 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Network Visibility Problem
Nov 19, 2018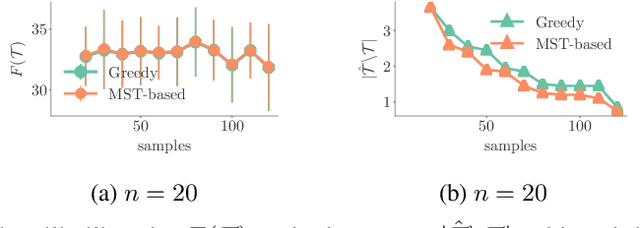
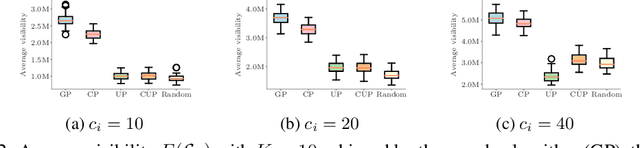
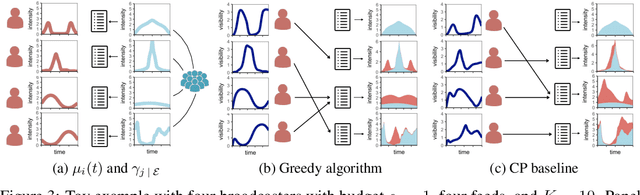
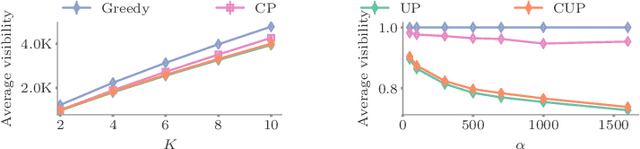
Social media is an attention economy where users are constantly competing for attention in their followers' feeds. Users are likely to elicit greater attention from their followers, their audience, if their posts remain visible at the top of their followers' feeds for a longer period of time. However, this depends on the rate at which their followers receive information in their feeds, which in turn depends on the users their followers follow. Then, who should follow whom to maximize the visibility each user achieve? In this paper, we represent users' posts and feeds using the framework of temporal point processes. Under this representation, the problem reduces to optimizing a non-submodular nondecreasing set function under matroid constraints. Then, we show that the set function satisfies a novel property, $\xi$-submodularity, which allows a simple and efficient greedy algorithm to enjoy theoretical guarantees. In particular, we prove that the greedy algorithm offers a $(1/\xi + 1)$ approximation factor, where $\xi$ is the strong submodularity ratio, a new measure of approximate submodularity that we are able to bound in our problem. Experiments on both synthetic and real data gathered from Twitter show that our greedy algorithm is able to consistently outperform several baselines.
Deep Reinforcement Learning of Marked Temporal Point Processes
Nov 06, 2018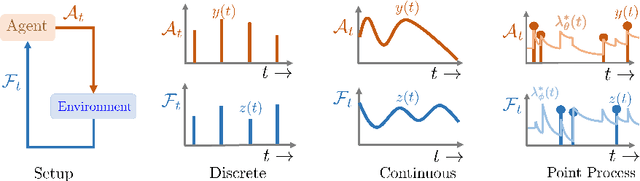

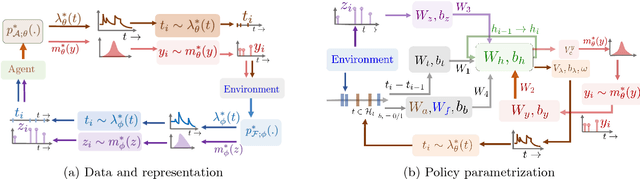
In a wide variety of applications, humans interact with a complex environment by means of asynchronous stochastic discrete events in continuous time. Can we design online interventions that will help humans achieve certain goals in such asynchronous setting? In this paper, we address the above problem from the perspective of deep reinforcement learning of marked temporal point processes, where both the actions taken by an agent and the feedback it receives from the environment are asynchronous stochastic discrete events characterized using marked temporal point processes. In doing so, we define the agent's policy using the intensity and mark distribution of the corresponding process and then derive a flexible policy gradient method, which embeds the agent's actions and the feedback it receives into real-valued vectors using deep recurrent neural networks. Our method does not make any assumptions on the functional form of the intensity and mark distribution of the feedback and it allows for arbitrarily complex reward functions. We apply our methodology to two different applications in personalized teaching and viral marketing and, using data gathered from Duolingo and Twitter, we show that it may be able to find interventions to help learners and marketers achieve their goals more effectively than alternatives.
Stochastic Optimal Control of Epidemic Processes in Networks
Oct 30, 2018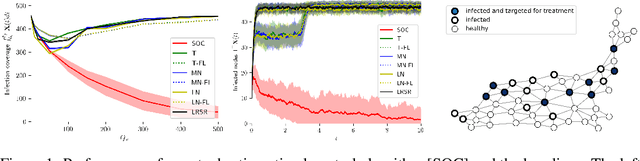
We approach the development of models and control strategies of susceptible-infected-susceptible (SIS) epidemic processes from the perspective of marked temporal point processes and stochastic optimal control of stochastic differential equations (SDEs) with jumps. In contrast to previous work, this novel perspective is particularly well-suited to make use of fine-grained data about disease outbreaks, and it lets us overcome the shortcomings of current control strategies. Our control strategy resorts to treatment intensities to determine who to treat and when to do so, to minimize the amount of infected individuals over time. Preliminary experiments with synthetic data show that our control strategy consistently outperforms several alternatives. Looking into the future, we believe our methodology provides a promising step towards the development of practical data-driven control strategies of epidemic processes.
Designing Random Graph Models Using Variational Autoencoders With Applications to Chemical Design
May 23, 2018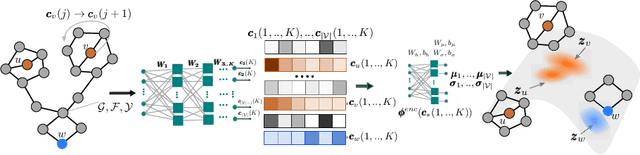
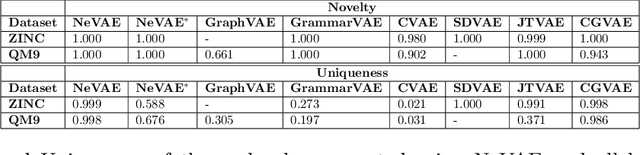
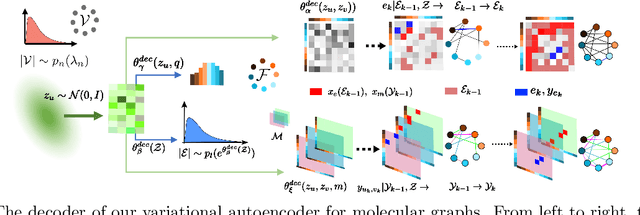

Deep generative models have been praised for their ability to learn smooth latent representation of images, text, and audio, which can then be used to generate new, plausible data. However, current generative models are unable to work with graphs due to their unique characteristics--their underlying structure is not Euclidean or grid-like, they remain isomorphic under permutation of the nodes labels, and they come with a different number of nodes and edges. In this paper, we propose NeVAE, a novel variational autoencoder for graphs, whose encoder and decoder are specially designed to account for the above properties by means of several technical innovations. In addition, by using masking, the decoder is able to guarantee a set of local structural and functional properties in the generated graphs. Experiments reveal that our model is able to learn and mimic the generative process of several well-known random graph models and can be used to discover new molecules more effectively than several state of the art methods. Moreover, by utilizing Bayesian optimization over the continuous latent representation of molecules our model finds, we can also identify molecules that maximize certain desirable properties more effectively than alternatives.
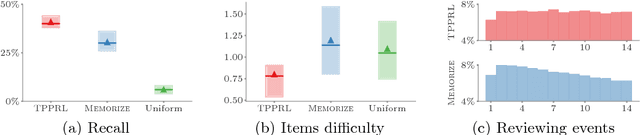
Optimizing Human Learning
Mar 10, 2018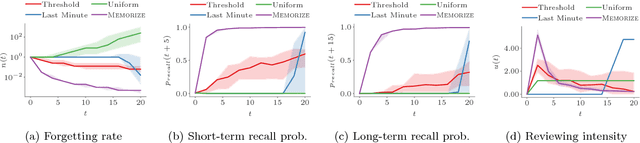
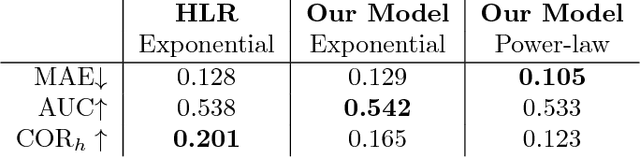

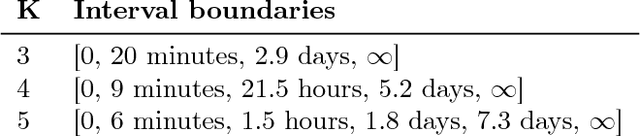
Spaced repetition is a technique for efficient memorization which uses repeated, spaced review of content to improve long-term retention. Can we find the optimal reviewing schedule to maximize the benefits of spaced repetition? In this paper, we introduce a novel, flexible representation of spaced repetition using the framework of marked temporal point processes and then address the above question as an optimal control problem for stochastic differential equations with jumps. For two well-known human memory models, we show that the optimal reviewing schedule is given by the recall probability of the content to be learned. As a result, we can then develop a simple, scalable online algorithm, Memorize, to sample the optimal reviewing times. Experiments on both synthetic and real data gathered from Duolingo, a popular language-learning online platform, show that our algorithm may be able to help learners memorize more effectively than alternatives.
On the Complexity of Opinions and Online Discussions
Feb 19, 2018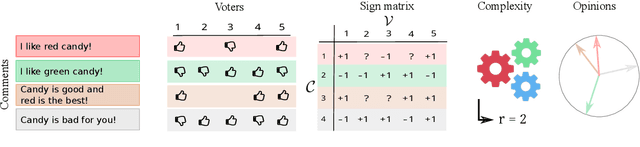
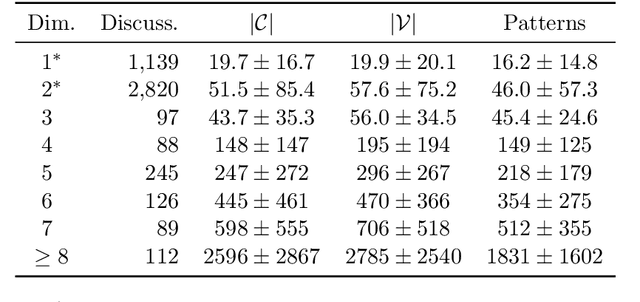
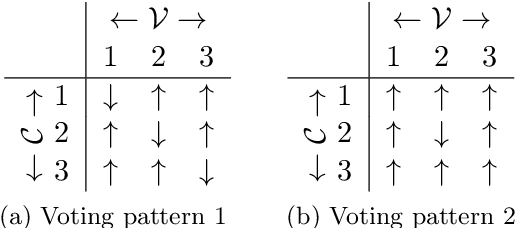
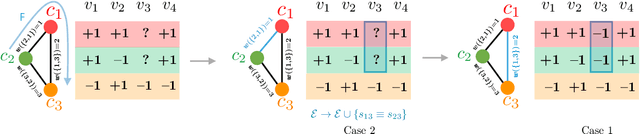
In an increasingly polarized world, demagogues who reduce complexity down to simple arguments based on emotion are gaining in popularity. Are opinions and online discussions falling into demagoguery? In this work, we aim to provide computational tools to investigate this question and, by doing so, explore the nature and complexity of online discussions and their space of opinions, uncovering where each participant lies. More specifically, we present a modeling framework to construct latent representations of opinions in online discussions which are consistent with human judgements, as measured by online voting. If two opinions are close in the resulting latent space of opinions, it is because humans think they are similar. Our modeling framework is theoretically grounded and establishes a surprising connection between opinion and voting models and the sign-rank of a matrix. Moreover, it also provides a set of practical algorithms to both estimate the dimension of the latent space of opinions and infer where opinions expressed by the participants of an online discussion lie in this space. Experiments on a large dataset from Yahoo! News, Yahoo! Finance, Yahoo! Sports, and the Newsroom app suggest that unidimensional opinion models may be often unable to accurately represent online discussions, provide insights into human judgements and opinions, and show that our framework is able to circumvent language nuances such as sarcasm or humor by relying on human judgements instead of textual analysis.
Steering Social Activity: A Stochastic Optimal Control Point Of View
Feb 19, 2018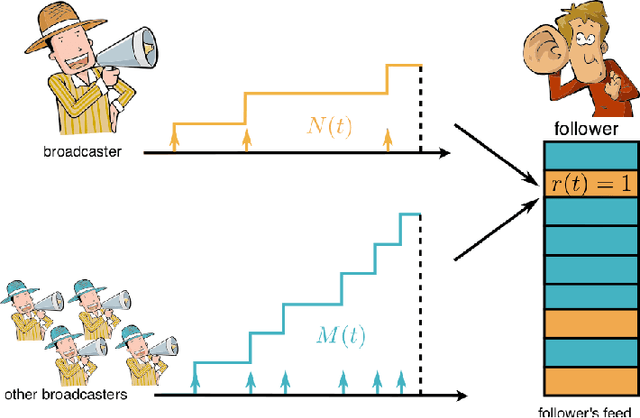
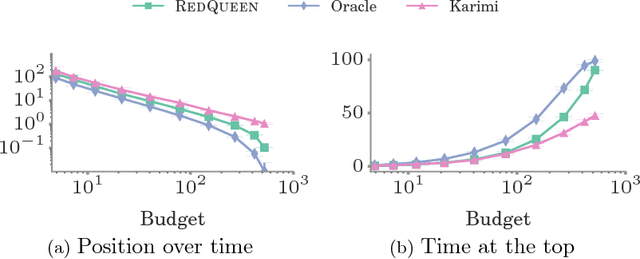
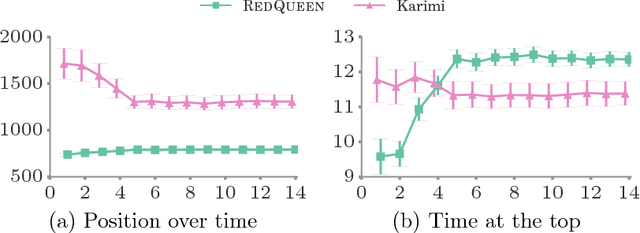
User engagement in online social networking depends critically on the level of social activity in the corresponding platform--the number of online actions, such as posts, shares or replies, taken by their users. Can we design data-driven algorithms to increase social activity? At a user level, such algorithms may increase activity by helping users decide when to take an action to be more likely to be noticed by their peers. At a network level, they may increase activity by incentivizing a few influential users to take more actions, which in turn will trigger additional actions by other users. In this paper, we model social activity using the framework of marked temporal point processes, derive an alternate representation of these processes using stochastic differential equations (SDEs) with jumps and, exploiting this alternate representation, develop two efficient online algorithms with provable guarantees to steer social activity both at a user and at a network level. In doing so, we establish a previously unexplored connection between optimal control of jump SDEs and doubly stochastic marked temporal point processes, which is of independent interest. Finally, we experiment both with synthetic and real data gathered from Twitter and show that our algorithms consistently steer social activity more effectively than the state of the art.
Leveraging the Crowd to Detect and Reduce the Spread of Fake News and Misinformation
Nov 27, 2017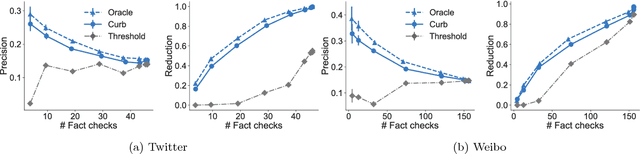
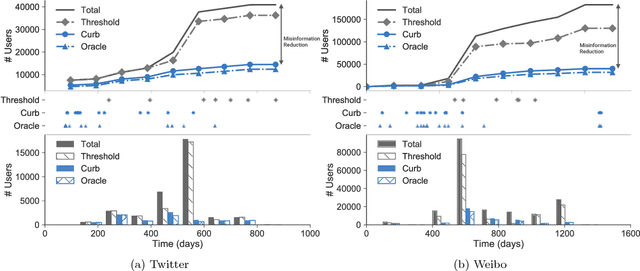
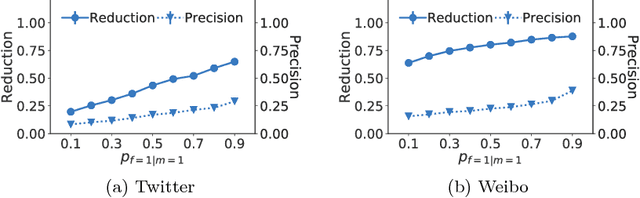
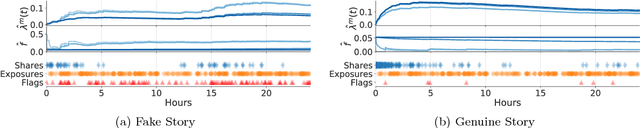
Online social networking sites are experimenting with the following crowd-powered procedure to reduce the spread of fake news and misinformation: whenever a user is exposed to a story through her feed, she can flag the story as misinformation and, if the story receives enough flags, it is sent to a trusted third party for fact checking. If this party identifies the story as misinformation, it is marked as disputed. However, given the uncertain number of exposures, the high cost of fact checking, and the trade-off between flags and exposures, the above mentioned procedure requires careful reasoning and smart algorithms which, to the best of our knowledge, do not exist to date. In this paper, we first introduce a flexible representation of the above procedure using the framework of marked temporal point processes. Then, we develop a scalable online algorithm, Curb, to select which stories to send for fact checking and when to do so to efficiently reduce the spread of misinformation with provable guarantees. In doing so, we need to solve a novel stochastic optimal control problem for stochastic differential equations with jumps, which is of independent interest. Experiments on two real-world datasets gathered from Twitter and Weibo show that our algorithm may be able to effectively reduce the spread of fake news and misinformation.
Distilling Information Reliability and Source Trustworthiness from Digital Traces
Apr 02, 2017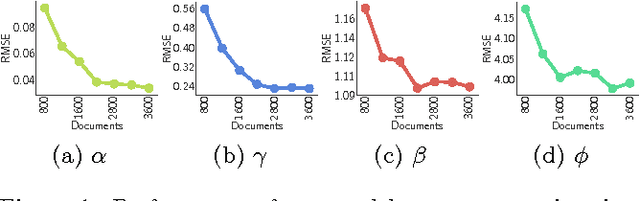
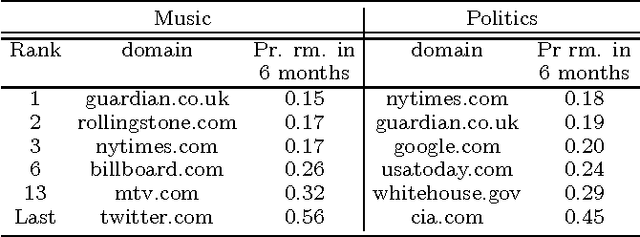
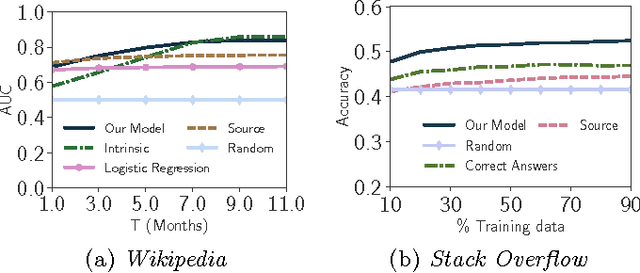
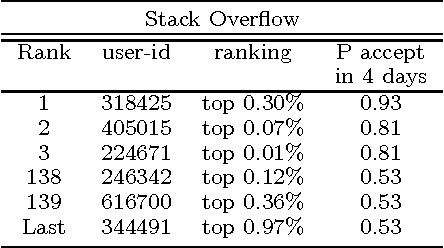
Online knowledge repositories typically rely on their users or dedicated editors to evaluate the reliability of their content. These evaluations can be viewed as noisy measurements of both information reliability and information source trustworthiness. Can we leverage these noisy evaluations, often biased, to distill a robust, unbiased and interpretable measure of both notions? In this paper, we argue that the temporal traces left by these noisy evaluations give cues on the reliability of the information and the trustworthiness of the sources. Then, we propose a temporal point process modeling framework that links these temporal traces to robust, unbiased and interpretable notions of information reliability and source trustworthiness. Furthermore, we develop an efficient convex optimization procedure to learn the parameters of the model from historical traces. Experiments on real-world data gathered from Wikipedia and Stack Overflow show that our modeling framework accurately predicts evaluation events, provides an interpretable measure of information reliability and source trustworthiness, and yields interesting insights about real-world events.
Scalable Influence Maximization for Multiple Products in Continuous-Time Diffusion Networks
Jan 29, 2017
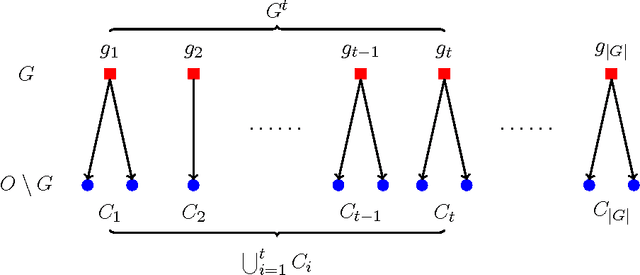
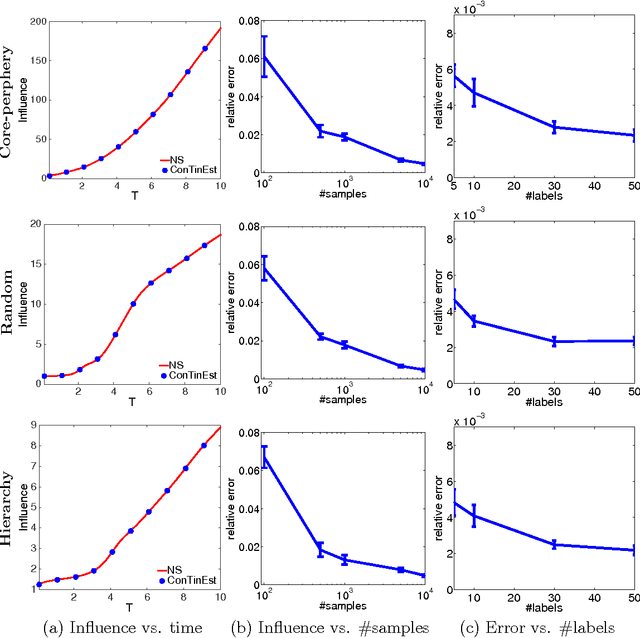
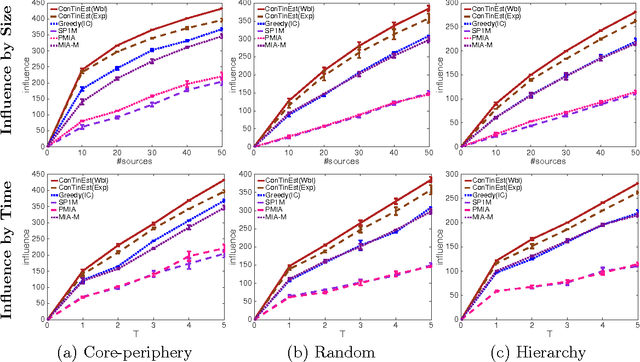
A typical viral marketing model identifies influential users in a social network to maximize a single product adoption assuming unlimited user attention, campaign budgets, and time. In reality, multiple products need campaigns, users have limited attention, convincing users incurs costs, and advertisers have limited budgets and expect the adoptions to be maximized soon. Facing these user, monetary, and timing constraints, we formulate the problem as a submodular maximization task in a continuous-time diffusion model under the intersection of a matroid and multiple knapsack constraints. We propose a randomized algorithm estimating the user influence in a network ($|\mathcal{V}|$ nodes, $|\mathcal{E}|$ edges) to an accuracy of $\epsilon$ with $n=\mathcal{O}(1/\epsilon^2)$ randomizations and $\tilde{\mathcal{O}}(n|\mathcal{E}|+n|\mathcal{V}|)$ computations. By exploiting the influence estimation algorithm as a subroutine, we develop an adaptive threshold greedy algorithm achieving an approximation factor $k_a/(2+2 k)$ of the optimal when $k_a$ out of the $k$ knapsack constraints are active. Extensive experiments on networks of millions of nodes demonstrate that the proposed algorithms achieve the state-of-the-art in terms of effectiveness and scalability.