 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction
Aug 29, 2018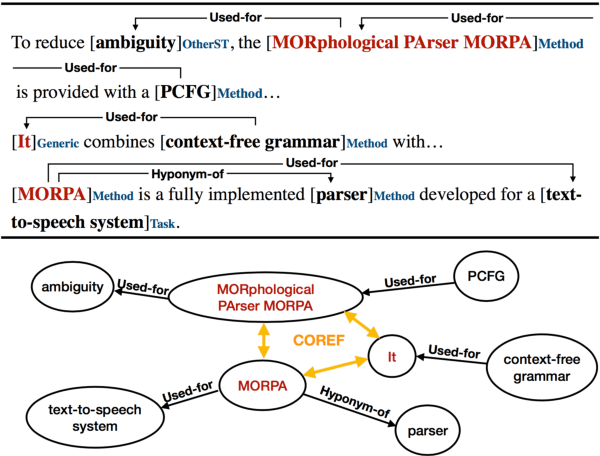
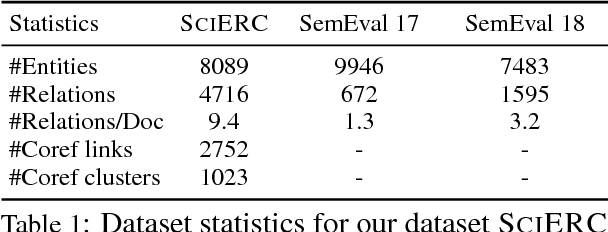
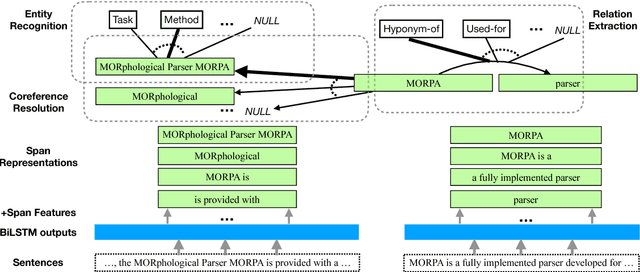
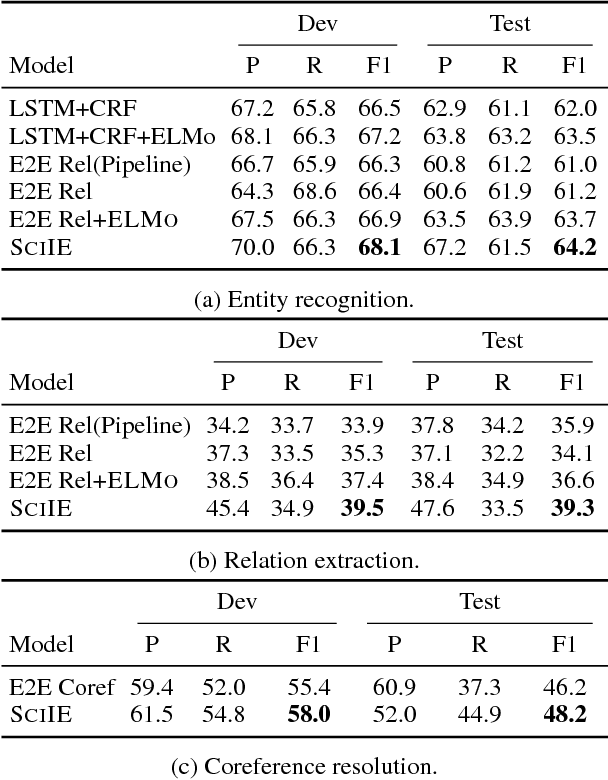
We introduce a multi-task setup of identifying and classifying entities, relations, and coreference clusters in scientific articles. We create SciERC, a dataset that includes annotations for all three tasks and develop a unified framework called Scientific Information Extractor (SciIE) for with shared span representations. The multi-task setup reduces cascading errors between tasks and leverages cross-sentence relations through coreference links. Experiments show that our multi-task model outperforms previous models in scientific information extraction without using any domain-specific features. We further show that the framework supports construction of a scientific knowledge graph, which we use to analyze information in scientific literature.
Scientific Relation Extraction with Selectively Incorporated Concept Embeddings
Aug 26, 2018
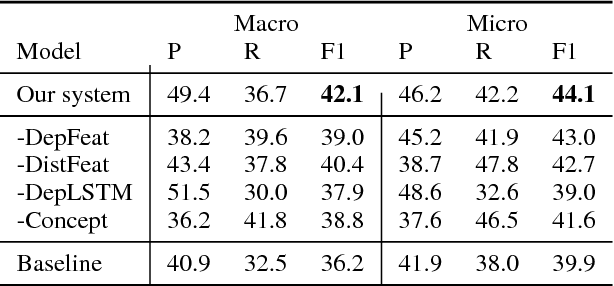
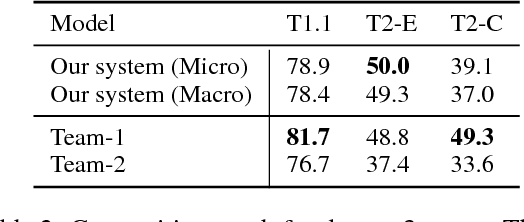
This paper describes our submission for the SemEval 2018 Task 7 shared task on semantic relation extraction and classification in scientific papers. We extend the end-to-end relation extraction model of (Miwa and Bansal) with enhancements such as a character-level encoding attention mechanism on selecting pretrained concept candidate embeddings. Our official submission ranked the second in relation classification task (Subtask 1.1 and Subtask 2 Senerio 2), and the first in the relation extraction task (Subtask 2 Scenario 1).
Real-Time Prediction of the Duration of Distribution System Outages
Jul 30, 2018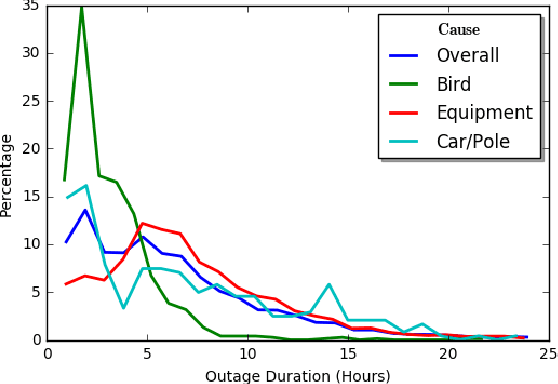
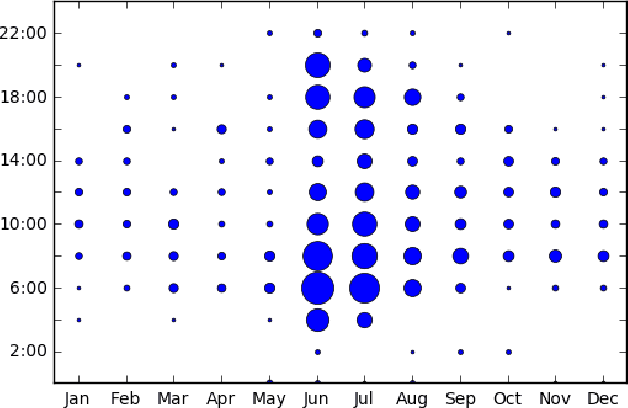
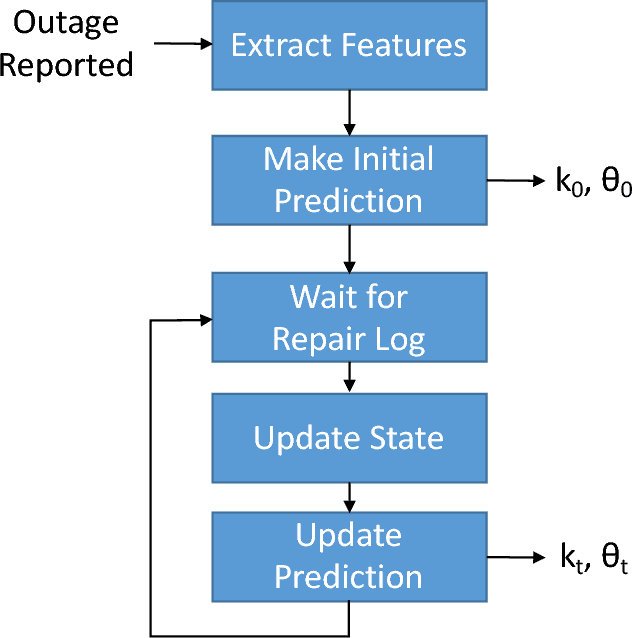
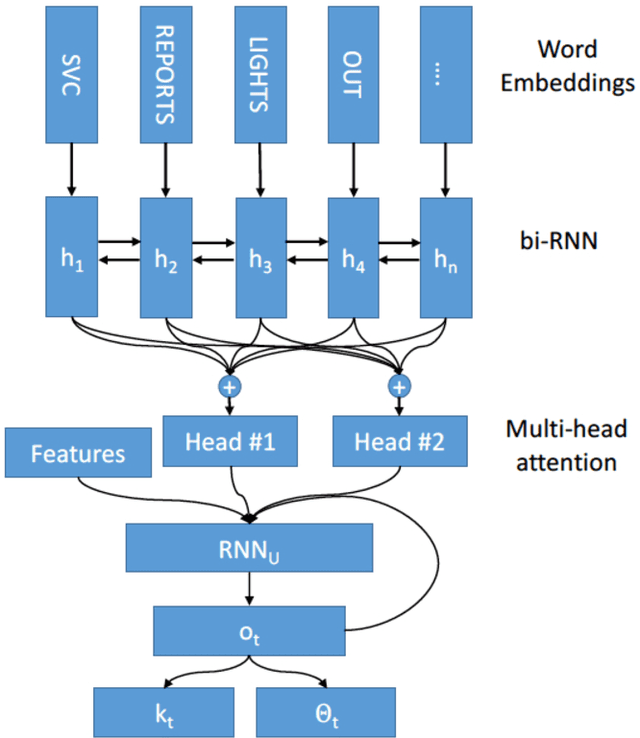
This paper addresses the problem of predicting duration of unplanned power outages, using historical outage records to train a series of neural network predictors. The initial duration prediction is made based on environmental factors, and it is updated based on incoming field reports using natural language processing to automatically analyze the text. Experiments using 15 years of outage records show good initial results and improved performance leveraging text. Case studies show that the language processing identifies phrases that point to outage causes and repair steps.
Training Augmentation with Adversarial Examples for Robust Speech Recognition
Jun 17, 2018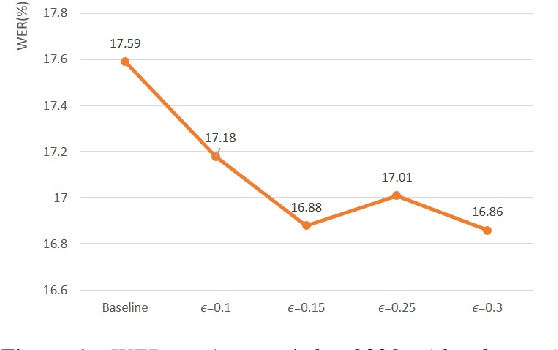
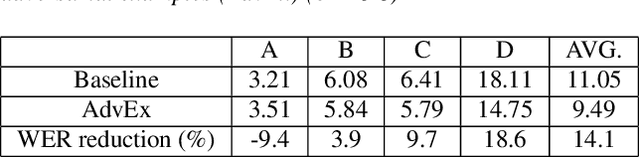
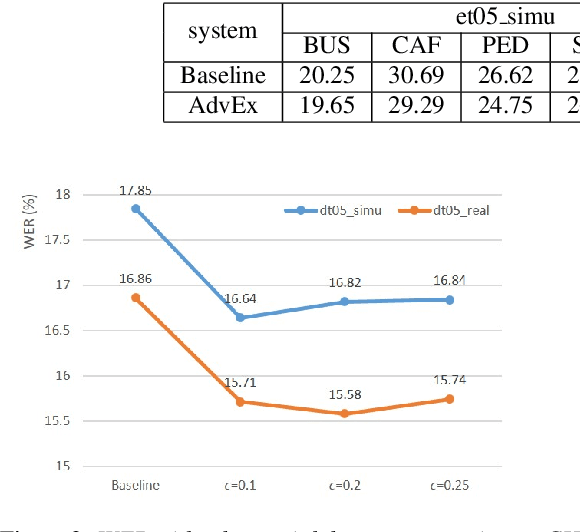
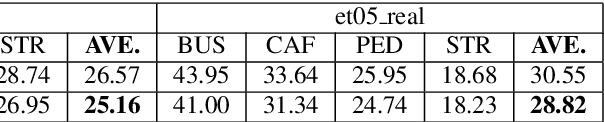
This paper explores the use of adversarial examples in training speech recognition systems to increase robustness of deep neural network acoustic models. During training, the fast gradient sign method is used to generate adversarial examples augmenting the original training data. Different from conventional data augmentation based on data transformations, the examples are dynamically generated based on current acoustic model parameters. We assess the impact of adversarial data augmentation in experiments on the Aurora-4 and CHiME-4 single-channel tasks, showing improved robustness against noise and channel variation. Further improvement is obtained when combining adversarial examples with teacher/student training, leading to a 23% relative word error rate reduction on Aurora-4.
Domain Adversarial Training for Accented Speech Recognition
Jun 07, 2018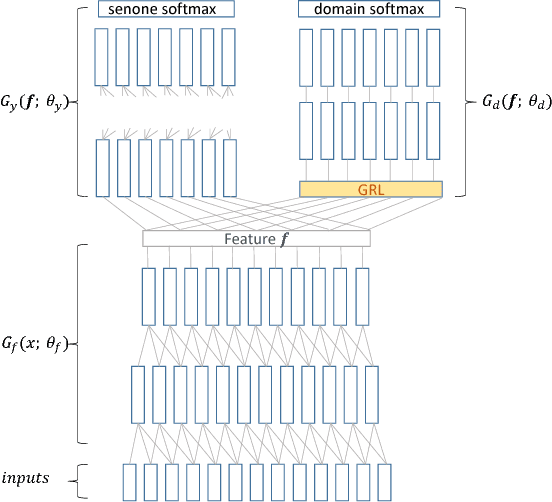

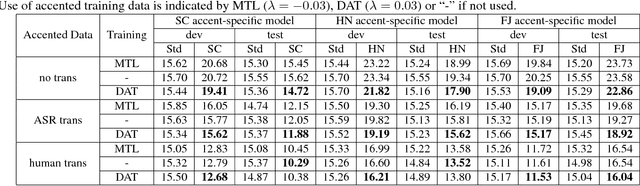
In this paper, we propose a domain adversarial training (DAT) algorithm to alleviate the accented speech recognition problem. In order to reduce the mismatch between labeled source domain data ("standard" accent) and unlabeled target domain data (with heavy accents), we augment the learning objective for a Kaldi TDNN network with a domain adversarial training (DAT) objective to encourage the model to learn accent-invariant features. In experiments with three Mandarin accents, we show that DAT yields up to 7.45% relative character error rate reduction when we do not have transcriptions of the accented speech, compared with the baseline trained on standard accent data only. We also find a benefit from DAT when used in combination with training from automatic transcriptions on the accented data. Furthermore, we find that DAT is superior to multi-task learning for accented speech recognition.
Low-Rank RNN Adaptation for Context-Aware Language Modeling
May 04, 2018A context-aware language model uses location, user and/or domain metadata (context) to adapt its predictions. In neural language models, context information is typically represented as an embedding and it is given to the RNN as an additional input, which has been shown to be useful in many applications. We introduce a more powerful mechanism for using context to adapt an RNN by letting the context vector control a low-rank transformation of the recurrent layer weight matrix. Experiments show that allowing a greater fraction of the model parameters to be adjusted has benefits in terms of perplexity and classification for several different types of context.
Sounding Board: A User-Centric and Content-Driven Social Chatbot
Apr 26, 2018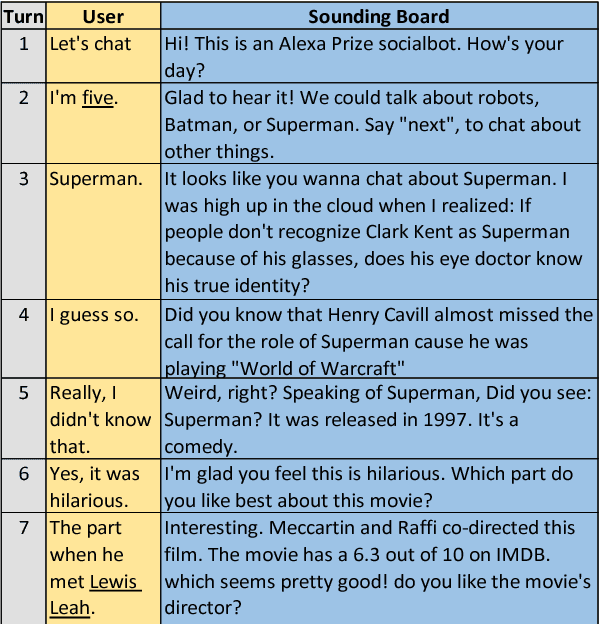

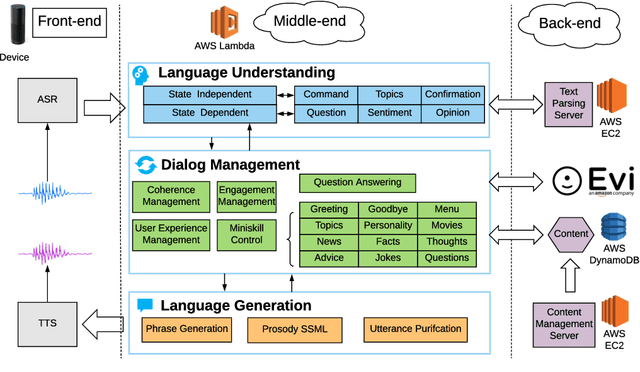
We present Sounding Board, a social chatbot that won the 2017 Amazon Alexa Prize. The system architecture consists of several components including spoken language processing, dialogue management, language generation, and content management, with emphasis on user-centric and content-driven design. We also share insights gained from large-scale online logs based on 160,000 conversations with real-world users.
Personalized Language Model for Query Auto-Completion
Apr 25, 2018
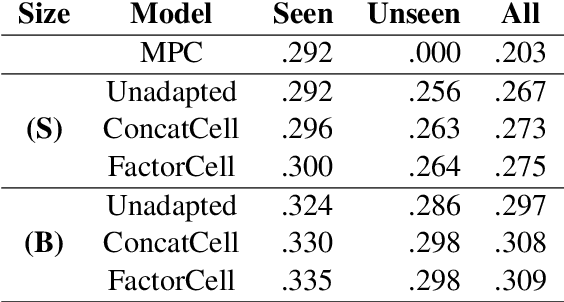
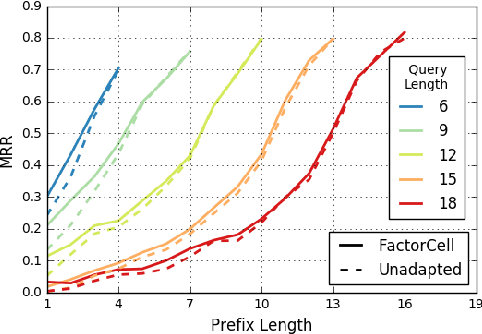
Query auto-completion is a search engine feature whereby the system suggests completed queries as the user types. Recently, the use of a recurrent neural network language model was suggested as a method of generating query completions. We show how an adaptable language model can be used to generate personalized completions and how the model can use online updating to make predictions for users not seen during training. The personalized predictions are significantly better than a baseline that uses no user information.
Community Member Retrieval on Social Media using Textual Information
Apr 16, 2018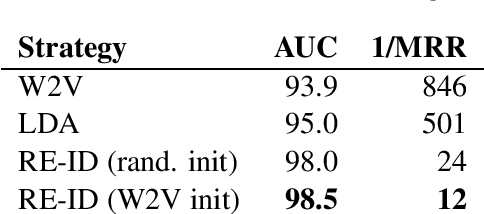
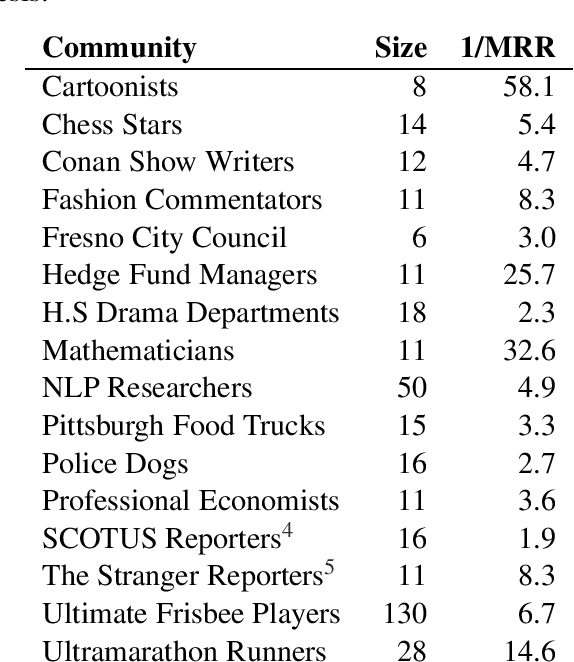

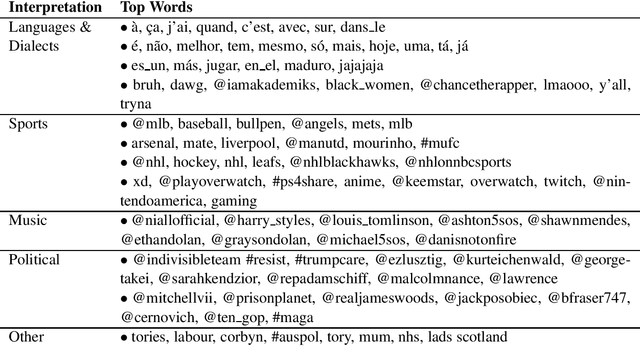
This paper addresses the problem of community membership detection using only text features in a scenario where a small number of positive labeled examples defines the community. The solution introduces an unsupervised proxy task for learning user embeddings: user re-identification. Experiments with 16 different communities show that the resulting embeddings are more effective for community membership identification than common unsupervised representations.
Parsing Speech: A Neural Approach to Integrating Lexical and Acoustic-Prosodic Information
Apr 15, 2018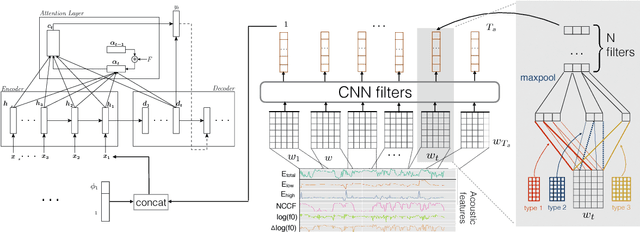
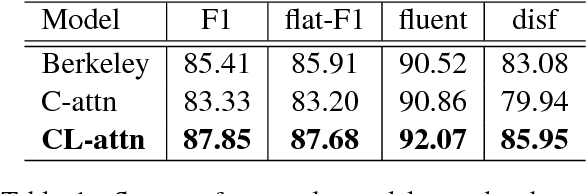
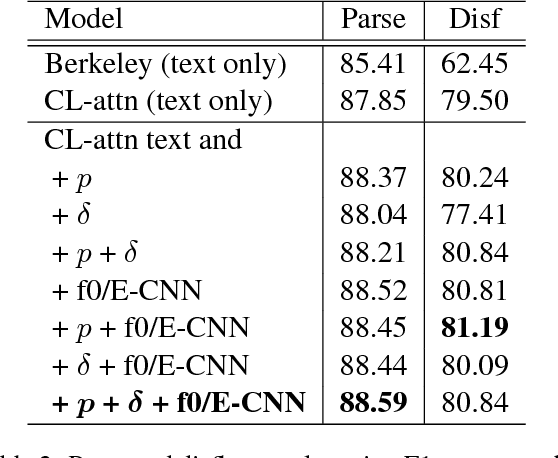
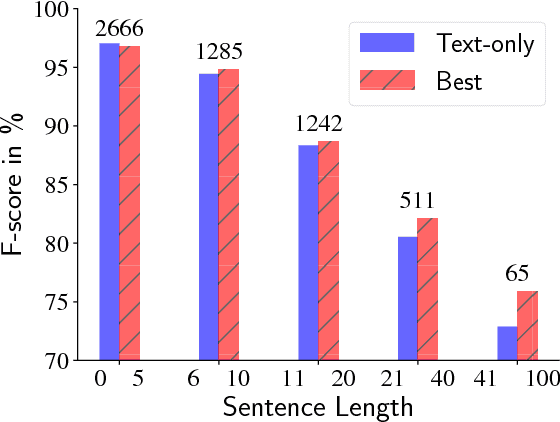
In conversational speech, the acoustic signal provides cues that help listeners disambiguate difficult parses. For automatically parsing spoken utterances, we introduce a model that integrates transcribed text and acoustic-prosodic features using a convolutional neural network over energy and pitch trajectories coupled with an attention-based recurrent neural network that accepts text and prosodic features. We find that different types of acoustic-prosodic features are individually helpful, and together give statistically significant improvements in parse and disfluency detection F1 scores over a strong text-only baseline. For this study with known sentence boundaries, error analyses show that the main benefit of acoustic-prosodic features is in sentences with disfluencies, attachment decisions are most improved, and transcription errors obscure gains from prosody.