 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisturbance-Free Surgical Video Generation from Multi-Camera Shadowless Lamps for Open Surgery
Dec 09, 2025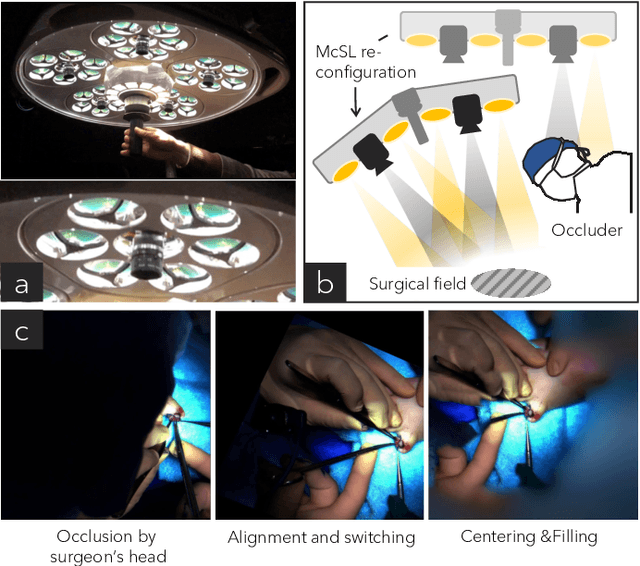
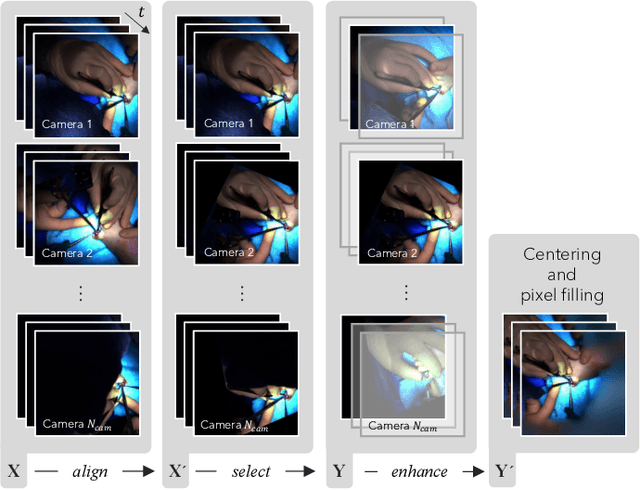
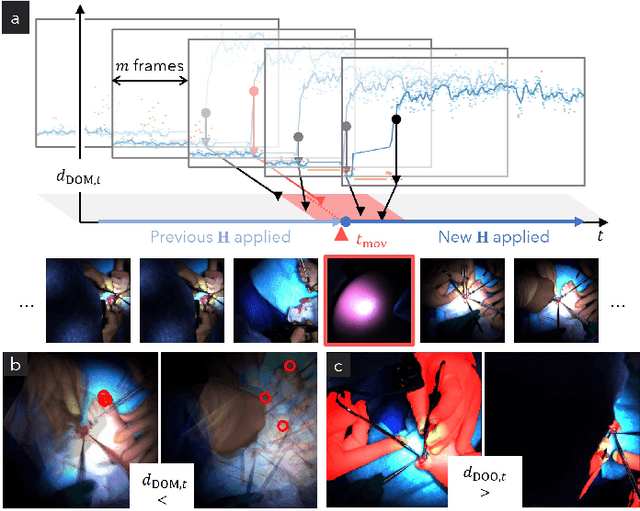
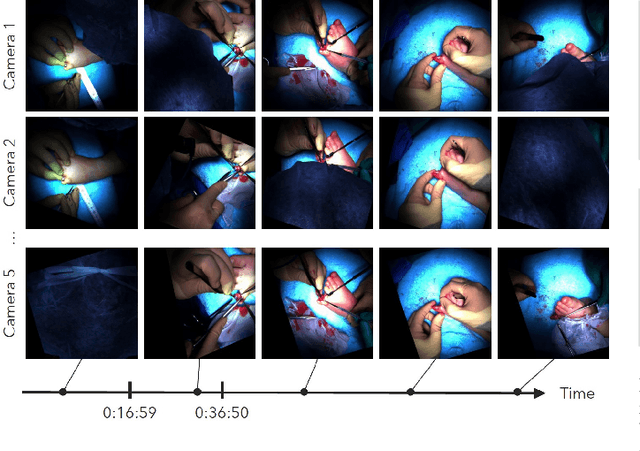
Video recordings of open surgeries are greatly required for education and research purposes. However, capturing unobstructed videos is challenging since surgeons frequently block the camera field of view. To avoid occlusion, the positions and angles of the camera must be frequently adjusted, which is highly labor-intensive. Prior work has addressed this issue by installing multiple cameras on a shadowless lamp and arranging them to fully surround the surgical area. This setup increases the chances of some cameras capturing an unobstructed view. However, manual image alignment is needed in post-processing since camera configurations change every time surgeons move the lamp for optimal lighting. This paper aims to fully automate this alignment task. The proposed method identifies frames in which the lighting system moves, realigns them, and selects the camera with the least occlusion to generate a video that consistently presents the surgical field from a fixed perspective. A user study involving surgeons demonstrated that videos generated by our method were superior to those produced by conventional methods in terms of the ease of confirming the surgical area and the comfort during video viewing. Additionally, our approach showed improvements in video quality over existing techniques. Furthermore, we implemented several synthesis options for the proposed view-synthesis method and conducted a user study to assess surgeons' preferences for each option.
High-Quality Virtual Single-Viewpoint Surgical Video: Geometric Autocalibration of Multiple Cameras in Surgical Lights
Mar 05, 2025Occlusion-free video generation is challenging due to surgeons' obstructions in the camera field of view. Prior work has addressed this issue by installing multiple cameras on a surgical light, hoping some cameras will observe the surgical field with less occlusion. However, this special camera setup poses a new imaging challenge since camera configurations can change every time surgeons move the light, and manual image alignment is required. This paper proposes an algorithm to automate this alignment task. The proposed method detects frames where the lighting system moves, realigns them, and selects the camera with the least occlusion. This algorithm results in a stabilized video with less occlusion. Quantitative results show that our method outperforms conventional approaches. A user study involving medical doctors also confirmed the superiority of our method.
Deep Selection: A Fully Supervised Camera Selection Network for Surgery Recordings
Mar 28, 2023Recording surgery in operating rooms is an essential task for education and evaluation of medical treatment. However, recording the desired targets, such as the surgery field, surgical tools, or doctor's hands, is difficult because the targets are heavily occluded during surgery. We use a recording system in which multiple cameras are embedded in the surgical lamp, and we assume that at least one camera is recording the target without occlusion at any given time. As the embedded cameras obtain multiple video sequences, we address the task of selecting the camera with the best view of the surgery. Unlike the conventional method, which selects the camera based on the area size of the surgery field, we propose a deep neural network that predicts the camera selection probability from multiple video sequences by learning the supervision of the expert annotation. We created a dataset in which six different types of plastic surgery are recorded, and we provided the annotation of camera switching. Our experiments show that our approach successfully switched between cameras and outperformed three baseline methods.