 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngiAI: A Multi-Agent Framework and Benchmark Suite for LLM-Driven Engineering Design
May 19, 2026Large Language Model (LLM) agents are increasingly applied to engineering design tasks, yet existing evaluation frameworks do not adequately address multi-agent systems that combine simulation, retrieval, and manufacturing preparation. We introduce a benchmark suite with three evaluation dimensions: (1) a workflow benchmark with seven prompt styles targeting distinct cognitive demands-including direct tool use, semantic disambiguation, conditional branching, and working-memory tasks; (2) a Retrieval-Augmented Generation (RAG) benchmark with gated scoring isolating retrieval contributions to parameter selection; and (3) an High Performance Computing (HPC) benchmark evaluating end-to-end ML training orchestration on a SLURM cluster. Alongside the benchmark we present EngiAI, a Multi-Agent System (MAS) reference implementation built on LangGraph that operationalizes the benchmark by coordinating seven specialized agents through a supervisor architecture, unifying topology optimization, document retrieval, HPC job orchestration, and 3D printer control. Across four LLM backends and two EngiBench problems, proprietary models achieve 96-97% average task completion on Beams2D, while open-source 4B-parameter models reach 55-78%, with clear generational improvement. Conditional branching proves most challenging, with task completion dropping to 20-53% for the conditional style on Photonics2D. RAG gating confirms near-perfect retrieval-augmented scores ($\approx 1.0$) versus near-zero without retrieval, validating the evaluation design. On HPC orchestration, one model completes all pipeline steps in 100% of runs while another drops to 50%, revealing that multi-step instruction following degrades over long-running workflows.
Beyond Inference-Time Search: Reinforcement Learning Synthesizes Reusable Solvers
May 18, 2026Large language models (LLMs) typically approach combinatorial optimization as an inference-time procedure, solving each instance separately through sampling, search, or repeated prompting. We ask whether reinforcement learning can instead shift part of this reasoning cost into the weights of a code LLM, so that the model synthesizes a reusable solver for an entire problem family. We study this question on Synergistic Dependency Selection (SDS), a controlled variant of constrained Quadratic Knapsack designed to expose a specific failure mode: local signals and strict feasibility constraints make greedy heuristics attractive but unreliable. Under identical scaffolding, Best-of-64 base-model sampling saturates at an approximately 28.7% gap to the global Virtual Best Solver (VBS); code audits show that the base model often retrieves Simulated Annealing templates but misimplements the Metropolis acceptance rule. We fine-tune Qwen2.5-Coder-14B-Instruct with Group Relative Policy Optimization (GRPO) using a feasibility-gated reward and light structural scaffolding. The resulting policy converges to a constraint-aware Simulated Annealing template in 99.8% of feasible SDS outputs, achieves a 5.0% gap to that VBS, and is 91 times cheaper in post-generation execution/search cost than cumulative Best-of-64 evaluation. A compile-once check shows that one best frozen solver per seed remains highly competitive when reused unchanged across the SDS test set, while an additional-domain evaluation on Job Shop Scheduling provides narrower but positive evidence that the scaffold transfers beyond SDS. Negative ablations reveal the limits of this recipe: standard stabilizers degrade performance, a soft feasibility gate fails, and results remain sensitive to reward normalization and domain-specific design choices.
Autonomous Soft Robotic Guidewire Navigation via Imitation Learning
Oct 10, 2025In endovascular surgery, endovascular interventionists push a thin tube called a catheter, guided by a thin wire to a treatment site inside the patient's blood vessels to treat various conditions such as blood clots, aneurysms, and malformations. Guidewires with robotic tips can enhance maneuverability, but they present challenges in modeling and control. Automation of soft robotic guidewire navigation has the potential to overcome these challenges, increasing the precision and safety of endovascular navigation. In other surgical domains, end-to-end imitation learning has shown promising results. Thus, we develop a transformer-based imitation learning framework with goal conditioning, relative action outputs, and automatic contrast dye injections to enable generalizable soft robotic guidewire navigation in an aneurysm targeting task. We train the model on 36 different modular bifurcated geometries, generating 647 total demonstrations under simulated fluoroscopy, and evaluate it on three previously unseen vascular geometries. The model can autonomously drive the tip of the robot to the aneurysm location with a success rate of 83% on the unseen geometries, outperforming several baselines. In addition, we present ablation and baseline studies to evaluate the effectiveness of each design and data collection choice. Project website: https://softrobotnavigation.github.io/
Inverse design with conditional cascaded diffusion models
Aug 16, 2024Adjoint-based design optimizations are usually computationally expensive and those costs scale with resolution. To address this, researchers have proposed machine learning approaches for inverse design that can predict higher-resolution solutions from lower cost/resolution ones. Due to the recent success of diffusion models over traditional generative models, we extend the use of diffusion models for multi-resolution tasks by proposing the conditional cascaded diffusion model (cCDM). Compared to GANs, cCDM is more stable to train, and each diffusion model within the cCDM can be trained independently, thus each model's parameters can be tuned separately to maximize the performance of the pipeline. Our study compares cCDM against a cGAN model with transfer learning. Our results demonstrate that the cCDM excels in capturing finer details, preserving volume fraction constraints, and minimizing compliance errors in multi-resolution tasks when a sufficient amount of high-resolution training data (more than 102 designs) is available. Furthermore, we explore the impact of training data size on the performance of both models. While both models show decreased performance with reduced high-resolution training data, the cCDM loses its superiority to the cGAN model with transfer learning when training data is limited (less than 102), and we show the break-even point for this transition. Also, we highlight that while the diffusion model may achieve better pixel-wise performance in both low-resolution and high-resolution scenarios, this does not necessarily guarantee that the model produces optimal compliance error or constraint satisfaction.
Bayesian Inverse Problems with Conditional Sinkhorn Generative Adversarial Networks in Least Volume Latent Spaces
May 22, 2024Solving inverse problems in scientific and engineering fields has long been intriguing and holds great potential for many applications, yet most techniques still struggle to address issues such as high dimensionality, nonlinearity and model uncertainty inherent in these problems. Recently, generative models such as Generative Adversarial Networks (GANs) have shown great potential in approximating complex high dimensional conditional distributions and have paved the way for characterizing posterior densities in Bayesian inverse problems, yet the problems' high dimensionality and high nonlinearity often impedes the model's training. In this paper we show how to tackle these issues with Least Volume--a novel unsupervised nonlinear dimension reduction method--that can learn to represent the given datasets with the minimum number of latent variables while estimating their intrinsic dimensions. Once the low dimensional latent spaces are identified, efficient and accurate training of conditional generative models becomes feasible, resulting in a latent conditional GAN framework for posterior inference. We demonstrate the power of the proposed methodology on a variety of applications including inversion of parameters in systems of ODEs and high dimensional hydraulic conductivities in subsurface flow problems, and reveal the impact of the observables' and unobservables' intrinsic dimensions on inverse problems.
Compressing Latent Space via Least Volume
Apr 27, 2024



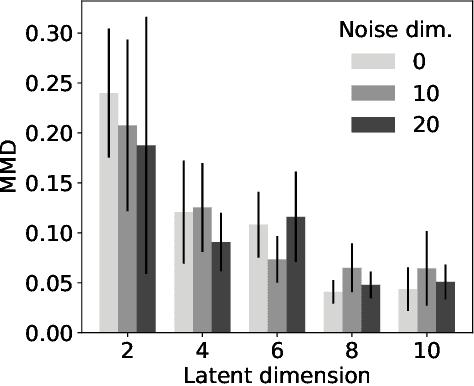
This paper introduces Least Volume-a simple yet effective regularization inspired by geometric intuition-that can reduce the necessary number of latent dimensions needed by an autoencoder without requiring any prior knowledge of the intrinsic dimensionality of the dataset. We show that the Lipschitz continuity of the decoder is the key to making it work, provide a proof that PCA is just a linear special case of it, and reveal that it has a similar PCA-like importance ordering effect when applied to nonlinear models. We demonstrate the intuition behind the regularization on some pedagogical toy problems, and its effectiveness on several benchmark problems, including MNIST, CIFAR-10 and CelebA.
IH-GAN: A Conditional Generative Model for Implicit Surface-Based Inverse Design of Cellular Structures
Mar 03, 2021

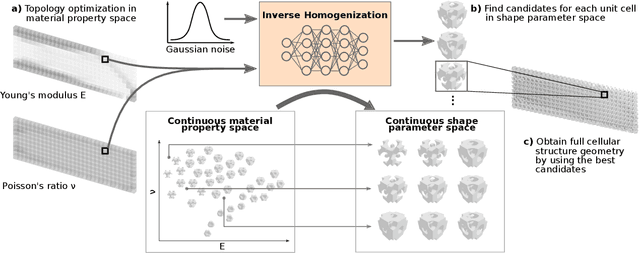
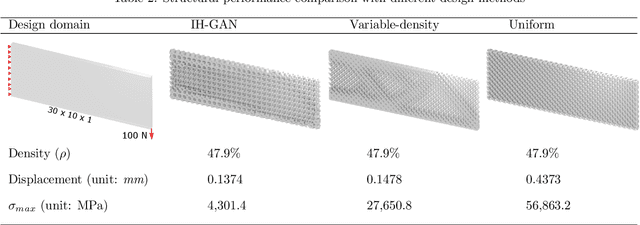
Variable-density cellular structures can overcome connectivity and manufacturability issues of topologically-optimized, functionally graded structures, particularly when those structures are represented as discrete density maps. One na\"ive approach to creating variable-density cellular structures is simply replacing the discrete density map with an unselective type of unit cells having corresponding densities. However, doing so breaks the desired mechanical behavior, as equivalent density alone does not guarantee equivalent mechanical properties. Another approach uses homogenization methods to estimate each pre-defined unit cell's effective properties and remaps the unit cells following a scaling law. However, a scaling law merely mitigates the problem by performing an indirect and inaccurate mapping from the material property space to single-type unit cells. In contrast, we propose a deep generative model that resolves this problem by automatically learning an accurate mapping and generating diverse cellular unit cells conditioned on desired properties (i.e., Young's modulus and Poisson's ratio). We demonstrate our method via the use of implicit function-based unit cells and conditional generative adversarial networks. Results show that our method can 1) generate various unit cells that satisfy given material properties with high accuracy (relative error <5%), 2) create functionally graded cellular structures with high-quality interface connectivity (98.7% average overlap area at interfaces), and 3) improve the structural performance over the conventional topology-optimized variable-density structure (84.4% reduction in concentrated stress and extra 7% reduction in displacement).
Airfoil Design Parameterization and Optimization using Bézier Generative Adversarial Networks
Jun 27, 2020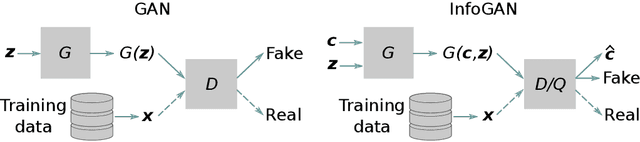
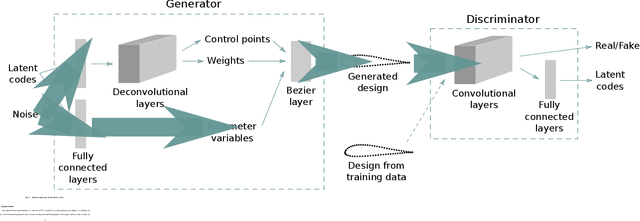
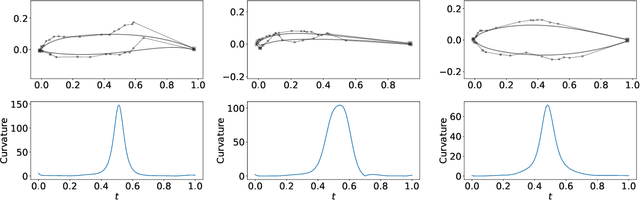
Global optimization of aerodynamic shapes usually requires a large number of expensive computational fluid dynamics simulations because of the high dimensionality of the design space. One approach to combat this problem is to reduce the design space dimension by obtaining a new representation. This requires a parametric function that compactly and sufficiently describes useful variation in shapes. We propose a deep generative model, B\'ezier-GAN, to parameterize aerodynamic designs by learning from shape variations in an existing database. The resulted new parameterization can accelerate design optimization convergence by improving the representation compactness while maintaining sufficient representation capacity. We use the airfoil design as an example to demonstrate the idea and analyze B\'ezier-GAN's representation capacity and compactness. Results show that B\'ezier-GAN both (1) learns smooth and realistic shape representations for a wide range of airfoils and (2) empirically accelerates optimization convergence by at least two times compared to state-of-the-art parameterization methods.
Forming Diverse Teams from Sequentially Arriving People
Feb 25, 2020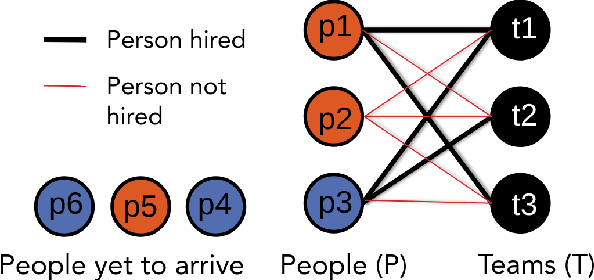


Collaborative work often benefits from having teams or organizations with heterogeneous members. In this paper, we present a method to form such diverse teams from people arriving sequentially over time. We define a monotone submodular objective function that combines the diversity and quality of a team and propose an algorithm to maximize the objective while satisfying multiple constraints. This allows us to balance both how diverse the team is and how well it can perform the task at hand. Using crowd experiments, we show that, in practice, the algorithm leads to large gains in team diversity. Using simulations, we show how to quantify the additional cost of forming diverse teams and how to address the problem of simultaneously maximizing diversity for several attributes (e.g., country of origin, gender). Our method has applications in collaborative work ranging from team formation, the assignment of workers to teams in crowdsourcing, and reviewer allocation to journal papers arriving sequentially. Our code is publicly accessible for further research.
Adaptive Expansion Bayesian Optimization for Unbounded Global Optimization
Jan 12, 2020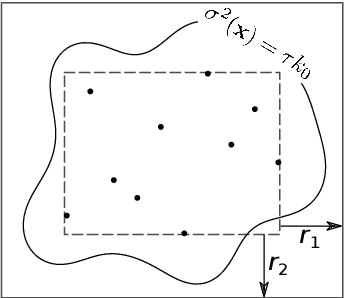
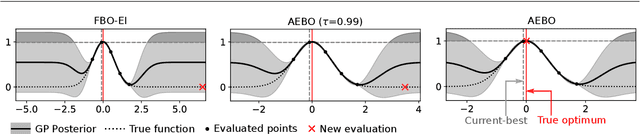
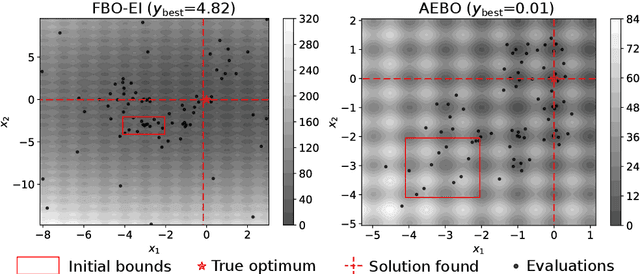
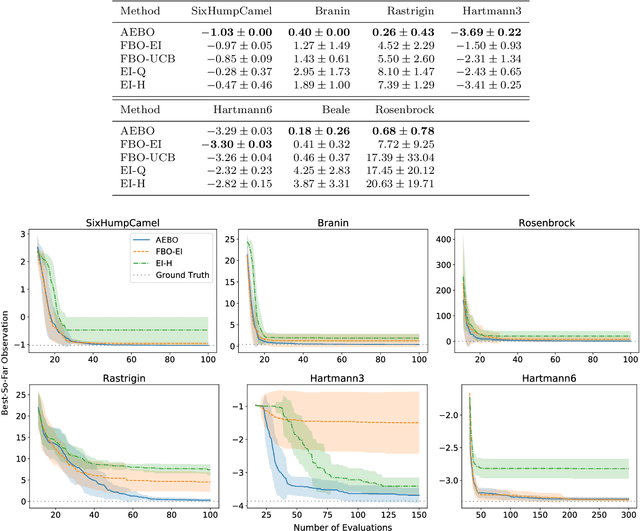
Bayesian optimization is normally performed within fixed variable bounds. In cases like hyperparameter tuning for machine learning algorithms, setting the variable bounds is not trivial. It is hard to guarantee that any fixed bounds will include the true global optimum. We propose a Bayesian optimization approach that only needs to specify an initial search space that does not necessarily include the global optimum, and expands the search space when necessary. However, over-exploration may occur during the search space expansion. Our method can adaptively balance exploration and exploitation in an expanding space. Results on a range of synthetic test functions and an MLP hyperparameter optimization task show that the proposed method out-performs or at least as good as the current state-of-the-art methods.