 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Grounded Language Understanding in a Collaborative Environment: IGLU 2021
May 05, 2022
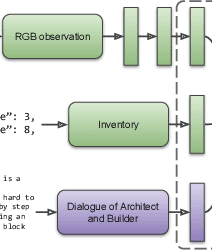
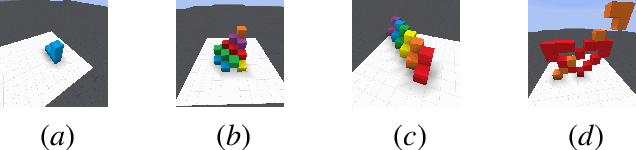
Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose \emph{IGLU: Interactive Grounded Language Understanding in a Collaborative Environment}. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
* arXiv admin note: substantial text overlap with arXiv:2110.06536
Summarization with Graphical Elements
Apr 25, 2022

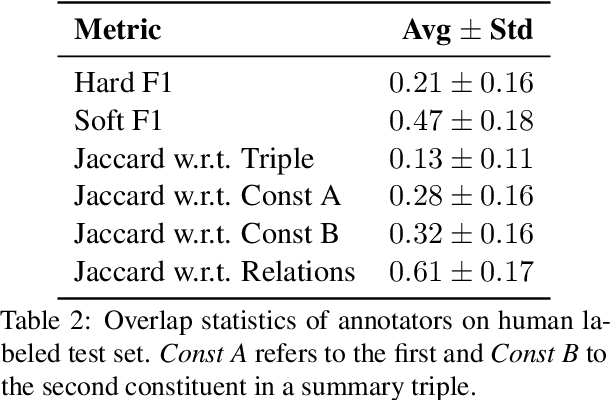

Automatic text summarization has experienced substantial progress in recent years. With this progress, the question has arisen whether the types of summaries that are typically generated by automatic summarization models align with users' needs. Ter Hoeve et al (2020) answer this question negatively. Amongst others, they recommend focusing on generating summaries with more graphical elements. This is in line with what we know from the psycholinguistics literature about how humans process text. Motivated from these two angles, we propose a new task: summarization with graphical elements, and we verify that these summaries are helpful for a critical mass of people. We collect a high quality human labeled dataset to support research into the task. We present a number of baseline methods that show that the task is interesting and challenging. Hence, with this work we hope to inspire a new line of research within the automatic summarization community.
Towards Interactive Language Modeling
Dec 14, 2021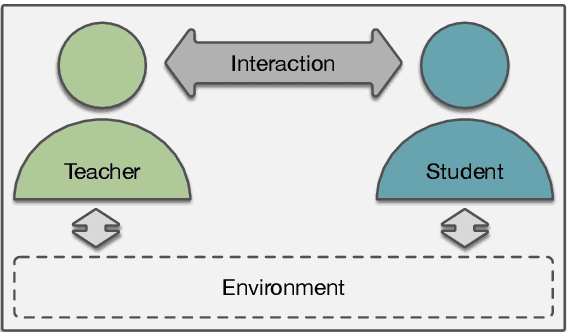
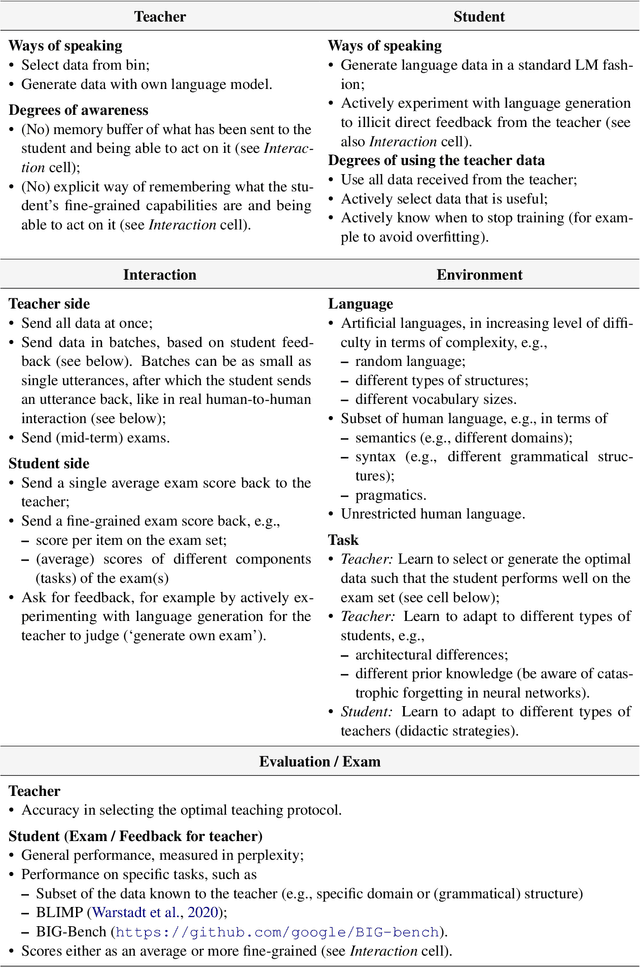
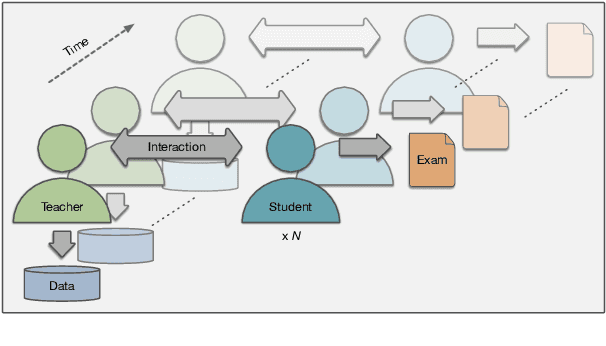
Interaction between caregivers and children plays a critical role in human language acquisition and development. Given this observation, it is remarkable that explicit interaction plays little to no role in artificial language modeling -- which also targets the acquisition of human language, yet by artificial models. Moreover, an interactive approach to language modeling has the potential to make language models substantially more versatile and to considerably impact downstream applications. Motivated by these considerations, we pioneer the space of interactive language modeling. As a first contribution we present a road map in which we detail the steps that need to be taken towards interactive language modeling. We then lead by example and take the first steps on this road map, showing the initial feasibility of our approach. As such, this work aims to be the start of a larger research agenda on interactive language modeling.
NeurIPS 2021 Competition IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Oct 15, 2021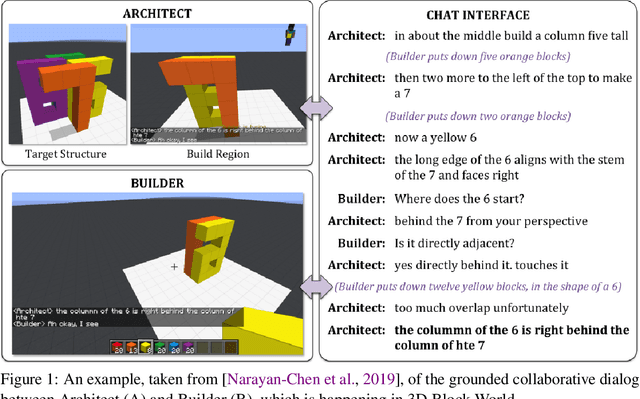

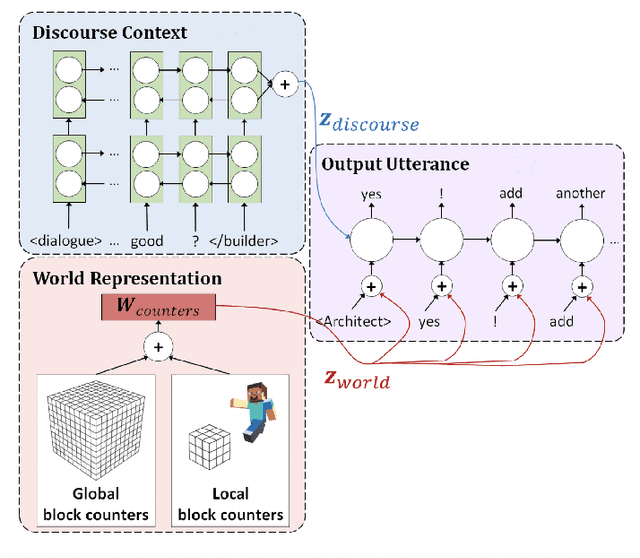
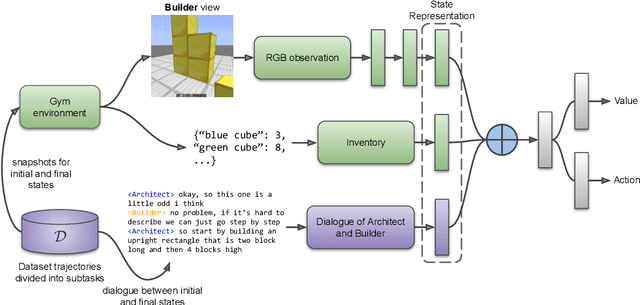
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the important challenges in AI. Another important aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
CF-GNNExplainer: Counterfactual Explanations for Graph Neural Networks
Feb 05, 2021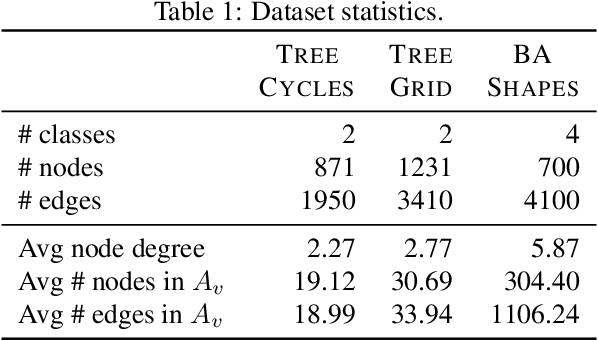
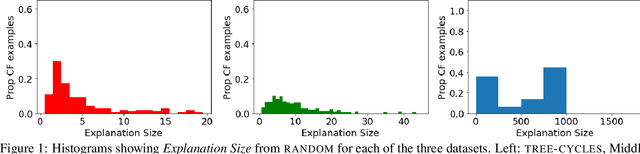
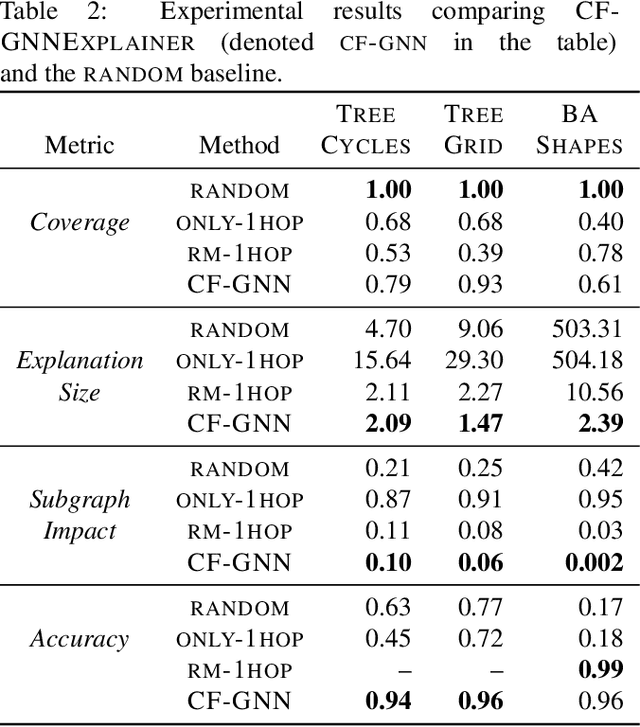
Graph neural networks (GNNs) have shown increasing promise in real-world applications, which has caused an increased interest in understanding their predictions. However, existing methods for explaining predictions from GNNs do not provide an opportunity for recourse: given a prediction for a particular instance, we want to understand how the prediction can be changed. We propose CF-GNNExplainer: the first method for generating counterfactual explanations for GNNs, i.e., the minimal perturbations to the input graph data such that the prediction changes. Using only edge deletions, we find that we are able to generate counterfactual examples for the majority of instances across three widely used datasets for GNN explanations, while removing less than 3 edges on average, with at least 94% accuracy. This indicates that CF-GNNExplainer primarily removes edges that are crucial for the original predictions, resulting in minimal counterfactual examples.
What Makes a Good Summary? Reconsidering the Focus of Automatic Summarization
Dec 14, 2020



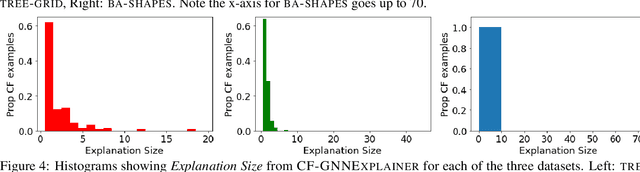
Automatic text summarization has enjoyed great progress over the last years. Now is the time to re-assess its focus and objectives. Does the current focus fully adhere to users' desires or should we expand or change our focus? We investigate this question empirically by conducting a survey amongst heavy users of pre-made summaries. We find that the current focus of the field does not fully align with participants' wishes. In response, we identify three groups of implications. First, we argue that it is important to adopt a broader perspective on automatic summarization. Based on our findings, we illustrate how we can expand our view when it comes to the types of input material that is to be summarized, the purpose of the summaries and their potential formats. Second, we define requirements for datasets that can facilitate these research directions. Third, usefulness is an important aspect of summarization that should be included in our evaluation methodology; we propose a methodology to evaluate the usefulness of a summary. With this work we unlock important research directions for future work on automatic summarization and we hope to initiate the development of methods in these directions.
Conditional Image Generation and Manipulation for User-Specified Content
May 11, 2020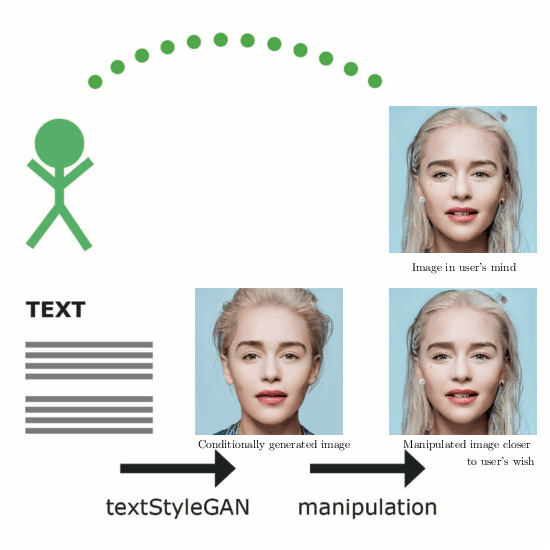
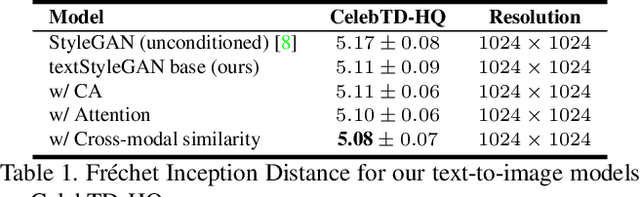
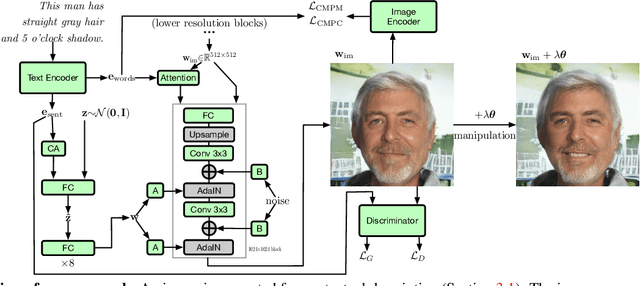
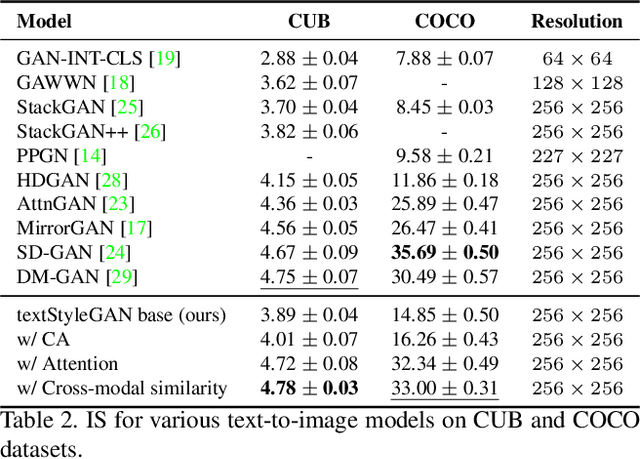
In recent years, Generative Adversarial Networks (GANs) have improved steadily towards generating increasingly impressive real-world images. It is useful to steer the image generation process for purposes such as content creation. This can be done by conditioning the model on additional information. However, when conditioning on additional information, there still exists a large set of images that agree with a particular conditioning. This makes it unlikely that the generated image is exactly as envisioned by a user, which is problematic for practical content creation scenarios such as generating facial composites or stock photos. To solve this problem, we propose a single pipeline for text-to-image generation and manipulation. In the first part of our pipeline we introduce textStyleGAN, a model that is conditioned on text. In the second part of our pipeline we make use of the pre-trained weights of textStyleGAN to perform semantic facial image manipulation. The approach works by finding semantic directions in latent space. We show that this method can be used to manipulate facial images for a wide range of attributes. Finally, we introduce the CelebTD-HQ dataset, an extension to CelebA-HQ, consisting of faces and corresponding textual descriptions.
Conversations with Documents. An Exploration of Document-Centered Assistance
Jan 27, 2020


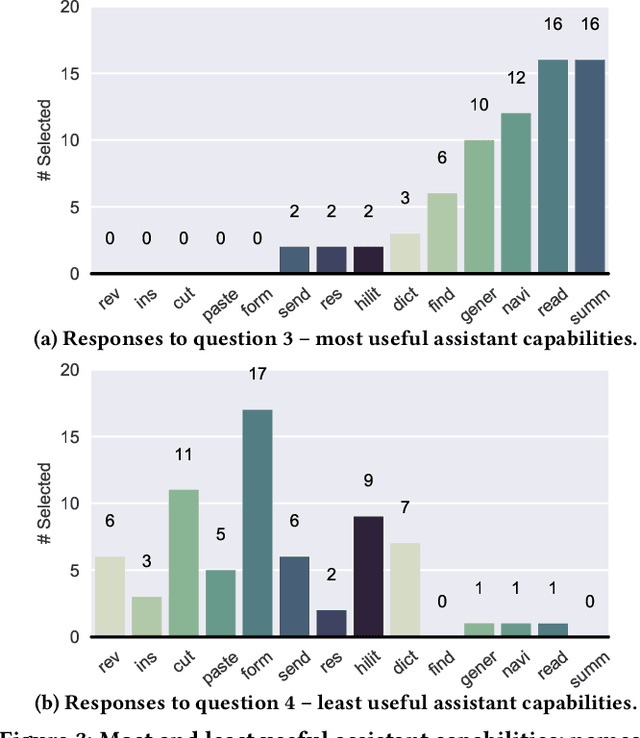
The role of conversational assistants has become more prevalent in helping people increase their productivity. Document-centered assistance, for example to help an individual quickly review a document, has seen less significant progress, even though it has the potential to tremendously increase a user's productivity. This type of document-centered assistance is the focus of this paper. Our contributions are three-fold: (1) We first present a survey to understand the space of document-centered assistance and the capabilities people expect in this scenario. (2) We investigate the types of queries that users will pose while seeking assistance with documents, and show that document-centered questions form the majority of these queries. (3) We present a set of initial machine learned models that show that (a) we can accurately detect document-centered questions, and (b) we can build reasonably accurate models for answering such questions. These positive results are encouraging, and suggest that even greater results may be attained with continued study of this interesting and novel problem space. Our findings have implications for the design of intelligent systems to support task completion via natural interactions with documents.
Understanding Multi-Head Attention in Abstractive Summarization
Nov 10, 2019

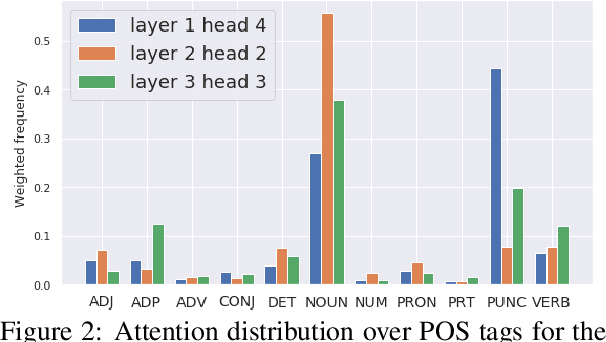
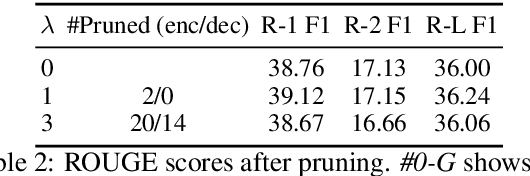
Attention mechanisms in deep learning architectures have often been used as a means of transparency and, as such, to shed light on the inner workings of the architectures. Recently, there has been a growing interest in whether or not this assumption is correct. In this paper we investigate the interpretability of multi-head attention in abstractive summarization, a sequence-to-sequence task for which attention does not have an intuitive alignment role, such as in machine translation. We first introduce three metrics to gain insight in the focus of attention heads and observe that these heads specialize towards relative positions, specific part-of-speech tags, and named entities. However, we also find that ablating and pruning these heads does not lead to a significant drop in performance, indicating redundancy. By replacing the softmax activation functions with sparsemax activation functions, we find that attention heads behave seemingly more transparent: we can ablate fewer heads and heads score higher on our interpretability metrics. However, if we apply pruning to the sparsemax model we find that we can prune even more heads, raising the question whether enforced sparsity actually improves transparency. Finally, we find that relative positions heads seem integral to summarization performance and persistently remain after pruning.
Do Transformer Attention Heads Provide Transparency in Abstractive Summarization?
Jul 08, 2019
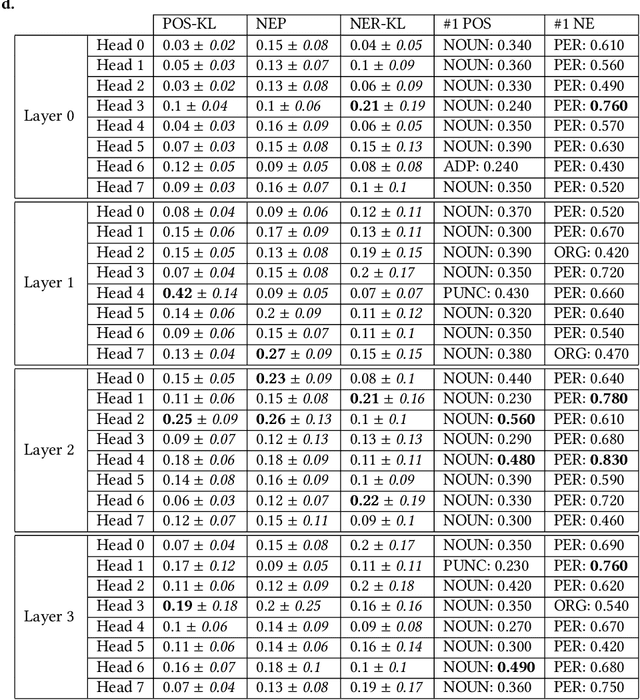

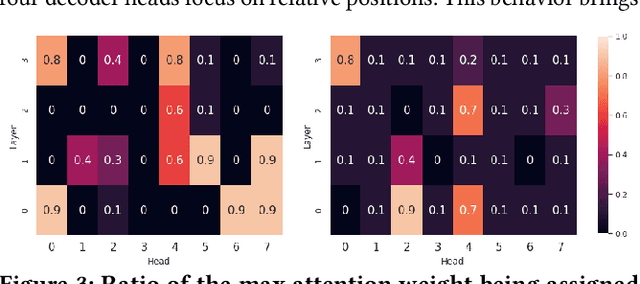
Learning algorithms become more powerful, often at the cost of increased complexity. In response, the demand for algorithms to be transparent is growing. In NLP tasks, attention distributions learned by attention-based deep learning models are used to gain insights in the models' behavior. To which extent is this perspective valid for all NLP tasks? We investigate whether distributions calculated by different attention heads in a transformer architecture can be used to improve transparency in the task of abstractive summarization. To this end, we present both a qualitative and quantitative analysis to investigate the behavior of the attention heads. We show that some attention heads indeed specialize towards syntactically and semantically distinct input. We propose an approach to evaluate to which extent the Transformer model relies on specifically learned attention distributions. We also discuss what this implies for using attention distributions as a means of transparency.