 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgram Synthesis and Semantic Parsing with Learned Code Idioms
Jul 23, 2019
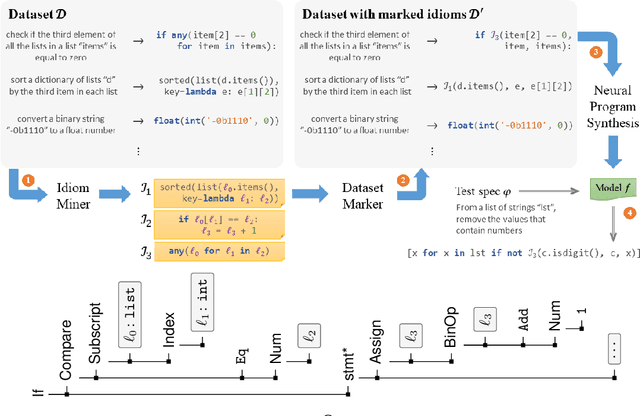
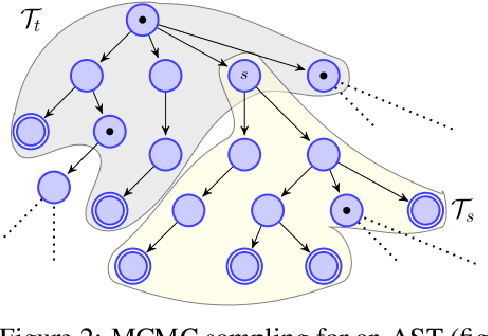
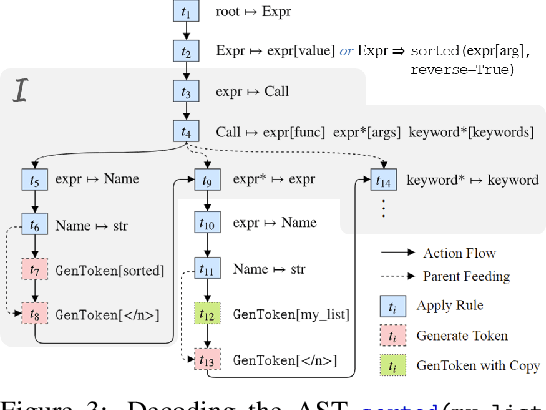
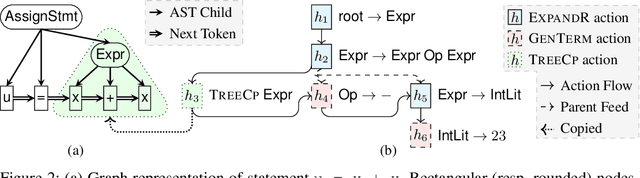
Program synthesis of general-purpose source code from natural language specifications is challenging due to the need to reason about high-level patterns in the target program and low-level implementation details at the same time. In this work, we present PATOIS, a system that allows a neural program synthesizer to explicitly interleave high-level and low-level reasoning at every generation step. It accomplishes this by automatically mining common code idioms from a given corpus, incorporating them into the underlying language for neural synthesis, and training a tree-based neural synthesizer to use these idioms during code generation. We evaluate PATOIS on two complex semantic parsing datasets and show that using learned code idioms improves the synthesizer's accuracy.
GNN-FiLM: Graph Neural Networks with Feature-wise Linear Modulation
Jun 28, 2019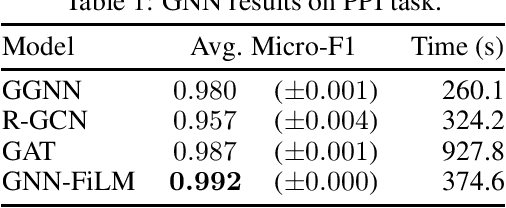
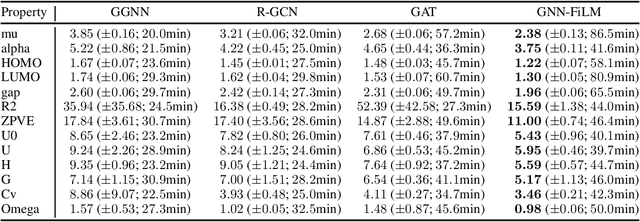
This paper presents a new Graph Neural Network (GNN) type using feature-wise linear modulations (FiLM). Many GNN variants propagate information along the edges of a graph by computing "messages" based only on the representation source of each edge. In GNN-FiLM, the representation of the target node of an edge is additionally used to compute a transformation that can be applied to all incoming messages, allowing feature-wise modulation of the passed information. Experiments with GNN-FiLM as well as a number of baselines and related extensions show that it outperforms baseline methods while not being significantly slower.
Structured Neural Summarization
Nov 05, 2018
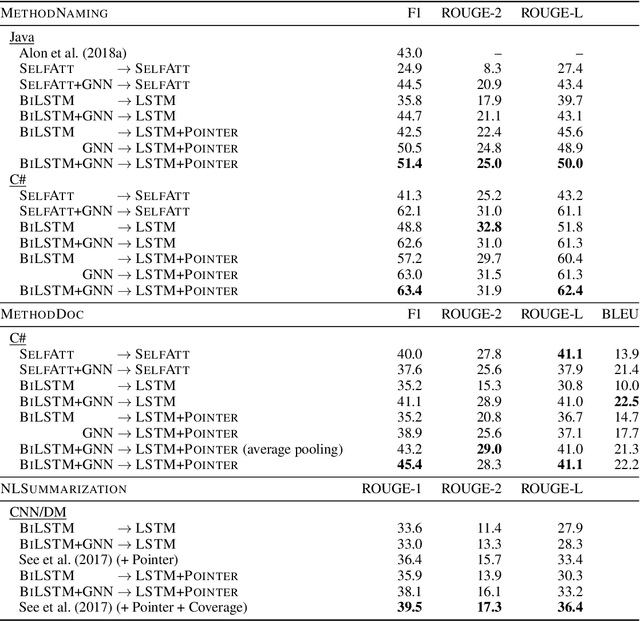
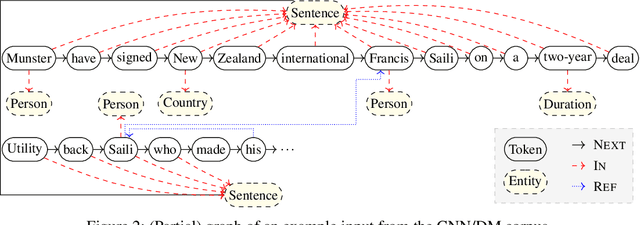
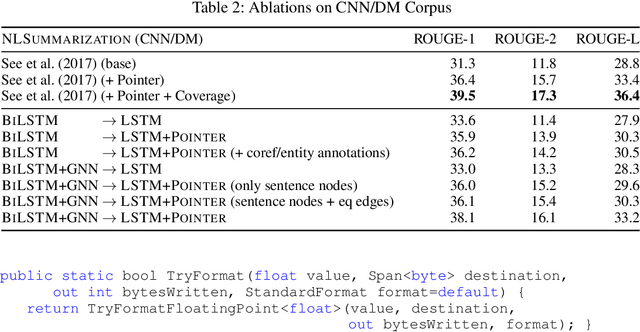
Summarization of long sequences into a concise statement is a core problem in natural language processing, requiring non-trivial understanding of the input. Based on the promising results of graph neural networks on highly structured data, we develop a framework to extend existing sequence encoders with a graph component that can reason about long-distance relationships in weakly structured data such as text. In an extensive evaluation, we show that the resulting hybrid sequence-graph models outperform both pure sequence models as well as pure graph models on a range of summarization tasks.
Learning to Represent Edits
Oct 31, 2018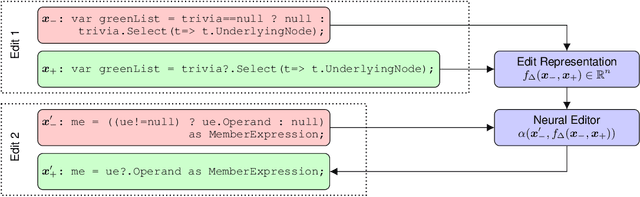
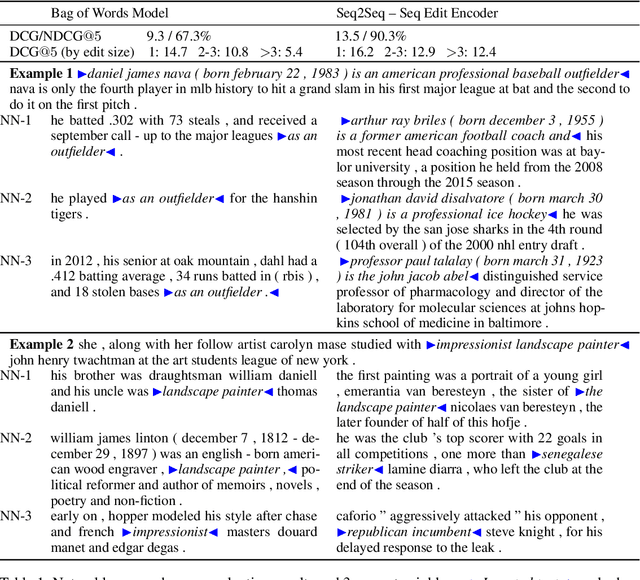
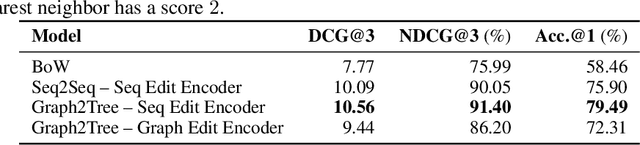
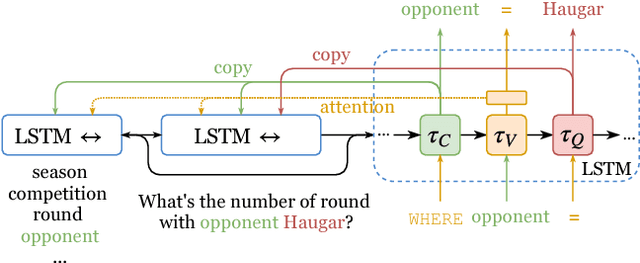
We introduce the problem of learning distributed representations of edits. By combining a "neural editor" with an "edit encoder", our models learn to represent the salient information of an edit and can be used to apply edits to new inputs. We experiment on natural language and source code edit data. Our evaluation yields promising results that suggest that our neural network models learn to capture the structure and semantics of edits. We hope that this interesting task and data source will inspire other researchers to work further on this problem.
Robust Text-to-SQL Generation with Execution-Guided Decoding
Sep 13, 2018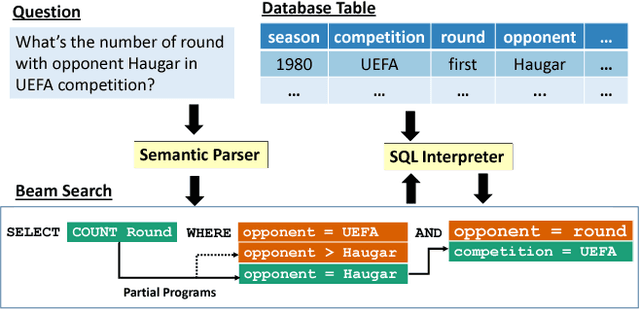
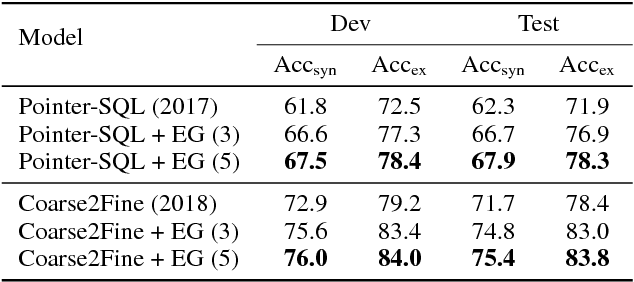
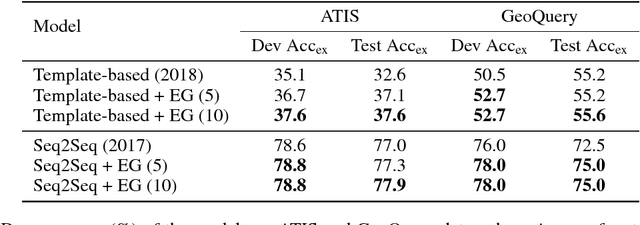
We consider the problem of neural semantic parsing, which translates natural language questions into executable SQL queries. We introduce a new mechanism, execution guidance, to leverage the semantics of SQL. It detects and excludes faulty programs during the decoding procedure by conditioning on the execution of partially generated program. The mechanism can be used with any autoregressive generative model, which we demonstrate on four state-of-the-art recurrent or template-based semantic parsing models. We demonstrate that execution guidance universally improves model performance on various text-to-SQL datasets with different scales and query complexity: WikiSQL, ATIS, and GeoQuery. As a result, we achieve new state-of-the-art execution accuracy of 83.8% on WikiSQL.
Constrained Graph Variational Autoencoders for Molecule Design
May 23, 2018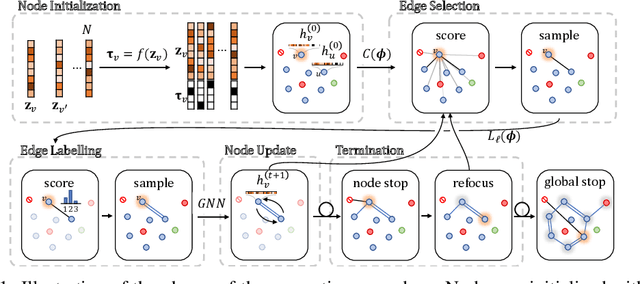
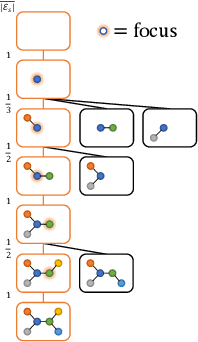
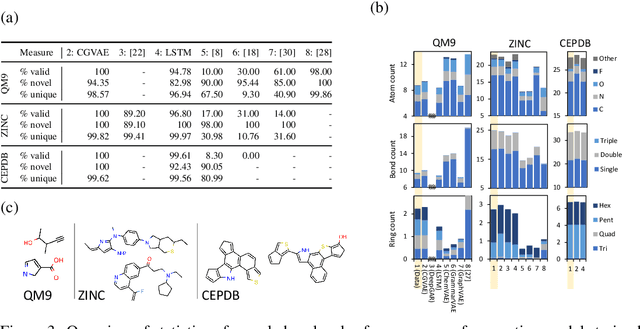

Graphs are ubiquitous data structures for representing interactions between entities. With an emphasis on the use of graphs to represent chemical molecules, we explore the task of learning to generate graphs that conform to a distribution observed in training data. We propose a variational autoencoder model in which both encoder and decoder are graph-structured. Our decoder assumes a sequential ordering of graph extension steps and we discuss and analyze design choices that mitigate the potential downsides of this linearization. Experiments compare our approach with a wide range of baselines on the molecule generation task and show that our method is more successful at matching the statistics of the original dataset on semantically important metrics. Furthermore, we show that by using appropriate shaping of the latent space, our model allows us to design molecules that are (locally) optimal in desired properties.
Generative Code Modeling with Graphs
May 22, 2018
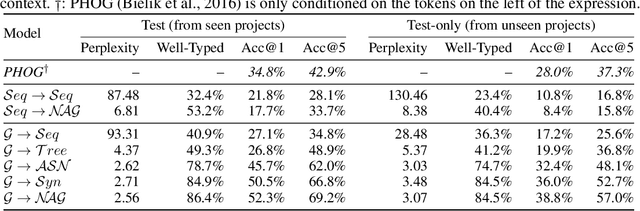

Generative models for source code are an interesting structured prediction problem, requiring to reason about both hard syntactic and semantic constraints as well as about natural, likely programs. We present a novel model for this problem that uses a graph to represent the intermediate state of the generated output. The generative procedure interleaves grammar-driven expansion steps with graph augmentation and neural message passing steps. An experimental evaluation shows that our new model can generate semantically meaningful expressions, outperforming a range of strong baselines.
Learning to Represent Programs with Graphs
May 04, 2018
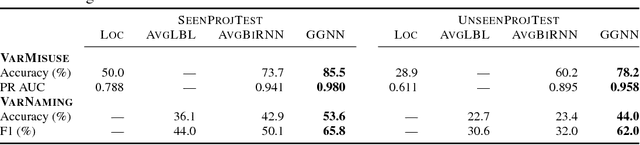
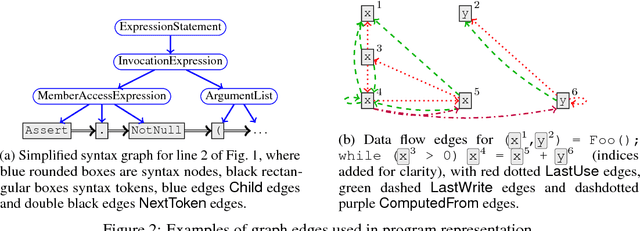

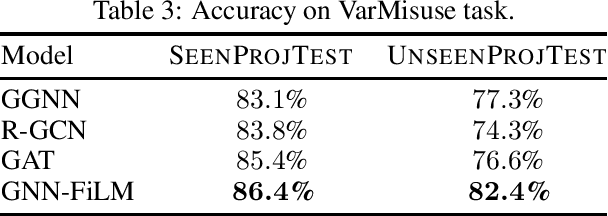
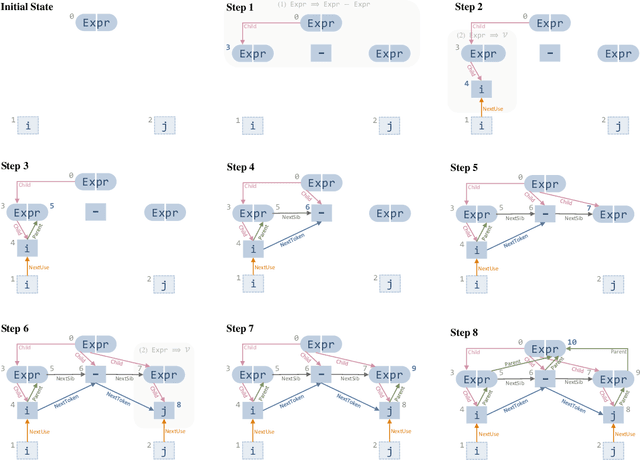
Learning tasks on source code (i.e., formal languages) have been considered recently, but most work has tried to transfer natural language methods and does not capitalize on the unique opportunities offered by code's known syntax. For example, long-range dependencies induced by using the same variable or function in distant locations are often not considered. We propose to use graphs to represent both the syntactic and semantic structure of code and use graph-based deep learning methods to learn to reason over program structures. In this work, we present how to construct graphs from source code and how to scale Gated Graph Neural Networks training to such large graphs. We evaluate our method on two tasks: VarNaming, in which a network attempts to predict the name of a variable given its usage, and VarMisuse, in which the network learns to reason about selecting the correct variable that should be used at a given program location. Our comparison to methods that use less structured program representations shows the advantages of modeling known structure, and suggests that our models learn to infer meaningful names and to solve the VarMisuse task in many cases. Additionally, our testing showed that VarMisuse identifies a number of bugs in mature open-source projects.
Graph Partition Neural Networks for Semi-Supervised Classification
Mar 16, 2018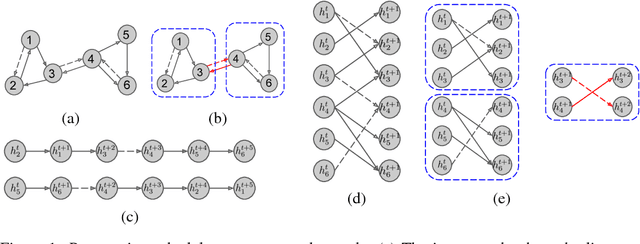

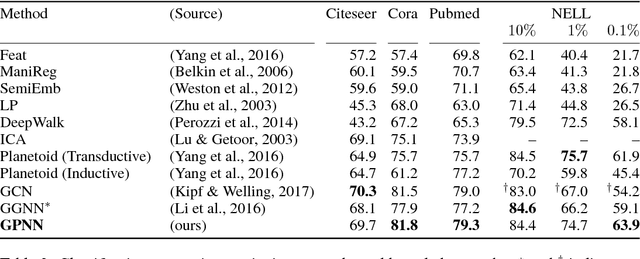
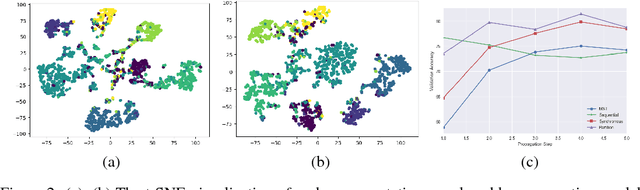
We present graph partition neural networks (GPNN), an extension of graph neural networks (GNNs) able to handle extremely large graphs. GPNNs alternate between locally propagating information between nodes in small subgraphs and globally propagating information between the subgraphs. To efficiently partition graphs, we experiment with several partitioning algorithms and also propose a novel variant for fast processing of large scale graphs. We extensively test our model on a variety of semi-supervised node classification tasks. Experimental results indicate that GPNNs are either superior or comparable to state-of-the-art methods on a wide variety of datasets for graph-based semi-supervised classification. We also show that GPNNs can achieve similar performance as standard GNNs with fewer propagation steps.
Gated Graph Sequence Neural Networks
Sep 22, 2017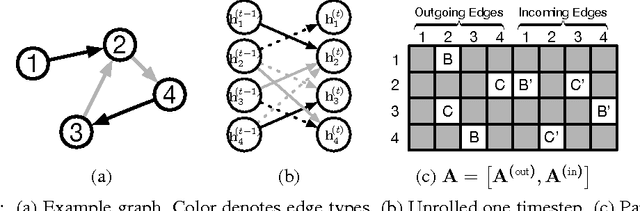
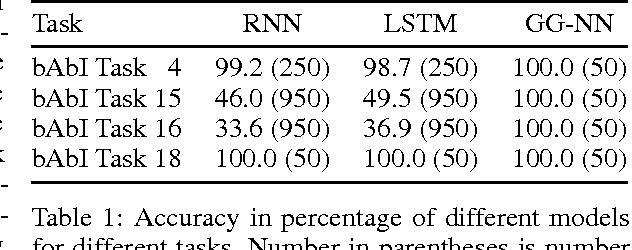
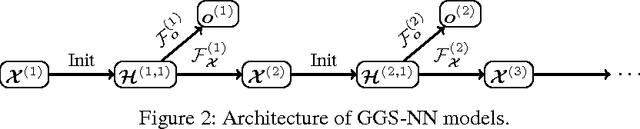

Graph-structured data appears frequently in domains including chemistry, natural language semantics, social networks, and knowledge bases. In this work, we study feature learning techniques for graph-structured inputs. Our starting point is previous work on Graph Neural Networks (Scarselli et al., 2009), which we modify to use gated recurrent units and modern optimization techniques and then extend to output sequences. The result is a flexible and broadly useful class of neural network models that has favorable inductive biases relative to purely sequence-based models (e.g., LSTMs) when the problem is graph-structured. We demonstrate the capabilities on some simple AI (bAbI) and graph algorithm learning tasks. We then show it achieves state-of-the-art performance on a problem from program verification, in which subgraphs need to be matched to abstract data structures.