 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntmaxKV: Support-Aware Decoding for Entmax Attention
May 20, 2026Long-context decoding is increasingly limited by KV-cache memory traffic since each generated token attends over a cache whose size grows linearly with context length. Existing sparse decoding methods reduce this cost by selecting subsets of tokens or pages, but are designed for softmax attention, whose dense tails make any truncation discard nonzero probability mass. In contrast, $α$-entmax produces exact zeros, turning sparse decoding from dense-tail approximation into support recovery: if the selected candidates contain the entmax support, sparse decoding remains exact. While recent entmax kernels enable efficient training, they do not address the autoregressive decoding bottleneck, where dense inference still streams the full KV cache before sparsity is known. In this work, we introduce EntmaxKV, an entmax-native sparse decoding framework that exploits sparsity before KV pages are loaded. EntmaxKV combines query-aware page scoring, support-aware candidate selection, and sparse entmax attention. We analyze truncation error through the dropped probability mass $δ$, showing that output error is controlled by $δ$ and vanishes when the entmax support is recovered. We further introduce a Gaussian-aware entmax selector that estimates the entmax threshold from lightweight page statistics, adapting the selected budget to the score distribution. Empirically, EntmaxKV drops less probability mass, retains more support tokens, and achieves lower output error than softmax-based sparse decoding at matched KV budgets. On long-context and language modeling benchmarks, it closely matches full-cache entmax while using a small fraction of the KV cache, achieving up to $3.36\times$ (softmax) and $5.43\times$ (entmax) speedup over full attention baselines at 1M context length. Code available at: https://github.com/deep-spin/entmaxkv.
DashAttention: Differentiable and Adaptive Sparse Hierarchical Attention
May 18, 2026Current hierarchical attention methods, such as NSA and InfLLMv2, select the top-k relevant key-value (KV) blocks based on coarse attention scores and subsequently apply fine-grained softmax attention on the selected tokens. However, the top-k operation assumes the number of relevant tokens for any query is fixed and it precludes the gradient flow between the sparse and dense stages. In this work, we propose DashAttention (Differentiable and Adaptive Sparse Hierarchical Attention), which leverages the adaptively sparse $α$-entmax transformation to select a variable number of blocks according to the current query in the first stage. This in turn provides a prior for the second-stage softmax attention, keeping the entire hierarchy fully differentiable. Contrary to other hierarchical attention methods, we show that DashAttention is non-dispersive, translating to better long-context modeling ability. Experiments with large language models (LLMs) show that DashAttention achieves comparable accuracy as full attention with 75% sparsity and a better Pareto frontier than NSA and InfLLMv2, especially in high-sparsity regimes. We also provide an efficient, GPU-aware implementation of DashAttention in Triton, which achieves a speedup of up to over FlashAttention-3 at inference time. Overall, DashAttention offers a cost-effective strategy to model long contexts.
Towards Prediction Explainability through Sparse Communication
Apr 28, 2020

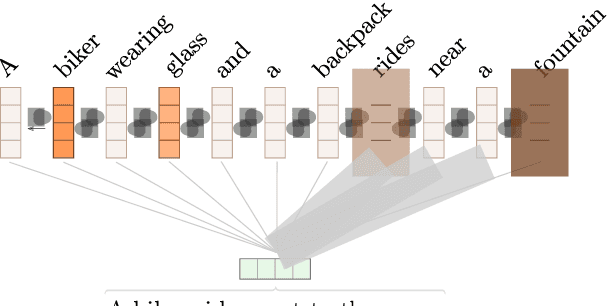
Explainability is a topic of growing importance in NLP. In this work, we provide a unified perspective of explainability as a communication problem between an explainer and a layperson about a classifier's decision. We use this framework to compare several prior approaches for extracting explanations, including gradient methods, representation erasure, and attention mechanisms, in terms of their communication success. In addition, we reinterpret these methods at the light of classical feature selection, and we use this as inspiration to propose new embedded methods for explainability, through the use of selective, sparse attention. Experiments in text classification, natural language entailment, and machine translation, using different configurations of explainers and laypeople (including both machines and humans), reveal an advantage of attention-based explainers over gradient and erasure methods. Furthermore, human evaluation experiments show promising results with post-hoc explainers trained to optimize communication success and faithfulness.
Evaluating Word Embeddings for Sentence Boundary Detection in Speech Transcripts
Aug 15, 2017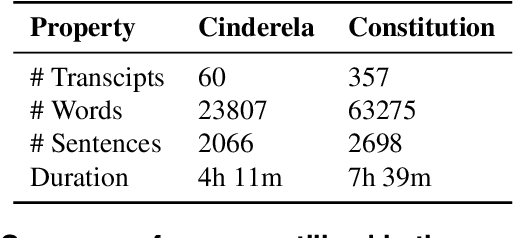
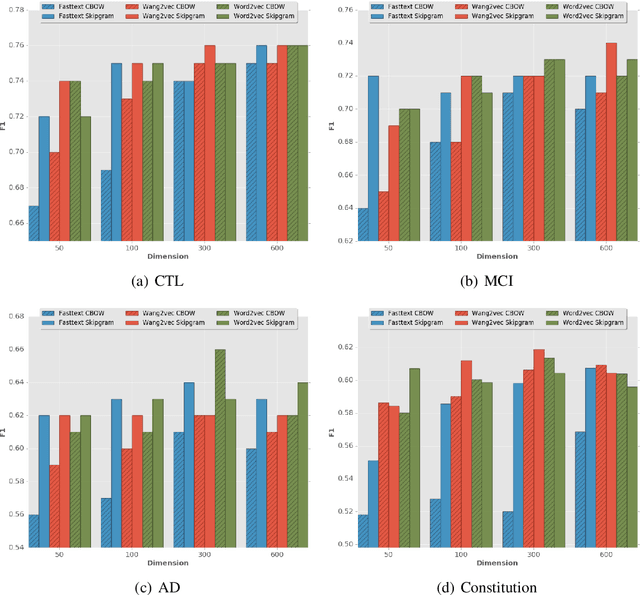
This paper is motivated by the automation of neuropsychological tests involving discourse analysis in the retellings of narratives by patients with potential cognitive impairment. In this scenario the task of sentence boundary detection in speech transcripts is important as discourse analysis involves the application of Natural Language Processing tools, such as taggers and parsers, which depend on the sentence as a processing unit. Our aim in this paper is to verify which embedding induction method works best for the sentence boundary detection task, specifically whether it be those which were proposed to capture semantic, syntactic or morphological similarities.
PELESent: Cross-domain polarity classification using distant supervision
Jul 09, 2017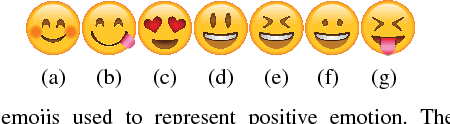
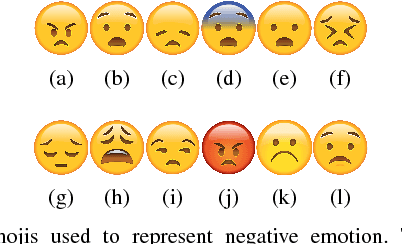
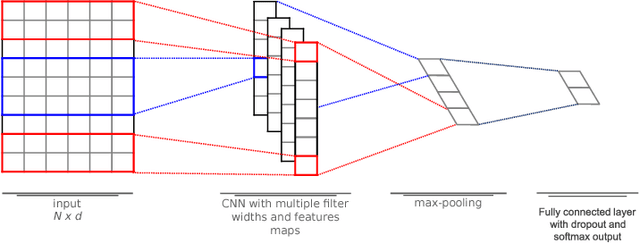
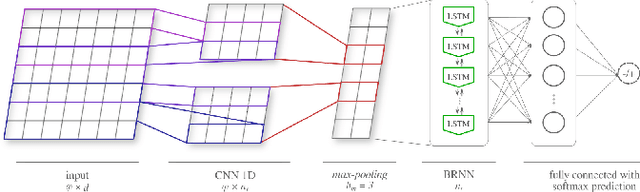
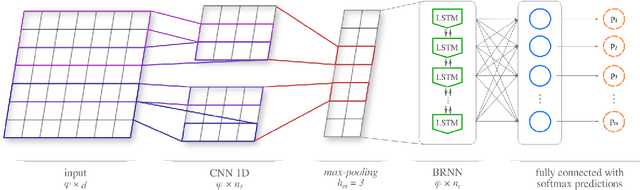
The enormous amount of texts published daily by Internet users has fostered the development of methods to analyze this content in several natural language processing areas, such as sentiment analysis. The main goal of this task is to classify the polarity of a message. Even though many approaches have been proposed for sentiment analysis, some of the most successful ones rely on the availability of large annotated corpus, which is an expensive and time-consuming process. In recent years, distant supervision has been used to obtain larger datasets. So, inspired by these techniques, in this paper we extend such approaches to incorporate popular graphic symbols used in electronic messages, the emojis, in order to create a large sentiment corpus for Portuguese. Trained on almost one million tweets, several models were tested in both same domain and cross-domain corpora. Our methods obtained very competitive results in five annotated corpora from mixed domains (Twitter and product reviews), which proves the domain-independent property of such approach. In addition, our results suggest that the combination of emoticons and emojis is able to properly capture the sentiment of a message.