 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Visual Speech Recognition for Small-Scale Datasets
Apr 02, 2019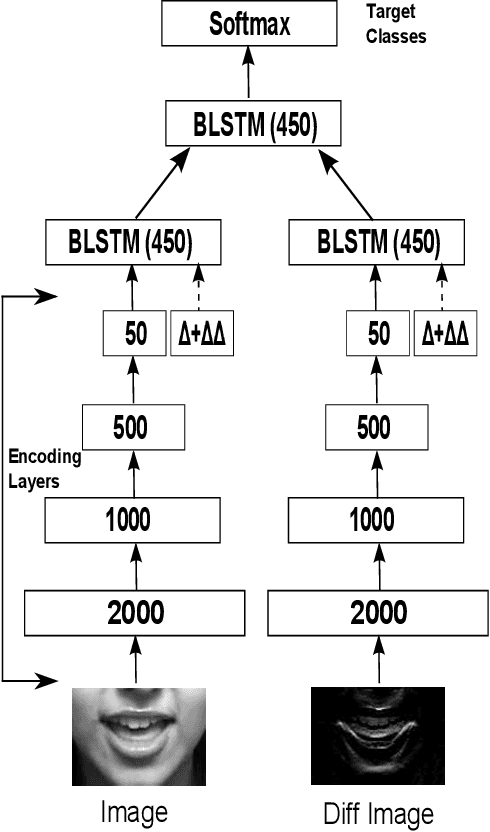
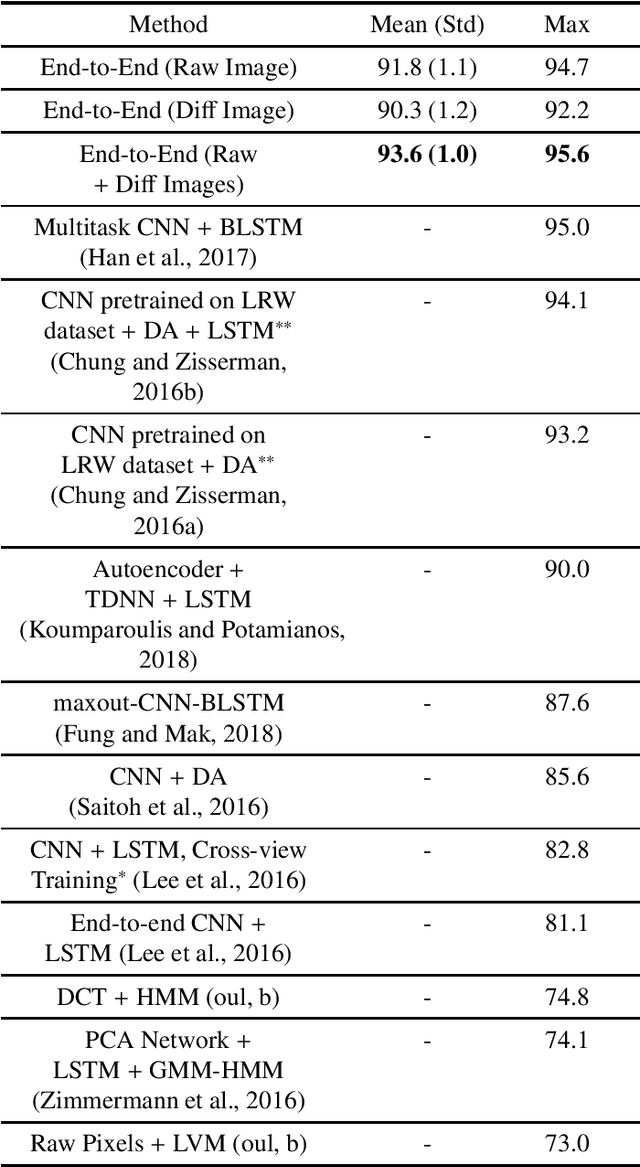
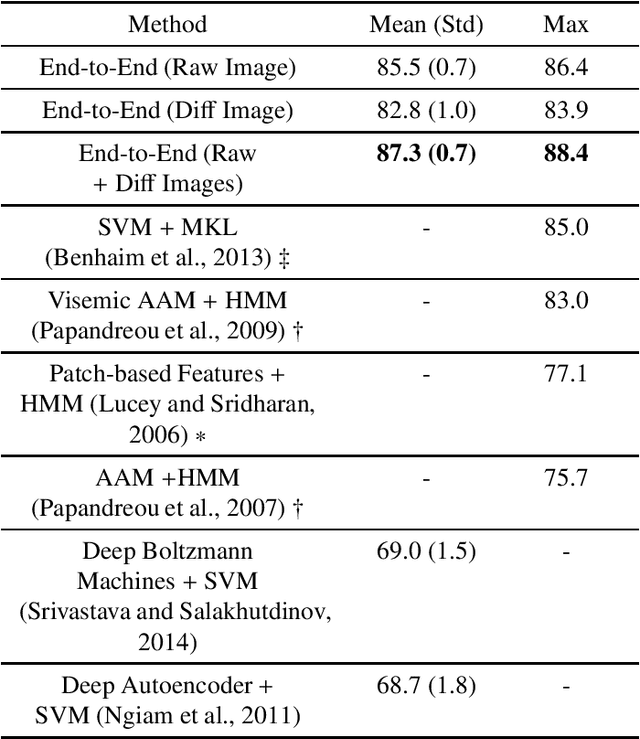
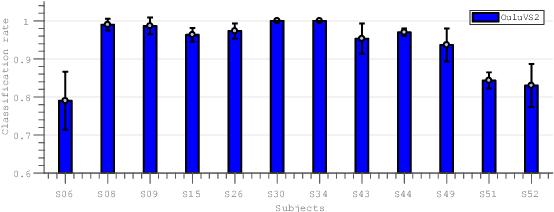
Traditional visual speech recognition systems consist of two stages, feature extraction and classification. Recently, several deep learning approaches have been presented which automatically extract features from the mouth images and aim to replace the feature extraction stage. However, research on joint learning of features and classification remains limited. In addition, most of the existing methods require large amounts of data in order to achieve state-of-the-art performance, otherwise they under-perform. In this work, we present an end-to-end visual speech recognition system based on fully-connected layers and Long-Short Memory (LSTM) networks which is suitable for small-scale datasets. The model consists of two streams which extract features directly from the mouth and difference images, respectively. The temporal dynamics in each stream are modelled by a Bidirectional LSTM (BLSTM) and the fusion of the two streams takes place via another BLSTM. An absolute improvement of 0.6%, 3.4%, 3.9%, 11.4% over the state-of-the-art is reported on the OuluVS2, CUAVE, AVLetters and AVLetters2 databases, respectively.
MeshGAN: Non-linear 3D Morphable Models of Faces
Mar 25, 2019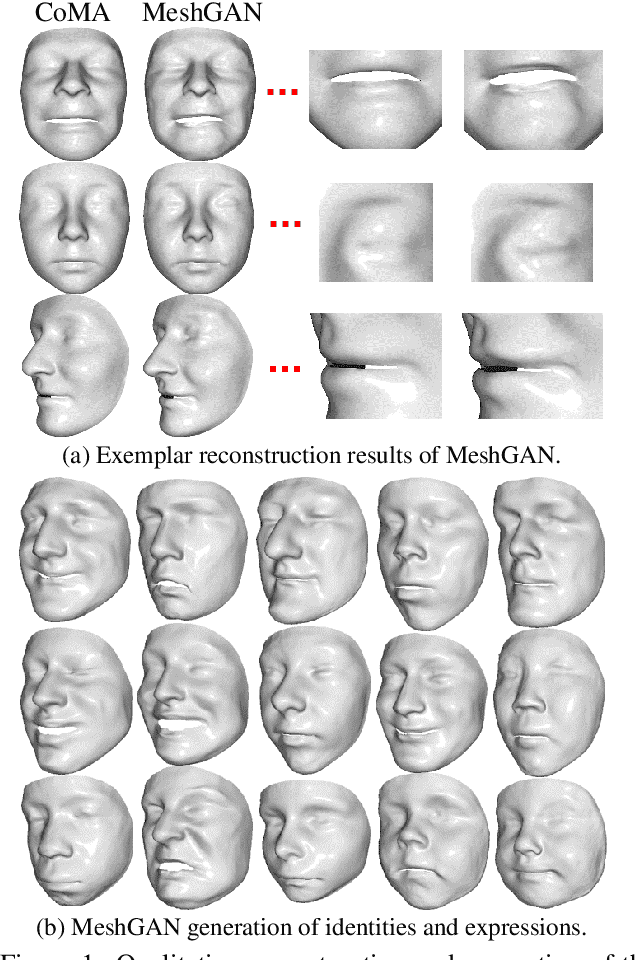


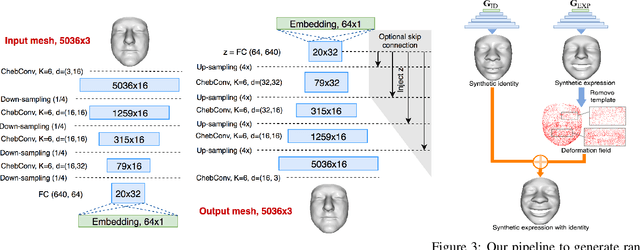
Generative Adversarial Networks (GANs) are currently the method of choice for generating visual data. Certain GAN architectures and training methods have demonstrated exceptional performance in generating realistic synthetic images (in particular, of human faces). However, for 3D object, GANs still fall short of the success they have had with images. One of the reasons is due to the fact that so far GANs have been applied as 3D convolutional architectures to discrete volumetric representations of 3D objects. In this paper, we propose the first intrinsic GANs architecture operating directly on 3D meshes (named as MeshGAN). Both quantitative and qualitative results are provided to show that MeshGAN can be used to generate high-fidelity 3D face with rich identities and expressions.
SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild
Jan 09, 2019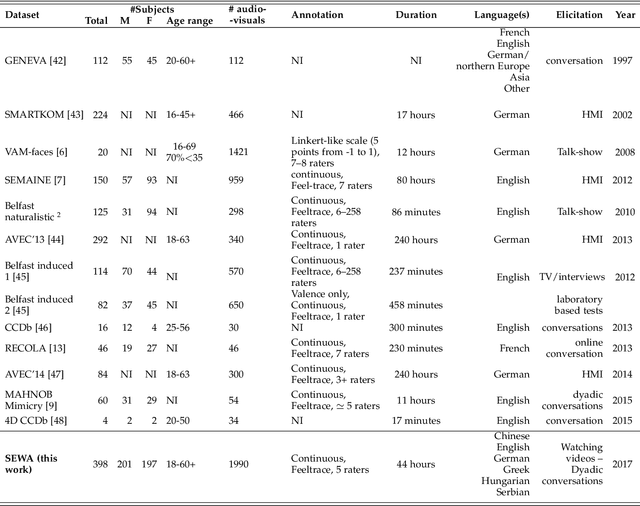
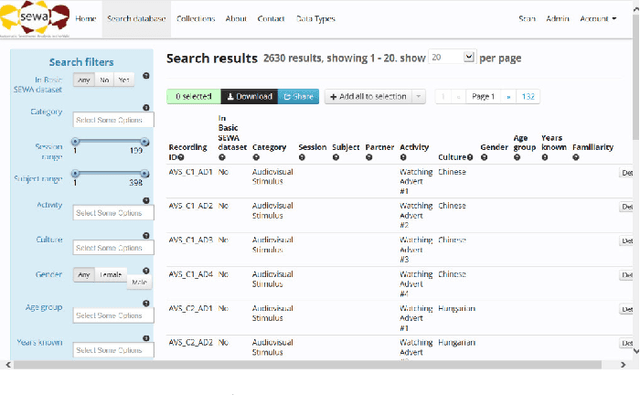
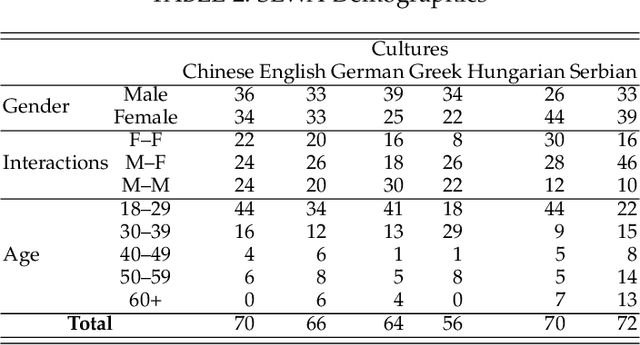

Natural human-computer interaction and audio-visual human behaviour sensing systems, which would achieve robust performance in-the-wild are more needed than ever as digital devices are becoming indispensable part of our life more and more. Accurately annotated real-world data are the crux in devising such systems. However, existing databases usually consider controlled settings, low demographic variability, and a single task. In this paper, we introduce the SEWA database of more than 2000 minutes of audio-visual data of 398 people coming from six cultures, 50% female, and uniformly spanning the age range of 18 to 65 years old. Subjects were recorded in two different contexts: while watching adverts and while discussing adverts in a video chat. The database includes rich annotations of the recordings in terms of facial landmarks, facial action units (FAU), various vocalisations, mirroring, and continuously valued valence, arousal, liking, agreement, and prototypic examples of (dis)liking. This database aims to be an extremely valuable resource for researchers in affective computing and automatic human sensing and is expected to push forward the research in human behaviour analysis, including cultural studies. Along with the database, we provide extensive baseline experiments for automatic FAU detection and automatic valence, arousal and (dis)liking intensity estimation.
Photorealistic Facial Synthesis in the Dimensional Affect Space
Nov 11, 2018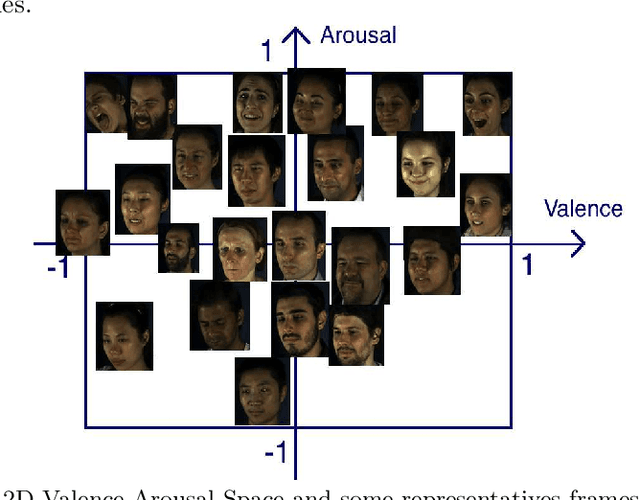
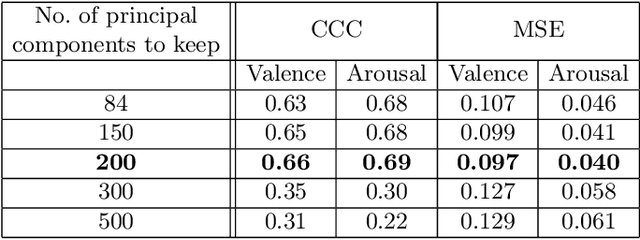
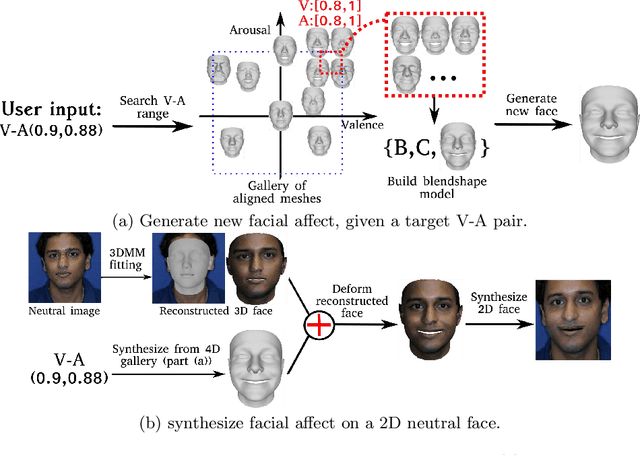

This paper presents a novel approach for synthesizing facial affect, which is based on our annotating 600,000 frames of the 4DFAB database in terms of valence and arousal. The input of this approach is a pair of these emotional state descriptors and a neutral 2D image of a person to whom the corresponding affect will be synthesized. Given this target pair, a set of 3D facial meshes is selected, which is used to build a blendshape model and generate the new facial affect. To synthesize the affect on the 2D neutral image, 3DMM fitting is performed and the reconstructed face is deformed to generate the target facial expressions. Last, the new face is rendered into the original image. Both qualitative and quantitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known databases, such as the Aff-Wild, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus.
Audio-Visual Speech Recognition With A Hybrid CTC/Attention Architecture
Sep 28, 2018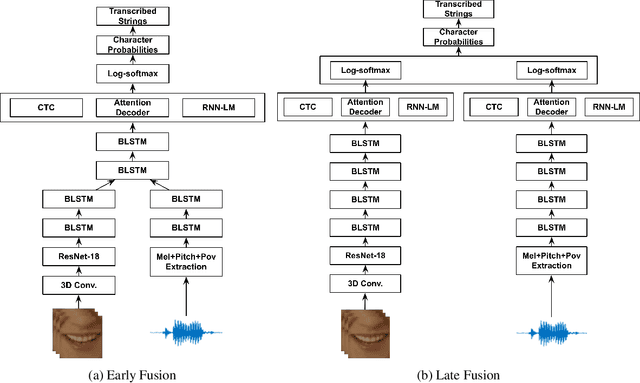

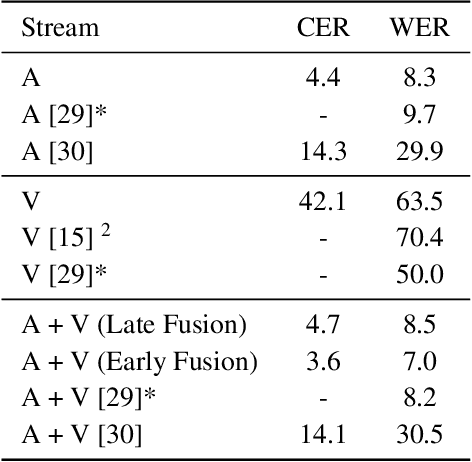
Recent works in speech recognition rely either on connectionist temporal classification (CTC) or sequence-to-sequence models for character-level recognition. CTC assumes conditional independence of individual characters, whereas attention-based models can provide nonsequential alignments. Therefore, we could use a CTC loss in combination with an attention-based model in order to force monotonic alignments and at the same time get rid of the conditional independence assumption. In this paper, we use the recently proposed hybrid CTC/attention architecture for audio-visual recognition of speech in-the-wild. To the best of our knowledge, this is the first time that such a hybrid architecture architecture is used for audio-visual recognition of speech. We use the LRS2 database and show that the proposed audio-visual model leads to an 1.3% absolute decrease in word error rate over the audio-only model and achieves the new state-of-the-art performance on LRS2 database (7% word error rate). We also observe that the audio-visual model significantly outperforms the audio-based model (up to 32.9% absolute improvement in word error rate) for several different types of noise as the signal-to-noise ratio decreases.
Face Mask Extraction in Video Sequence
Jul 24, 2018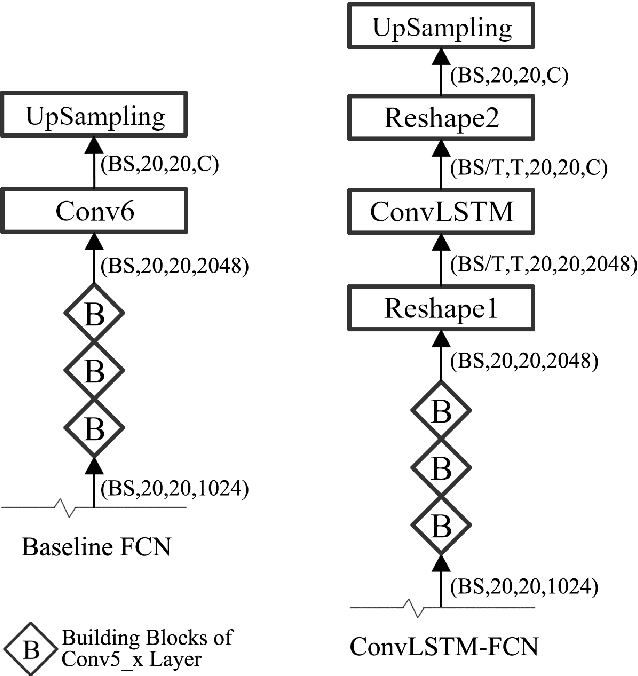
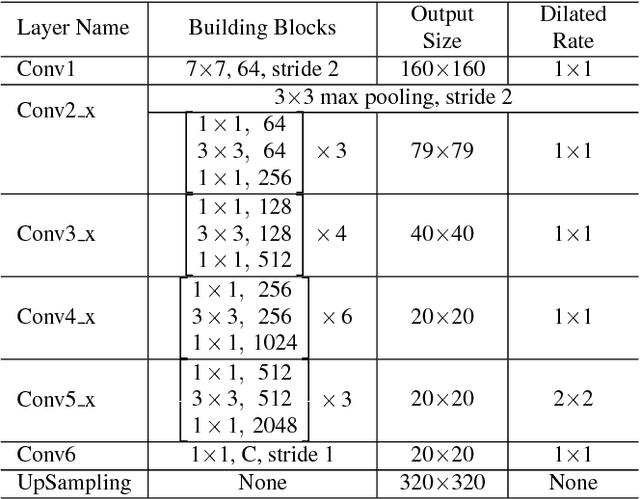
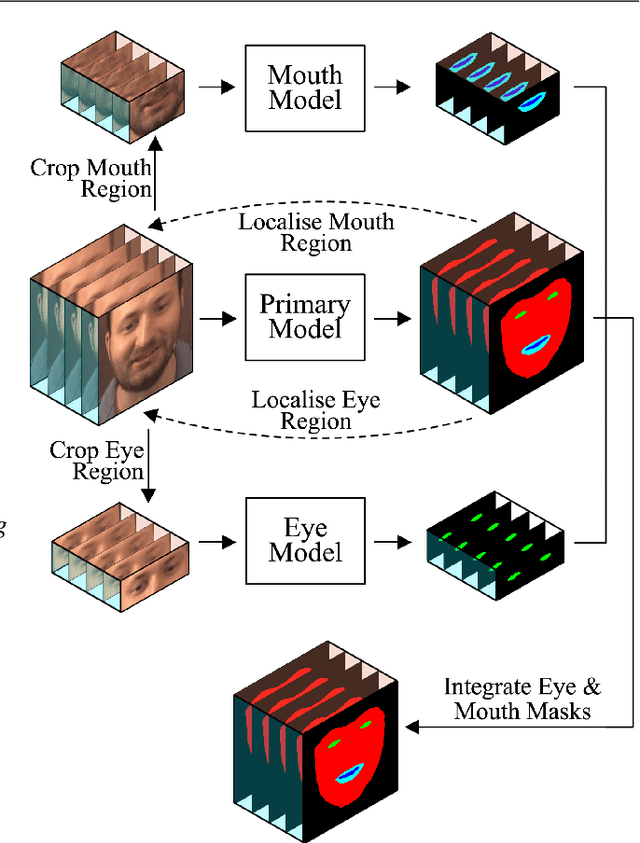
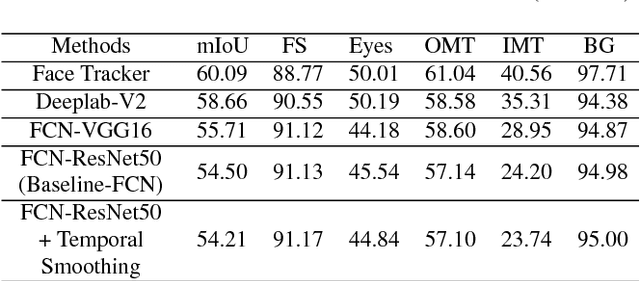
Inspired by the recent development of deep network-based methods in semantic image segmentation, we introduce an end-to-end trainable model for face mask extraction in video sequence. Comparing to landmark-based sparse face shape representation, our method can produce the segmentation masks of individual facial components, which can better reflect their detailed shape variations. By integrating Convolutional LSTM (ConvLSTM) algorithm with Fully Convolutional Networks (FCN), our new ConvLSTM-FCN model works on a per-sequence basis and takes advantage of the temporal correlation in video clips. In addition, we also propose a novel loss function, called Segmentation Loss, to directly optimise the Intersection over Union (IoU) performances. In practice, to further increase segmentation accuracy, one primary model and two additional models were trained to focus on the face, eyes, and mouth regions, respectively. Our experiment shows the proposed method has achieved a 16.99% relative improvement (from 54.50% to 63.76% mean IoU) over the baseline FCN model on the 300 Videos in the Wild (300VW) dataset.
Transfer Learning for Action Unit Recognition
Jul 19, 2018
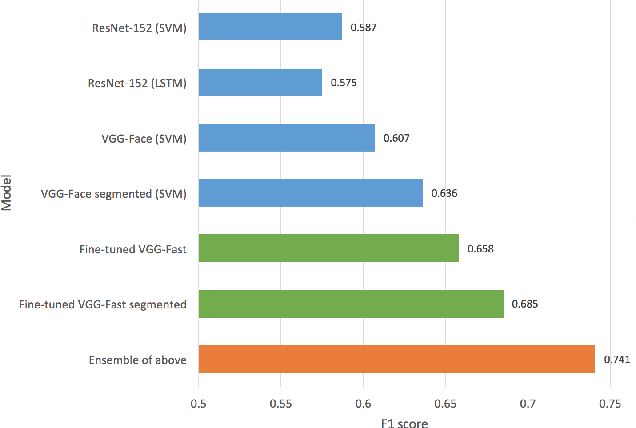
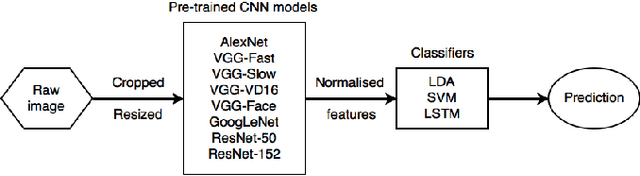
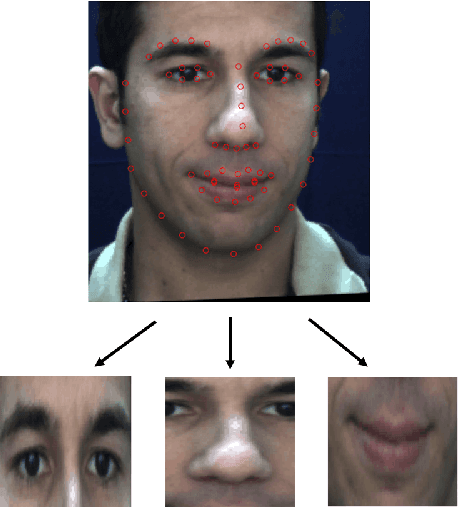
This paper presents a classifier ensemble for Facial Expression Recognition (FER) based on models derived from transfer learning. The main experimentation work is conducted for facial action unit detection using feature extraction and fine-tuning convolutional neural networks (CNNs). Several classifiers for extracted CNN codes such as Linear Discriminant Analysis (LDA), Support Vector Machines (SVMs) and Long Short-Term Memory (LSTM) are compared and evaluated. Multi-model ensembles are also used to further improve the performance. We have found that VGG-Face and ResNet are the relatively optimal pre-trained models for action unit recognition using feature extraction and the ensemble of VGG-Net variants and ResNet achieves the best result.
End-to-End Speech-Driven Facial Animation with Temporal GANs
Jul 19, 2018

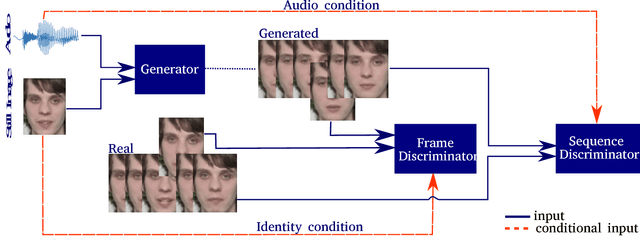

Speech-driven facial animation is the process which uses speech signals to automatically synthesize a talking character. The majority of work in this domain creates a mapping from audio features to visual features. This often requires post-processing using computer graphics techniques to produce realistic albeit subject dependent results. We present a system for generating videos of a talking head, using a still image of a person and an audio clip containing speech, that doesn't rely on any handcrafted intermediate features. To the best of our knowledge, this is the first method capable of generating subject independent realistic videos directly from raw audio. Our method can generate videos which have (a) lip movements that are in sync with the audio and (b) natural facial expressions such as blinks and eyebrow movements. We achieve this by using a temporal GAN with 2 discriminators, which are capable of capturing different aspects of the video. The effect of each component in our system is quantified through an ablation study. The generated videos are evaluated based on their sharpness, reconstruction quality, and lip-reading accuracy. Finally, a user study is conducted, confirming that temporal GANs lead to more natural sequences than a static GAN-based approach.
4DFAB: A Large Scale 4D Facial Expression Database for Biometric Applications
Jun 14, 2018
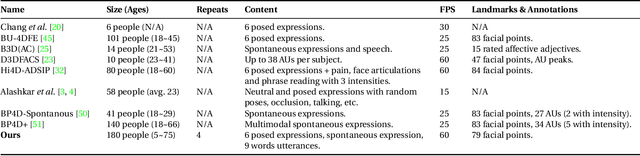


The progress we are currently witnessing in many computer vision applications, including automatic face analysis, would not be made possible without tremendous efforts in collecting and annotating large scale visual databases. To this end, we propose 4DFAB, a new large scale database of dynamic high-resolution 3D faces (over 1,800,000 3D meshes). 4DFAB contains recordings of 180 subjects captured in four different sessions spanning over a five-year period. It contains 4D videos of subjects displaying both spontaneous and posed facial behaviours. The database can be used for both face and facial expression recognition, as well as behavioural biometrics. It can also be used to learn very powerful blendshapes for parametrising facial behaviour. In this paper, we conduct several experiments and demonstrate the usefulness of the database for various applications. The database will be made publicly available for research purposes.
Mobile Face Tracking: A Survey and Benchmark
May 24, 2018
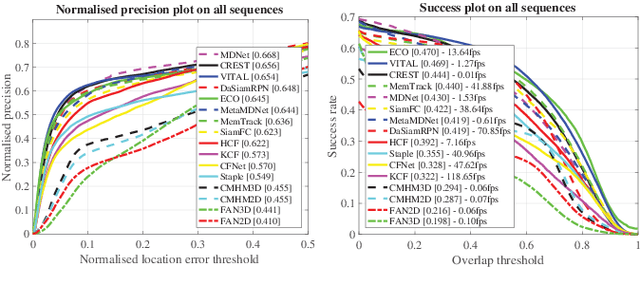
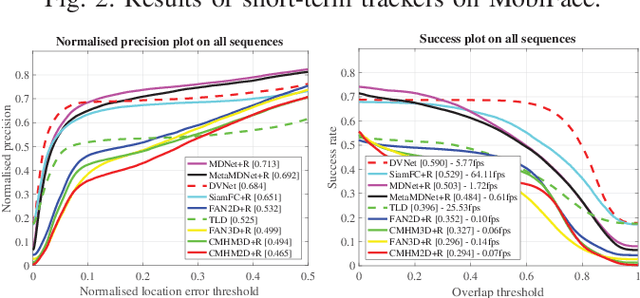
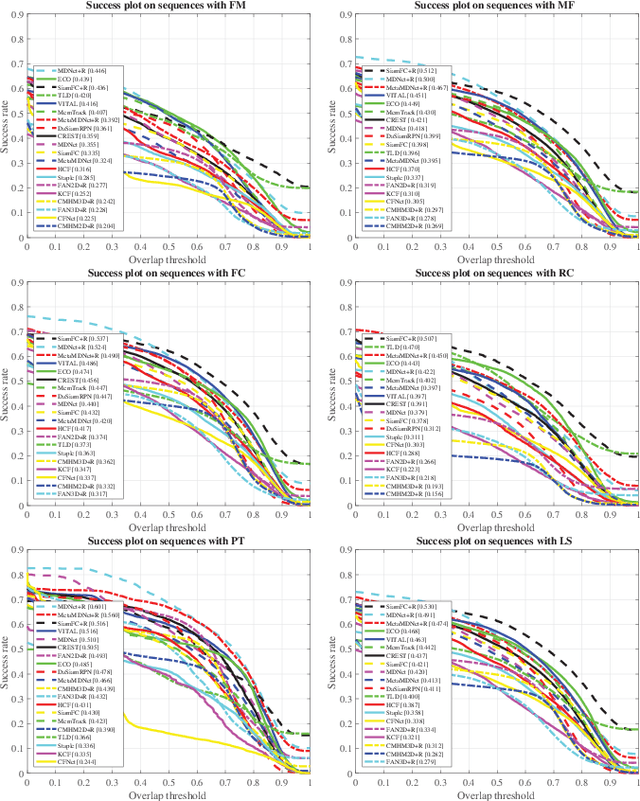
With the rapid development of smartphones, facial analysis has been playing an increasingly important role in a multitude of mobile applications. In most scenarios, face tracking serves as a crucial first step because more often than not, a mobile application would only need to focus on analysing a specific face in a complex setting. Albeit inheriting many commons traits of the generic visual tracking problem, face tracking in mobile scenarios is characterised by a unique set of challenges. In this work, we propose iBUG MobiFace benchmark, the first mobile face tracking benchmark consisting of 50 sequences captured by smartphone users in unconstrained environments. The sequences contain a total of 50,736 frames with 46 distinct identities to be tracked. The tracking target in each sequence is selected with varying difficulties in mobile scenarios. In addition to frame by frame bounding box, the annotations of 9 sequence attributes(e.g. multiple faces) are provided. We further provide a survey of 23 state-of-the-art visual trackers and a comprehensive quantitative evaluation of these methods on the proposed benchmark. In particular, trackers from two most popular frameworks, namely, correlation filter-based tracking and deep learning-based tracking, are studied. Our experiment shows that (a) the performance of all existing generic object trackers drops significantly on the mobile face tracking scenario, suggesting the need of more research effort into mobile face tracking, and (b) the effective combination of deep learning tracking and face-related algorithms(e.g. face detection) provides the most promising basis for future developments in the field. The database, annotations and evaluation protocol/code will be made publicly available on the iBUG website.