 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANAS: Multi-Agent Neural Architecture Search
Sep 05, 2019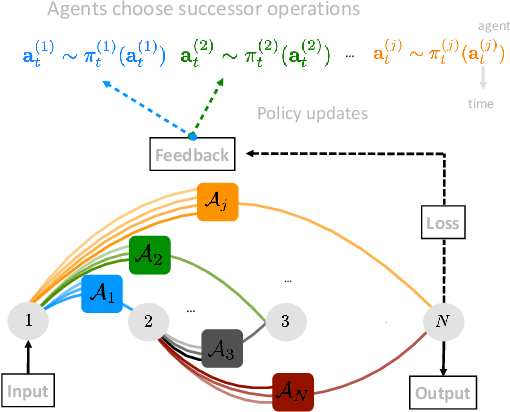
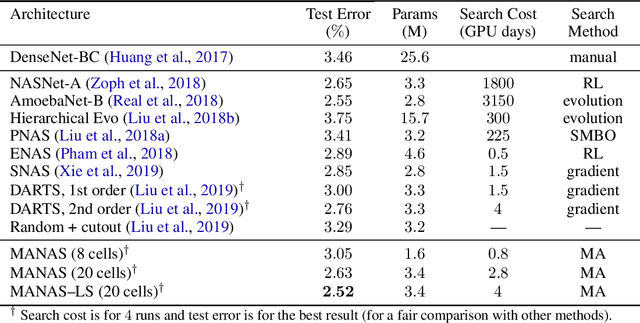
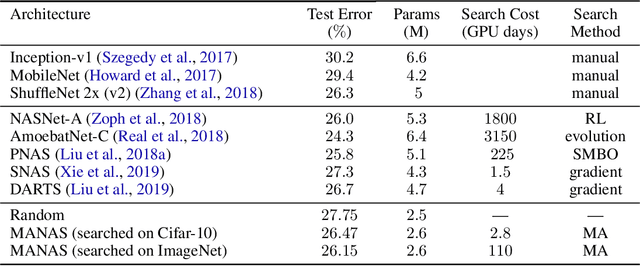
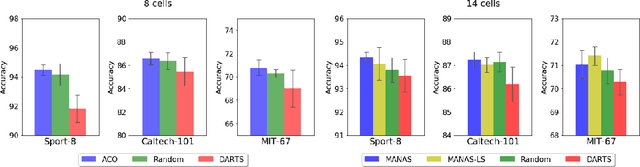
The Neural Architecture Search (NAS) problem is typically formulated as a graph search problem where the goal is to learn the optimal operations over edges in order to maximise a graph-level global objective. Due to the large architecture parameter space, efficiency is a key bottleneck preventing NAS from its practical use. In this paper, we address the issue by framing NAS as a multi-agent problem where agents control a subset of the network and coordinate to reach optimal architectures. We provide two distinct lightweight implementations, with reduced memory requirements (1/8th of state-of-the-art), and performances above those of much more computationally expensive methods. Theoretically, we demonstrate vanishing regrets of the form O(sqrt(T)), with T being the total number of rounds. Finally, aware that random search is an, often ignored, effective baseline we perform additional experiments on 3 alternative datasets and 2 network configurations, and achieve favourable results in comparison.
Boundary Optimizing Network (BON)
Jan 23, 2018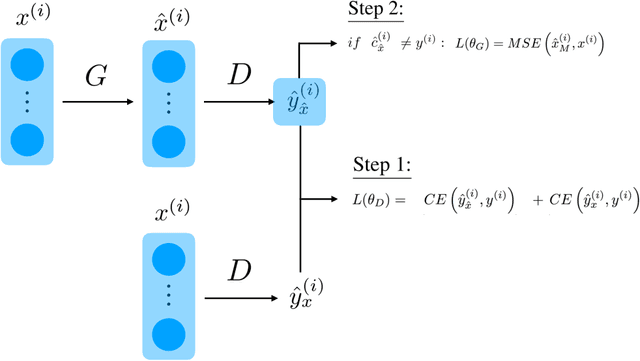
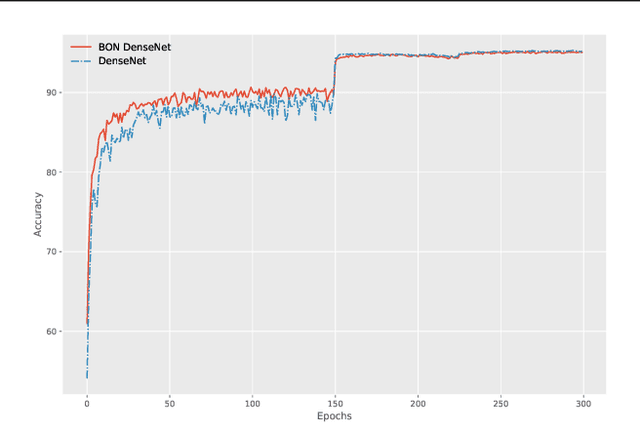
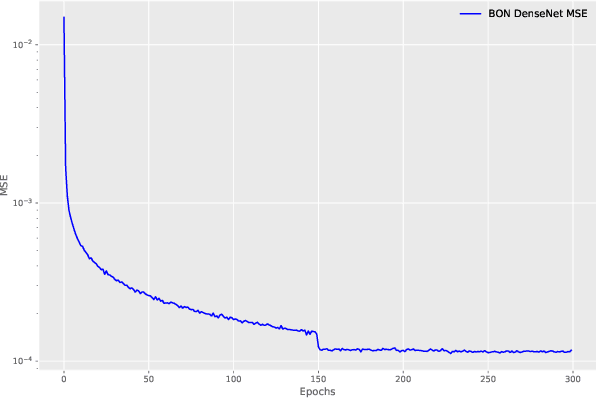
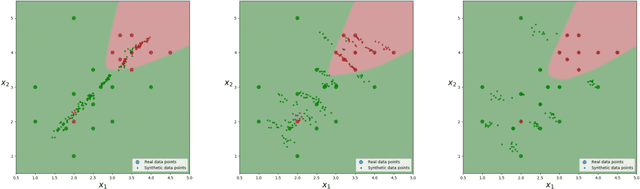
Despite all the success that deep neural networks have seen in classifying certain datasets, the challenge of finding optimal solutions that generalize still remains. In this paper, we propose the Boundary Optimizing Network (BON), a new approach to generalization for deep neural networks when used for supervised learning. Given a classification network, we propose to use a collaborative generative network that produces new synthetic data points in the form of perturbations of original data points. In this way, we create a data support around each original data point which prevents decision boundaries from passing too close to the original data points, i.e. prevents overfitting. We show that BON improves convergence on CIFAR-10 using the state-of-the-art Densenet. We do however observe that the generative network suffers from catastrophic forgetting during training, and we therefore propose to use a variation of Memory Aware Synapses to optimize the generative network (called BON++). On the Iris dataset, we visualize the effect of BON++ when the generator does not suffer from catastrophic forgetting and conclude that the approach has the potential to create better boundaries in a higher dimensional space.
Exploiting Nontrivial Connectivity for Automatic Speech Recognition
Nov 28, 2017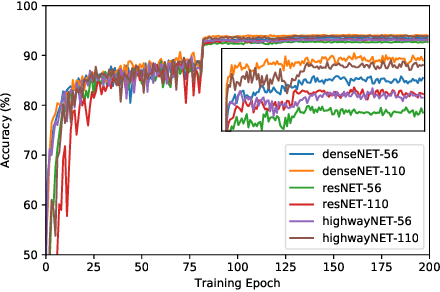
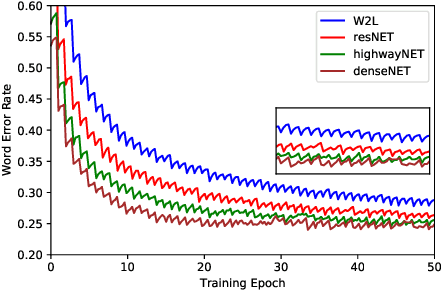

Nontrivial connectivity has allowed the training of very deep networks by addressing the problem of vanishing gradients and offering a more efficient method of reusing parameters. In this paper we make a comparison between residual networks, densely-connected networks and highway networks on an image classification task. Next, we show that these methodologies can easily be deployed into automatic speech recognition and provide significant improvements to existing models.