 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Students' Java Programming Errors with Large Language Models
Jun 12, 2026Understanding student errors in the programming is a cornerstone of programming education, yet obtaining a representative set of student errors for any newly designed task remains slow and costly, since authentic submissions only accumulate after extensive classroom deployment. This paper explores whether large language models (LLMs) can serve as scalable proxies for students by simulating realistic logical errors in code submissions. Using the CodeWorkout dataset of 74,000+ unique student Java submissions across 37 problems, we evaluate five LLMs under three mainstream prompting strategies: Input-Output (IO), Chain-of-Thought (CoT), and iterative Self-Refine. We assess performance along two key dimensions: diversity (the range of distinct error patterns) and alignment (alignment with authentic student mistakes), and examine how these vary by struggling level of programming tasks. Our quantitative findings reveal that while all models generate diverse errors, their alignment to human submissions diverges: Claude Sonnet 4 achieves the most balanced performance. In addition, we conducted a blinded expert annotation study (N = 401) comparing synthetic and authentic errors. This qualitative analysis confirms that the generated errors are functionally indistinguishable from authentic student errors. Moreover, higher-struggling-level problems elicit more diverse but less student-like errors. These results highlight trade-offs in using LLMs to simulate human learners and suggest design considerations for integrating synthetic errors into teachable agents, intelligent tutoring systems, and large-scale learning analytics.
The Order Matters: Sequential Fine-Tuning of LLaMA for Coherent Automated Essay Scoring
Jun 09, 2026Automated Essay Scoring (AES) systems must judge interdependent discourse elements (e.g., lead, claim, evidence, conclusion), yet most approaches treat these in isolation, harming coherence and generalization. We investigate task-aware fine-tuning of LLaMA-3.1-8B for AES using parameter-efficient LoRA with 4-bit quantization and compare three training curricula: (i) Sequential (progressively fine-tuning on lead, then position, then claim, then evidence, then conclusion), (ii) Independent (task-specific models), and (iii) Randomized (shuffled multi-task). Experiments on the PERSUADE~2.0 corpus show that modeling task dependencies matters: Sequential fine-tuning yields the strongest overall results, including F1 scores of 65% (evidence) and 87% (conclusion) and corresponding accuracies of 63% and 85%, surpassing Independent training and outperforming a general-purpose LLaMA-70B baseline on conclusion despite its far larger capacity. Randomized training improves position scoring (57% F1) but is less consistent elsewhere. These findings indicate that (1) curriculum design aligned with discourse structure can materially improve AES, and (2) small, task-optimized models can be competitive with substantially larger Large Language Models (LLM), offering a practical path to scalable, cost-effective assessment. We release templates and implementation details to facilitate reproduction and future work on curriculum design for educational NLP.
Early-Token Confidence Predicts Reasoning Quality in Multi-Agent LLM Debate
Jun 09, 2026Evaluating reasoning quality in multi-agent LLM systems is challenging, especially for open-ended tasks without reference answers. We investigate whether intrinsic confidence signals, token-level log-probabilities from decoding, can predict reasoning quality as assessed by LLM-as-judge evaluation. Using a debate-based essay scoring framework, we compare confidence proxies against rubric-based judge scores across two ASAP essay sets. We find that early-token confidence, particularly within the first few generated tokens, is consistently the strongest predictor of reasoning quality, outperforming full-sequence statistics. Analysis of log-probability trajectories shows that the opening phase of generation is the most heterogeneous and therefore most informative. We also observe a systematic asymmetry between agent roles, with stronger alignment between confidence and quality for supportive reasoning than for adversarial critique. These results suggest that early decoding dynamics provide a lightweight and effective signal for estimating reasoning reliability in multi-agent LLM systems.
The Confident Liar: Diagnosing Multi-Agent Debate with Log-Probabilities and LLM-as-Judge
Jun 09, 2026Multi-agent debate systems are typically evaluated only on whether the final answer is correct, overlooking the quality of the intermediate reasoning that debate is designed to produce. This paper studies the relationship between three signals in multi-agent debate: token-level log-probability distributions over reasoning tokens, LLM-as-judge rubric scores assigned to those tokens, and final task accuracy. We examine whether internal confidence signals predict externally evaluated reasoning quality, and whether either signal aligns with task correctness, across three domains: rubric-based scoring, mathematical reasoning, and factual question answering. Our framework pairs a two-agent debate architecture -- a Constructor and an Auditor -- with an LLM-as-judge that scores each agent's reasoning along instruction following, justification quality, and evidence grounding, together with a critical-failure flag. Experiments in the rubric-scoring domain reveal a consistent four-phase confidence trajectory and a substantial role asymmetry: confidence aligns with judged reasoning quality roughly twice as strongly for the Constructor as for the Auditor, and confidence-based detection of critical reasoning failures is markedly more reliable for the Constructor (AUROC 0.804) than for the Auditor (0.634). These findings motivate the broader cross-domain investigation proposed in this paper.
MADRAG: Multi-Agent Debate with Retrieval-Augmented Generation for Training-Free Analytic Essay Scoring
Jun 04, 2026We present MADRAG, a training-free framework for analytic essay scoring that combines multi-agent reasoning with retrieval-augmented grounding. Unlike standard LLM-as-judge approaches, which are prone to bias and unstable scoring, MADRAG decomposes evaluation into an interactive process: an Advocate identifies strengths, a Skeptic critiques weaknesses, and a Judge aggregates their arguments into a final score. Crucially, the Judge is augmented with rubric-aligned exemplar retrieval, enabling calibration through comparison with scored examples. Our results show that MADRAG significantly outperforms prompt-based baselines while approaching the performance of supervised systems without requiring task-specific training. Ablation studies demonstrate that retrieval drives calibration gains, while debate improves reasoning on higher-level traits. Our findings highlight the complementary roles of structured interaction and external memory in reliable LLM-based evaluation.
Emergent AI-Assisted Discourse: Case Study of a Second Language Writer Authoring with ChatGPT
Oct 23, 2023The rapid proliferation of ChatGPT has incited debates regarding its impact on human writing. Amid concerns about declining writing standards, this study investigates the role of ChatGPT in facilitating academic writing, especially among language learners. Using a case study approach, this study examines the experiences of Kailing, a doctoral student, who integrates ChatGPT throughout their academic writing process. The study employs activity theory as a lens for understanding writing with generative AI tools and data analyzed includes semi-structured interviews, writing samples, and GPT logs. Results indicate that Kailing effectively collaborates with ChatGPT across various writing stages while preserving her distinct authorial voice and agency. This underscores the potential of AI tools such as ChatGPT to enhance academic writing for language learners without overshadowing individual authenticity. This case study offers a critical exploration of how ChatGPT is utilized in the academic writing process and the preservation of a student's authentic voice when engaging with the tool.
Fantastic Questions and Where to Find Them: FairytaleQA -- An Authentic Dataset for Narrative Comprehension
Mar 26, 2022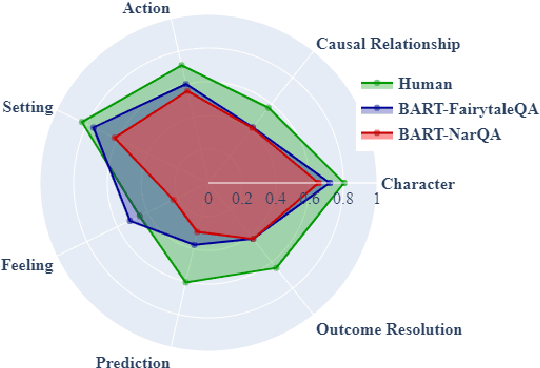
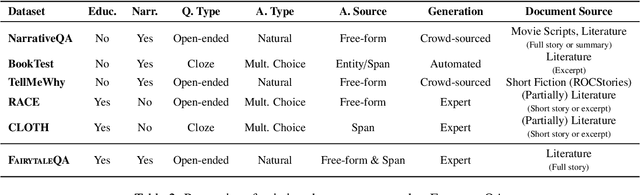
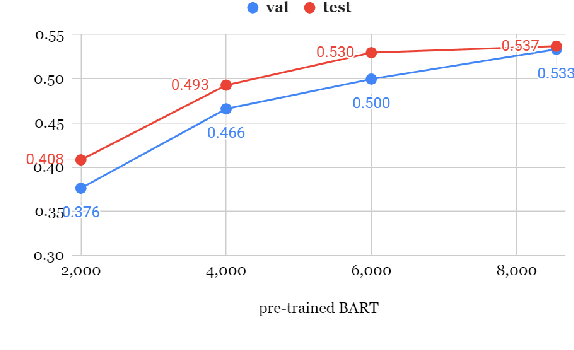
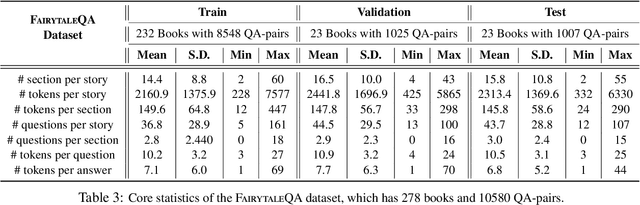
Question answering (QA) is a fundamental means to facilitate assessment and training of narrative comprehension skills for both machines and young children, yet there is scarcity of high-quality QA datasets carefully designed to serve this purpose. In particular, existing datasets rarely distinguish fine-grained reading skills, such as the understanding of varying narrative elements. Drawing on the reading education research, we introduce FairytaleQA, a dataset focusing on narrative comprehension of kindergarten to eighth-grade students. Generated by educational experts based on an evidence-based theoretical framework, FairytaleQA consists of 10,580 explicit and implicit questions derived from 278 children-friendly stories, covering seven types of narrative elements or relations. Our dataset is valuable in two folds: First, we ran existing QA models on our dataset and confirmed that this annotation helps assess models' fine-grained learning skills. Second, the dataset supports question generation (QG) task in the education domain. Through benchmarking with QG models, we show that the QG model trained on FairytaleQA is capable of asking high-quality and more diverse questions.