 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Speech-to-Speech Translation to Automatic Dubbing
Feb 02, 2020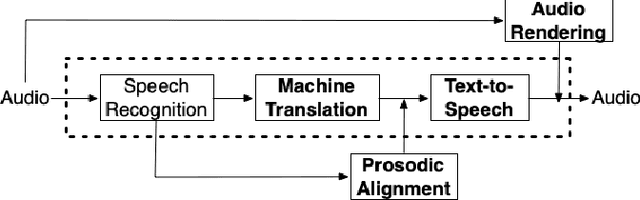

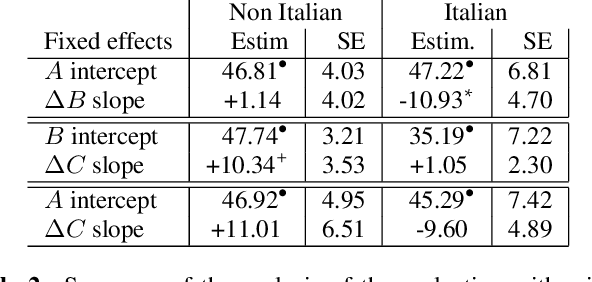
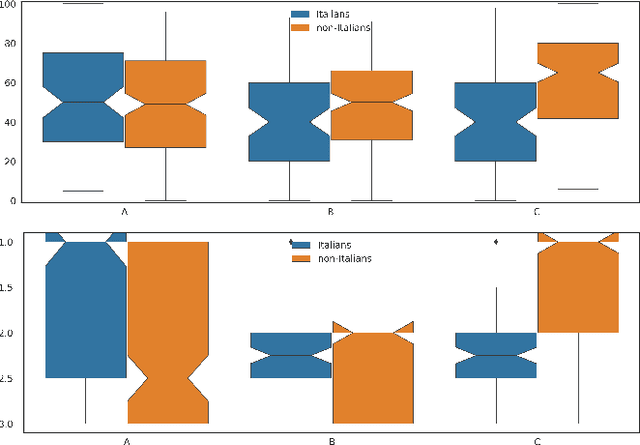
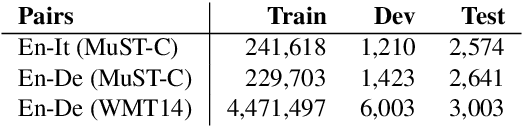
We present enhancements to a speech-to-speech translation pipeline in order to perform automatic dubbing. Our architecture features neural machine translation generating output of preferred length, prosodic alignment of the translation with the original speech segments, neural text-to-speech with fine tuning of the duration of each utterance, and, finally, audio rendering to enriches text-to-speech output with background noise and reverberation extracted from the original audio. We report on a subjective evaluation of automatic dubbing of excerpts of TED Talks from English into Italian, which measures the perceived naturalness of automatic dubbing and the relative importance of each proposed enhancement.
Adapting Multilingual Neural Machine Translation to Unseen Languages
Oct 30, 2019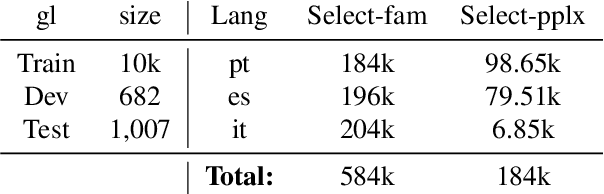
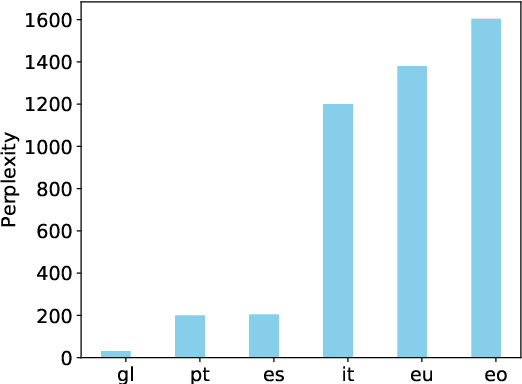
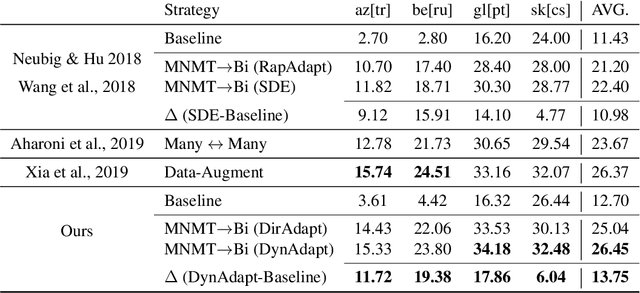
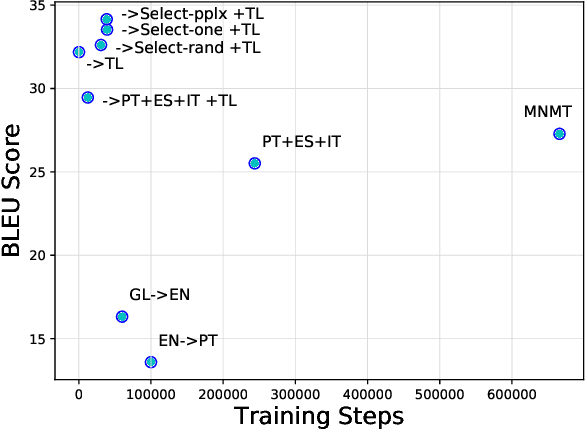
Multilingual Neural Machine Translation (MNMT) for low-resource languages (LRL) can be enhanced by the presence of related high-resource languages (HRL), but the relatedness of HRL usually relies on predefined linguistic assumptions about language similarity. Recently, adapting MNMT to a LRL has shown to greatly improve performance. In this work, we explore the problem of adapting an MNMT model to an unseen LRL using data selection and model adaptation. In order to improve NMT for LRL, we employ perplexity to select HRL data that are most similar to the LRL on the basis of language distance. We extensively explore data selection in popular multilingual NMT settings, namely in (zero-shot) translation, and in adaptation from a multilingual pre-trained model, for both directions (LRL-en). We further show that dynamic adaptation of the model's vocabulary results in a more favourable segmentation for the LRL in comparison with direct adaptation. Experiments show reductions in training time and significant performance gains over LRL baselines, even with zero LRL data (+13.0 BLEU), up to +17.0 BLEU for pre-trained multilingual model dynamic adaptation with related data selection. Our method outperforms current approaches, such as massively multilingual models and data augmentation, on four LRL.
Controlling the Output Length of Neural Machine Translation
Oct 25, 2019

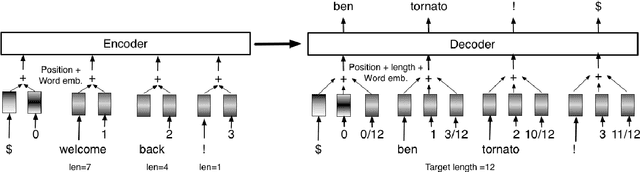
The recent advances introduced by neural machine translation (NMT) are rapidly expanding the application fields of machine translation, as well as reshaping the quality level to be targeted. In particular, if translations have to fit some given layout, quality should not only be measured in terms of adequacy and fluency, but also length. Exemplary cases are the translation of document files, subtitles, and scripts for dubbing, where the output length should ideally be as close as possible to the length of the input text. This paper addresses for the first time, to the best of our knowledge, the problem of controlling the output length in NMT. We investigate two methods for biasing the output length with a transformer architecture: i) conditioning the output to a given target-source length-ratio class and ii) enriching the transformer positional embedding with length information. Our experiments show that both methods can induce the network to generate shorter translations, as well as acquiring interpretable linguistic skills.
Robust Neural Machine Translation for Clean and Noisy Speech Transcripts
Oct 22, 2019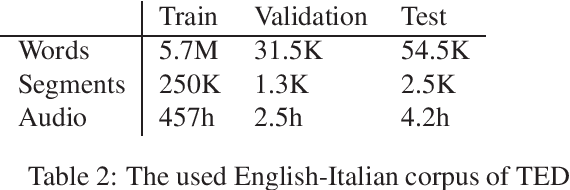
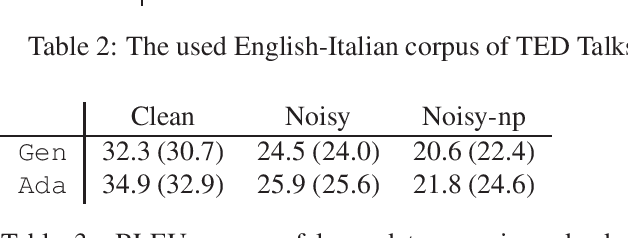
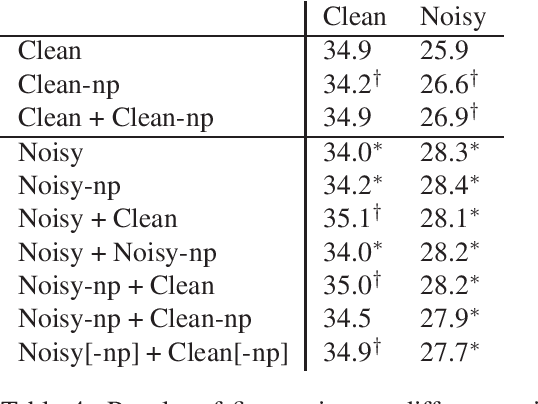
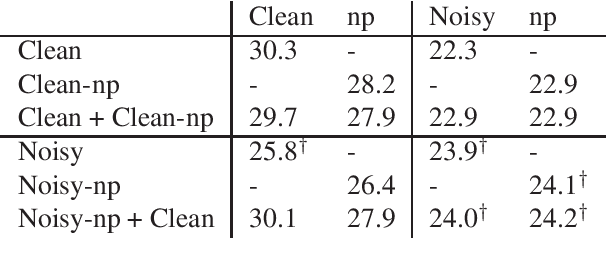
Neural machine translation models have shown to achieve high quality when trained and fed with well structured and punctuated input texts. Unfortunately, the latter condition is not met in spoken language translation, where the input is generated by an automatic speech recognition (ASR) system. In this paper, we study how to adapt a strong NMT system to make it robust to typical ASR errors. As in our application scenarios transcripts might be post-edited by human experts, we propose adaptation strategies to train a single system that can translate either clean or noisy input with no supervision on the input type. Our experimental results on a public speech translation data set show that adapting a model on a significant amount of parallel data including ASR transcripts is beneficial with test data of the same type, but produces a small degradation when translating clean text. Adapting on both clean and noisy variants of the same data leads to the best results on both input types.
On the Importance of Word Boundaries in Character-level Neural Machine Translation
Oct 21, 2019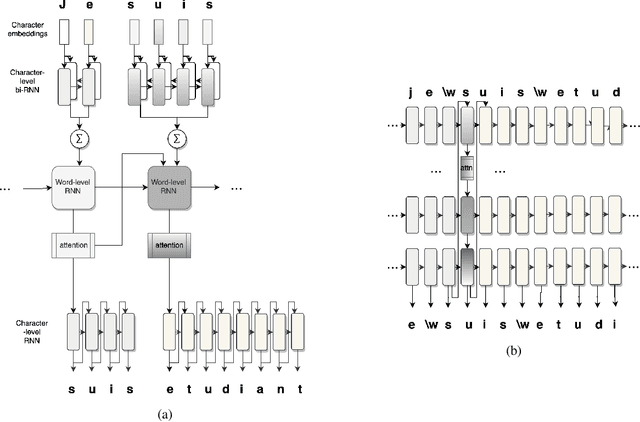
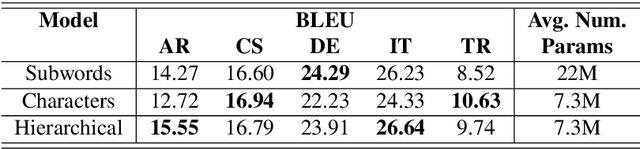
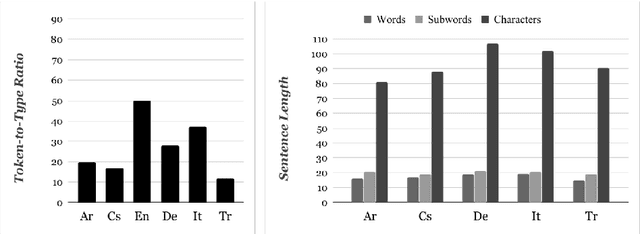
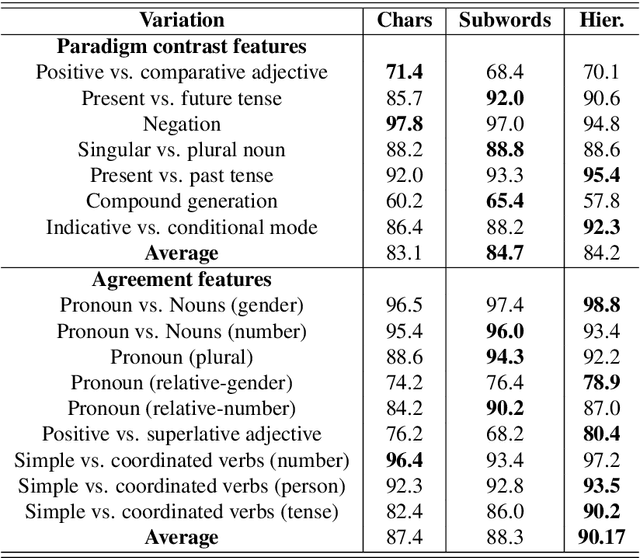
Neural Machine Translation (NMT) models generally perform translation using a fixed-size lexical vocabulary, which is an important bottleneck on their generalization capability and overall translation quality. The standard approach to overcome this limitation is to segment words into subword units, typically using some external tools with arbitrary heuristics, resulting in vocabulary units not optimized for the translation task. Recent studies have shown that the same approach can be extended to perform NMT directly at the level of characters, which can deliver translation accuracy on-par with subword-based models, on the other hand, this requires relatively deeper networks. In this paper, we propose a more computationally-efficient solution for character-level NMT which implements a hierarchical decoding architecture where translations are subsequently generated at the level of words and characters. We evaluate different methods for open-vocabulary NMT in the machine translation task from English into five languages with distinct morphological typology, and show that the hierarchical decoding model can reach higher translation accuracy than the subword-level NMT model using significantly fewer parameters, while demonstrating better capacity in learning longer-distance contextual and grammatical dependencies than the standard character-level NMT model.
Multilingual Neural Machine Translation for Zero-Resource Languages
Sep 16, 2019
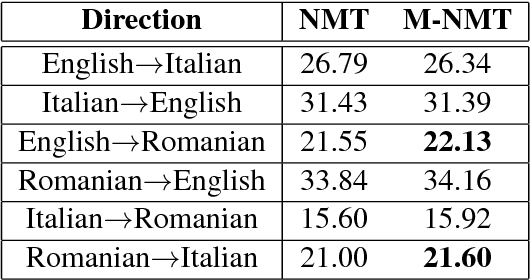
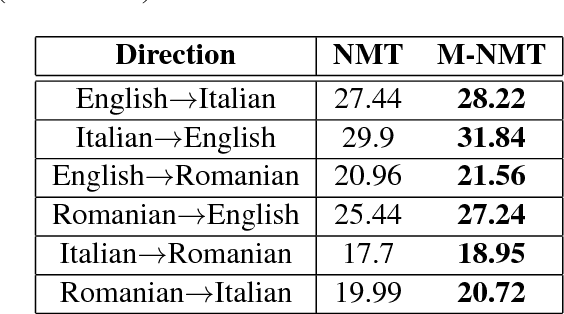
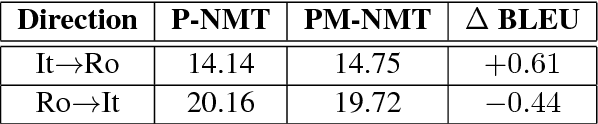
In recent years, Neural Machine Translation (NMT) has been shown to be more effective than phrase-based statistical methods, thus quickly becoming the state of the art in machine translation (MT). However, NMT systems are limited in translating low-resourced languages, due to the significant amount of parallel data that is required to learn useful mappings between languages. In this work, we show how the so-called multilingual NMT can help to tackle the challenges associated with low-resourced language translation. The underlying principle of multilingual NMT is to force the creation of hidden representations of words in a shared semantic space across multiple languages, thus enabling a positive parameter transfer across languages. Along this direction, we present multilingual translation experiments with three languages (English, Italian, Romanian) covering six translation directions, utilizing both recurrent neural networks and transformer (or self-attentive) neural networks. We then focus on the zero-shot translation problem, that is how to leverage multi-lingual data in order to learn translation directions that are not covered by the available training material. To this aim, we introduce our recently proposed iterative self-training method, which incrementally improves a multilingual NMT on a zero-shot direction by just relying on monolingual data. Our results on TED talks data show that multilingual NMT outperforms conventional bilingual NMT, that the transformer NMT outperforms recurrent NMT, and that zero-shot NMT outperforms conventional pivoting methods and even matches the performance of a fully-trained bilingual system.
Training Neural Machine Translation To Apply Terminology Constraints
Jun 03, 2019
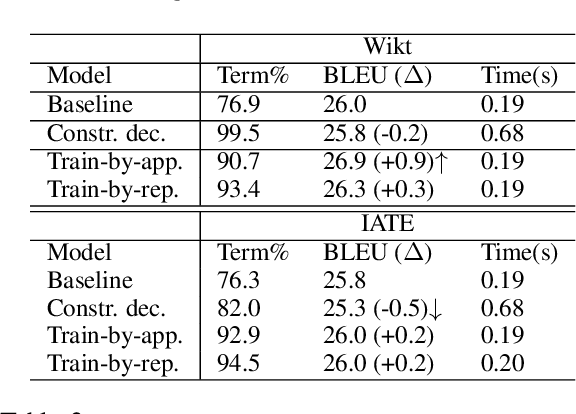

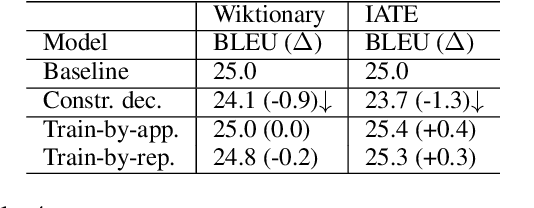
This paper proposes a novel method to inject custom terminology into neural machine translation at run time. Previous works have mainly proposed modifications to the decoding algorithm in order to constrain the output to include run-time-provided target terms. While being effective, these constrained decoding methods add, however, significant computational overhead to the inference step, and, as we show in this paper, can be brittle when tested in realistic conditions. In this paper we approach the problem by training a neural MT system to learn how to use custom terminology when provided with the input. Comparative experiments show that our method is not only more effective than a state-of-the-art implementation of constrained decoding, but is also as fast as constraint-free decoding.
Phonetically-Oriented Word Error Alignment for Speech Recognition Error Analysis in Speech Translation
Apr 24, 2019
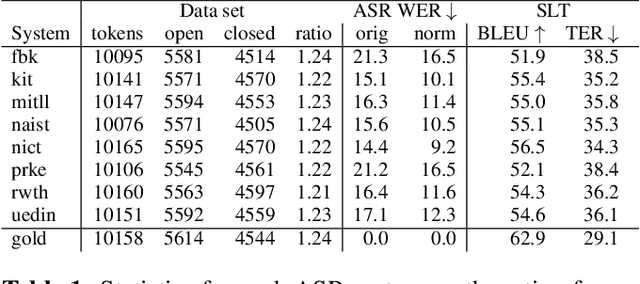
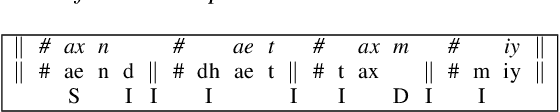
We propose a variation to the commonly used Word Error Rate (WER) metric for speech recognition evaluation which incorporates the alignment of phonemes, in the absence of time boundary information. After computing the Levenshtein alignment on words in the reference and hypothesis transcripts, spans of adjacent errors are converted into phonemes with word and syllable boundaries and a phonetic Levenshtein alignment is performed. The aligned phonemes are recombined into aligned words that adjust the word alignment labels in each error region. We demonstrate that our Phonetically-Oriented Word Error Rate (POWER) yields similar scores to WER with the added advantages of better word alignments and the ability to capture one-to-many word alignments corresponding to homophonic errors in speech recognition hypotheses. These improved alignments allow us to better trace the impact of Levenshtein error types on downstream tasks such as speech translation.
Assessing the Tolerance of Neural Machine Translation Systems Against Speech Recognition Errors
Apr 24, 2019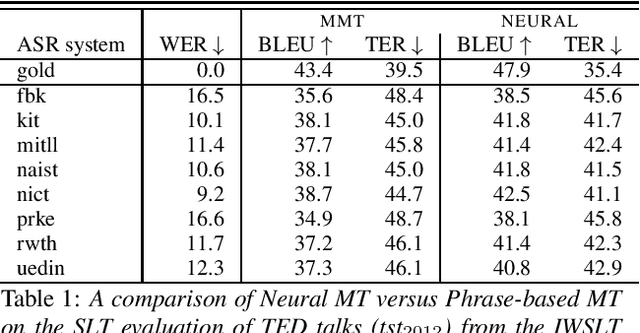
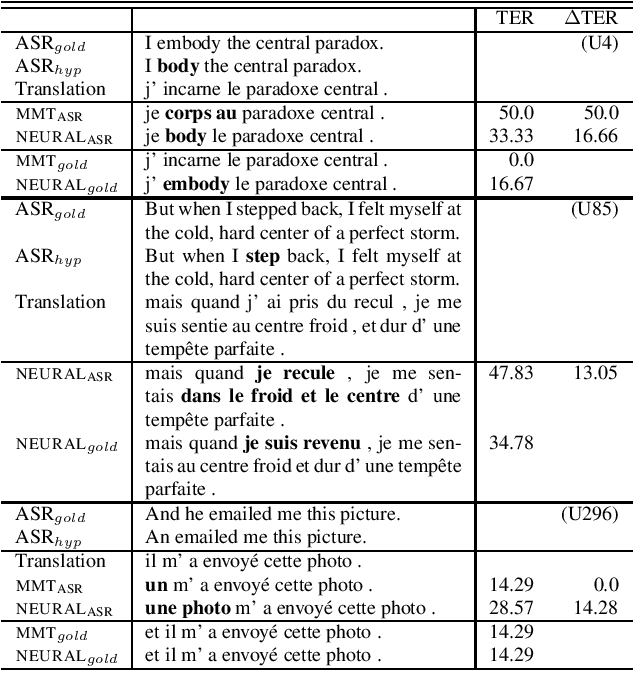
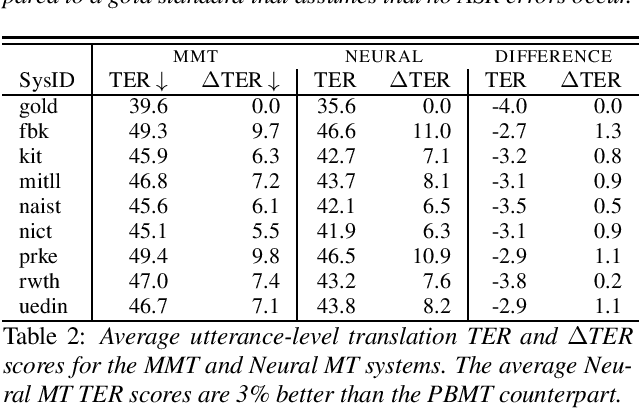
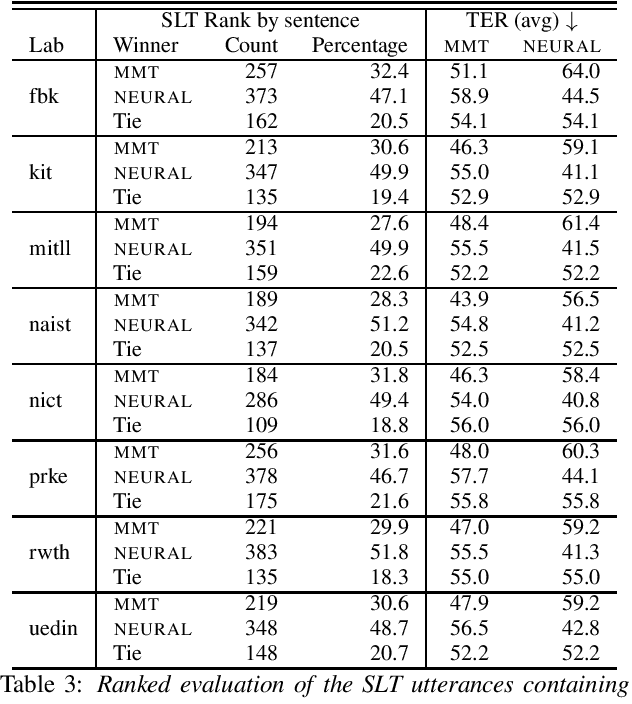
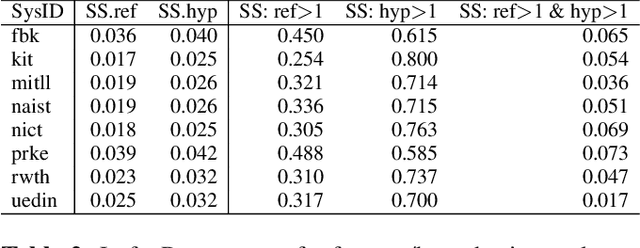
Machine translation systems are conventionally trained on textual resources that do not model phenomena that occur in spoken language. While the evaluation of neural machine translation systems on textual inputs is actively researched in the literature , little has been discovered about the complexities of translating spoken language data with neural models. We introduce and motivate interesting problems one faces when considering the translation of automatic speech recognition (ASR) outputs on neural machine translation (NMT) systems. We test the robustness of sentence encoding approaches for NMT encoder-decoder modeling, focusing on word-based over byte-pair encoding. We compare the translation of utterances containing ASR errors in state-of-the-art NMT encoder-decoder systems against a strong phrase-based machine translation baseline in order to better understand which phenomena present in ASR outputs are better represented under the NMT framework than approaches that represent translation as a linear model.
Improving Zero-Shot Translation of Low-Resource Languages
Nov 04, 2018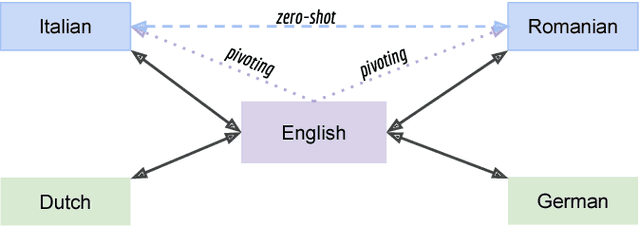

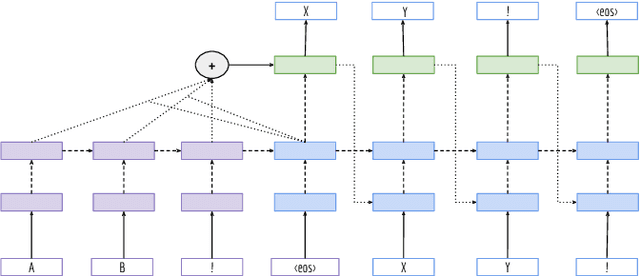
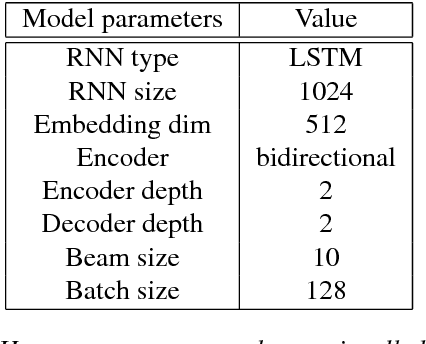
Recent work on multilingual neural machine translation reported competitive performance with respect to bilingual models and surprisingly good performance even on (zeroshot) translation directions not observed at training time. We investigate here a zero-shot translation in a particularly lowresource multilingual setting. We propose a simple iterative training procedure that leverages a duality of translations directly generated by the system for the zero-shot directions. The translations produced by the system (sub-optimal since they contain mixed language from the shared vocabulary), are then used together with the original parallel data to feed and iteratively re-train the multilingual network. Over time, this allows the system to learn from its own generated and increasingly better output. Our approach shows to be effective in improving the two zero-shot directions of our multilingual model. In particular, we observed gains of about 9 BLEU points over a baseline multilingual model and up to 2.08 BLEU over a pivoting mechanism using two bilingual models. Further analysis shows that there is also a slight improvement in the non-zero-shot language directions.