 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopologically Densified Distributions
Feb 12, 2020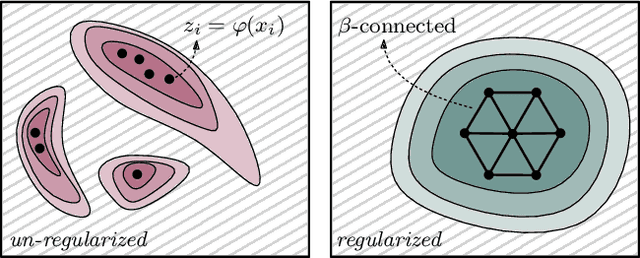
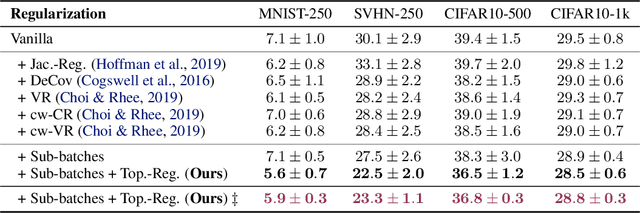
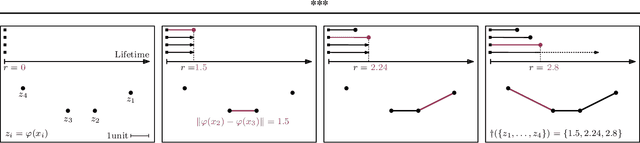
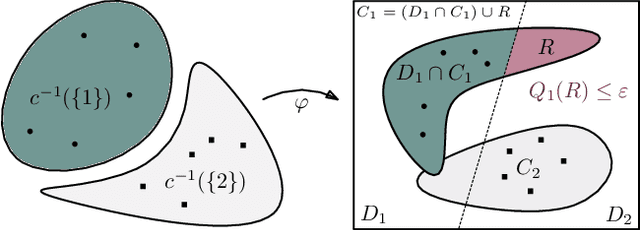
We study regularization in the context of small sample-size learning with over-parameterized neural networks. Specifically, we shift focus from architectural properties, such as norms on the network weights, to properties of the internal representations before a linear classifier. Specifically, we impose a topological constraint on samples drawn from the probability measure induced in that space. This provably leads to mass concentration effects around the representations of training instances, i.e., a property beneficial for generalization. By leveraging previous work to impose topological constraints in a neural network setting, we provide empirical evidence (across various vision benchmarks) to support our claim for better generalization.
VoteNet+ : An Improved Deep Learning Label Fusion Method for Multi-atlas Segmentation
Nov 01, 2019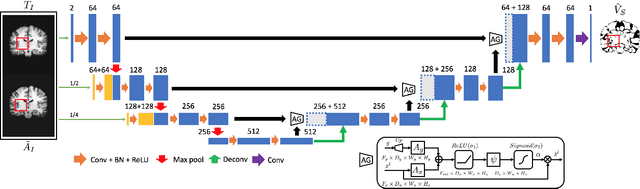
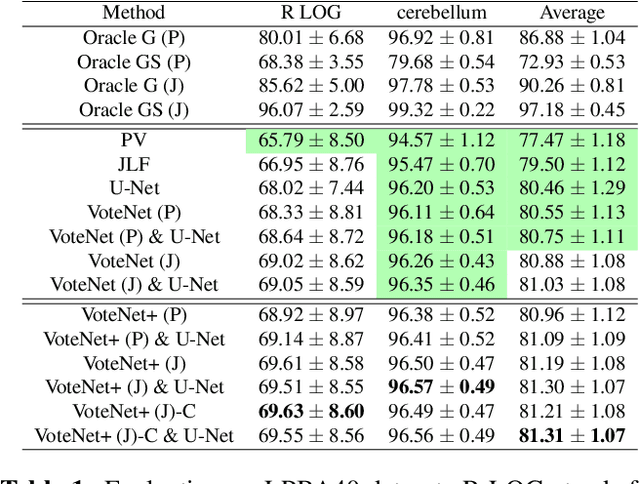
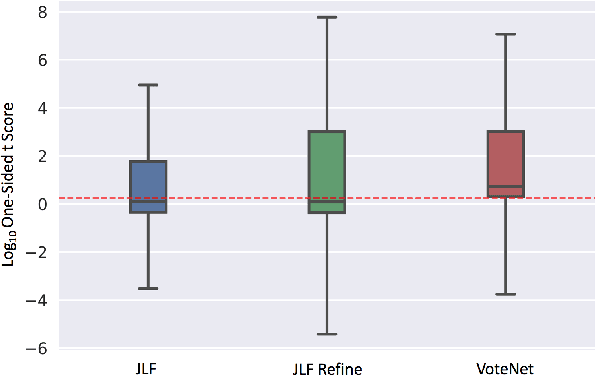
In this work, we improve the performance of multi-atlas segmentation (MAS) by integrating the recently proposed VoteNet model with the joint label fusion (JLF) approach. Specifically, we first illustrate that using a deep convolutional neural network to predict atlas probabilities can better distinguish correct atlas labels from incorrect ones than relying on image intensity difference as is typical in JLF. Motivated by this finding, we propose VoteNet+, an improved deep network to locally predict the probability of an atlas label to differs from the label of the target image. Furthermore, we show that JLF is more suitable for the VoteNet framework as a label fusion method than plurality voting. Lastly, we use Platt scaling to calibrate the probabilities of our new model. Results on LPBA40 3D MR brain images show that our proposed method can achieve better performance than VoteNet.
Deep Message Passing on Sets
Sep 21, 2019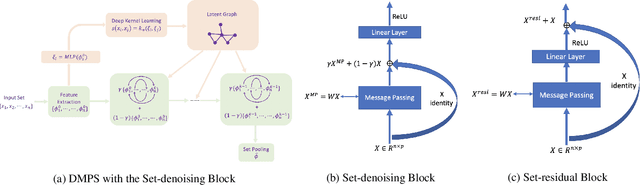
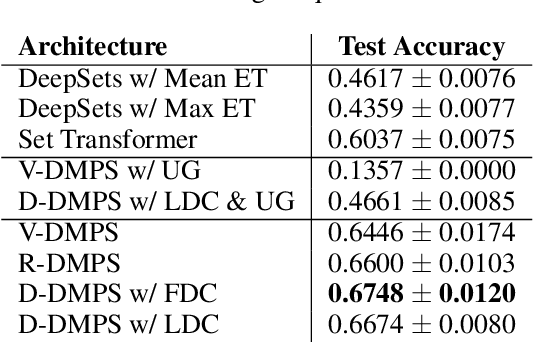
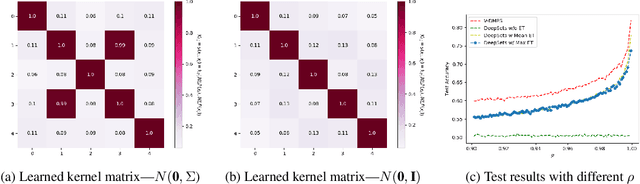
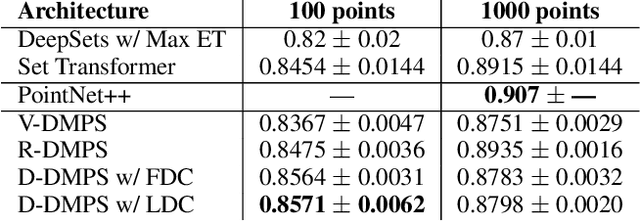
Modern methods for learning over graph input data have shown the fruitfulness of accounting for relationships among elements in a collection. However, most methods that learn over set input data use only rudimentary approaches to exploit intra-collection relationships. In this work we introduce Deep Message Passing on Sets (DMPS), a novel method that incorporates relational learning for sets. DMPS not only connects learning on graphs with learning on sets via deep kernel learning, but it also bridges message passing on sets and traditional diffusion dynamics commonly used in denoising models. Based on these connections, we develop two new blocks for relational learning on sets: the set-denoising block and the set-residual block. The former is motivated by the connection between message passing on general graphs and diffusion-based denoising models, whereas the latter is inspired by the well-known residual network. In addition to demonstrating the interpretability of our model by learning the true underlying relational structure experimentally, we also show the effectiveness of our approach on both synthetic and real-world datasets by achieving results that are competitive with or outperform the state-of-the-art.
Deep Multi-View Learning via Task-Optimal CCA
Jul 17, 2019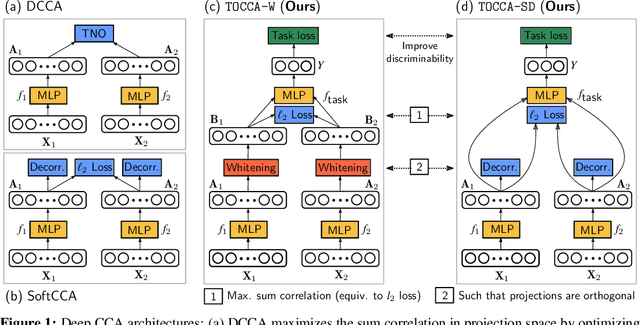

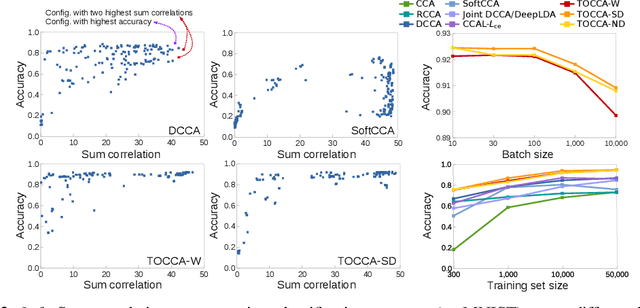

Canonical Correlation Analysis (CCA) is widely used for multimodal data analysis and, more recently, for discriminative tasks such as multi-view learning; however, it makes no use of class labels. Recent CCA methods have started to address this weakness but are limited in that they do not simultaneously optimize the CCA projection for discrimination and the CCA projection itself, or they are linear only. We address these deficiencies by simultaneously optimizing a CCA-based and a task objective in an end-to-end manner. Together, these two objectives learn a non-linear CCA projection to a shared latent space that is highly correlated and discriminative. Our method shows a significant improvement over previous state-of-the-art (including deep supervised approaches) for cross-view classification, regularization with a second view, and semi-supervised learning on real data.
Connectivity-Optimized Representation Learning via Persistent Homology
Jun 21, 2019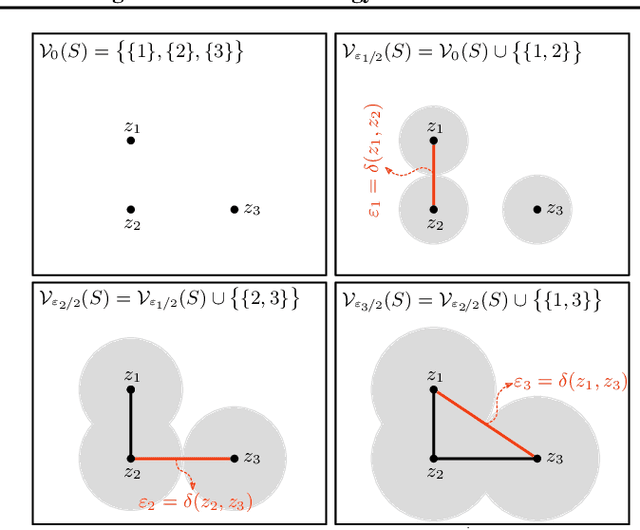
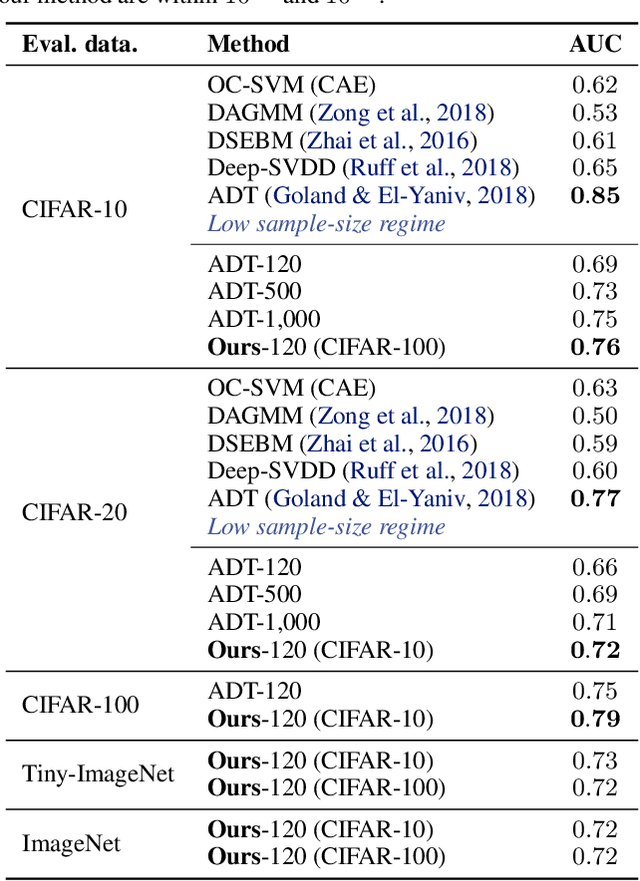
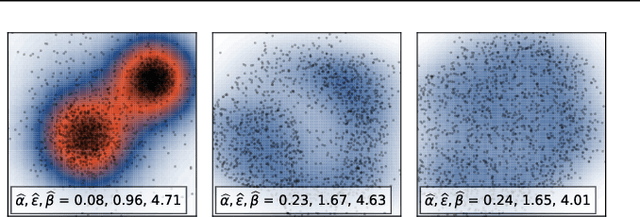
We study the problem of learning representations with controllable connectivity properties. This is beneficial in situations when the imposed structure can be leveraged upstream. In particular, we control the connectivity of an autoencoder's latent space via a novel type of loss, operating on information from persistent homology. Under mild conditions, this loss is differentiable and we present a theoretical analysis of the properties induced by the loss. We choose one-class learning as our upstream task and demonstrate that the imposed structure enables informed parameter selection for modeling the in-class distribution via kernel density estimators. Evaluated on computer vision data, these one-class models exhibit competitive performance and, in a low sample size regime, outperform other methods by a large margin. Notably, our results indicate that a single autoencoder, trained on auxiliary (unlabeled) data, yields a mapping into latent space that can be reused across datasets for one-class learning.
Region-specific Diffeomorphic Metric Mapping
Jun 01, 2019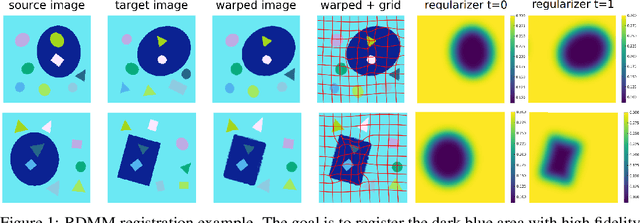
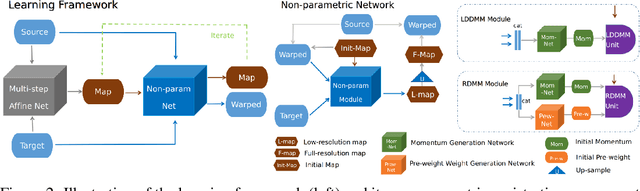

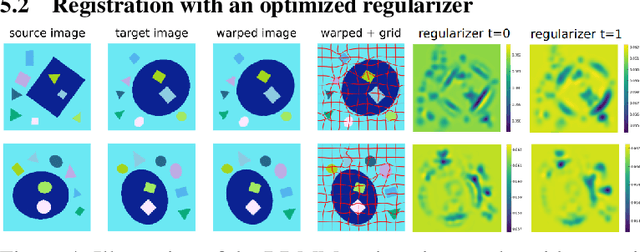
We introduce a region-specific diffeomorphic metric mapping (RDMM) registration approach. RDMM is non-parametric, estimating spatio-temporal velocity fields which parameterize the sought-for spatial transformation. Regularization of these velocity fields is necessary. However, while existing non-parametric registration approaches, e.g., the large displacement diffeomorphic metric mapping (LDDMM) model, use a fixed spatially-invariant regularization our model advects a spatially-varying regularizer with the estimated velocity field, thereby naturally attaching a spatio-temporal regularizer to deforming objects. We explore a family of RDMM registration approaches: 1) a registration model where regions with separate regularizations are pre-defined (e.g., in an atlas space), 2) a registration model where a general spatially-varying regularizer is estimated, and 3) a registration model where the spatially-varying regularizer is obtained via an end-to-end trained deep learning (DL) model. We provide a variational derivation of RDMM, show that the model can assure diffeomorphic transformations in the continuum, and that LDDMM is a particular instance of RDMM. To evaluate RDMM performance we experiment 1) on synthetic 2D data and 2) on two 3D datasets: knee magnetic resonance images (MRIs) of the Osteoarthritis Initiative (OAI) and computed tomography images (CT) of the lung. Results show that our framework achieves state-of-the-art image registration performance, while providing additional information via a learned spatio-temoporal regularizer. Further, our deep learning approach allows for very fast RDMM and LDDMM estimations. Our code will be open-sourced. Code is available at https://github.com/uncbiag/registration.
VoteNet: A Deep Learning Label Fusion Method for Multi-Atlas Segmentation
May 31, 2019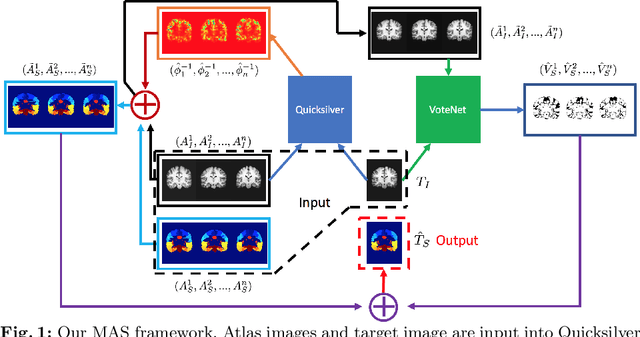
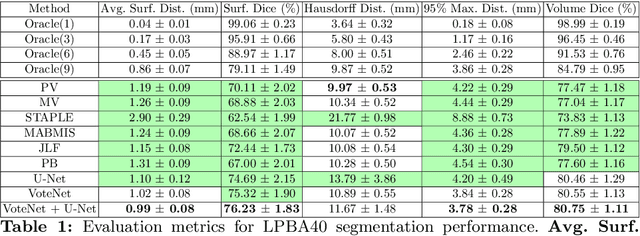
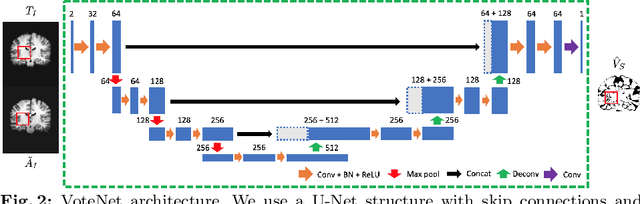
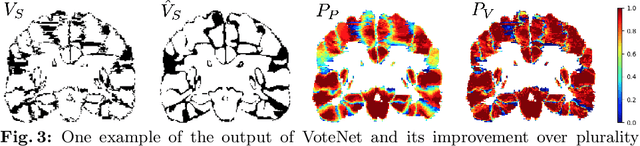
Deep learning (DL) approaches are state-of-the-art for many medical image segmentation tasks. They offer a number of advantages: they can be trained for specific tasks, computations are fast at test time, and segmentation quality is typically high. In contrast, previously popular multi-atlas segmentation (MAS) methods are relatively slow (as they rely on costly registrations) and even though sophisticated label fusion strategies have been proposed, DL approaches generally outperform MAS. In this work, we propose a DL-based label fusion strategy (VoteNet) which locally selects a set of reliable atlases whose labels are then fused via plurality voting. Experiments on 3D brain MRI data show that by selecting a good initial atlas set MAS with VoteNet significantly outperforms a number of other label fusion strategies as well as a direct DL segmentation approach. We also provide an experimental analysis of the upper performance bound achievable by our method. While unlikely achievable in practice, this bound suggests room for further performance improvements. Lastly, to address the runtime disadvantage of standard MAS, all our results make use of a fast DL registration approach.
Graph Filtration Learning
May 27, 2019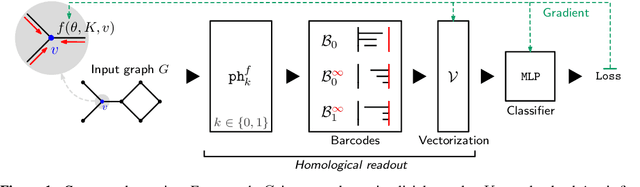
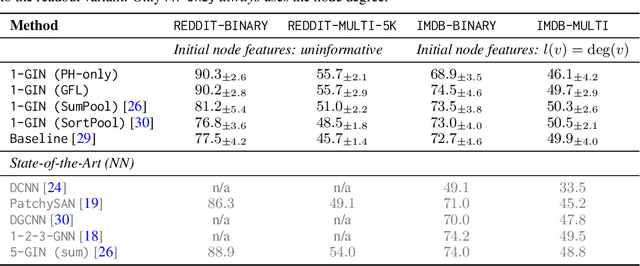
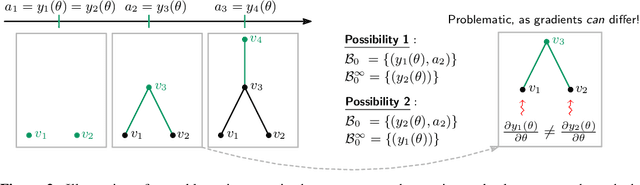
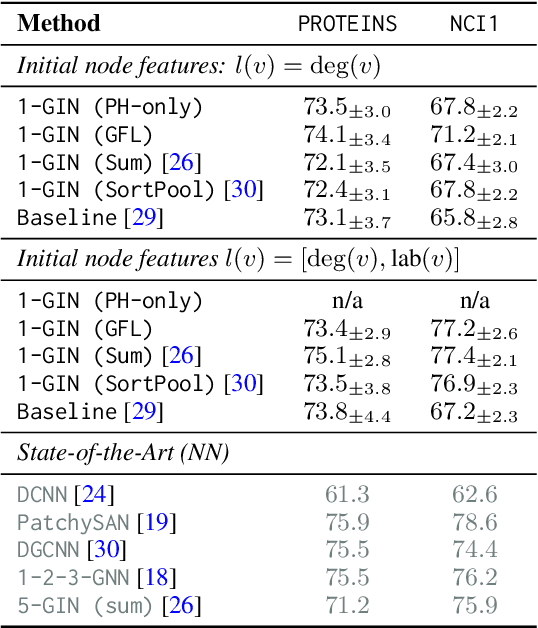
We propose an approach to learning with graph-structured data in the problem domain of graph classification. In particular, we present a novel type of readout operation to aggregate node features into a graph-level representation. To this end, we leverage persistent homology computed via a real-valued, learnable, filter function. We establish the theoretical foundation for differentiating through the persistent homology computation. Empirically, we show that this type of readout operation compares favorably to previous techniques, especially when the graph connectivity structure is informative for the learning problem.
Metric Learning for Image Registration
Apr 21, 2019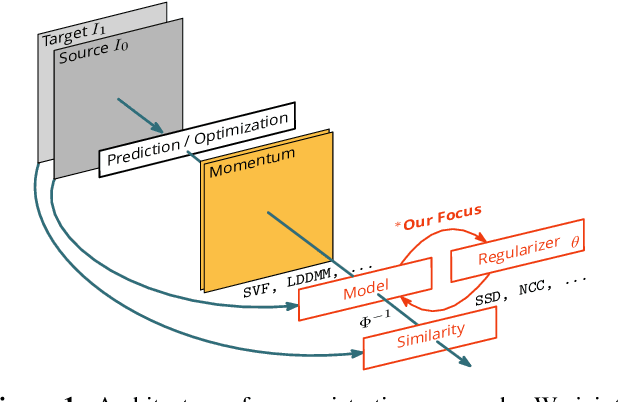
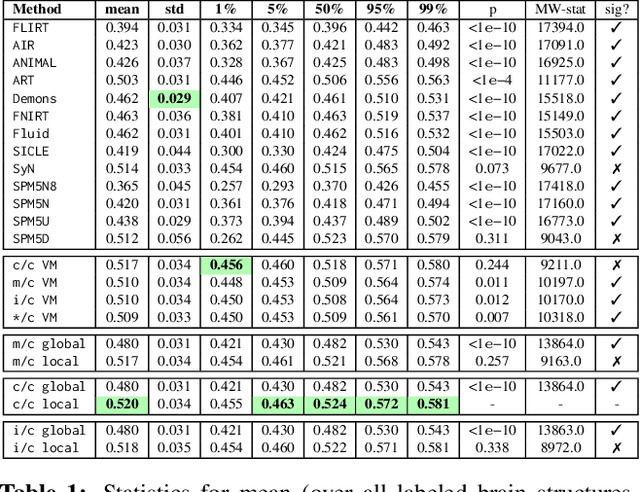
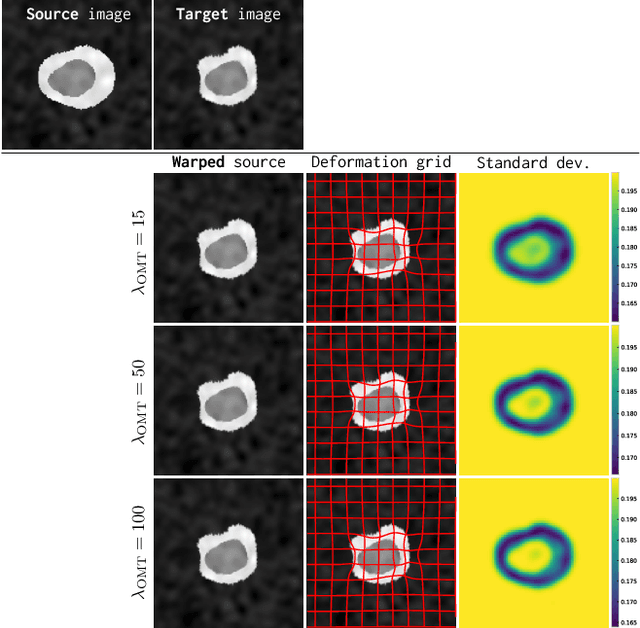

Image registration is a key technique in medical image analysis to estimate deformations between image pairs. A good deformation model is important for high-quality estimates. However, most existing approaches use ad-hoc deformation models chosen for mathematical convenience rather than to capture observed data variation. Recent deep learning approaches learn deformation models directly from data. However, they provide limited control over the spatial regularity of transformations. Instead of learning the entire registration approach, we learn a spatially-adaptive regularizer within a registration model. This allows controlling the desired level of regularity and preserving structural properties of a registration model. For example, diffeomorphic transformations can be attained. Our approach is a radical departure from existing deep learning approaches to image registration by embedding a deep learning model in an optimization-based registration algorithm to parameterize and data-adapt the registration model itself.
DeepAtlas: Joint Semi-Supervised Learning of Image Registration and Segmentation
Apr 17, 2019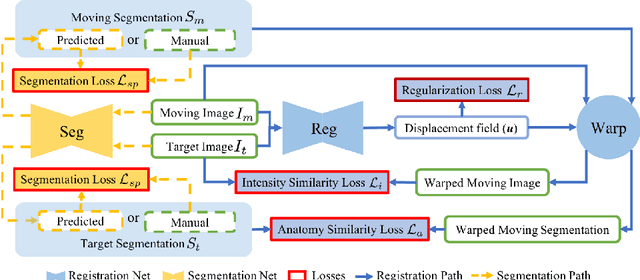
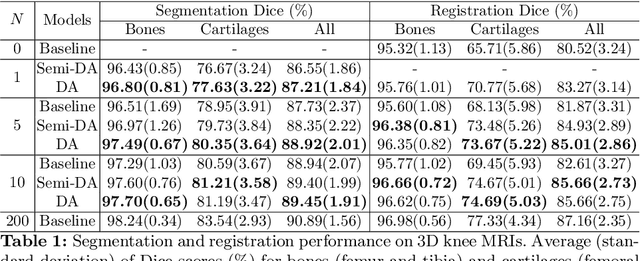
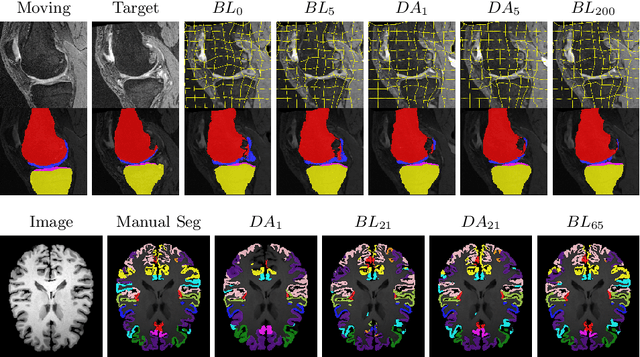
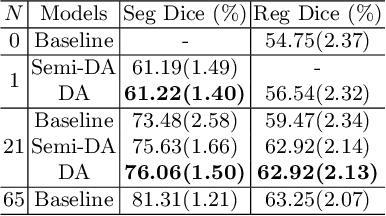
Deep convolutional neural networks (CNNs) are state-of-the-art for semantic image segmentation, but typically require many labeled training samples. Obtaining 3D segmentations of medical images for supervised training is difficult and labor intensive. Motivated by classical approaches for joint segmentation and registration we therefore propose a deep learning framework that jointly learns networks for image registration and image segmentation. In contrast to previous work on deep unsupervised image registration, which showed the benefit of weak supervision via image segmentations, our approach can use existing segmentations when available and computes them via the segmentation network otherwise, thereby providing the same registration benefit. Conversely, segmentation network training benefits from the registration, which essentially provides a realistic form of data augmentation. Experiments on knee and brain 3D magnetic resonance (MR) images show that our approach achieves large simultaneous improvements of segmentation and registration accuracy (over independently trained networks) and allows training high-quality models with very limited training data. Specifically, in a one-shot-scenario (with only one manually labeled image) our approach increases Dice scores (%) over an unsupervised registration network by 2.7 and 1.8 on the knee and brain images respectively.