 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfless Sequential Learning
Oct 08, 2018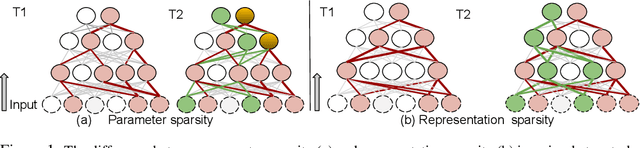
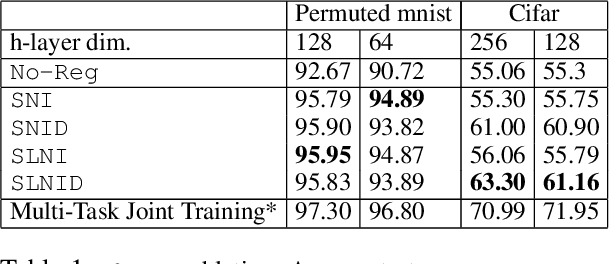
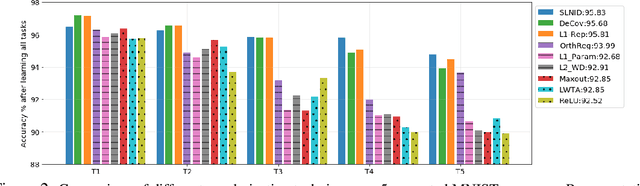

Sequential learning studies the problem of learning tasks in a sequence with access restricted to only the data of the current task. In this paper we look at a scenario with a fixed model capacity, and postulate that the learning process should not be selfish, i.e. it should account for future tasks to be added and %therefore aim at utilizing a minimum number of neurons, thus leave enough capacity for them. To achieve Selfless Sequential Learning} we study different regularization strategies and activation functions that could lead to less interference between the different tasks. We find that learning a sparse representation is more beneficial for sequential learning than encouraging parameter sparsity. In particular, we propose a novel regularizer, that encourages representation sparsity by means of neural inhibition. It results in few active neurons which in turn leaves more free neurons to be utilized by upcoming tasks. As suppressing all other neurons in a layer can be too drastic, especially for complex tasks requiring strong representations, our regularizer only inhibits other neurons in a local neighbourhood, inspired by inhibition processes in the brain. We combine our novel regularizer, SLNI, with state-of-the-art sequential learning methods that penalize changes to important previously learned parts of the network. We show that our new regularizer leads to increased sparsity which translates in consistent performance improvement %over alternative regularizers we studied on diverse datasets.
Memory Aware Synapses: Learning what to forget
Oct 05, 2018
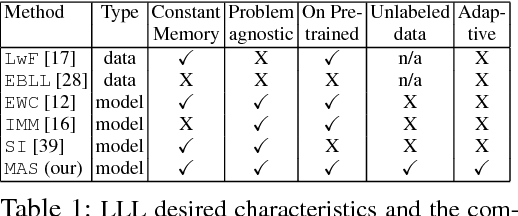
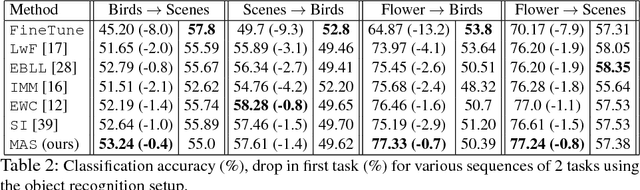
Humans can learn in a continuous manner. Old rarely utilized knowledge can be overwritten by new incoming information while important, frequently used knowledge is prevented from being erased. In artificial learning systems, lifelong learning so far has focused mainly on accumulating knowledge over tasks and overcoming catastrophic forgetting. In this paper, we argue that, given the limited model capacity and the unlimited new information to be learned, knowledge has to be preserved or erased selectively. Inspired by neuroplasticity, we propose a novel approach for lifelong learning, coined Memory Aware Synapses (MAS). It computes the importance of the parameters of a neural network in an unsupervised and online manner. Given a new sample which is fed to the network, MAS accumulates an importance measure for each parameter of the network, based on how sensitive the predicted output function is to a change in this parameter. When learning a new task, changes to important parameters can then be penalized, effectively preventing important knowledge related to previous tasks from being overwritten. Further, we show an interesting connection between a local version of our method and Hebb's rule,which is a model for the learning process in the brain. We test our method on a sequence of object recognition tasks and on the challenging problem of learning an embedding for predicting $<$subject, predicate, object$>$ triplets. We show state-of-the-art performance and, for the first time, the ability to adapt the importance of the parameters based on unlabeled data towards what the network needs (not) to forget, which may vary depending on test conditions.
Large-Scale Visual Relationship Understanding
Sep 14, 2018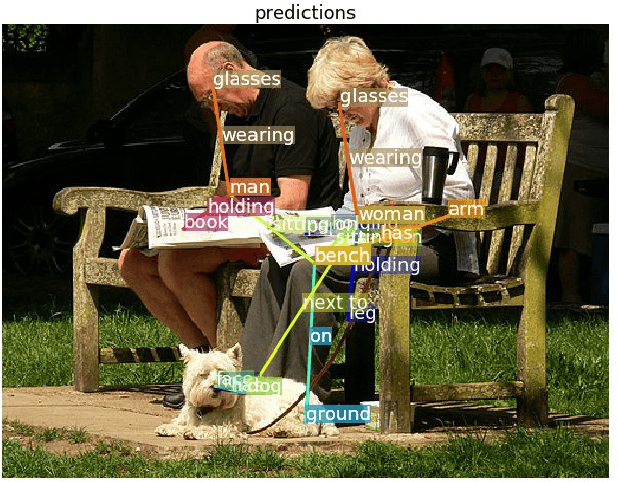
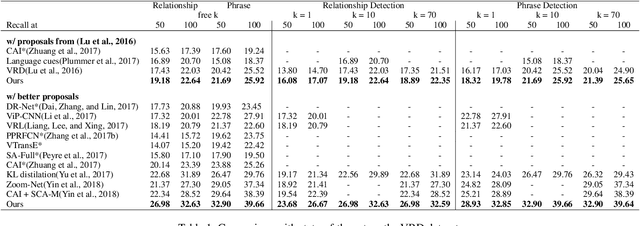
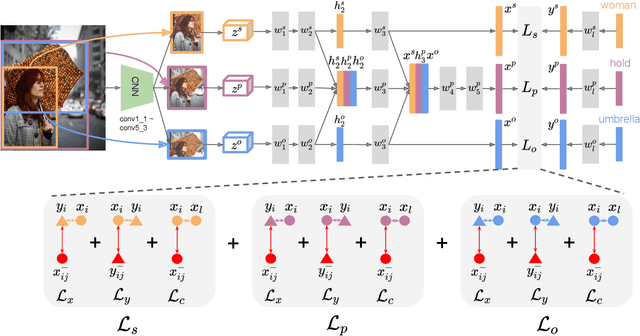
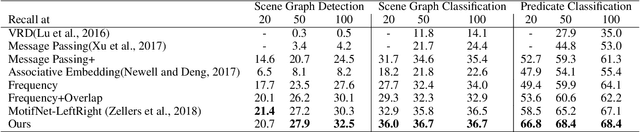
Large scale visual understanding is challenging, as it requires a model to handle the widely-spread and imbalanced distribution of <subject, relation, object> triples. In real-world scenarios with large numbers of objects and relations, some are seen very commonly while others are barely seen. We develop a new relationship detection model that embeds objects and relations into two vector spaces where both discriminative capability and semantic affinity are preserved. We learn both a visual and a semantic module that map features from the two modalities into a shared space, where matched pairs of features have to discriminate against those unmatched, but also maintain close distances to semantically similar ones. Benefiting from that, our model can achieve superior performance even when the visual entity categories scale up to more than 80,000, with extremely skewed class distribution. We demonstrate the efficacy of our model on a large and imbalanced benchmark based of Visual Genome that comprises 53,000+ objects and 29,000+ relations, a scale at which no previous work has ever been evaluated at. We show superiority of our model over carefully designed baselines on the original Visual Genome dataset with 80,000+ categories. We also show state-of-the-art performance on the VRD dataset and the scene graph dataset which is a subset of Visual Genome with 200 categories.
Visual Coreference Resolution in Visual Dialog using Neural Module Networks
Sep 06, 2018

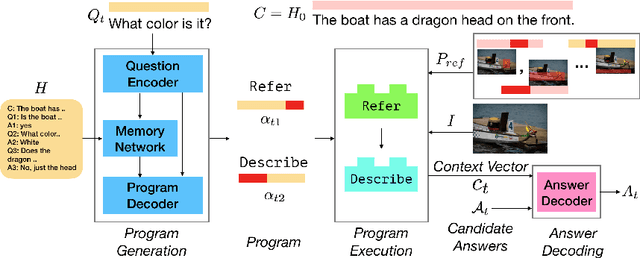

Visual dialog entails answering a series of questions grounded in an image, using dialog history as context. In addition to the challenges found in visual question answering (VQA), which can be seen as one-round dialog, visual dialog encompasses several more. We focus on one such problem called visual coreference resolution that involves determining which words, typically noun phrases and pronouns, co-refer to the same entity/object instance in an image. This is crucial, especially for pronouns (e.g., `it'), as the dialog agent must first link it to a previous coreference (e.g., `boat'), and only then can rely on the visual grounding of the coreference `boat' to reason about the pronoun `it'. Prior work (in visual dialog) models visual coreference resolution either (a) implicitly via a memory network over history, or (b) at a coarse level for the entire question; and not explicitly at a phrase level of granularity. In this work, we propose a neural module network architecture for visual dialog by introducing two novel modules - Refer and Exclude - that perform explicit, grounded, coreference resolution at a finer word level. We demonstrate the effectiveness of our model on MNIST Dialog, a visually simple yet coreference-wise complex dataset, by achieving near perfect accuracy, and on VisDial, a large and challenging visual dialog dataset on real images, where our model outperforms other approaches, and is more interpretable, grounded, and consistent qualitatively.
Pythia v0.1: the Winning Entry to the VQA Challenge 2018
Jul 27, 2018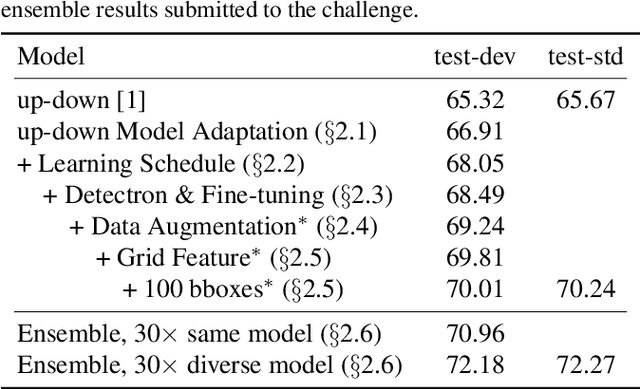
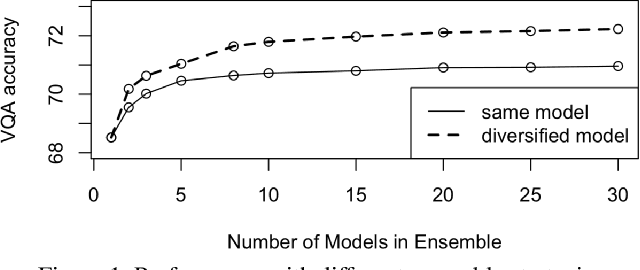
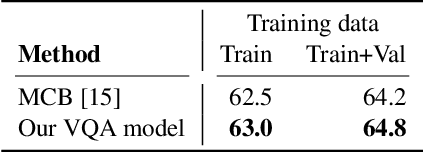
This document describes Pythia v0.1, the winning entry from Facebook AI Research (FAIR)'s A-STAR team to the VQA Challenge 2018. Our starting point is a modular re-implementation of the bottom-up top-down (up-down) model. We demonstrate that by making subtle but important changes to the model architecture and the learning rate schedule, fine-tuning image features, and adding data augmentation, we can significantly improve the performance of the up-down model on VQA v2.0 dataset -- from 65.67% to 70.22%. Furthermore, by using a diverse ensemble of models trained with different features and on different datasets, we are able to significantly improve over the 'standard' way of ensembling (i.e. same model with different random seeds) by 1.31%. Overall, we achieve 72.27% on the test-std split of the VQA v2.0 dataset. Our code in its entirety (training, evaluation, data-augmentation, ensembling) and pre-trained models are publicly available at: https://github.com/facebookresearch/pythia
Multimodal Explanations: Justifying Decisions and Pointing to the Evidence
Feb 15, 2018
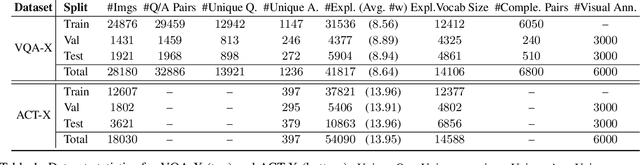

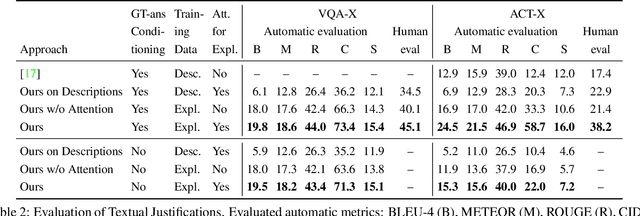
Deep models that are both effective and explainable are desirable in many settings; prior explainable models have been unimodal, offering either image-based visualization of attention weights or text-based generation of post-hoc justifications. We propose a multimodal approach to explanation, and argue that the two modalities provide complementary explanatory strengths. We collect two new datasets to define and evaluate this task, and propose a novel model which can provide joint textual rationale generation and attention visualization. Our datasets define visual and textual justifications of a classification decision for activity recognition tasks (ACT-X) and for visual question answering tasks (VQA-X). We quantitatively show that training with the textual explanations not only yields better textual justification models, but also better localizes the evidence that supports the decision. We also qualitatively show cases where visual explanation is more insightful than textual explanation, and vice versa, supporting our thesis that multimodal explanation models offer significant benefits over unimodal approaches.
Attentive Explanations: Justifying Decisions and Pointing to the Evidence (Extended Abstract)
Nov 17, 2017
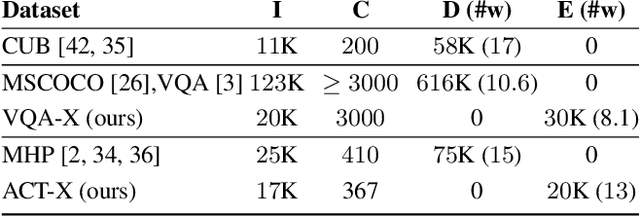

Deep models are the defacto standard in visual decision problems due to their impressive performance on a wide array of visual tasks. On the other hand, their opaqueness has led to a surge of interest in explainable systems. In this work, we emphasize the importance of model explanation in various forms such as visual pointing and textual justification. The lack of data with justification annotations is one of the bottlenecks of generating multimodal explanations. Thus, we propose two large-scale datasets with annotations that visually and textually justify a classification decision for various activities, i.e. ACT-X, and for question answering, i.e. VQA-X. We also introduce a multimodal methodology for generating visual and textual explanations simultaneously. We quantitatively show that training with the textual explanations not only yields better textual justification models, but also models that better localize the evidence that support their decision.
Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training
Nov 06, 2017
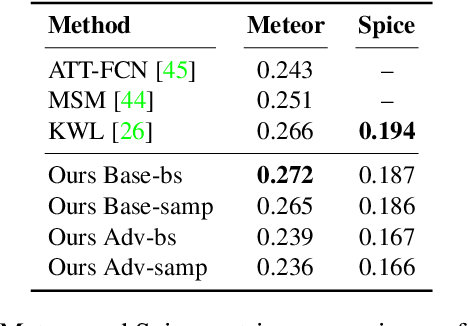
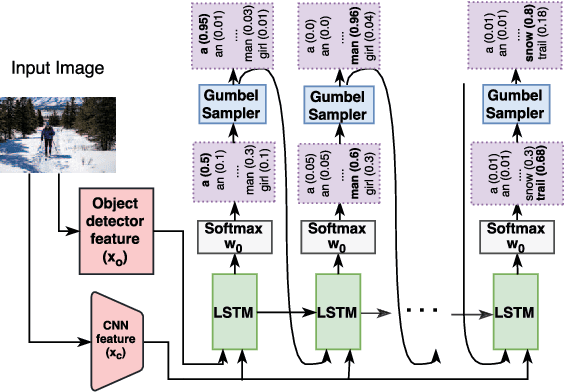
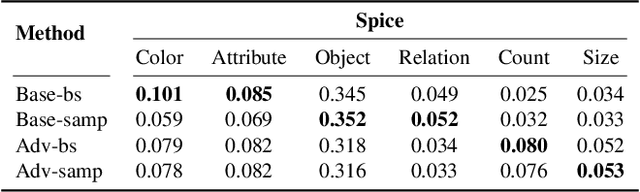
While strong progress has been made in image captioning over the last years, machine and human captions are still quite distinct. A closer look reveals that this is due to the deficiencies in the generated word distribution, vocabulary size, and strong bias in the generators towards frequent captions. Furthermore, humans -- rightfully so -- generate multiple, diverse captions, due to the inherent ambiguity in the captioning task which is not considered in today's systems. To address these challenges, we change the training objective of the caption generator from reproducing groundtruth captions to generating a set of captions that is indistinguishable from human generated captions. Instead of handcrafting such a learning target, we employ adversarial training in combination with an approximate Gumbel sampler to implicitly match the generated distribution to the human one. While our method achieves comparable performance to the state-of-the-art in terms of the correctness of the captions, we generate a set of diverse captions, that are significantly less biased and match the word statistics better in several aspects.
Learning to Reason: End-to-End Module Networks for Visual Question Answering
Sep 11, 2017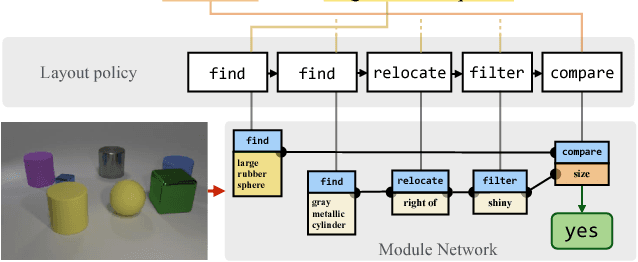

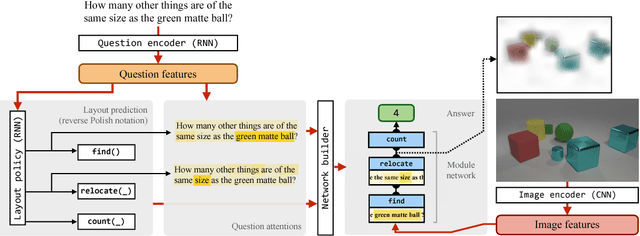

Natural language questions are inherently compositional, and many are most easily answered by reasoning about their decomposition into modular sub-problems. For example, to answer "is there an equal number of balls and boxes?" we can look for balls, look for boxes, count them, and compare the results. The recently proposed Neural Module Network (NMN) architecture implements this approach to question answering by parsing questions into linguistic substructures and assembling question-specific deep networks from smaller modules that each solve one subtask. However, existing NMN implementations rely on brittle off-the-shelf parsers, and are restricted to the module configurations proposed by these parsers rather than learning them from data. In this paper, we propose End-to-End Module Networks (N2NMNs), which learn to reason by directly predicting instance-specific network layouts without the aid of a parser. Our model learns to generate network structures (by imitating expert demonstrations) while simultaneously learning network parameters (using the downstream task loss). Experimental results on the new CLEVR dataset targeted at compositional question answering show that N2NMNs achieve an error reduction of nearly 50% relative to state-of-the-art attentional approaches, while discovering interpretable network architectures specialized for each question.
Attentive Explanations: Justifying Decisions and Pointing to the Evidence
Jul 25, 2017Deep models are the defacto standard in visual decision models due to their impressive performance on a wide array of visual tasks. However, they are frequently seen as opaque and are unable to explain their decisions. In contrast, humans can justify their decisions with natural language and point to the evidence in the visual world which led to their decisions. We postulate that deep models can do this as well and propose our Pointing and Justification (PJ-X) model which can justify its decision with a sentence and point to the evidence by introspecting its decision and explanation process using an attention mechanism. Unfortunately there is no dataset available with reference explanations for visual decision making. We thus collect two datasets in two domains where it is interesting and challenging to explain decisions. First, we extend the visual question answering task to not only provide an answer but also a natural language explanation for the answer. Second, we focus on explaining human activities which is traditionally more challenging than object classification. We extensively evaluate our PJ-X model, both on the justification and pointing tasks, by comparing it to prior models and ablations using both automatic and human evaluations.