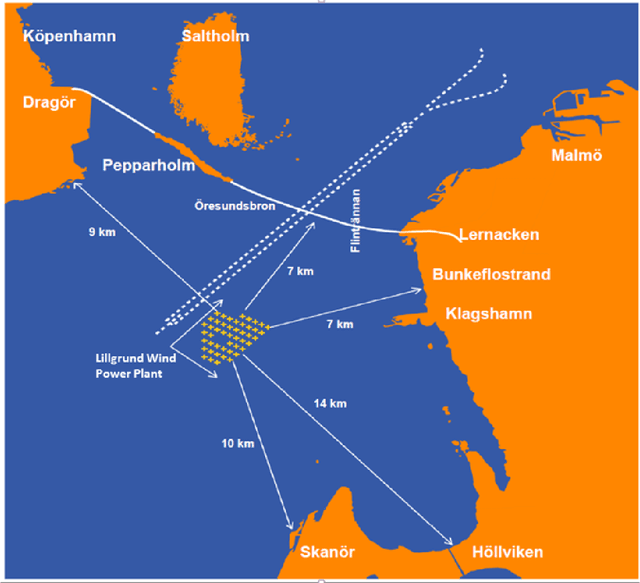
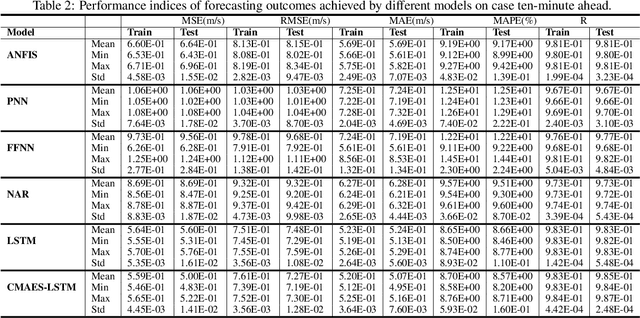
Accurate short-term wind speed forecasting is essential for large-scale integration of wind power generation. However, the seasonal and stochastic characteristics of wind speed make forecasting a challenging task. This study uses a new hybrid evolutionary approach that uses a popular evolutionary search algorithm, CMA-ES, to tune the hyper-parameters of two Long short-term memory(LSTM) ANN models for wind prediction. The proposed hybrid approach is trained on data gathered from an offshore wind turbine installed in a Swedish wind farm located in the Baltic Sea. Two forecasting horizons including ten-minutes ahead (absolute short term) and one-hour ahead (short term) are considered in our experiments. Our experimental results indicate that the new approach is superior to five other applied machine learning models, i.e., polynomial neural network (PNN), feed-forward neural network (FNN), nonlinear autoregressive neural network (NAR) and adaptive neuro-fuzzy inference system (ANFIS), as measured by five performance criteria.
A Non-Dominated Sorting Based Customized Random-Key Genetic Algorithm for the Bi-Objective Traveling Thief Problem
Feb 11, 2020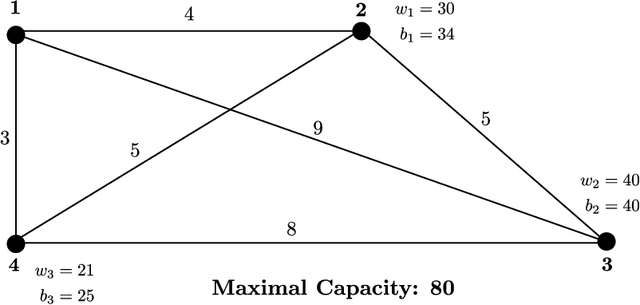

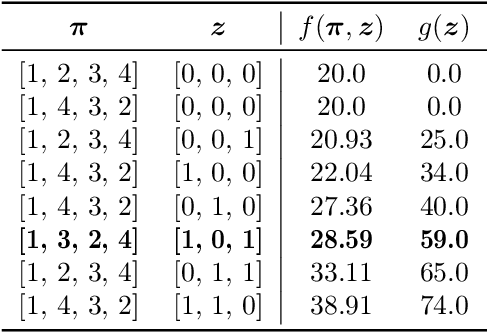
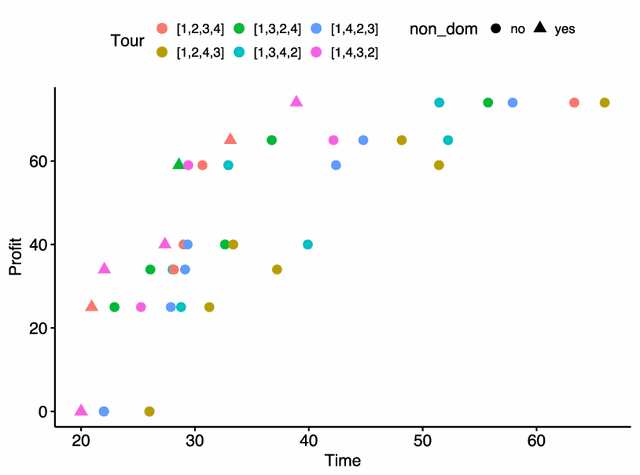
In this paper, we propose a method to solve a bi-objective variant of the well-studied Traveling Thief Problem (TTP). The TTP is a multi-component problem that combines two classic combinatorial problems: Traveling Salesman Problem (TSP) and Knapsack Problem (KP). In the TTP, a thief has to visit each city exactly once and can pick items throughout their journey. The thief begins their journey with an empty knapsack and travels with a speed inversely proportional to the knapsack weight. We address the BI-TTP, a bi-objective version of the TTP, where the goal is to minimize the overall traveling time and to maximize the profit of the collected items. Our method is based on a genetic algorithm with customization addressing problem characteristics. We incorporate domain knowledge through a combination of near-optimal solutions of each subproblem in the initial population and a custom repair operation to avoid the evaluation of infeasible solutions. Moreover, the independent variables of the TSP and KP components are unified to a real variable representation by using a biased random-key approach. The bi-objective aspect of the problem is addressed through an elite population extracted based on the non-dominated rank and crowding distance of each solution. Furthermore, we provide a comprehensive study which shows the influence of hyperparameters on the performance of our method and investigate the performance of each hyperparameter combination over time. In addition to our experiments, we discuss the results of the BI-TTP competitions at EMO-2019 and GECCO-2019 conferences where our method has won first and second place, respectively, thus proving its ability to find high-quality solutions consistently.