 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Shape Gap: A Benchmark and Baseline for Deformation-Aware 6D Pose Estimation of Agricultural Produce
Mar 28, 2026Accurate 6D pose estimation for robotic harvesting is fundamentally hindered by the biological deformability and high intra-class shape variability of agricultural produce. Instance-level methods fail in this setting, as obtaining exact 3D models for every unique piece of produce is practically infeasible, while category-level approaches that rely on a fixed template suffer significant accuracy degradation when the prior deviates from the true instance geometry. To bridge such lack of robustness to deformation, we introduce PEAR (Pose and dEformation of Agricultural pRoduce), the first benchmark providing joint 6D pose and per-instance 3D deformation ground truth across 8 produce categories, acquired via a robotic manipulator for high annotation accuracy. Using PEAR, we show that state-of-the-art methods suffer up to 6x performance degradation when faced with the inherent geometric deviations of real-world produce. Motivated by this finding, we propose SEED (Simultaneous Estimation of posE and Deformation), a unified RGB-only framework that jointly predicts 6D pose and explicit lattice deformations from a single image across multiple produce categories. Trained entirely on synthetic data with generative texture augmentation applied at the UV level, SEED outperforms MegaPose on 6 out of 8 categories under identical RGB-only conditions, demonstrating that explicit shape modeling is a critical step toward reliable pose estimation in agricultural robotics.
Dual Orthogonal Guidance for Robust Diffusion-based Handwritten Text Generation
Aug 23, 2025Diffusion-based Handwritten Text Generation (HTG) approaches achieve impressive results on frequent, in-vocabulary words observed at training time and on regular styles. However, they are prone to memorizing training samples and often struggle with style variability and generation clarity. In particular, standard diffusion models tend to produce artifacts or distortions that negatively affect the readability of the generated text, especially when the style is hard to produce. To tackle these issues, we propose a novel sampling guidance strategy, Dual Orthogonal Guidance (DOG), that leverages an orthogonal projection of a negatively perturbed prompt onto the original positive prompt. This approach helps steer the generation away from artifacts while maintaining the intended content, and encourages more diverse, yet plausible, outputs. Unlike standard Classifier-Free Guidance (CFG), which relies on unconditional predictions and produces noise at high guidance scales, DOG introduces a more stable, disentangled direction in the latent space. To control the strength of the guidance across the denoising process, we apply a triangular schedule: weak at the start and end of denoising, when the process is most sensitive, and strongest in the middle steps. Experimental results on the state-of-the-art DiffusionPen and One-DM demonstrate that DOG improves both content clarity and style variability, even for out-of-vocabulary words and challenging writing styles.
Quo Vadis Handwritten Text Generation for Handwritten Text Recognition?
Aug 13, 2025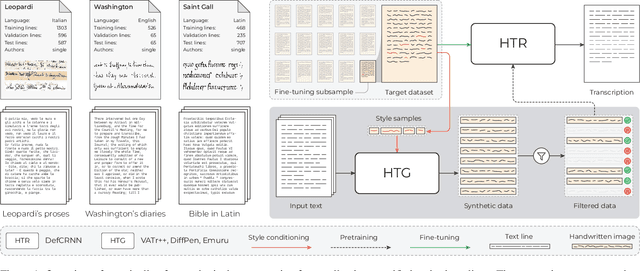


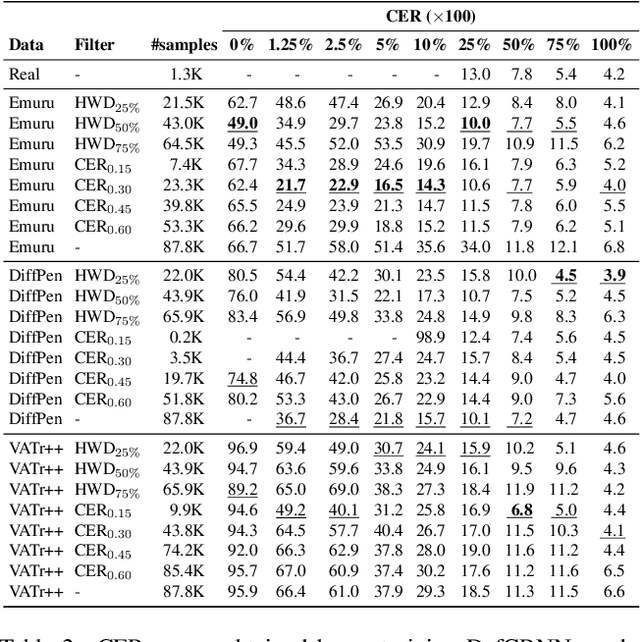
The digitization of historical manuscripts presents significant challenges for Handwritten Text Recognition (HTR) systems, particularly when dealing with small, author-specific collections that diverge from the training data distributions. Handwritten Text Generation (HTG) techniques, which generate synthetic data tailored to specific handwriting styles, offer a promising solution to address these challenges. However, the effectiveness of various HTG models in enhancing HTR performance, especially in low-resource transcription settings, has not been thoroughly evaluated. In this work, we systematically compare three state-of-the-art styled HTG models (representing the generative adversarial, diffusion, and autoregressive paradigms for HTG) to assess their impact on HTR fine-tuning. We analyze how visual and linguistic characteristics of synthetic data influence fine-tuning outcomes and provide quantitative guidelines for selecting the most effective HTG model. The results of our analysis provide insights into the current capabilities of HTG methods and highlight key areas for further improvement in their application to low-resource HTR.
Only-Style: Stylistic Consistency in Image Generation without Content Leakage
Jun 11, 2025Generating images in a consistent reference visual style remains a challenging computer vision task. State-of-the-art methods aiming for style-consistent generation struggle to effectively separate semantic content from stylistic elements, leading to content leakage from the image provided as a reference to the targets. To address this challenge, we propose Only-Style: a method designed to mitigate content leakage in a semantically coherent manner while preserving stylistic consistency. Only-Style works by localizing content leakage during inference, allowing the adaptive tuning of a parameter that controls the style alignment process, specifically within the image patches containing the subject in the reference image. This adaptive process best balances stylistic consistency with leakage elimination. Moreover, the localization of content leakage can function as a standalone component, given a reference-target image pair, allowing the adaptive tuning of any method-specific parameter that provides control over the impact of the stylistic reference. In addition, we propose a novel evaluation framework to quantify the success of style-consistent generations in avoiding undesired content leakage. Our approach demonstrates a significant improvement over state-of-the-art methods through extensive evaluation across diverse instances, consistently achieving robust stylistic consistency without undesired content leakage.
Object-Centric Action-Enhanced Representations for Robot Visuo-Motor Policy Learning
May 27, 2025Learning visual representations from observing actions to benefit robot visuo-motor policy generation is a promising direction that closely resembles human cognitive function and perception. Motivated by this, and further inspired by psychological theories suggesting that humans process scenes in an object-based fashion, we propose an object-centric encoder that performs semantic segmentation and visual representation generation in a coupled manner, unlike other works, which treat these as separate processes. To achieve this, we leverage the Slot Attention mechanism and use the SOLV model, pretrained in large out-of-domain datasets, to bootstrap fine-tuning on human action video data. Through simulated robotic tasks, we demonstrate that visual representations can enhance reinforcement and imitation learning training, highlighting the effectiveness of our integrated approach for semantic segmentation and encoding. Furthermore, we show that exploiting models pretrained on out-of-domain datasets can benefit this process, and that fine-tuning on datasets depicting human actions -- although still out-of-domain -- , can significantly improve performance due to close alignment with robotic tasks. These findings show the capability to reduce reliance on annotated or robot-specific action datasets and the potential to build on existing visual encoders to accelerate training and improve generalizability.
Proactive tactile exploration for object-agnostic shape reconstruction from minimal visual priors
May 17, 2025



The perception of an object's surface is important for robotic applications enabling robust object manipulation. The level of accuracy in such a representation affects the outcome of the action planning, especially during tasks that require physical contact, e.g. grasping. In this paper, we propose a novel iterative method for 3D shape reconstruction consisting of two steps. At first, a mesh is fitted on data points acquired from the object's surface, based on a single primitive template. Subsequently, the mesh is properly adjusted to adequately represent local deformities. Moreover, a novel proactive tactile exploration strategy aims at minimizing the total uncertainty with the least number of contacts, while reducing the risk of contact failure in case the estimated surface differs significantly from the real one. The performance of the methodology is evaluated both in 3D simulation and on a real setup.
Pre-training for Action Recognition with Automatically Generated Fractal Datasets
Nov 26, 2024In recent years, interest in synthetic data has grown, particularly in the context of pre-training the image modality to support a range of computer vision tasks, including object classification, medical imaging etc. Previous work has demonstrated that synthetic samples, automatically produced by various generative processes, can replace real counterparts and yield strong visual representations. This approach resolves issues associated with real data such as collection and labeling costs, copyright and privacy. We extend this trend to the video domain applying it to the task of action recognition. Employing fractal geometry, we present methods to automatically produce large-scale datasets of short synthetic video clips, which can be utilized for pre-training neural models. The generated video clips are characterized by notable variety, stemmed by the innate ability of fractals to generate complex multi-scale structures. To narrow the domain gap, we further identify key properties of real videos and carefully emulate them during pre-training. Through thorough ablations, we determine the attributes that strengthen downstream results and offer general guidelines for pre-training with synthetic videos. The proposed approach is evaluated by fine-tuning pre-trained models on established action recognition datasets HMDB51 and UCF101 as well as four other video benchmarks related to group action recognition, fine-grained action recognition and dynamic scenes. Compared to standard Kinetics pre-training, our reported results come close and are even superior on a portion of downstream datasets. Code and samples of synthetic videos are available at https://github.com/davidsvy/fractal_video .
DiffusionPen: Towards Controlling the Style of Handwritten Text Generation
Sep 09, 2024



Handwritten Text Generation (HTG) conditioned on text and style is a challenging task due to the variability of inter-user characteristics and the unlimited combinations of characters that form new words unseen during training. Diffusion Models have recently shown promising results in HTG but still remain under-explored. We present DiffusionPen (DiffPen), a 5-shot style handwritten text generation approach based on Latent Diffusion Models. By utilizing a hybrid style extractor that combines metric learning and classification, our approach manages to capture both textual and stylistic characteristics of seen and unseen words and styles, generating realistic handwritten samples. Moreover, we explore several variation strategies of the data with multi-style mixtures and noisy embeddings, enhancing the robustness and diversity of the generated data. Extensive experiments using IAM offline handwriting database show that our method outperforms existing methods qualitatively and quantitatively, and its additional generated data can improve the performance of Handwriting Text Recognition (HTR) systems. The code is available at: https://github.com/koninik/DiffusionPen.
Rethinking HTG Evaluation: Bridging Generation and Recognition
Sep 04, 2024The evaluation of generative models for natural image tasks has been extensively studied. Similar protocols and metrics are used in cases with unique particularities, such as Handwriting Generation, even if they might not be completely appropriate. In this work, we introduce three measures tailored for HTG evaluation, $ \text{HTG}_{\text{HTR}} $, $ \text{HTG}_{\text{style}} $, and $ \text{HTG}_{\text{OOV}} $, and argue that they are more expedient to evaluate the quality of generated handwritten images. The metrics rely on the recognition error/accuracy of Handwriting Text Recognition and Writer Identification models and emphasize writing style, textual content, and diversity as the main aspects that adhere to the content of handwritten images. We conduct comprehensive experiments on the IAM handwriting database, showcasing that widely used metrics such as FID fail to properly quantify the diversity and the practical utility of generated handwriting samples. Our findings show that our metrics are richer in information and underscore the necessity of standardized evaluation protocols in HTG. The proposed metrics provide a more robust and informative protocol for assessing HTG quality, contributing to improved performance in HTR. Code for the evaluation protocol is available at: https://github.com/koninik/HTG_evaluation.
Mushroom Segmentation and 3D Pose Estimation from Point Clouds using Fully Convolutional Geometric Features and Implicit Pose Encoding
Apr 17, 2024



Modern agricultural applications rely more and more on deep learning solutions. However, training well-performing deep networks requires a large amount of annotated data that may not be available and in the case of 3D annotation may not even be feasible for human annotators. In this work, we develop a deep learning approach to segment mushrooms and estimate their pose on 3D data, in the form of point clouds acquired by depth sensors. To circumvent the annotation problem, we create a synthetic dataset of mushroom scenes, where we are fully aware of 3D information, such as the pose of each mushroom. The proposed network has a fully convolutional backbone, that parses sparse 3D data, and predicts pose information that implicitly defines both instance segmentation and pose estimation task. We have validated the effectiveness of the proposed implicit-based approach for a synthetic test set, as well as provided qualitative results for a small set of real acquired point clouds with depth sensors. Code is publicly available at https://github.com/georgeretsi/mushroom-pose.