 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell, Don't Show!: Language Guidance Eases Transfer Across Domains in Images and Videos
Mar 08, 2024



We introduce LaGTran, a novel framework that utilizes readily available or easily acquired text descriptions to guide robust transfer of discriminative knowledge from labeled source to unlabeled target data with domain shifts. While unsupervised adaptation methods have been established to address this problem, they show limitations in handling challenging domain shifts due to their exclusive operation within the pixel-space. Motivated by our observation that semantically richer text modality has more favorable transfer properties, we devise a transfer mechanism to use a source-trained text-classifier to generate predictions on the target text descriptions, and utilize these predictions as supervision for the corresponding images. Our approach driven by language guidance is surprisingly easy and simple, yet significantly outperforms all prior approaches on challenging datasets like GeoNet and DomainNet, validating its extreme effectiveness. To further extend the scope of our study beyond images, we introduce a new benchmark to study ego-exo transfer in videos and find that our language-aided LaGTran yields significant gains in this highly challenging and non-trivial transfer setting. Code, models, and proposed datasets are publicly available at https://tarun005.github.io/lagtran/.
TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion
Jan 17, 2024



We present TextureDreamer, a novel image-guided texture synthesis method to transfer relightable textures from a small number of input images (3 to 5) to target 3D shapes across arbitrary categories. Texture creation is a pivotal challenge in vision and graphics. Industrial companies hire experienced artists to manually craft textures for 3D assets. Classical methods require densely sampled views and accurately aligned geometry, while learning-based methods are confined to category-specific shapes within the dataset. In contrast, TextureDreamer can transfer highly detailed, intricate textures from real-world environments to arbitrary objects with only a few casually captured images, potentially significantly democratizing texture creation. Our core idea, personalized geometry-aware score distillation (PGSD), draws inspiration from recent advancements in diffuse models, including personalized modeling for texture information extraction, variational score distillation for detailed appearance synthesis, and explicit geometry guidance with ControlNet. Our integration and several essential modifications substantially improve the texture quality. Experiments on real images spanning different categories show that TextureDreamer can successfully transfer highly realistic, semantic meaningful texture to arbitrary objects, surpassing the visual quality of previous state-of-the-art.
What You See is What You GAN: Rendering Every Pixel for High-Fidelity Geometry in 3D GANs
Jan 04, 2024



3D-aware Generative Adversarial Networks (GANs) have shown remarkable progress in learning to generate multi-view-consistent images and 3D geometries of scenes from collections of 2D images via neural volume rendering. Yet, the significant memory and computational costs of dense sampling in volume rendering have forced 3D GANs to adopt patch-based training or employ low-resolution rendering with post-processing 2D super resolution, which sacrifices multiview consistency and the quality of resolved geometry. Consequently, 3D GANs have not yet been able to fully resolve the rich 3D geometry present in 2D images. In this work, we propose techniques to scale neural volume rendering to the much higher resolution of native 2D images, thereby resolving fine-grained 3D geometry with unprecedented detail. Our approach employs learning-based samplers for accelerating neural rendering for 3D GAN training using up to 5 times fewer depth samples. This enables us to explicitly "render every pixel" of the full-resolution image during training and inference without post-processing superresolution in 2D. Together with our strategy to learn high-quality surface geometry, our method synthesizes high-resolution 3D geometry and strictly view-consistent images while maintaining image quality on par with baselines relying on post-processing super resolution. We demonstrate state-of-the-art 3D gemetric quality on FFHQ and AFHQ, setting a new standard for unsupervised learning of 3D shapes in 3D GANs.
Controllable Safety-Critical Closed-loop Traffic Simulation via Guided Diffusion
Dec 31, 2023Evaluating the performance of autonomous vehicle planning algorithms necessitates simulating long-tail traffic scenarios. Traditional methods for generating safety-critical scenarios often fall short in realism and controllability. Furthermore, these techniques generally neglect the dynamics of agent interactions. To mitigate these limitations, we introduce a novel closed-loop simulation framework rooted in guided diffusion models. Our approach yields two distinct advantages: 1) the generation of realistic long-tail scenarios that closely emulate real-world conditions, and 2) enhanced controllability, enabling more comprehensive and interactive evaluations. We achieve this through novel guidance objectives that enhance road progress while lowering collision and off-road rates. We develop a novel approach to simulate safety-critical scenarios through an adversarial term in the denoising process, which allows the adversarial agent to challenge a planner with plausible maneuvers, while all agents in the scene exhibit reactive and realistic behaviors. We validate our framework empirically using the NuScenes dataset, demonstrating improvements in both realism and controllability. These findings affirm that guided diffusion models provide a robust and versatile foundation for safety-critical, interactive traffic simulation, extending their utility across the broader landscape of autonomous driving. For additional resources and demonstrations, visit our project page at https://safe-sim.github.io.
LLM-Assist: Enhancing Closed-Loop Planning with Language-Based Reasoning
Dec 30, 2023Although planning is a crucial component of the autonomous driving stack, researchers have yet to develop robust planning algorithms that are capable of safely handling the diverse range of possible driving scenarios. Learning-based planners suffer from overfitting and poor long-tail performance. On the other hand, rule-based planners generalize well, but might fail to handle scenarios that require complex driving maneuvers. To address these limitations, we investigate the possibility of leveraging the common-sense reasoning capabilities of Large Language Models (LLMs) such as GPT4 and Llama2 to generate plans for self-driving vehicles. In particular, we develop a novel hybrid planner that leverages a conventional rule-based planner in conjunction with an LLM-based planner. Guided by commonsense reasoning abilities of LLMs, our approach navigates complex scenarios which existing planners struggle with, produces well-reasoned outputs while also remaining grounded through working alongside the rule-based approach. Through extensive evaluation on the nuPlan benchmark, we achieve state-of-the-art performance, outperforming all existing pure learning- and rule-based methods across most metrics. Our code will be available at https://llmassist.github.io.
Generating Enhanced Negatives for Training Language-Based Object Detectors
Dec 29, 2023The recent progress in language-based open-vocabulary object detection can be largely attributed to finding better ways of leveraging large-scale data with free-form text annotations. Training such models with a discriminative objective function has proven successful, but requires good positive and negative samples. However, the free-form nature and the open vocabulary of object descriptions make the space of negatives extremely large. Prior works randomly sample negatives or use rule-based techniques to build them. In contrast, we propose to leverage the vast knowledge built into modern generative models to automatically build negatives that are more relevant to the original data. Specifically, we use large-language-models to generate negative text descriptions, and text-to-image diffusion models to also generate corresponding negative images. Our experimental analysis confirms the relevance of the generated negative data, and its use in language-based detectors improves performance on two complex benchmarks.
OpEnCam: Lensless Optical Encryption Camera
Dec 02, 2023Lensless cameras multiplex the incoming light before it is recorded by the sensor. This ability to multiplex the incoming light has led to the development of ultra-thin, high-speed, and single-shot 3D imagers. Recently, there have been various attempts at demonstrating another useful aspect of lensless cameras - their ability to preserve the privacy of a scene by capturing encrypted measurements. However, existing lensless camera designs suffer numerous inherent privacy vulnerabilities. To demonstrate this, we develop the first comprehensive attack model for encryption cameras, and propose OpEnCam -- a novel lensless OPtical ENcryption CAmera design that overcomes these vulnerabilities. OpEnCam encrypts the incoming light before capturing it using the modulating ability of optical masks. Recovery of the original scene from an OpEnCam measurement is possible only if one has access to the camera's encryption key, defined by the unique optical elements of each camera. Our OpEnCam design introduces two major improvements over existing lensless camera designs - (a) the use of two co-axially located optical masks, one stuck to the sensor and the other a few millimeters above the sensor and (b) the design of mask patterns, which are derived heuristically from signal processing ideas. We show, through experiments, that OpEnCam is robust against a range of attack types while still maintaining the imaging capabilities of existing lensless cameras. We validate the efficacy of OpEnCam using simulated and real data. Finally, we built and tested a prototype in the lab for proof-of-concept.
Exploring Question Decomposition for Zero-Shot VQA
Oct 25, 2023



Visual question answering (VQA) has traditionally been treated as a single-step task where each question receives the same amount of effort, unlike natural human question-answering strategies. We explore a question decomposition strategy for VQA to overcome this limitation. We probe the ability of recently developed large vision-language models to use human-written decompositions and produce their own decompositions of visual questions, finding they are capable of learning both tasks from demonstrations alone. However, we show that naive application of model-written decompositions can hurt performance. We introduce a model-driven selective decomposition approach for second-guessing predictions and correcting errors, and validate its effectiveness on eight VQA tasks across three domains, showing consistent improvements in accuracy, including improvements of >20% on medical VQA datasets and boosting the zero-shot performance of BLIP-2 above chance on a VQA reformulation of the challenging Winoground task. Project Site: https://zaidkhan.me/decomposition-0shot-vqa/
Domain Generalization Guided by Gradient Signal to Noise Ratio of Parameters
Oct 11, 2023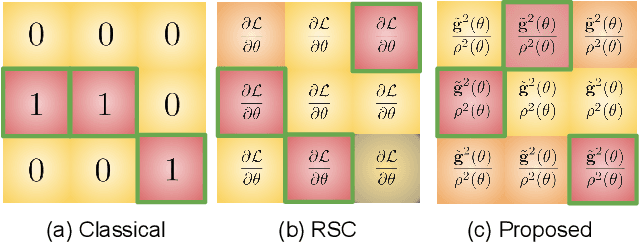



Overfitting to the source domain is a common issue in gradient-based training of deep neural networks. To compensate for the over-parameterized models, numerous regularization techniques have been introduced such as those based on dropout. While these methods achieve significant improvements on classical benchmarks such as ImageNet, their performance diminishes with the introduction of domain shift in the test set i.e. when the unseen data comes from a significantly different distribution. In this paper, we move away from the classical approach of Bernoulli sampled dropout mask construction and propose to base the selection on gradient-signal-to-noise ratio (GSNR) of network's parameters. Specifically, at each training step, parameters with high GSNR will be discarded. Furthermore, we alleviate the burden of manually searching for the optimal dropout ratio by leveraging a meta-learning approach. We evaluate our method on standard domain generalization benchmarks and achieve competitive results on classification and face anti-spoofing problems.
Efficient Controllable Multi-Task Architectures
Aug 22, 2023



We aim to train a multi-task model such that users can adjust the desired compute budget and relative importance of task performances after deployment, without retraining. This enables optimizing performance for dynamically varying user needs, without heavy computational overhead to train and save models for various scenarios. To this end, we propose a multi-task model consisting of a shared encoder and task-specific decoders where both encoder and decoder channel widths are slimmable. Our key idea is to control the task importance by varying the capacities of task-specific decoders, while controlling the total computational cost by jointly adjusting the encoder capacity. This improves overall accuracy by allowing a stronger encoder for a given budget, increases control over computational cost, and delivers high-quality slimmed sub-architectures based on user's constraints. Our training strategy involves a novel 'Configuration-Invariant Knowledge Distillation' loss that enforces backbone representations to be invariant under different runtime width configurations to enhance accuracy. Further, we present a simple but effective search algorithm that translates user constraints to runtime width configurations of both the shared encoder and task decoders, for sampling the sub-architectures. The key rule for the search algorithm is to provide a larger computational budget to the higher preferred task decoder, while searching a shared encoder configuration that enhances the overall MTL performance. Various experiments on three multi-task benchmarks (PASCALContext, NYUDv2, and CIFAR100-MTL) with diverse backbone architectures demonstrate the advantage of our approach. For example, our method shows a higher controllability by ~33.5% in the NYUD-v2 dataset over prior methods, while incurring much less compute cost.