 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Multi-Figurative Language Detection
May 31, 2023



Figures of speech help people express abstract concepts and evoke stronger emotions than literal expressions, thereby making texts more creative and engaging. Due to its pervasive and fundamental character, figurative language understanding has been addressed in Natural Language Processing, but it's highly understudied in a multilingual setting and when considering more than one figure of speech at the same time. To bridge this gap, we introduce multilingual multi-figurative language modelling, and provide a benchmark for sentence-level figurative language detection, covering three common figures of speech and seven languages. Specifically, we develop a framework for figurative language detection based on template-based prompt learning. In so doing, we unify multiple detection tasks that are interrelated across multiple figures of speech and languages, without requiring task- or language-specific modules. Experimental results show that our framework outperforms several strong baselines and may serve as a blueprint for the joint modelling of other interrelated tasks.
Pre-Trained Language-Meaning Models for Multilingual Parsing and Generation
May 31, 2023



Pre-trained language models (PLMs) have achieved great success in NLP and have recently been used for tasks in computational semantics. However, these tasks do not fully benefit from PLMs since meaning representations are not explicitly included in the pre-training stage. We introduce multilingual pre-trained language-meaning models based on Discourse Representation Structures (DRSs), including meaning representations besides natural language texts in the same model, and design a new strategy to reduce the gap between the pre-training and fine-tuning objectives. Since DRSs are language neutral, cross-lingual transfer learning is adopted to further improve the performance of non-English tasks. Automatic evaluation results show that our approach achieves the best performance on both the multilingual DRS parsing and DRS-to-text generation tasks. Correlation analysis between automatic metrics and human judgements on the generation task further validates the effectiveness of our model. Human inspection reveals that out-of-vocabulary tokens are the main cause of erroneous results.
DUMB: A Benchmark for Smart Evaluation of Dutch Models
May 22, 2023



We introduce the Dutch Model Benchmark: DUMB. The benchmark includes a diverse set of datasets for low-, medium- and high-resource tasks. The total set of eight tasks include three tasks that were previously not available in Dutch. Instead of relying on a mean score across tasks, we propose Relative Error Reduction (RER), which compares the DUMB performance of models to a strong baseline which can be referred to in the future even when assessing different sets of models. Through a comparison of 14 pre-trained models (mono- and multi-lingual, of varying sizes), we assess the internal consistency of the benchmark tasks, as well as the factors that likely enable high performance. Our results indicate that current Dutch monolingual models under-perform and suggest training larger Dutch models with other architectures and pre-training objectives. At present, the highest performance is achieved by DeBERTaV3 (large), XLM-R (large) and mDeBERTaV3 (base). In addition to highlighting best strategies for training larger Dutch models, DUMB will foster further research on Dutch. A public leaderboard is available at https://dumbench.nl.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023



We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Multidimensional Evaluation for Text Style Transfer Using ChatGPT
Apr 26, 2023We investigate the potential of ChatGPT as a multidimensional evaluator for the task of \emph{Text Style Transfer}, alongside, and in comparison to, existing automatic metrics as well as human judgements. We focus on a zero-shot setting, i.e. prompting ChatGPT with specific task instructions, and test its performance on three commonly-used dimensions of text style transfer evaluation: style strength, content preservation, and fluency. We perform a comprehensive correlation analysis for two transfer directions (and overall) at different levels. Compared to existing automatic metrics, ChatGPT achieves competitive correlations with human judgments. These preliminary results are expected to provide a first glimpse into the role of large language models in the multidimensional evaluation of stylized text generation.
Dead or Murdered? Predicting Responsibility Perception in Femicide News Reports
Sep 24, 2022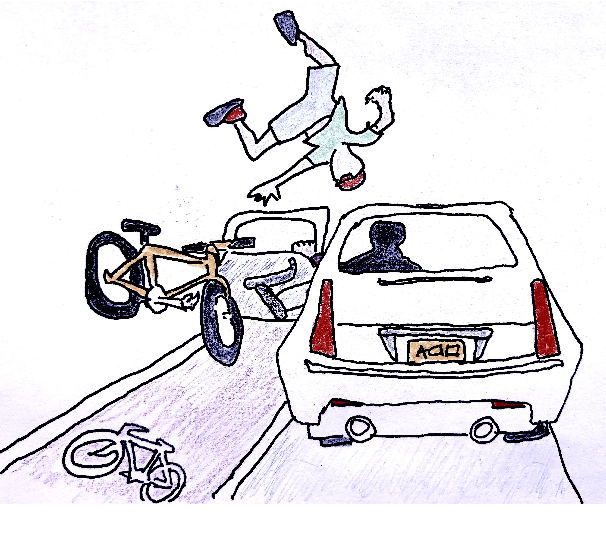


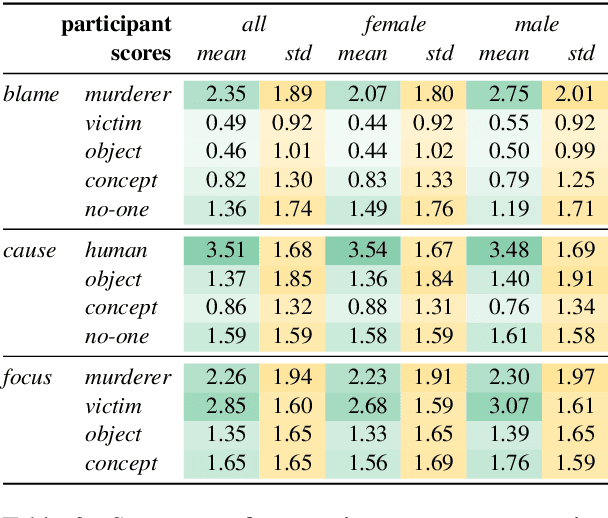
Different linguistic expressions can conceptualize the same event from different viewpoints by emphasizing certain participants over others. Here, we investigate a case where this has social consequences: how do linguistic expressions of gender-based violence (GBV) influence who we perceive as responsible? We build on previous psycholinguistic research in this area and conduct a large-scale perception survey of GBV descriptions automatically extracted from a corpus of Italian newspapers. We then train regression models that predict the salience of GBV participants with respect to different dimensions of perceived responsibility. Our best model (fine-tuned BERT) shows solid overall performance, with large differences between dimensions and participants: salient _focus_ is more predictable than salient _blame_, and perpetrators' salience is more predictable than victims' salience. Experiments with ridge regression models using different representations show that features based on linguistic theory similarly to word-based features. Overall, we show that different linguistic choices do trigger different perceptions of responsibility, and that such perceptions can be modelled automatically. This work can be a core instrument to raise awareness of the consequences of different perspectivizations in the general public and in news producers alike.
Multi-Figurative Language Generation
Sep 05, 2022
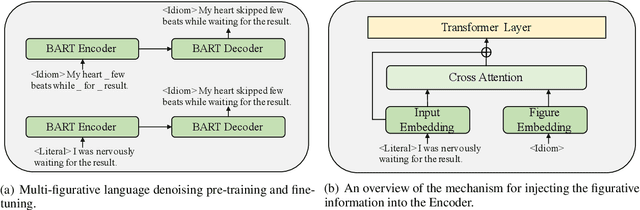

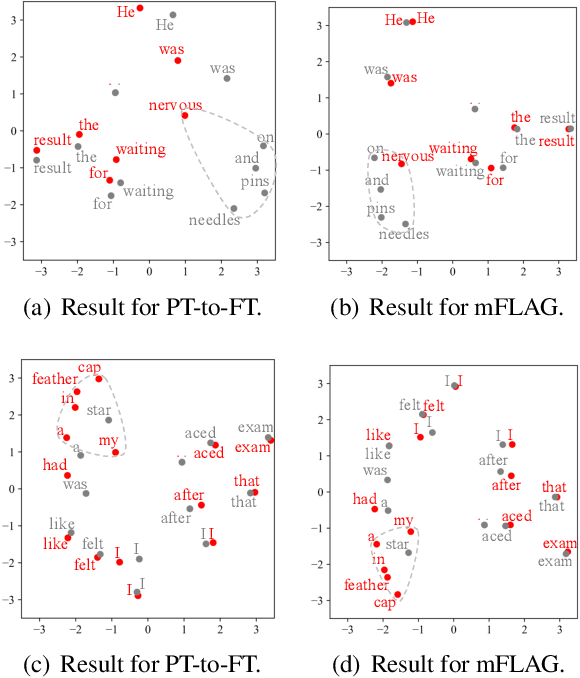
Figurative language generation is the task of reformulating a given text in the desired figure of speech while still being faithful to the original context. We take the first step towards multi-figurative language modelling by providing a benchmark for the automatic generation of five common figurative forms in English. We train mFLAG employing a scheme for multi-figurative language pre-training on top of BART, and a mechanism for injecting the target figurative information into the encoder; this enables the generation of text with the target figurative form from another figurative form without parallel figurative-figurative sentence pairs. Our approach outperforms all strong baselines. We also offer some qualitative analysis and reflections on the relationship between the different figures of speech.
Human Judgement as a Compass to Navigate Automatic Metrics for Formality Transfer
Apr 15, 2022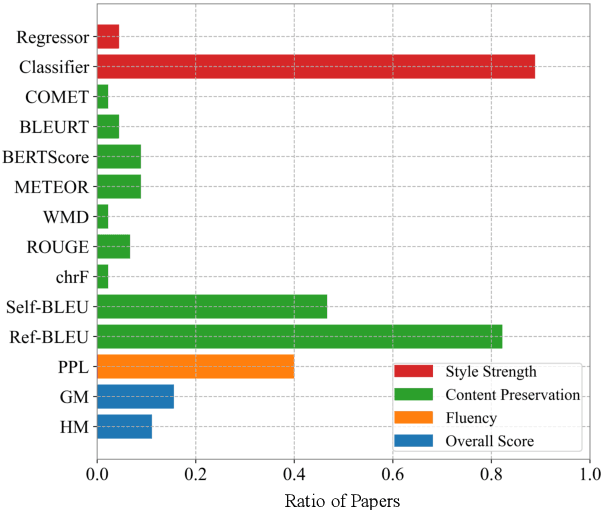
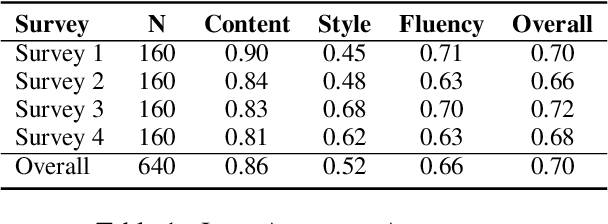
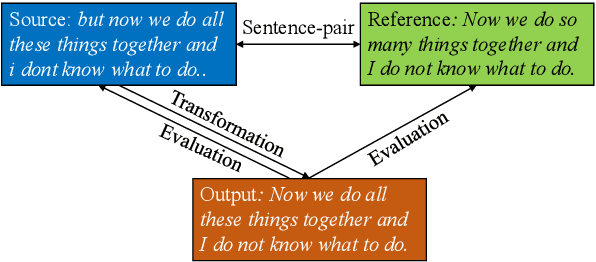

Although text style transfer has witnessed rapid development in recent years, there is as yet no established standard for evaluation, which is performed using several automatic metrics, lacking the possibility of always resorting to human judgement. We focus on the task of formality transfer, and on the three aspects that are usually evaluated: style strength, content preservation, and fluency. To cast light on how such aspects are assessed by common and new metrics, we run a human-based evaluation and perform a rich correlation analysis. We are then able to offer some recommendations on the use of such metrics in formality transfer, also with an eye to their generalisability (or not) to related tasks.
Multilingual Pre-training with Language and Task Adaptation for Multilingual Text Style Transfer
Mar 16, 2022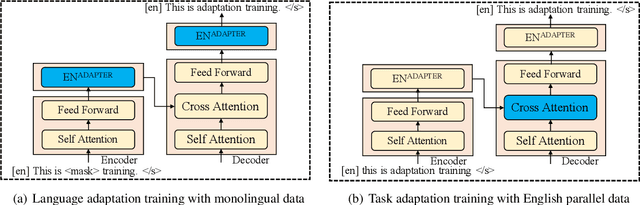
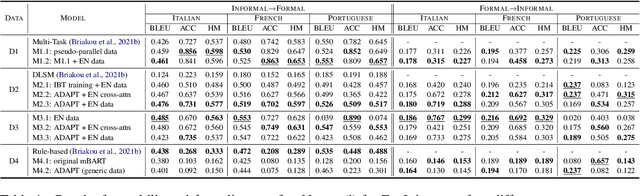
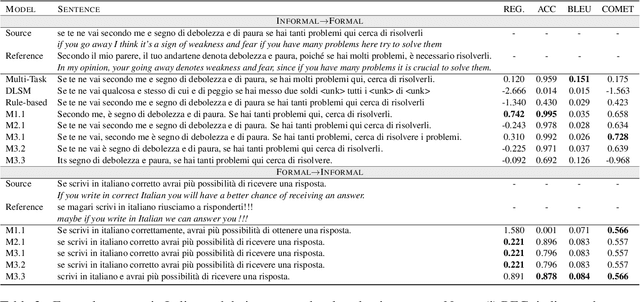
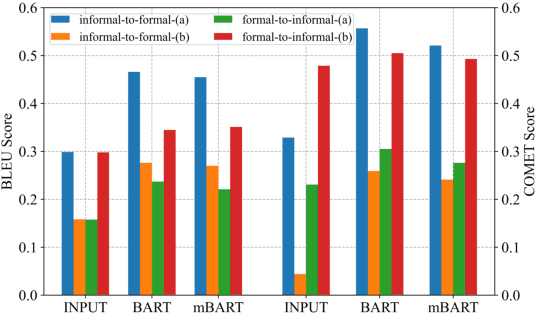
We exploit the pre-trained seq2seq model mBART for multilingual text style transfer. Using machine translated data as well as gold aligned English sentences yields state-of-the-art results in the three target languages we consider. Besides, in view of the general scarcity of parallel data, we propose a modular approach for multilingual formality transfer, which consists of two training strategies that target adaptation to both language and task. Our approach achieves competitive performance without monolingual task-specific parallel data and can be applied to other style transfer tasks as well as to other languages.
IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation
Mar 07, 2022
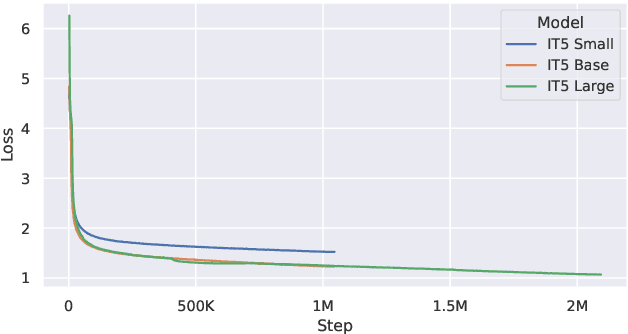
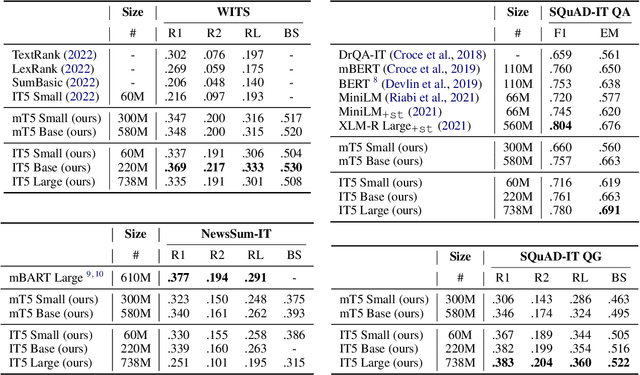
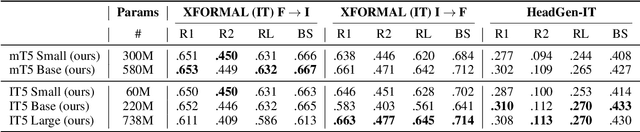
The T5 model and its unified text-to-text paradigm contributed in advancing the state-of-the-art for many natural language processing tasks. While some multilingual variants of the T5 model have recently been introduced, their performances were found to provide suboptimal performances for languages other than English if compared to monolingual variants. We are motivated by these findings to introduce IT5, the first family of encoder-decoder transformer models pretrained specifically on Italian. We perform a thorough cleaning of a web-crawled Italian corpus including more than 40 billion words and use it to pretrain three IT5 models of different sizes. The performance of IT5 models and their multilingual counterparts is then evaluated on a broad range of natural language understanding and generation benchmarks for Italian. We find the monolingual IT5 models to provide the best scale-to-performance ratio across tested models, consistently outperforming their multilingual counterparts and setting a new state-of-the-art for most Italian conditional language generation tasks.