 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptable Self-supervised Representation Learning on Remote Sensing Satellite Imagery
Apr 19, 2023This work presents a novel domain adaption paradigm for studying contrastive self-supervised representation learning and knowledge transfer using remote sensing satellite data. Major state-of-the-art remote sensing visual domain efforts primarily focus on fully supervised learning approaches that rely entirely on human annotations. On the other hand, human annotations in remote sensing satellite imagery are always subject to limited quantity due to high costs and domain expertise, making transfer learning a viable alternative. The proposed approach investigates the knowledge transfer of selfsupervised representations across the distinct source and target data distributions in depth in the remote sensing data domain. In this arrangement, self-supervised contrastive learning-based pretraining is performed on the source dataset, and downstream tasks are performed on the target datasets in a round-robin fashion. Experiments are conducted on three publicly available datasets, UC Merced Landuse (UCMD), SIRI-WHU, and MLRSNet, for different downstream classification tasks versus label efficiency. In self-supervised knowledge transfer, the proposed approach achieves state-of-the-art performance with label efficiency labels and outperforms a fully supervised setting. A more in-depth qualitative examination reveals consistent evidence for explainable representation learning. The source code and trained models are published on GitHub.
Deep Perceptual Similarity is Adaptable to Ambiguous Contexts
Apr 05, 2023



The concept of image similarity is ambiguous, meaning that images that are considered similar in one context might not be in another. This ambiguity motivates the creation of metrics for specific contexts. This work explores the ability of the successful deep perceptual similarity (DPS) metrics to adapt to a given context. Recently, DPS metrics have emerged using the deep features of neural networks for comparing images. These metrics have been successful on datasets that leverage the average human perception in limited settings. But the question remains if they could be adapted to specific contexts of similarity. No single metric can suit all definitions of similarity and previous metrics have been rule-based which are labor intensive to rewrite for new contexts. DPS metrics, on the other hand, use neural networks which might be retrained for each context. However, retraining networks takes resources and might ruin performance on previous tasks. This work examines the adaptability of DPS metrics by training positive scalars for the deep features of pretrained CNNs to correctly measure similarity for different contexts. Evaluation is performed on contexts defined by randomly ordering six image distortions (e.g. rotation) by which should be considered more similar when applied to an image. This also gives insight into whether the features in the CNN is enough to discern different distortions without retraining. Finally, the trained metrics are evaluated on a perceptual similarity dataset to evaluate if adapting to an ordering affects their performance on established scenarios. The findings show that DPS metrics can be adapted with high performance. While the adapted metrics have difficulties with the same contexts as baselines, performance is improved in 99% of cases. Finally, it is shown that the adaption is not significantly detrimental to prior performance on perceptual similarity.
WordStylist: Styled Verbatim Handwritten Text Generation with Latent Diffusion Models
Mar 29, 2023



Text-to-Image synthesis is the task of generating an image according to a specific text description. Generative Adversarial Networks have been considered the standard method for image synthesis virtually since their introduction; today, Denoising Diffusion Probabilistic Models are recently setting a new baseline, with remarkable results in Text-to-Image synthesis, among other fields. Aside its usefulness per se, it can also be particularly relevant as a tool for data augmentation to aid training models for other document image processing tasks. In this work, we present a latent diffusion-based method for styled text-to-text-content-image generation on word-level. Our proposed method manages to generate realistic word image samples from different writer styles, by using class index styles and text content prompts without the need of adversarial training, writer recognition, or text recognition. We gauge system performance with Frechet Inception Distance, writer recognition accuracy, and writer retrieval. We show that the proposed model produces samples that are aesthetically pleasing, help boosting text recognition performance, and gets similar writer retrieval score as real data.
Functional Knowledge Transfer with Self-supervised Representation Learning
Mar 12, 2023This work investigates the unexplored usability of self-supervised representation learning in the direction of functional knowledge transfer. In this work, functional knowledge transfer is achieved by joint optimization of self-supervised learning pseudo task and supervised learning task, improving supervised learning task performance. Recent progress in self-supervised learning uses a large volume of data, which becomes a constraint for its applications on small-scale datasets. This work shares a simple yet effective joint training framework that reinforces human-supervised task learning by learning self-supervised representations just-in-time and vice versa. Experiments on three public datasets from different visual domains, Intel Image, CIFAR, and APTOS, reveal a consistent track of performance improvements on classification tasks during joint optimization. Qualitative analysis also supports the robustness of learnt representations. Source code and trained models are available on GitHub.
Lon-eå at SemEval-2023 Task 11: A Comparison of\\Activation Functions for Soft and Hard Label Prediction
Mar 04, 2023We study the influence of different activation functions in the output layer of deep neural network models for soft and hard label prediction in the learning with disagreement task. In this task, the goal is to quantify the amount of disagreement via predicting soft labels. To predict the soft labels, we use BERT-based preprocessors and encoders and vary the activation function used in the output layer, while keeping other parameters constant. The soft labels are then used for the hard label prediction. The activation functions considered are sigmoid as well as a step-function that is added to the model post-training and a sinusoidal activation function, which is introduced for the first time in this paper.
A Systematic Performance Analysis of Deep Perceptual Loss Networks Breaks Transfer Learning Conventions
Feb 08, 2023Deep perceptual loss is a type of loss function in computer vision that aims to mimic human perception by using the deep features extracted from neural networks. In recent years the method has been applied to great effect on a host of interesting computer vision tasks, especially for tasks with image or image-like outputs. Many applications of the method use pretrained networks, often convolutional networks, for loss calculation. Despite the increased interest and broader use, more effort is needed toward exploring which networks to use for calculating deep perceptual loss and from which layers to extract the features. This work aims to rectify this by systematically evaluating a host of commonly used and readily available, pretrained networks for a number of different feature extraction points on four existing use cases of deep perceptual loss. The four use cases are implementations of previous works where the selected networks and extraction points are evaluated instead of the networks and extraction points used in the original work. The experimental tasks are dimensionality reduction, image segmentation, super-resolution, and perceptual similarity. The performance on these four tasks, attributes of the networks, and extraction points are then used as a basis for an in-depth analysis. This analysis uncovers essential information regarding which architectures provide superior performance for deep perceptual loss and how to choose an appropriate extraction point for a particular task and dataset. Furthermore, the work discusses the implications of the results for deep perceptual loss and the broader field of transfer learning. The results break commonly held assumptions in transfer learning, which imply that deep perceptual loss deviates from most transfer learning settings or that these assumptions need a thorough re-evaluation.
Bipol: Multi-axes Evaluation of Bias with Explainability in Benchmark Datasets
Jan 28, 2023



We evaluate five English NLP benchmark datasets (available on the superGLUE leaderboard) for bias, along multiple axes. The datasets are the following: Boolean Question (Boolq), CommitmentBank (CB), Winograd Schema Challenge (WSC), Winogender diagnostic (AXg), and Recognising Textual Entailment (RTE). Bias can be harmful and it is known to be common in data, which ML models learn from. In order to mitigate bias in data, it is crucial to be able to estimate it objectively. We use bipol, a novel multi-axes bias metric with explainability, to quantify and explain how much bias exists in these datasets. Multilingual, multi-axes bias evaluation is not very common. Hence, we also contribute a new, large labelled Swedish bias-detection dataset, with about 2 million samples; translated from the English version. In addition, we contribute new multi-axes lexica for bias detection in Swedish. We train a SotA model on the new dataset for bias detection. We make the codes, model, and new dataset publicly available.
Depth Contrast: Self-Supervised Pretraining on 3DPM Images for Mining Material Classification
Oct 18, 2022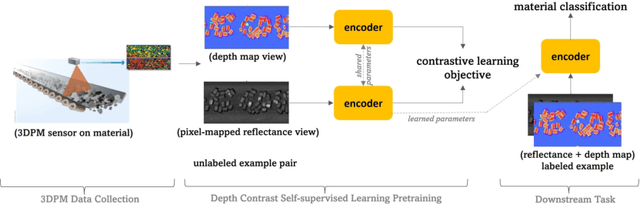
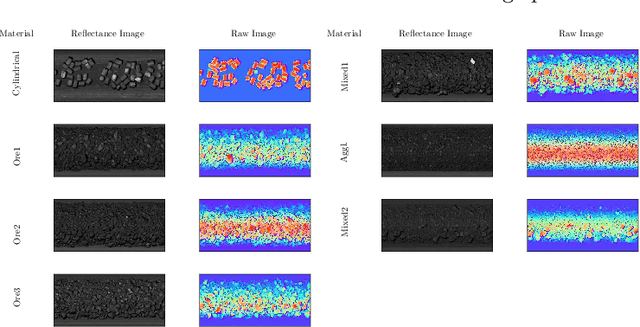
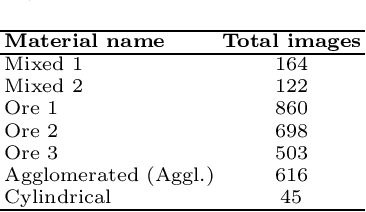
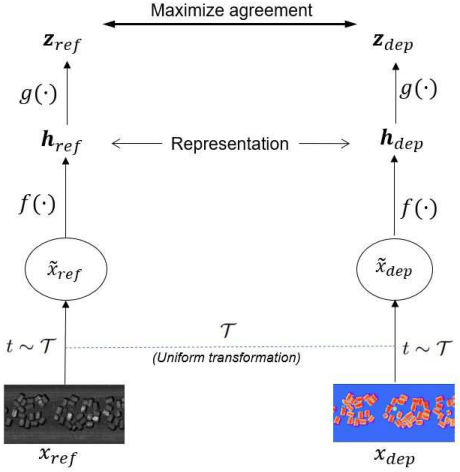
This work presents a novel self-supervised representation learning method to learn efficient representations without labels on images from a 3DPM sensor (3-Dimensional Particle Measurement; estimates the particle size distribution of material) utilizing RGB images and depth maps of mining material on the conveyor belt. Human annotations for material categories on sensor-generated data are scarce and cost-intensive. Currently, representation learning without human annotations remains unexplored for mining materials and does not leverage on utilization of sensor-generated data. The proposed method, Depth Contrast, enables self-supervised learning of representations without labels on the 3DPM dataset by exploiting depth maps and inductive transfer. The proposed method outperforms material classification over ImageNet transfer learning performance in fully supervised learning settings and achieves an F1 score of 0.73. Further, The proposed method yields an F1 score of 0.65 with an 11% improvement over ImageNet transfer learning performance in a semi-supervised setting when only 20% of labels are used in fine-tuning. Finally, the Proposed method showcases improved performance generalization on linear evaluation. The implementation of proposed method is available on GitHub.
Multi-Task Meta Learning: learn how to adapt to unseen tasks
Oct 13, 2022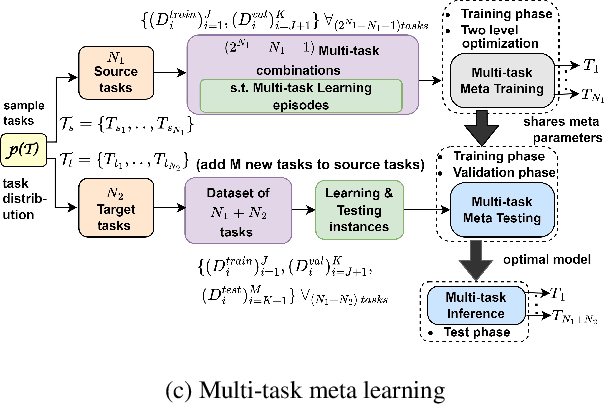
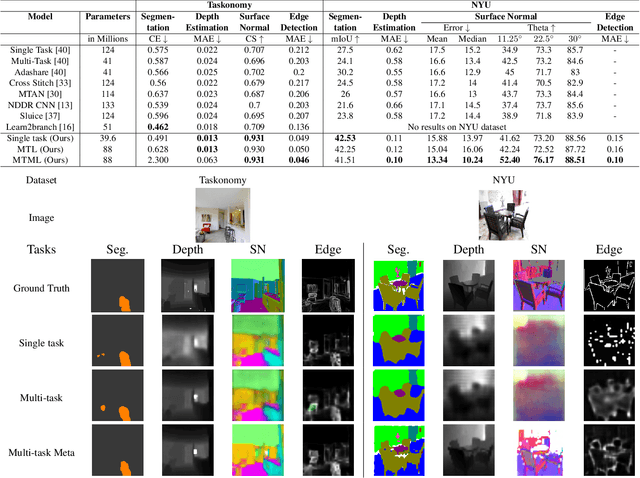
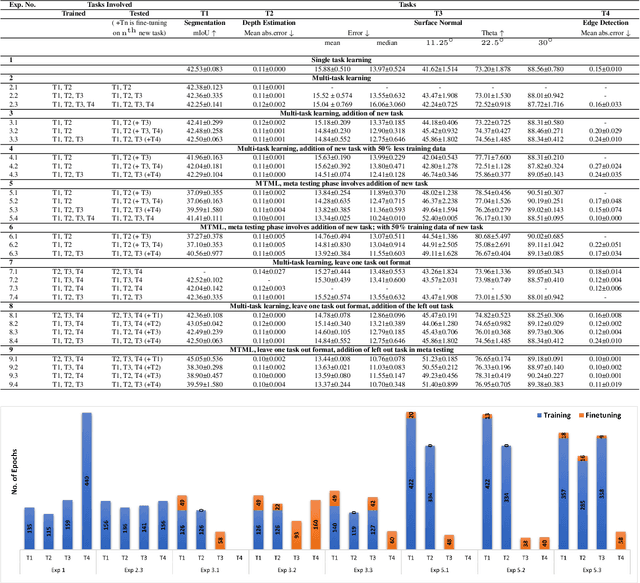
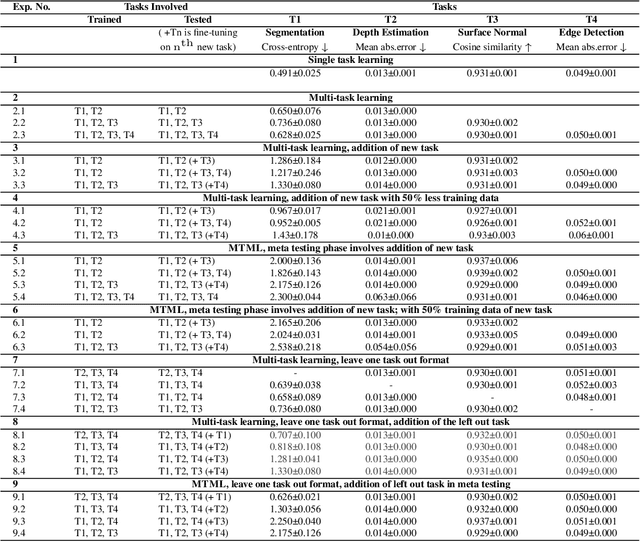
This work aims to integrate two learning paradigms Multi-Task Learning (MTL) and meta learning, to bring together the best of both worlds, i.e., simultaneous learning of multiple tasks, an element of MTL and promptly adapting to new tasks with fewer data, a quality of meta learning. We propose Multi-task Meta Learning (MTML), an approach to enhance MTL compared to single task learning by employing meta learning. The fundamental idea of this work is to train a multi-task model, such that when an unseen task is introduced, it can learn in fewer steps whilst offering a performance at least as good as conventional single task learning on the new task or inclusion within the MTL. By conducting various experiments, we demonstrate this paradigm on two datasets and four tasks: NYU-v2 and the taskonomy dataset for which we perform semantic segmentation, depth estimation, surface normal estimation, and edge detection. MTML achieves state-of-the-art results for most of the tasks, and MTL also performs reasonably well for all tasks compared to single task learning.
T5 for Hate Speech, Augmented Data and Ensemble
Oct 11, 2022
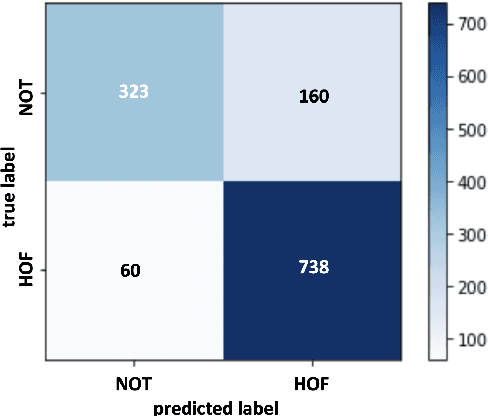
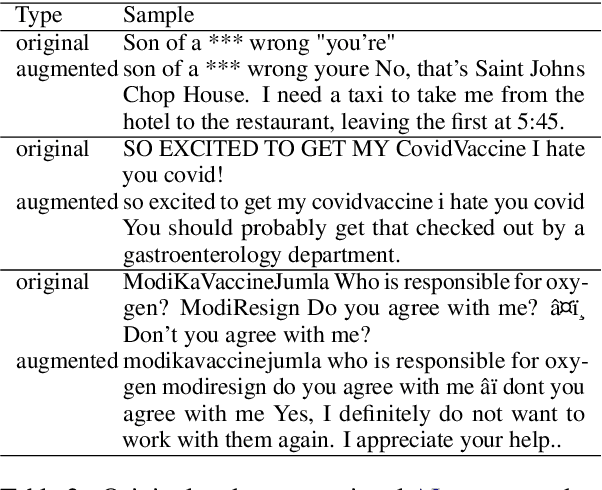
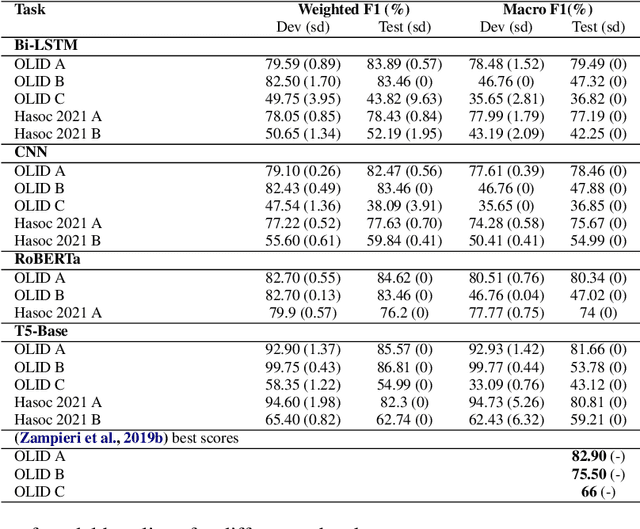
We conduct relatively extensive investigations of automatic hate speech (HS) detection using different state-of-the-art (SoTA) baselines over 11 subtasks of 6 different datasets. Our motivation is to determine which of the recent SoTA models is best for automatic hate speech detection and what advantage methods like data augmentation and ensemble may have on the best model, if any. We carry out 6 cross-task investigations. We achieve new SoTA on two subtasks - macro F1 scores of 91.73% and 53.21% for subtasks A and B of the HASOC 2020 dataset, where previous SoTA are 51.52% and 26.52%, respectively. We achieve near-SoTA on two others - macro F1 scores of 81.66% for subtask A of the OLID 2019 dataset and 82.54% for subtask A of the HASOC 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and use two explainable artificial intelligence (XAI) algorithms (IG and SHAP) to reveal how two of the models (Bi-LSTM and T5) make the predictions they do by using examples. Other contributions of this work are 1) the introduction of a simple, novel mechanism for correcting out-of-class (OOC) predictions in T5, 2) a detailed description of the data augmentation methods, 3) the revelation of the poor data annotations in the HASOC 2021 dataset by using several examples and XAI (buttressing the need for better quality control), and 4) the public release of our model checkpoints and codes to foster transparency.