 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability Requires Interactivity
Sep 16, 2021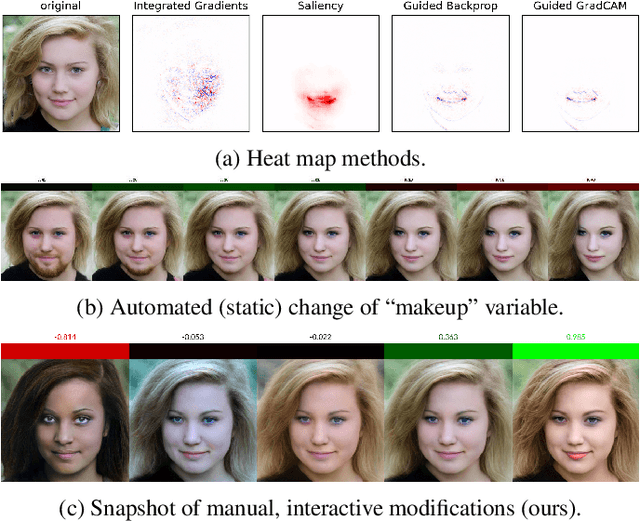

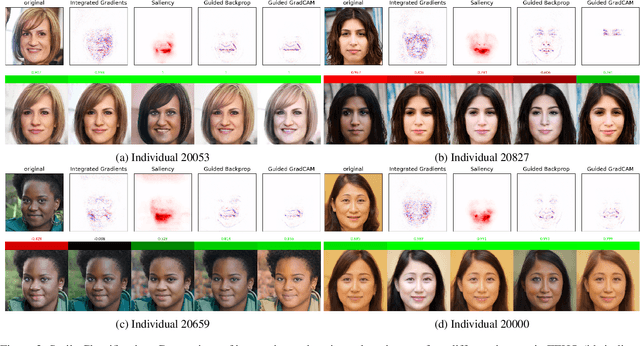

When explaining the decisions of deep neural networks, simple stories are tempting but dangerous. Especially in computer vision, the most popular explanation approaches give a false sense of comprehension to its users and provide an overly simplistic picture. We introduce an interactive framework to understand the highly complex decision boundaries of modern vision models. It allows the user to exhaustively inspect, probe, and test a network's decisions. Across a range of case studies, we compare the power of our interactive approach to static explanation methods, showing how these can lead a user astray, with potentially severe consequences.
Explaining Bayesian Neural Networks
Aug 23, 2021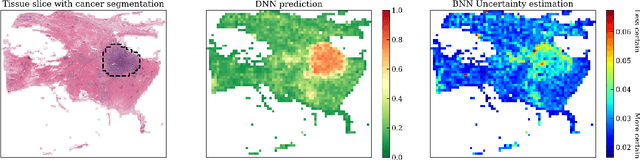
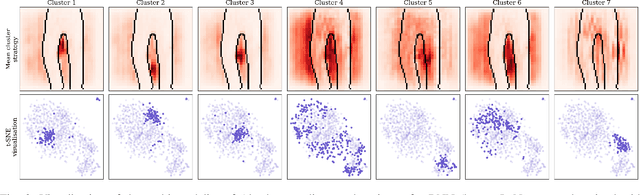
To make advanced learning machines such as Deep Neural Networks (DNNs) more transparent in decision making, explainable AI (XAI) aims to provide interpretations of DNNs' predictions. These interpretations are usually given in the form of heatmaps, each one illustrating relevant patterns regarding the prediction for a given instance. Bayesian approaches such as Bayesian Neural Networks (BNNs) so far have a limited form of transparency (model transparency) already built-in through their prior weight distribution, but notably, they lack explanations of their predictions for given instances. In this work, we bring together these two perspectives of transparency into a holistic explanation framework for explaining BNNs. Within the Bayesian framework, the network weights follow a probability distribution. Hence, the standard (deterministic) prediction strategy of DNNs extends in BNNs to a predictive distribution, and thus the standard explanation extends to an explanation distribution. Exploiting this view, we uncover that BNNs implicitly employ multiple heterogeneous prediction strategies. While some of these are inherited from standard DNNs, others are revealed to us by considering the inherent uncertainty in BNNs. Our quantitative and qualitative experiments on toy/benchmark data and real-world data from pathology show that the proposed approach of explaining BNNs can lead to more effective and insightful explanations.
Fine-grained Generalization Analysis of Structured Output Prediction
May 31, 2021
In machine learning we often encounter structured output prediction problems (SOPPs), i.e. problems where the output space admits a rich internal structure. Application domains where SOPPs naturally occur include natural language processing, speech recognition, and computer vision. Typical SOPPs have an extremely large label set, which grows exponentially as a function of the size of the output. Existing generalization analysis implies generalization bounds with at least a square-root dependency on the cardinality $d$ of the label set, which can be vacuous in practice. In this paper, we significantly improve the state of the art by developing novel high-probability bounds with a logarithmic dependency on $d$. Moreover, we leverage the lens of algorithmic stability to develop generalization bounds in expectation without any dependency on $d$. Our results therefore build a solid theoretical foundation for learning in large-scale SOPPs. Furthermore, we extend our results to learning with weakly dependent data.
Fine-grained Generalization Analysis of Vector-valued Learning
Apr 29, 2021
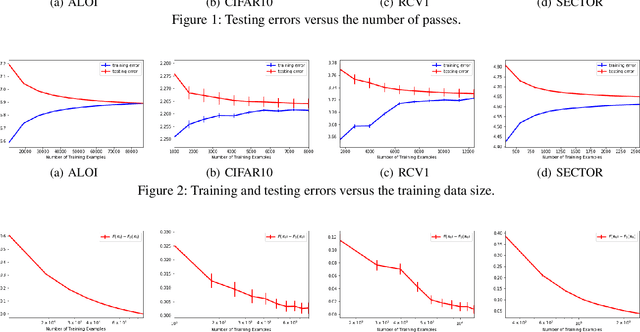

Many fundamental machine learning tasks can be formulated as a problem of learning with vector-valued functions, where we learn multiple scalar-valued functions together. Although there is some generalization analysis on different specific algorithms under the empirical risk minimization principle, a unifying analysis of vector-valued learning under a regularization framework is still lacking. In this paper, we initiate the generalization analysis of regularized vector-valued learning algorithms by presenting bounds with a mild dependency on the output dimension and a fast rate on the sample size. Our discussions relax the existing assumptions on the restrictive constraint of hypothesis spaces, smoothness of loss functions and low-noise condition. To understand the interaction between optimization and learning, we further use our results to derive the first generalization bounds for stochastic gradient descent with vector-valued functions. We apply our general results to multi-class classification and multi-label classification, which yield the first bounds with a logarithmic dependency on the output dimension for extreme multi-label classification with the Frobenius regularization. As a byproduct, we derive a Rademacher complexity bound for loss function classes defined in terms of a general strongly convex function.
Neural Transformation Learning for Deep Anomaly Detection Beyond Images
Mar 31, 2021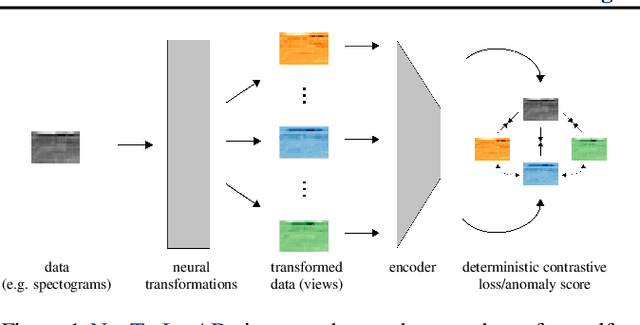

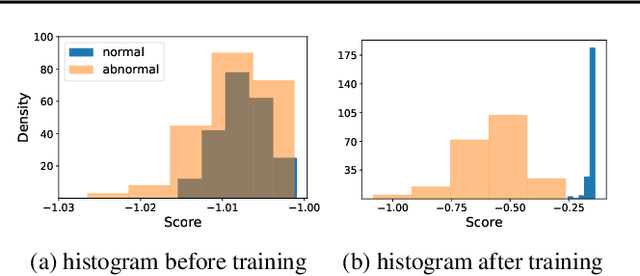
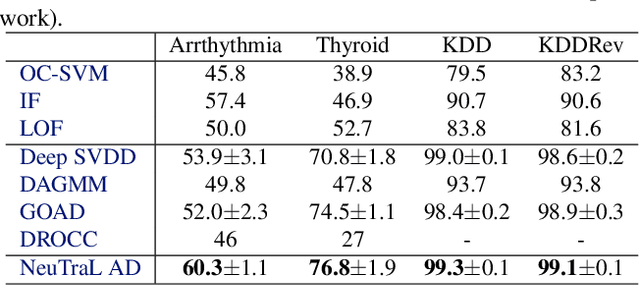
Data transformations (e.g. rotations, reflections, and cropping) play an important role in self-supervised learning. Typically, images are transformed into different views, and neural networks trained on tasks involving these views produce useful feature representations for downstream tasks, including anomaly detection. However, for anomaly detection beyond image data, it is often unclear which transformations to use. Here we present a simple end-to-end procedure for anomaly detection with learnable transformations. The key idea is to embed the transformed data into a semantic space such that the transformed data still resemble their untransformed form, while different transformations are easily distinguishable. Extensive experiments on time series demonstrate that we significantly outperform existing methods on the one-vs.-rest setting but also on the more challenging n-vs.-rest anomaly-detection task. On tabular datasets from the medical and cyber-security domains, our method learns domain-specific transformations and detects anomalies more accurately than previous work.
A Unifying Review of Deep and Shallow Anomaly Detection
Sep 28, 2020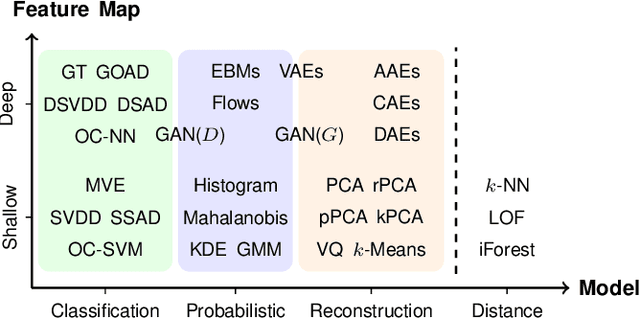

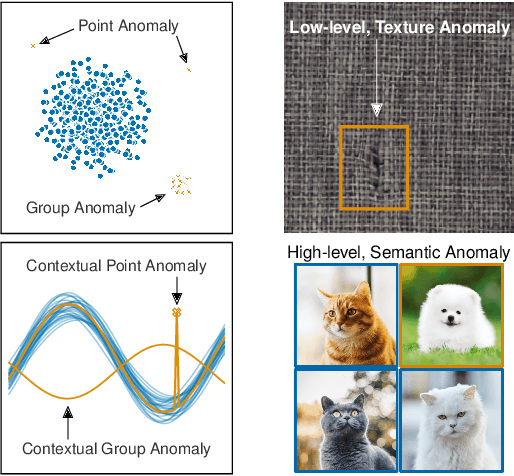
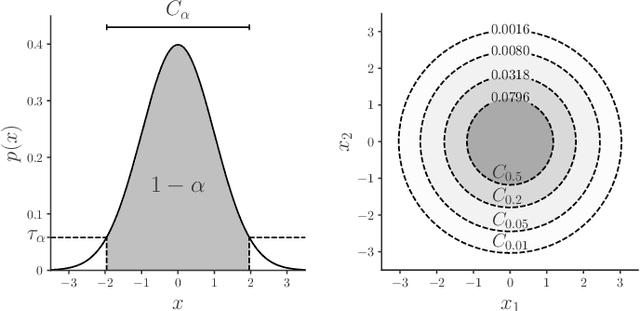
Deep learning approaches to anomaly detection have recently improved the state of the art in detection performance on complex datasets such as large collections of images or text. These results have sparked a renewed interest in the anomaly detection problem and led to the introduction of a great variety of new methods. With the emergence of numerous such methods, including approaches based on generative models, one-class classification, and reconstruction, there is a growing need to bring methods of this field into a systematic and unified perspective. In this review we aim to identify the common underlying principles as well as the assumptions that are often made implicitly by various methods. In particular, we draw connections between classic 'shallow' and novel deep approaches and show how this relation might cross-fertilize or extend both directions. We further provide an empirical assessment of major existing methods that is enriched by the use of recent explainability techniques, and present specific worked-through examples together with practical advice. Finally, we outline critical open challenges and identify specific paths for future research in anomaly detection.
Input Hessian Regularization of Neural Networks
Sep 14, 2020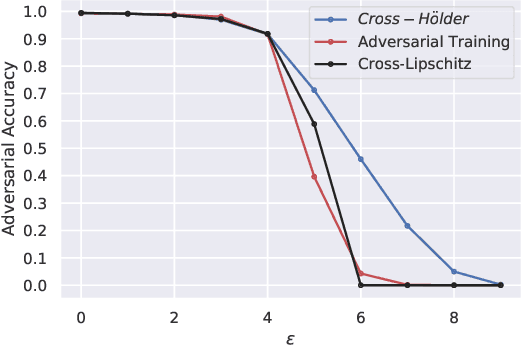
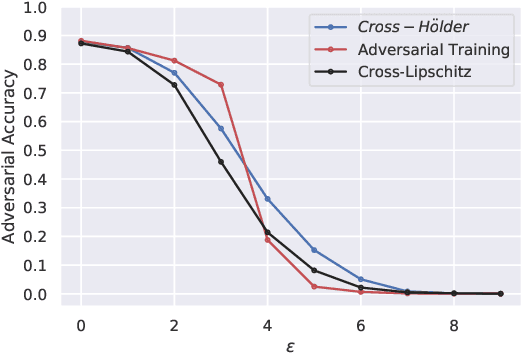
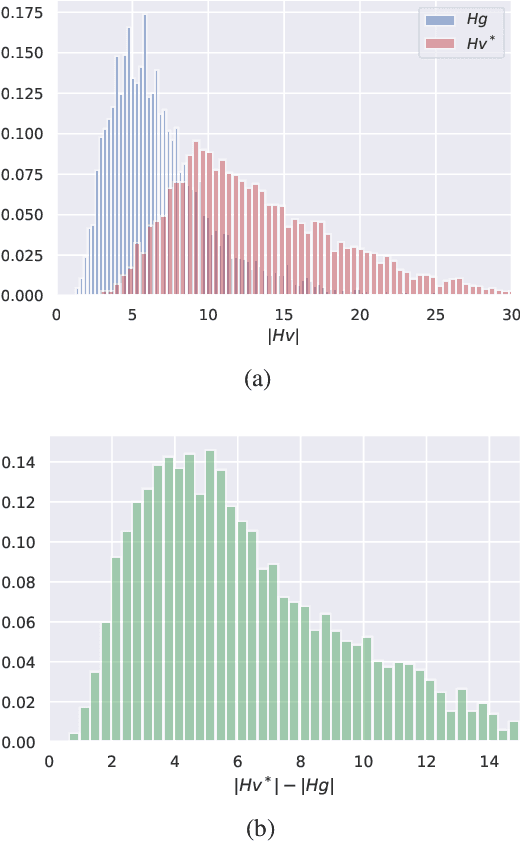
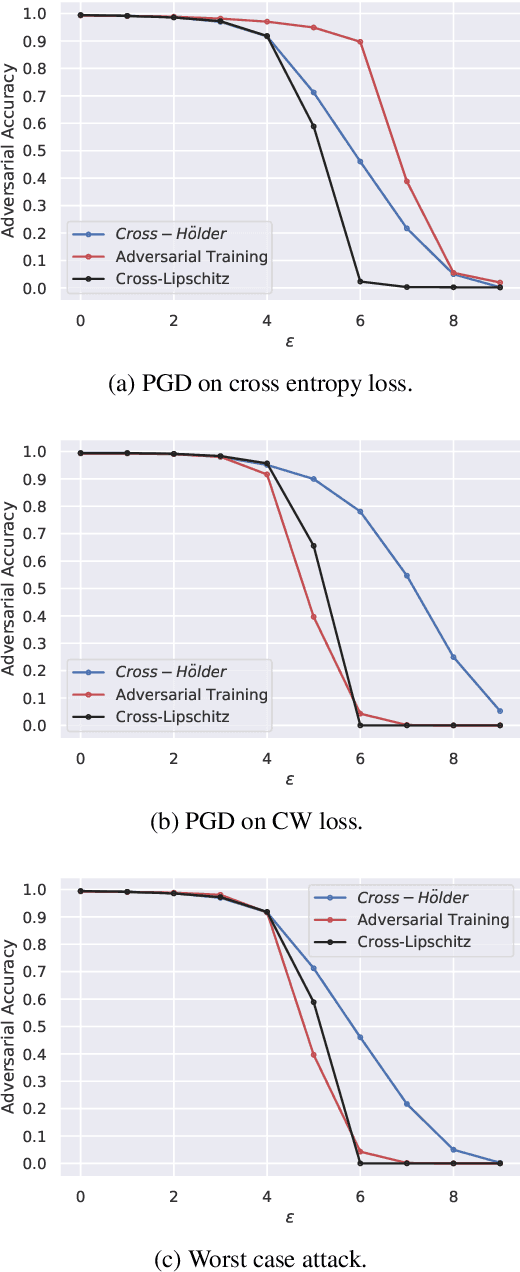
Regularizing the input gradient has shown to be effective in promoting the robustness of neural networks. The regularization of the input's Hessian is therefore a natural next step. A key challenge here is the computational complexity. Computing the Hessian of inputs is computationally infeasible. In this paper we propose an efficient algorithm to train deep neural networks with Hessian operator-norm regularization. We analyze the approach theoretically and prove that the Hessian operator norm relates to the ability of a neural network to withstand an adversarial attack. We give a preliminary experimental evaluation on the MNIST and FMNIST datasets, which demonstrates that the new regularizer can, indeed, be feasible and, furthermore, that it increases the robustness of neural networks over input gradient regularization.
Cloze Test Helps: Effective Video Anomaly Detection via Learning to Complete Video Events
Aug 27, 2020
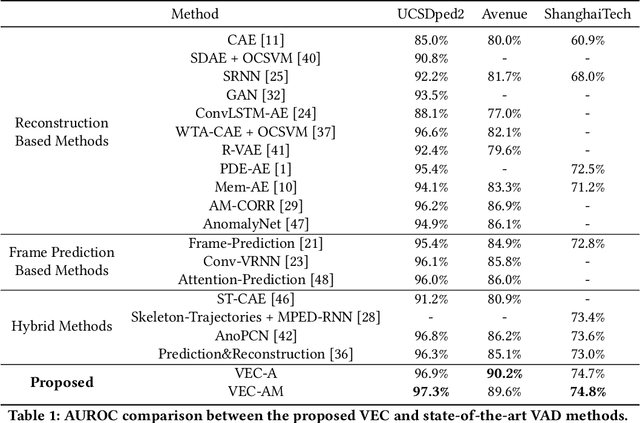
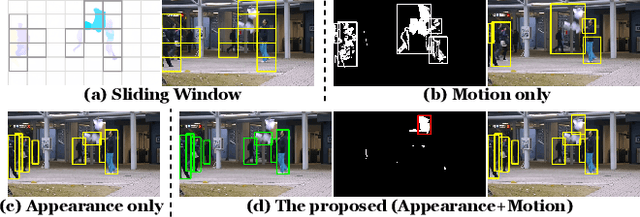

As a vital topic in media content interpretation, video anomaly detection (VAD) has made fruitful progress via deep neural network (DNN). However, existing methods usually follow a reconstruction or frame prediction routine. They suffer from two gaps: (1) They cannot localize video activities in a both precise and comprehensive manner. (2) They lack sufficient abilities to utilize high-level semantics and temporal context information. Inspired by frequently-used cloze test in language study, we propose a brand-new VAD solution named Video Event Completion (VEC) to bridge gaps above: First, we propose a novel pipeline to achieve both precise and comprehensive enclosure of video activities. Appearance and motion are exploited as mutually complimentary cues to localize regions of interest (RoIs). A normalized spatio-temporal cube (STC) is built from each RoI as a video event, which lays the foundation of VEC and serves as a basic processing unit. Second, we encourage DNN to capture high-level semantics by solving a visual cloze test. To build such a visual cloze test, a certain patch of STC is erased to yield an incomplete event (IE). The DNN learns to restore the original video event from the IE by inferring the missing patch. Third, to incorporate richer motion dynamics, another DNN is trained to infer erased patches' optical flow. Finally, two ensemble strategies using different types of IE and modalities are proposed to boost VAD performance, so as to fully exploit the temporal context and modality information for VAD. VEC can consistently outperform state-of-the-art methods by a notable margin (typically 1.5%-5% AUROC) on commonly-used VAD benchmarks. Our codes and results can be verified at github.com/yuguangnudt/VEC_VAD.
Explainable Deep One-Class Classification
Jul 03, 2020

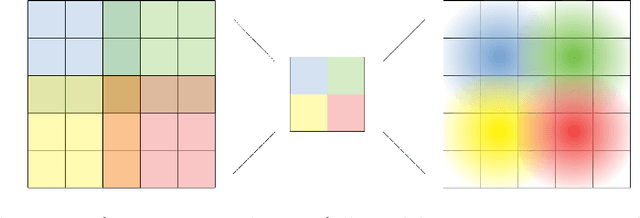
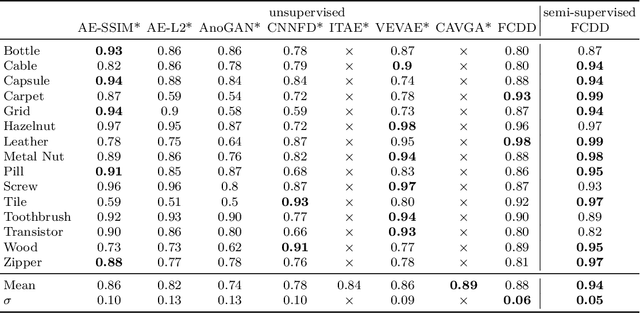
Deep one-class classification variants for anomaly detection learn a mapping that concentrates nominal samples in feature space causing anomalies to be mapped away. Because this transformation is highly non-linear, finding interpretations poses a significant challenge. In this paper we present an explainable deep one-class classification method, Fully Convolutional Data Description (FCDD), where the mapped samples are themselves also an explanation heatmap. FCDD yields competitive detection performance and provides reasonable explanations on common anomaly detection benchmarks with CIFAR-10 and ImageNet. On MVTec-AD, a recent manufacturing dataset offering ground-truth anomaly maps, FCDD meets the state of the art in an unsupervised setting, and outperforms its competitors in a semi-supervised setting. Finally, using FCDD's explanations we demonstrate the vulnerability of deep one-class classification models to spurious image features such as image watermarks.
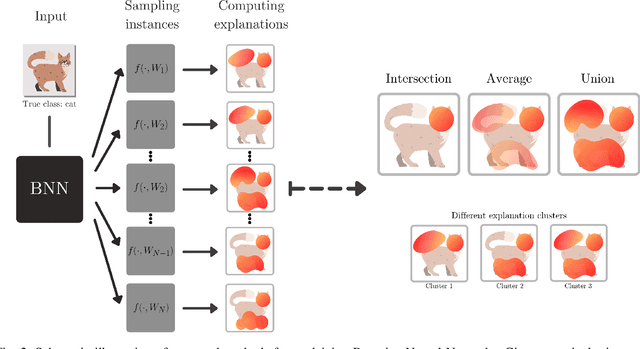
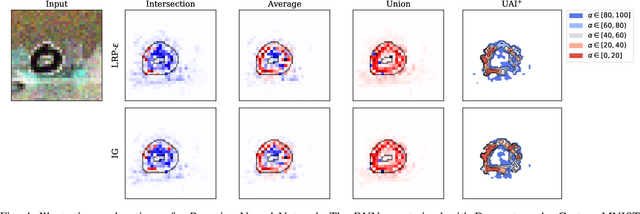
How Much Can I Trust You? -- Quantifying Uncertainties in Explaining Neural Networks
Jun 16, 2020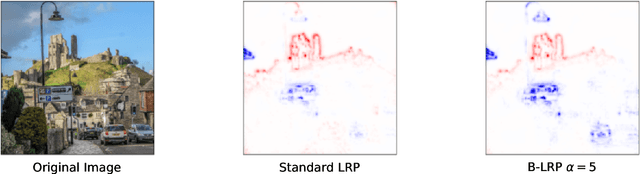
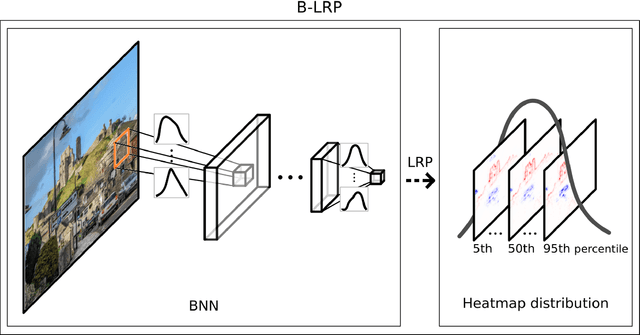
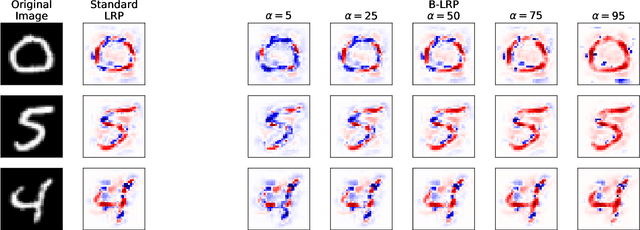
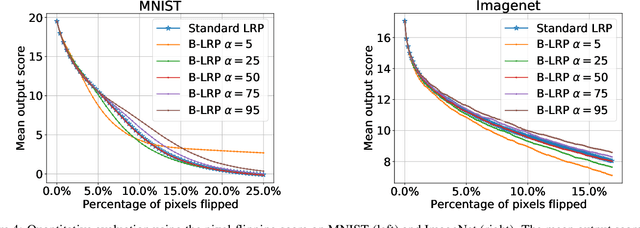
Explainable AI (XAI) aims to provide interpretations for predictions made by learning machines, such as deep neural networks, in order to make the machines more transparent for the user and furthermore trustworthy also for applications in e.g. safety-critical areas. So far, however, no methods for quantifying uncertainties of explanations have been conceived, which is problematic in domains where a high confidence in explanations is a prerequisite. We therefore contribute by proposing a new framework that allows to convert any arbitrary explanation method for neural networks into an explanation method for Bayesian neural networks, with an in-built modeling of uncertainties. Within the Bayesian framework a network's weights follow a distribution that extends standard single explanation scores and heatmaps to distributions thereof, in this manner translating the intrinsic network model uncertainties into a quantification of explanation uncertainties. This allows us for the first time to carve out uncertainties associated with a model explanation and subsequently gauge the appropriate level of explanation confidence for a user (using percentiles). We demonstrate the effectiveness and usefulness of our approach extensively in various experiments, both qualitatively and quantitatively.