 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual PatchNorm
Feb 06, 2023



We propose Dual PatchNorm: two Layer Normalization layers (LayerNorms), before and after the patch embedding layer in Vision Transformers. We demonstrate that Dual PatchNorm outperforms the result of exhaustive search for alternative LayerNorm placement strategies in the Transformer block itself. In our experiments, incorporating this trivial modification, often leads to improved accuracy over well-tuned Vision Transformers and never hurts.
Large language models can segment narrative events similarly to humans
Jan 24, 2023Humans perceive discrete events such as "restaurant visits" and "train rides" in their continuous experience. One important prerequisite for studying human event perception is the ability of researchers to quantify when one event ends and another begins. Typically, this information is derived by aggregating behavioral annotations from several observers. Here we present an alternative computational approach where event boundaries are derived using a large language model, GPT-3, instead of using human annotations. We demonstrate that GPT-3 can segment continuous narrative text into events. GPT-3-annotated events are significantly correlated with human event annotations. Furthermore, these GPT-derived annotations achieve a good approximation of the "consensus" solution (obtained by averaging across human annotations); the boundaries identified by GPT-3 are closer to the consensus, on average, than boundaries identified by individual human annotators. This finding suggests that GPT-3 provides a feasible solution for automated event annotations, and it demonstrates a further parallel between human cognition and prediction in large language models. In the future, GPT-3 may thereby help to elucidate the principles underlying human event perception.
A Unified Framework for Optimization-Based Graph Coarsening
Oct 02, 2022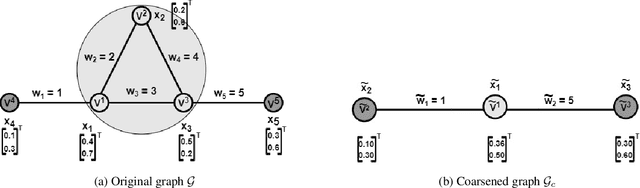
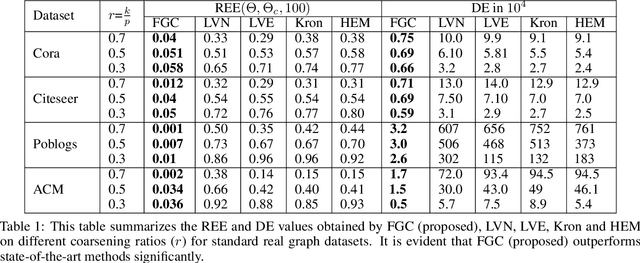
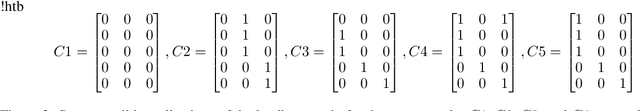
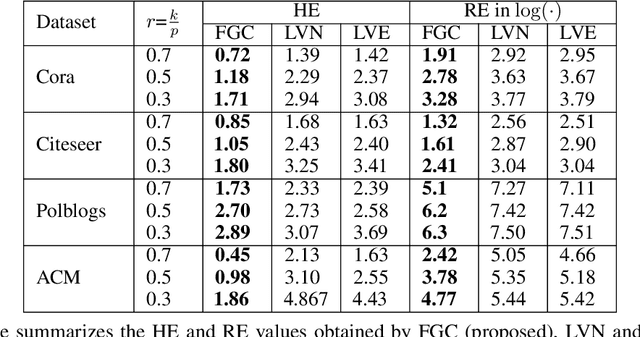
Graph coarsening is a widely used dimensionality reduction technique for approaching large-scale graph machine learning problems. Given a large graph, graph coarsening aims to learn a smaller-tractable graph while preserving the properties of the originally given graph. Graph data consist of node features and graph matrix (e.g., adjacency and Laplacian). The existing graph coarsening methods ignore the node features and rely solely on a graph matrix to simplify graphs. In this paper, we introduce a novel optimization-based framework for graph dimensionality reduction. The proposed framework lies in the unification of graph learning and dimensionality reduction. It takes both the graph matrix and the node features as the input and learns the coarsen graph matrix and the coarsen feature matrix jointly while ensuring desired properties. The proposed optimization formulation is a multi-block non-convex optimization problem, which is solved efficiently by leveraging block majorization-minimization, $\log$ determinant, Dirichlet energy, and regularization frameworks. The proposed algorithms are provably convergent and practically amenable to numerous tasks. It is also established that the learned coarsened graph is $\epsilon\in(0,1)$ similar to the original graph. Extensive experiments elucidate the efficacy of the proposed framework for real-world applications.
Functional Optimization Reinforcement Learning for Real-Time Bidding
Jul 03, 2022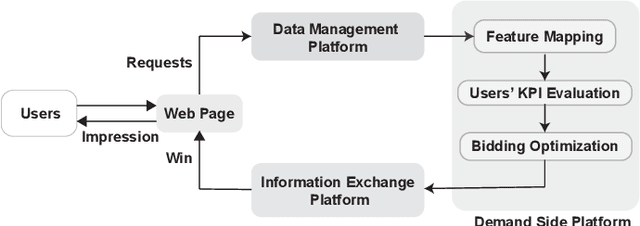
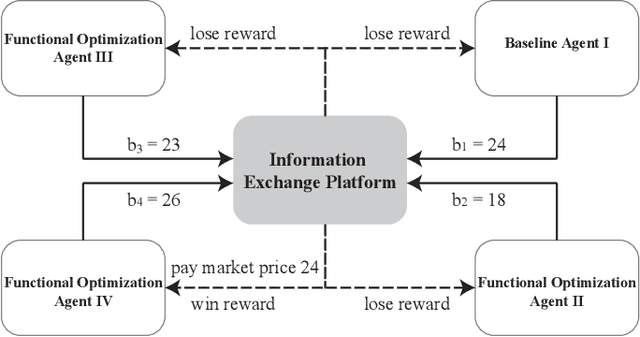
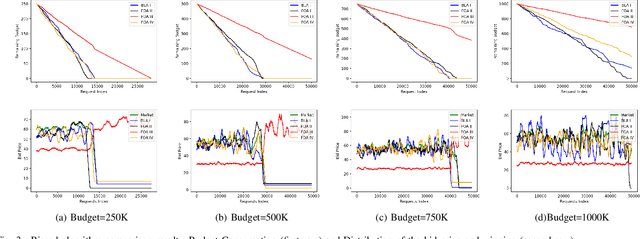
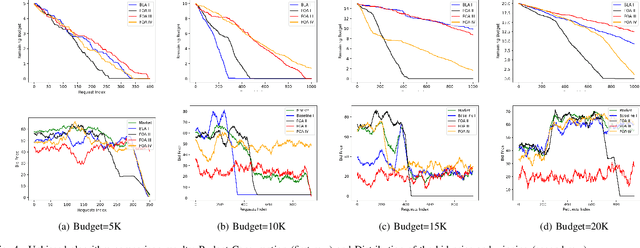
Real-time bidding is the new paradigm of programmatic advertising. An advertiser wants to make the intelligent choice of utilizing a \textbf{Demand-Side Platform} to improve the performance of their ad campaigns. Existing approaches are struggling to provide a satisfactory solution for bidding optimization due to stochastic bidding behavior. In this paper, we proposed a multi-agent reinforcement learning architecture for RTB with functional optimization. We designed four agents bidding environment: three Lagrange-multiplier based functional optimization agents and one baseline agent (without any attribute of functional optimization) First, numerous attributes have been assigned to each agent, including biased or unbiased win probability, Lagrange multiplier, and click-through rate. In order to evaluate the proposed RTB strategy's performance, we demonstrate the results on ten sequential simulated auction campaigns. The results show that agents with functional actions and rewards had the most significant average winning rate and winning surplus, given biased and unbiased winning information respectively. The experimental evaluations show that our approach significantly improve the campaign's efficacy and profitability.
On the surprising tradeoff between ImageNet accuracy and perceptual similarity
Mar 09, 2022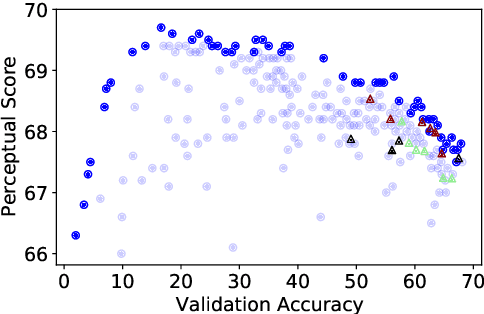
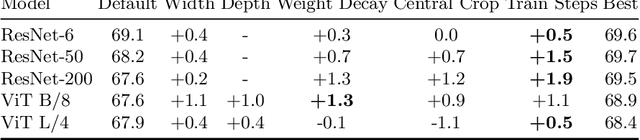
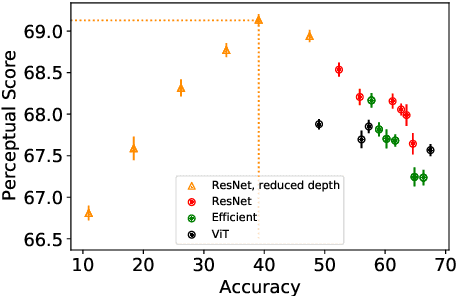
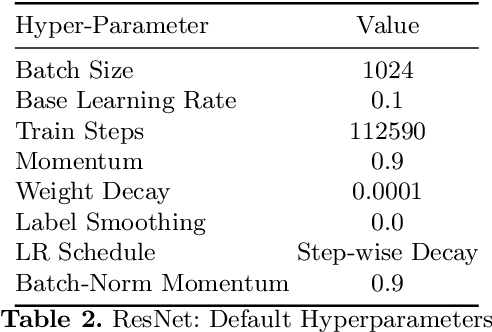
Perceptual distances between images, as measured in the space of pre-trained deep features, have outperformed prior low-level, pixel-based metrics on assessing image similarity. While the capabilities of older and less accurate models such as AlexNet and VGG to capture perceptual similarity are well known, modern and more accurate models are less studied. First, we observe a surprising inverse correlation between ImageNet accuracy and Perceptual Scores of modern networks such as ResNets, EfficientNets, and Vision Transformers: that is better classifiers achieve worse Perceptual Scores. Then, we perform a large-scale study and examine the ImageNet accuracy/Perceptual Score relationship on varying the depth, width, number of training steps, weight decay, label smoothing, and dropout. Higher accuracy improves Perceptual Score up to a certain point, but we uncover a Pareto frontier between accuracies and Perceptual Score in the mid-to-high accuracy regime. We explore this relationship further using distortion invariance, spatial frequency sensitivity, and alternative perceptual functions. Interestingly we discover shallow ResNets, trained for less than 5 epochs only on ImageNet, whose emergent Perceptual Score matches the prior best networks trained directly on supervised human perceptual judgements.
IISERB Brains at SemEval 2022 Task 6: A Deep-learning Framework to Identify Intended Sarcasm in English
Mar 04, 2022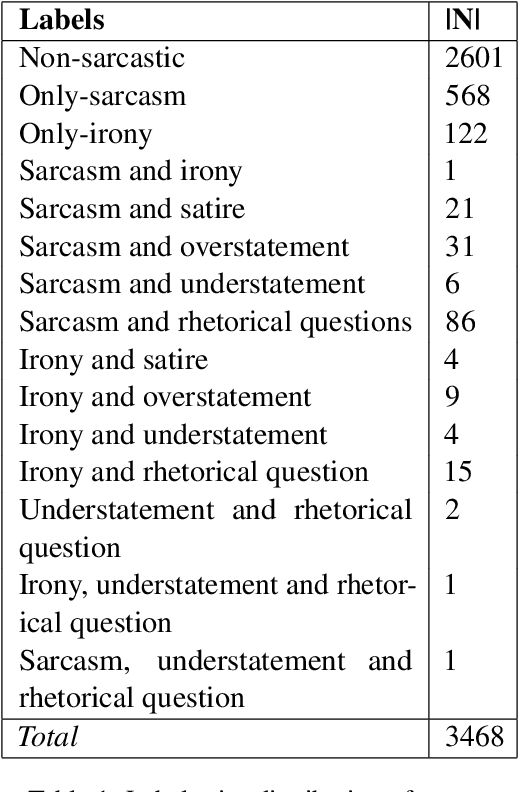
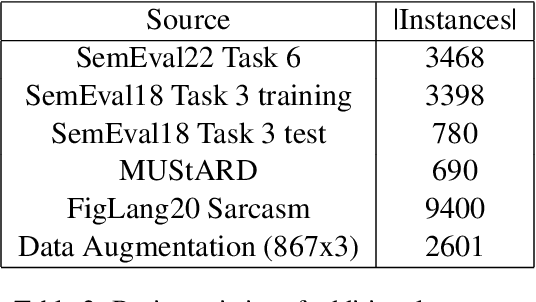
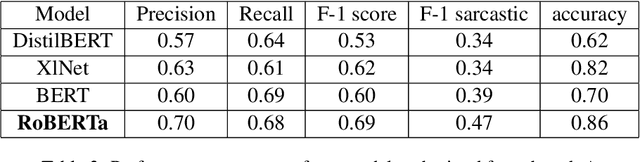
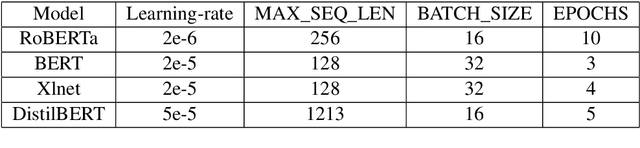
This paper describes the system architectures and the models submitted by our team "IISERBBrains" to SemEval 2022 Task 6 competition. We contested for all three sub-tasks floated for the English dataset. On the leader-board, wegot19th rank out of43 teams for sub-taskA, the 8th rank out of22 teams for sub-task B,and13th rank out of 16 teams for sub-taskC. Apart from the submitted results and models, we also report the other models and results that we obtained through our experiments after organizers published the gold labels of their evaluation data
Skillful Twelve Hour Precipitation Forecasts using Large Context Neural Networks
Nov 14, 2021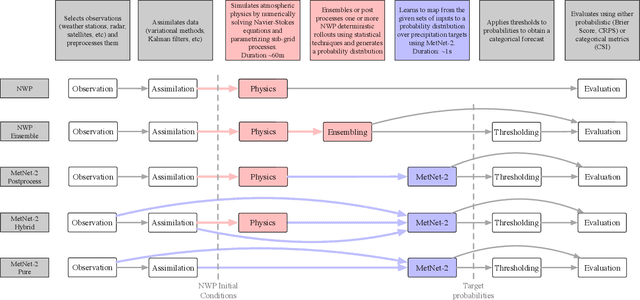
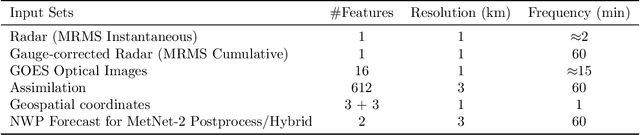
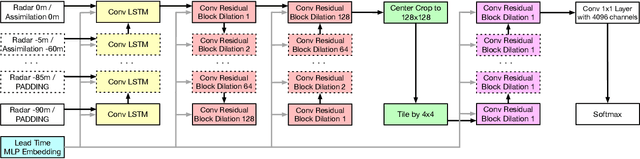

The problem of forecasting weather has been scientifically studied for centuries due to its high impact on human lives, transportation, food production and energy management, among others. Current operational forecasting models are based on physics and use supercomputers to simulate the atmosphere to make forecasts hours and days in advance. Better physics-based forecasts require improvements in the models themselves, which can be a substantial scientific challenge, as well as improvements in the underlying resolution, which can be computationally prohibitive. An emerging class of weather models based on neural networks represents a paradigm shift in weather forecasting: the models learn the required transformations from data instead of relying on hand-coded physics and are computationally efficient. For neural models, however, each additional hour of lead time poses a substantial challenge as it requires capturing ever larger spatial contexts and increases the uncertainty of the prediction. In this work, we present a neural network that is capable of large-scale precipitation forecasting up to twelve hours ahead and, starting from the same atmospheric state, the model achieves greater skill than the state-of-the-art physics-based models HRRR and HREF that currently operate in the Continental United States. Interpretability analyses reinforce the observation that the model learns to emulate advanced physics principles. These results represent a substantial step towards establishing a new paradigm of efficient forecasting with neural networks.
Colorization Transformer
Mar 07, 2021

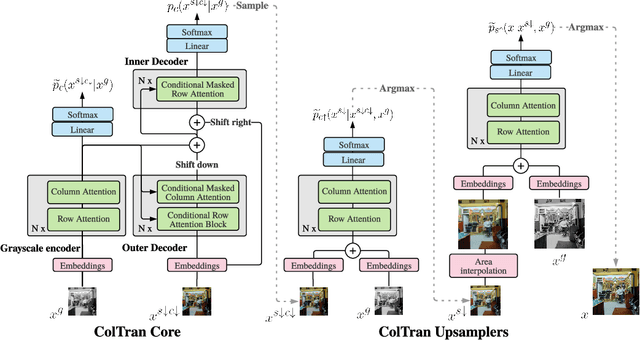
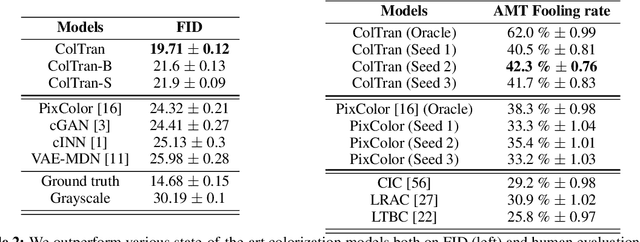
We present the Colorization Transformer, a novel approach for diverse high fidelity image colorization based on self-attention. Given a grayscale image, the colorization proceeds in three steps. We first use a conditional autoregressive transformer to produce a low resolution coarse coloring of the grayscale image. Our architecture adopts conditional transformer layers to effectively condition grayscale input. Two subsequent fully parallel networks upsample the coarse colored low resolution image into a finely colored high resolution image. Sampling from the Colorization Transformer produces diverse colorings whose fidelity outperforms the previous state-of-the-art on colorising ImageNet based on FID results and based on a human evaluation in a Mechanical Turk test. Remarkably, in more than 60% of cases human evaluators prefer the highest rated among three generated colorings over the ground truth. The code and pre-trained checkpoints for Colorization Transformer are publicly available at https://github.com/google-research/google-research/tree/master/coltran
ProtoDA: Efficient Transfer Learning for Few-Shot Intent Classification
Jan 28, 2021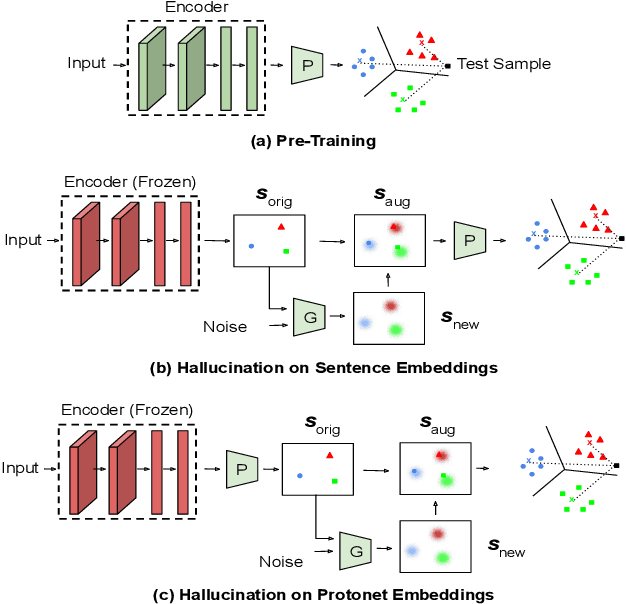

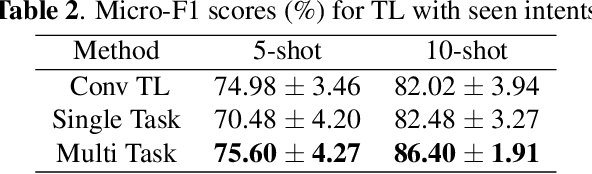
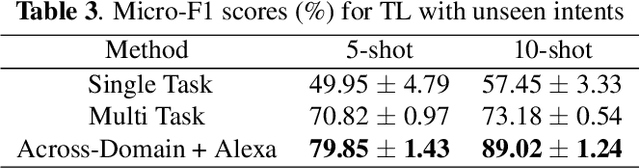
Practical sequence classification tasks in natural language processing often suffer from low training data availability for target classes. Recent works towards mitigating this problem have focused on transfer learning using embeddings pre-trained on often unrelated tasks, for instance, language modeling. We adopt an alternative approach by transfer learning on an ensemble of related tasks using prototypical networks under the meta-learning paradigm. Using intent classification as a case study, we demonstrate that increasing variability in training tasks can significantly improve classification performance. Further, we apply data augmentation in conjunction with meta-learning to reduce sampling bias. We make use of a conditional generator for data augmentation that is trained directly using the meta-learning objective and simultaneously with prototypical networks, hence ensuring that data augmentation is customized to the task. We explore augmentation in the sentence embedding space as well as prototypical embedding space. Combining meta-learning with augmentation provides upto 6.49% and 8.53% relative F1-score improvements over the best performing systems in the 5-shot and 10-shot learning, respectively.
Auto-Tuning Spectral Clustering for Speaker Diarization Using Normalized Maximum Eigengap
Mar 05, 2020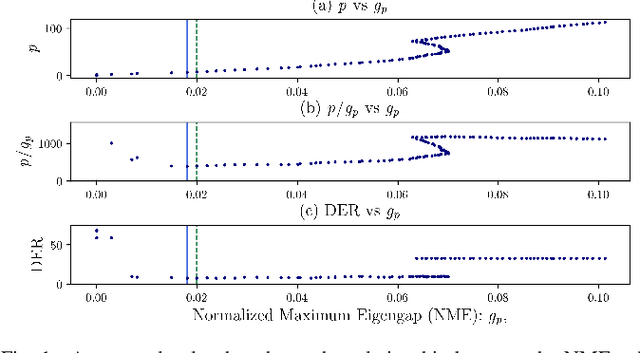
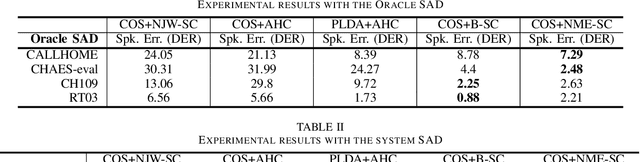
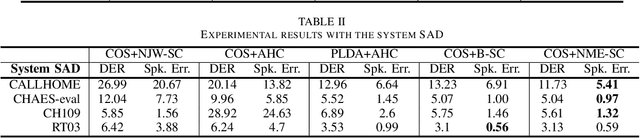
In this study, we propose a new spectral clustering framework that can auto-tune the parameters of the clustering algorithm in the context of speaker diarization. The proposed framework uses normalized maximum eigengap (NME) values to estimate the number of clusters and the parameters for the threshold of the elements of each row in an affinity matrix during spectral clustering, without the use of parameter tuning on the development set. Even through this hands-off approach, we achieve a comparable or better performance across various evaluation sets than the results found using traditional clustering methods that apply careful parameter tuning and development data. A relative improvement of 17% in the speaker error rate on the well-known CALLHOME evaluation set shows the effectiveness of our proposed spectral clustering with auto-tuning.