 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamicVGGT: Learning Dynamic Point Maps for 4D Scene Reconstruction in Autonomous Driving
Mar 09, 2026Dynamic scene reconstruction in autonomous driving remains a fundamental challenge due to significant temporal variations, moving objects, and complex scene dynamics. Existing feed-forward 3D models have demonstrated strong performance in static reconstruction but still struggle to capture dynamic motion. To address these limitations, we propose DynamicVGGT, a unified feed-forward framework that extends VGGT from static 3D perception to dynamic 4D reconstruction. Our goal is to model point motion within feed-forward 3D models in a dynamic and temporally coherent manner. To this end, we jointly predict the current and future point maps within a shared reference coordinate system, allowing the model to implicitly learn dynamic point representations through temporal correspondence. To efficiently capture temporal dependencies, we introduce a Motion-aware Temporal Attention (MTA) module that learns motion continuity. Furthermore, we design a Dynamic 3D Gaussian Splatting Head that explicitly models point motion by predicting Gaussian velocities using learnable motion tokens under scene flow supervision. It refines dynamic geometry through continuous 3D Gaussian optimization. Extensive experiments on autonomous driving datasets demonstrate that DynamicVGGT significantly outperforms existing methods in reconstruction accuracy, achieving robust feed-forward 4D dynamic scene reconstruction under complex driving scenarios.
End-to-end Audiovisual Speech Recognition
Feb 22, 2018
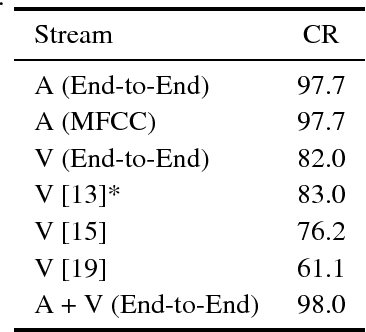
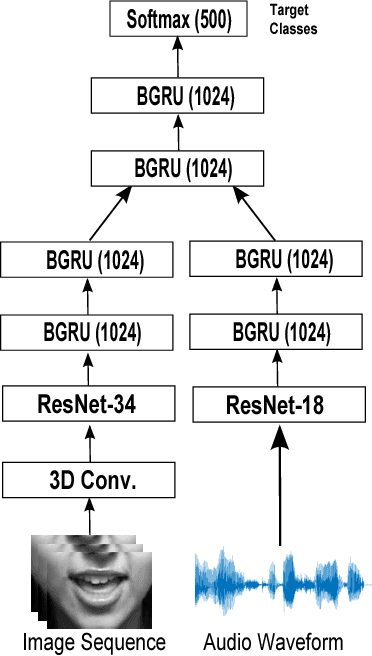
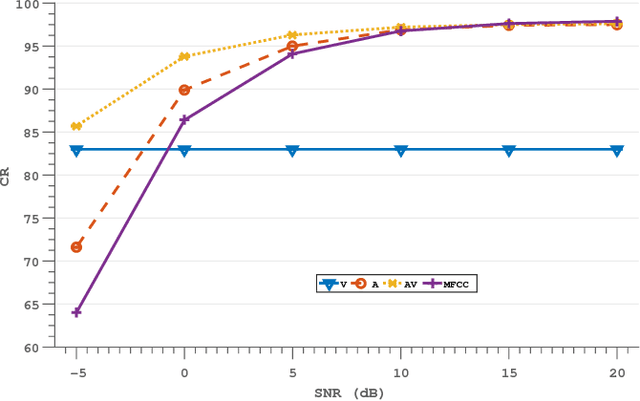
Several end-to-end deep learning approaches have been recently presented which extract either audio or visual features from the input images or audio signals and perform speech recognition. However, research on end-to-end audiovisual models is very limited. In this work, we present an end-to-end audiovisual model based on residual networks and Bidirectional Gated Recurrent Units (BGRUs). To the best of our knowledge, this is the first audiovisual fusion model which simultaneously learns to extract features directly from the image pixels and audio waveforms and performs within-context word recognition on a large publicly available dataset (LRW). The model consists of two streams, one for each modality, which extract features directly from mouth regions and raw waveforms. The temporal dynamics in each stream/modality are modeled by a 2-layer BGRU and the fusion of multiple streams/modalities takes place via another 2-layer BGRU. A slight improvement in the classification rate over an end-to-end audio-only and MFCC-based model is reported in clean audio conditions and low levels of noise. In presence of high levels of noise, the end-to-end audiovisual model significantly outperforms both audio-only models.