 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-AVSR: Audio-Visual Speech Recognition with Automatic Labels
Mar 25, 2023Audio-visual speech recognition has received a lot of attention due to its robustness against acoustic noise. Recently, the performance of automatic, visual, and audio-visual speech recognition (ASR, VSR, and AV-ASR, respectively) has been substantially improved, mainly due to the use of larger models and training sets. However, accurate labelling of datasets is time-consuming and expensive. Hence, in this work, we investigate the use of automatically-generated transcriptions of unlabelled datasets to increase the training set size. For this purpose, we use publicly-available pre-trained ASR models to automatically transcribe unlabelled datasets such as AVSpeech and VoxCeleb2. Then, we train ASR, VSR and AV-ASR models on the augmented training set, which consists of the LRS2 and LRS3 datasets as well as the additional automatically-transcribed data. We demonstrate that increasing the size of the training set, a recent trend in the literature, leads to reduced WER despite using noisy transcriptions. The proposed model achieves new state-of-the-art performance on AV-ASR on LRS2 and LRS3. In particular, it achieves a WER of 0.9% on LRS3, a relative improvement of 30% over the current state-of-the-art approach, and outperforms methods that have been trained on non-publicly available datasets with 26 times more training data.
Learning Cross-lingual Visual Speech Representations
Mar 14, 2023



Cross-lingual self-supervised learning has been a growing research topic in the last few years. However, current works only explored the use of audio signals to create representations. In this work, we study cross-lingual self-supervised visual representation learning. We use the recently-proposed Raw Audio-Visual Speech Encoders (RAVEn) framework to pre-train an audio-visual model with unlabelled multilingual data, and then fine-tune the visual model on labelled transcriptions. Our experiments show that: (1) multi-lingual models with more data outperform monolingual ones, but, when keeping the amount of data fixed, monolingual models tend to reach better performance; (2) multi-lingual outperforms English-only pre-training; (3) using languages which are more similar yields better results; and (4) fine-tuning on unseen languages is competitive to using the target language in the pre-training set. We hope our study inspires future research on non-English-only speech representation learning.
Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
Jan 06, 2023



Talking face generation has historically struggled to produce head movements and natural facial expressions without guidance from additional reference videos. Recent developments in diffusion-based generative models allow for more realistic and stable data synthesis and their performance on image and video generation has surpassed that of other generative models. In this work, we present an autoregressive diffusion model that requires only one identity image and audio sequence to generate a video of a realistic talking human head. Our solution is capable of hallucinating head movements, facial expressions, such as blinks, and preserving a given background. We evaluate our model on two different datasets, achieving state-of-the-art results on both of them.
Jointly Learning Visual and Auditory Speech Representations from Raw Data
Dec 12, 2022We present RAVEn, a self-supervised multi-modal approach to jointly learn visual and auditory speech representations. Our pre-training objective involves encoding masked inputs, and then predicting contextualised targets generated by slowly-evolving momentum encoders. Driven by the inherent differences between video and audio, our design is asymmetric w.r.t. the two modalities' pretext tasks: Whereas the auditory stream predicts both the visual and auditory targets, the visual one predicts only the auditory targets. We observe strong results in low- and high-resource labelled data settings when fine-tuning the visual and auditory encoders resulting from a single pre-training stage, in which the encoders are jointly trained. Notably, RAVEn surpasses all self-supervised methods on visual speech recognition (VSR) on LRS3, and combining RAVEn with self-training using only 30 hours of labelled data even outperforms a recent semi-supervised method trained on 90,000 hours of non-public data. At the same time, we achieve state-of-the-art results in the LRS3 low-resource setting for auditory speech recognition (as well as for VSR). Our findings point to the viability of learning powerful speech representations entirely from raw video and audio, i.e., without relying on handcrafted features. Code and models will be made public.
LA-VocE: Low-SNR Audio-visual Speech Enhancement using Neural Vocoders
Nov 20, 2022Audio-visual speech enhancement aims to extract clean speech from a noisy environment by leveraging not only the audio itself but also the target speaker's lip movements. This approach has been shown to yield improvements over audio-only speech enhancement, particularly for the removal of interfering speech. Despite recent advances in speech synthesis, most audio-visual approaches continue to use spectral mapping/masking to reproduce the clean audio, often resulting in visual backbones added to existing speech enhancement architectures. In this work, we propose LA-VocE, a new two-stage approach that predicts mel-spectrograms from noisy audio-visual speech via a transformer-based architecture, and then converts them into waveform audio using a neural vocoder (HiFi-GAN). We train and evaluate our framework on thousands of speakers and 11+ different languages, and study our model's ability to adapt to different levels of background noise and speech interference. Our experiments show that LA-VocE outperforms existing methods according to multiple metrics, particularly under very noisy scenarios.
FAN-Trans: Online Knowledge Distillation for Facial Action Unit Detection
Nov 11, 2022Due to its importance in facial behaviour analysis, facial action unit (AU) detection has attracted increasing attention from the research community. Leveraging the online knowledge distillation framework, we propose the ``FANTrans" method for AU detection. Our model consists of a hybrid network of convolution and transformer blocks to learn per-AU features and to model AU co-occurrences. The model uses a pre-trained face alignment network as the feature extractor. After further transformation by a small learnable add-on convolutional subnet, the per-AU features are fed into transformer blocks to enhance their representation. As multiple AUs often appear together, we propose a learnable attention drop mechanism in the transformer block to learn the correlation between the features for different AUs. We also design a classifier that predicts AU presence by considering all AUs' features, to explicitly capture label dependencies. Finally, we make the attempt of adapting online knowledge distillation in the training stage for this task, further improving the model's performance. Experiments on the BP4D and DISFA datasets demonstrating the effectiveness of proposed method.
* 9 pages, 6 figures
Streaming Audio-Visual Speech Recognition with Alignment Regularization
Nov 03, 2022Recognizing a word shortly after it is spoken is an important requirement for automatic speech recognition (ASR) systems in real-world scenarios. As a result, a large body of work on streaming audio-only ASR models has been presented in the literature. However, streaming audio-visual automatic speech recognition (AV-ASR) has received little attention in earlier works. In this work, we propose a streaming AV-ASR system based on a hybrid connectionist temporal classification (CTC)/attention neural network architecture. The audio and the visual encoder neural networks are both based on the conformer architecture, which is made streamable using chunk-wise self-attention (CSA) and causal convolution. Streaming recognition with a decoder neural network is realized by using the triggered attention technique, which performs time-synchronous decoding with joint CTC/attention scoring. For frame-level ASR criteria, such as CTC, a synchronized response from the audio and visual encoders is critical for a joint AV decision making process. In this work, we propose a novel alignment regularization technique that promotes synchronization of the audio and visual encoder, which in turn results in better word error rates (WERs) at all SNR levels for streaming and offline AV-ASR models. The proposed AV-ASR model achieves WERs of 2.0% and 2.6% on the Lip Reading Sentences 3 (LRS3) dataset in an offline and online setup, respectively, which both present state-of-the-art results when no external training data are used.
SS-VAERR: Self-Supervised Apparent Emotional Reaction Recognition from Video
Oct 20, 2022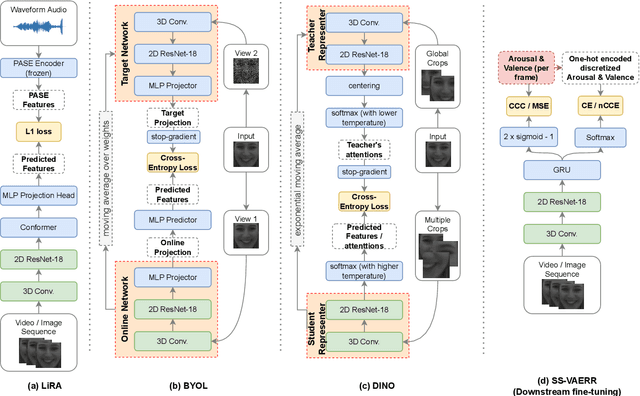

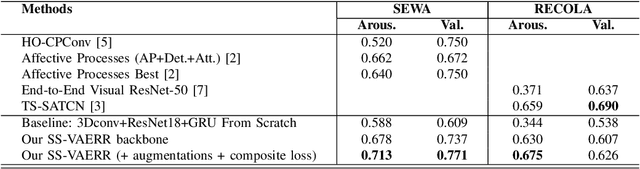
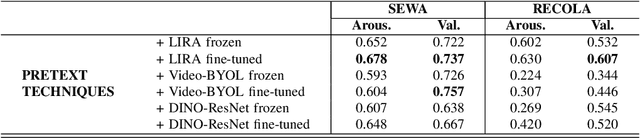
This work focuses on the apparent emotional reaction recognition (AERR) from the video-only input, conducted in a self-supervised fashion. The network is first pre-trained on different self-supervised pretext tasks and later fine-tuned on the downstream target task. Self-supervised learning facilitates the use of pre-trained architectures and larger datasets that might be deemed unfit for the target task and yet might be useful to learn informative representations and hence provide useful initializations for further fine-tuning on smaller more suitable data. Our presented contribution is two-fold: (1) an analysis of different state-of-the-art (SOTA) pretext tasks for the video-only apparent emotional reaction recognition architecture, and (2) an analysis of various combinations of the regression and classification losses that are likely to improve the performance further. Together these two contributions result in the current state-of-the-art performance for the video-only spontaneous apparent emotional reaction recognition with continuous annotations.
Training Strategies for Improved Lip-reading
Sep 03, 2022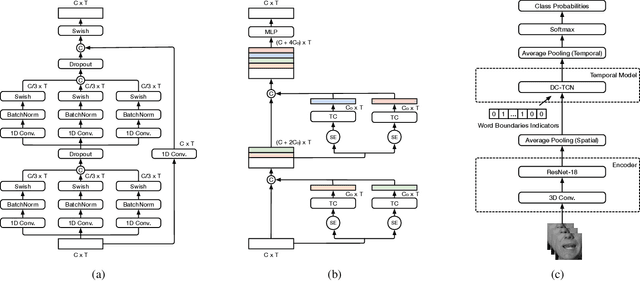
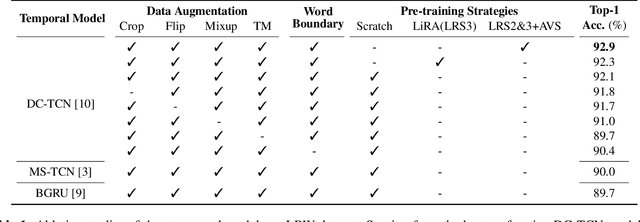
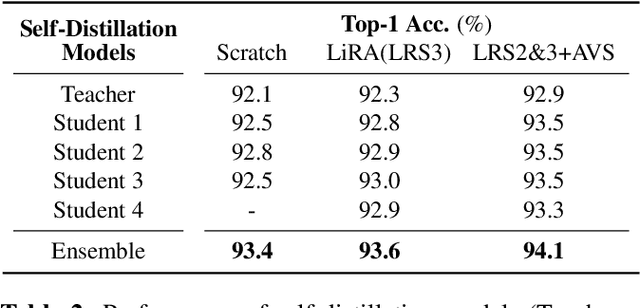
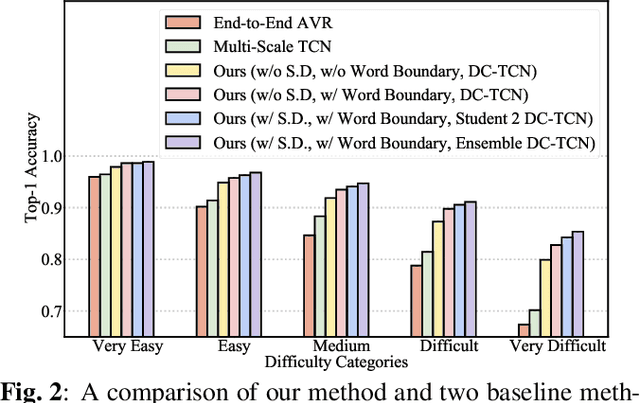
Several training strategies and temporal models have been recently proposed for isolated word lip-reading in a series of independent works. However, the potential of combining the best strategies and investigating the impact of each of them has not been explored. In this paper, we systematically investigate the performance of state-of-the-art data augmentation approaches, temporal models and other training strategies, like self-distillation and using word boundary indicators. Our results show that Time Masking (TM) is the most important augmentation followed by mixup and Densely-Connected Temporal Convolutional Networks (DC-TCN) are the best temporal model for lip-reading of isolated words. Using self-distillation and word boundary indicators is also beneficial but to a lesser extent. A combination of all the above methods results in a classification accuracy of 93.4%, which is an absolute improvement of 4.6% over the current state-of-the-art performance on the LRW dataset. The performance can be further improved to 94.1% by pre-training on additional datasets. An error analysis of the various training strategies reveals that the performance improves by increasing the classification accuracy of hard-to-recognise words.
SVTS: Scalable Video-to-Speech Synthesis
May 04, 2022
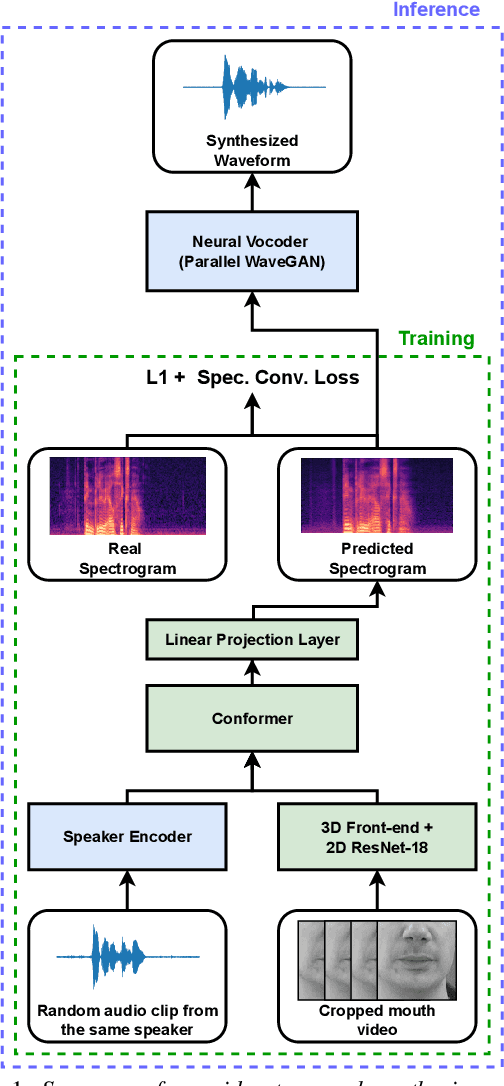
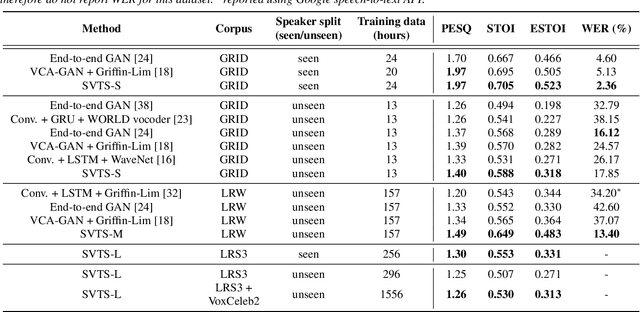
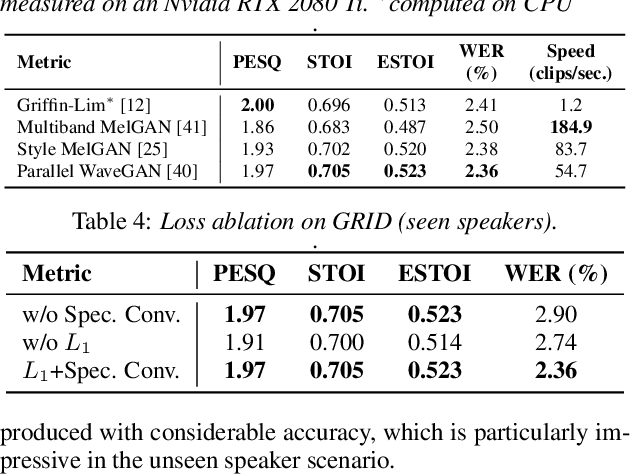
Video-to-speech synthesis (also known as lip-to-speech) refers to the translation of silent lip movements into the corresponding audio. This task has received an increasing amount of attention due to its self-supervised nature (i.e., can be trained without manual labelling) combined with the ever-growing collection of audio-visual data available online. Despite these strong motivations, contemporary video-to-speech works focus mainly on small- to medium-sized corpora with substantial constraints in both vocabulary and setting. In this work, we introduce a scalable video-to-speech framework consisting of two components: a video-to-spectrogram predictor and a pre-trained neural vocoder, which converts the mel-frequency spectrograms into waveform audio. We achieve state-of-the art results for GRID and considerably outperform previous approaches on LRW. More importantly, by focusing on spectrogram prediction using a simple feedforward model, we can efficiently and effectively scale our method to very large and unconstrained datasets: To the best of our knowledge, we are the first to show intelligible results on the challenging LRS3 dataset.