 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Language Models for Linguistic Structure
Nov 15, 2022



Although pretrained language models (PLMs) can be prompted to perform a wide range of language tasks, it remains an open question how much this ability comes from generalizable linguistic representations versus more surface-level lexical patterns. To test this, we present a structured prompting approach that can be used to prompt for linguistic structure prediction tasks, allowing us to perform zero- and few-shot sequence tagging with autoregressive PLMs. We evaluate this approach on part-of-speech tagging, named entity recognition, and sentence chunking and demonstrate strong few-shot performance in all cases. We also find that, though the surface forms of the tags provide some signal, structured prompting can retrieve linguistic structure even with arbitrary labels, indicating that PLMs contain this knowledge in a general manner robust to label choice.
Contrastive Decoding: Open-ended Text Generation as Optimization
Oct 27, 2022Likelihood, although useful as a training loss, is a poor search objective for guiding open-ended generation from language models (LMs). Existing generation algorithms must avoid both unlikely strings, which are incoherent, and highly likely ones, which are short and repetitive. We propose contrastive decoding (CD), a more reliable search objective that returns the difference between likelihood under a large LM (called the expert, e.g. OPT-13b) and a small LM (called the amateur, e.g. OPT-125m). CD is inspired by the fact that the failures of larger LMs are even more prevalent in smaller LMs, and that this difference signals exactly which texts should be preferred. CD requires zero training, and produces higher quality text than decoding from the larger LM alone. It also generalizes across model types (OPT and GPT2) and significantly outperforms four strong decoding algorithms in automatic and human evaluations.
RoMQA: A Benchmark for Robust, Multi-evidence, Multi-answer Question Answering
Oct 25, 2022We introduce RoMQA, the first benchmark for robust, multi-evidence, multi-answer question answering (QA). RoMQA contains clusters of questions that are derived from related constraints mined from the Wikidata knowledge graph. RoMQA evaluates robustness of QA models to varying constraints by measuring worst-case performance within each question cluster. Compared to prior QA datasets, RoMQA has more human-written questions that require reasoning over more evidence text and have, on average, many more correct answers. In addition, human annotators rate RoMQA questions as more natural or likely to be asked by people. We evaluate state-of-the-art large language models in zero-shot, few-shot, and fine-tuning settings, and find that RoMQA is challenging: zero-shot and few-shot models perform similarly to naive baselines, while supervised retrieval methods perform well below gold evidence upper bounds. Moreover, existing models are not robust to variations in question constraints, but can be made more robust by tuning on clusters of related questions. Our results show that RoMQA is a challenging benchmark for large language models, and provides a quantifiable test to build more robust QA methods.
M2D2: A Massively Multi-domain Language Modeling Dataset
Oct 13, 2022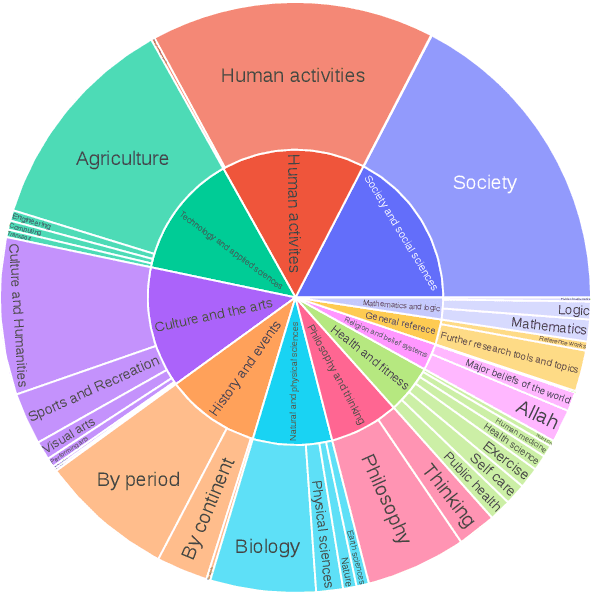
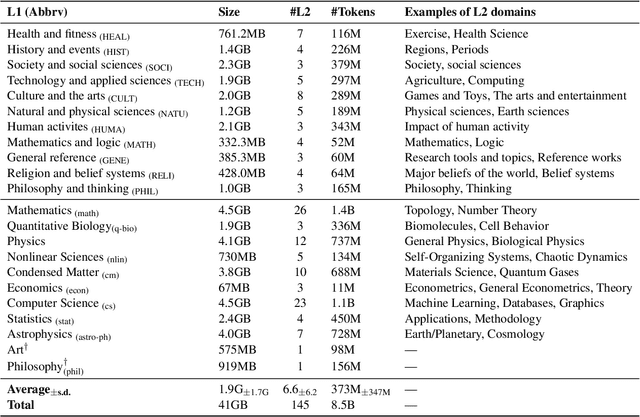
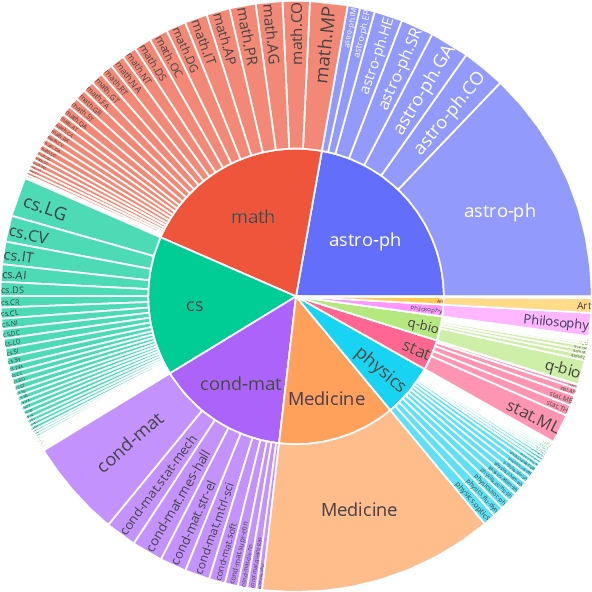
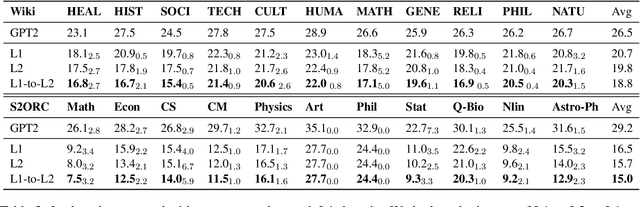
We present M2D2, a fine-grained, massively multi-domain corpus for studying domain adaptation in language models (LMs). M2D2 consists of 8.5B tokens and spans 145 domains extracted from Wikipedia and Semantic Scholar. Using ontologies derived from Wikipedia and ArXiv categories, we organize the domains in each data source into 22 groups. This two-level hierarchy enables the study of relationships between domains and their effects on in- and out-of-domain performance after adaptation. We also present a number of insights into the nature of effective domain adaptation in LMs, as examples of the new types of studies M2D2 enables. To improve in-domain performance, we show the benefits of adapting the LM along a domain hierarchy; adapting to smaller amounts of fine-grained domain-specific data can lead to larger in-domain performance gains than larger amounts of weakly relevant data. We further demonstrate a trade-off between in-domain specialization and out-of-domain generalization within and across ontologies, as well as a strong correlation between out-of-domain performance and lexical overlap between domains.
CORE: A Retrieve-then-Edit Framework for Counterfactual Data Generation
Oct 10, 2022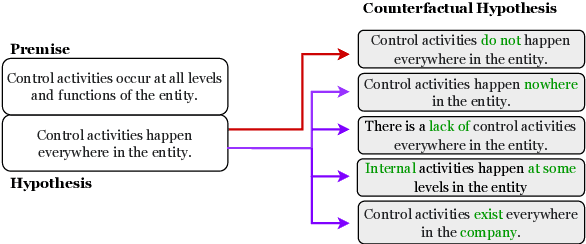

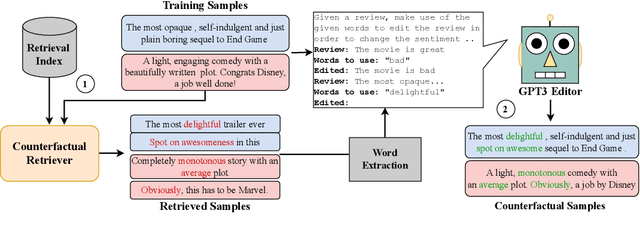
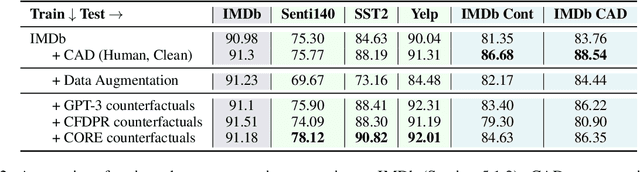
Counterfactual data augmentation (CDA) -- i.e., adding minimally perturbed inputs during training -- helps reduce model reliance on spurious correlations and improves generalization to out-of-distribution (OOD) data. Prior work on generating counterfactuals only considered restricted classes of perturbations, limiting their effectiveness. We present COunterfactual Generation via Retrieval and Editing (CORE), a retrieval-augmented generation framework for creating diverse counterfactual perturbations for CDA. For each training example, CORE first performs a dense retrieval over a task-related unlabeled text corpus using a learned bi-encoder and extracts relevant counterfactual excerpts. CORE then incorporates these into prompts to a large language model with few-shot learning capabilities, for counterfactual editing. Conditioning language model edits on naturally occurring data results in diverse perturbations. Experiments on natural language inference and sentiment analysis benchmarks show that CORE counterfactuals are more effective at improving generalization to OOD data compared to other DA approaches. We also show that the CORE retrieval framework can be used to encourage diversity in manually authored perturbations
Binding Language Models in Symbolic Languages
Oct 06, 2022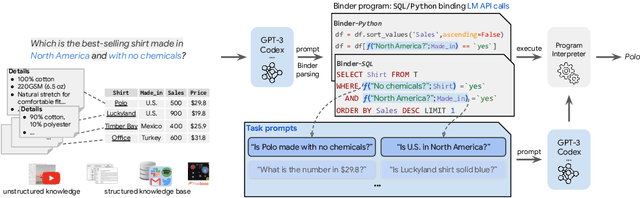
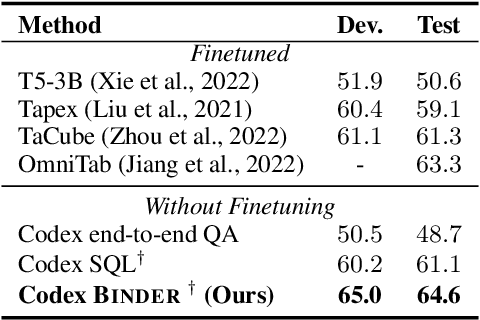

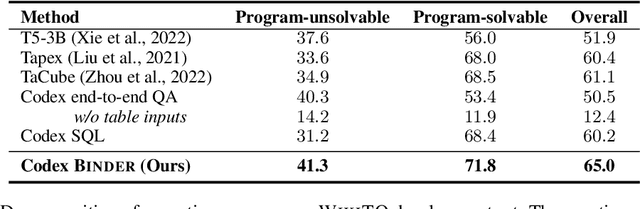
Though end-to-end neural approaches have recently been dominating NLP tasks in both performance and ease-of-use, they lack interpretability and robustness. We propose Binder, a training-free neural-symbolic framework that maps the task input to a program, which (1) allows binding a unified API of language model (LM) functionalities to a programming language (e.g., SQL, Python) to extend its grammar coverage and thus tackle more diverse questions, (2) adopts an LM as both the program parser and the underlying model called by the API during execution, and (3) requires only a few in-context exemplar annotations. Specifically, we employ GPT-3 Codex as the LM. In the parsing stage, with only a few in-context exemplars, Codex is able to identify the part of the task input that cannot be answerable by the original programming language, correctly generate API calls to prompt Codex to solve the unanswerable part, and identify where to place the API calls while being compatible with the original grammar. In the execution stage, Codex can perform versatile functionalities (e.g., commonsense QA, information extraction) given proper prompts in the API calls. Binder achieves state-of-the-art results on WikiTableQuestions and TabFact datasets, with explicit output programs that benefit human debugging. Note that previous best systems are all finetuned on tens of thousands of task-specific samples, while Binder only uses dozens of annotations as in-context exemplars without any training. Our code is available at https://github.com/HKUNLP/Binder .
Improving Policy Learning via Language Dynamics Distillation
Sep 30, 2022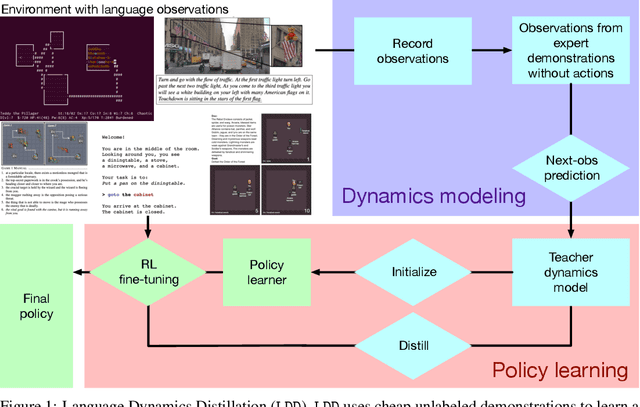
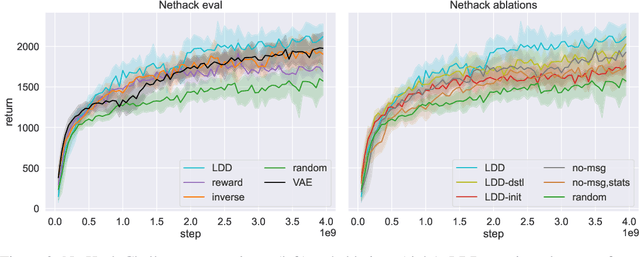
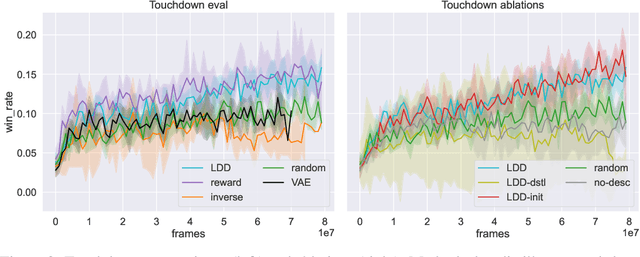
Recent work has shown that augmenting environments with language descriptions improves policy learning. However, for environments with complex language abstractions, learning how to ground language to observations is difficult due to sparse, delayed rewards. We propose Language Dynamics Distillation (LDD), which pretrains a model to predict environment dynamics given demonstrations with language descriptions, and then fine-tunes these language-aware pretrained representations via reinforcement learning (RL). In this way, the model is trained to both maximize expected reward and retain knowledge about how language relates to environment dynamics. On SILG, a benchmark of five tasks with language descriptions that evaluate distinct generalization challenges on unseen environments (NetHack, ALFWorld, RTFM, Messenger, and Touchdown), LDD outperforms tabula-rasa RL, VAE pretraining, and methods that learn from unlabeled demonstrations in inverse RL and reward shaping with pretrained experts. In our analyses, we show that language descriptions in demonstrations improve sample-efficiency and generalization across environments, and that dynamics modelling with expert demonstrations is more effective than with non-experts.
Mega: Moving Average Equipped Gated Attention
Sep 26, 2022
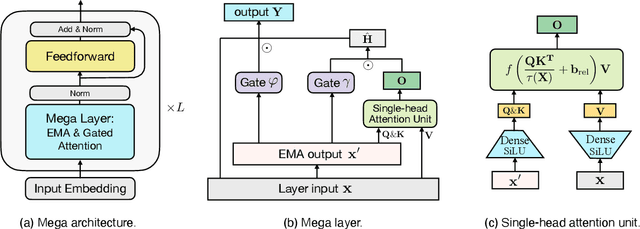
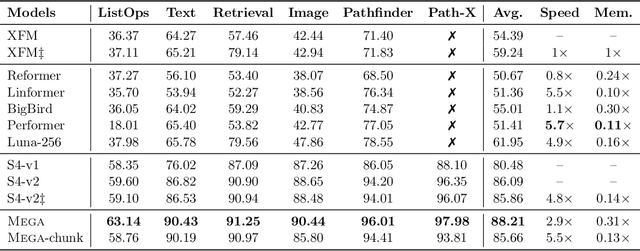
The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models.
Selective Annotation Makes Language Models Better Few-Shot Learners
Sep 05, 2022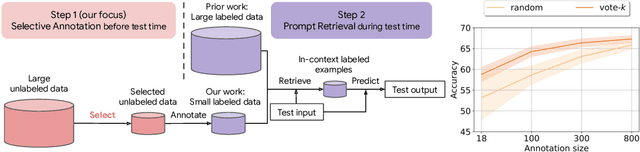
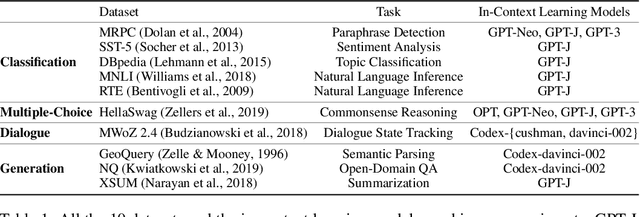
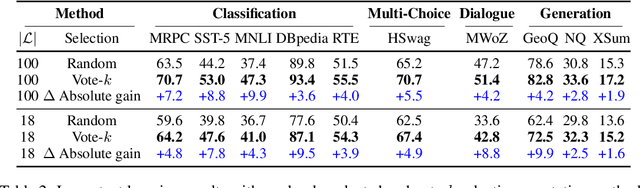
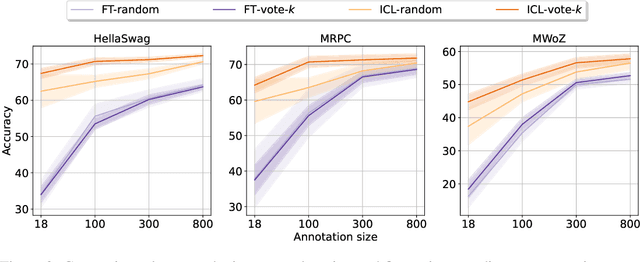
Many recent approaches to natural language tasks are built on the remarkable abilities of large language models. Large language models can perform in-context learning, where they learn a new task from a few task demonstrations, without any parameter updates. This work examines the implications of in-context learning for the creation of datasets for new natural language tasks. Departing from recent in-context learning methods, we formulate an annotation-efficient, two-step framework: selective annotation that chooses a pool of examples to annotate from unlabeled data in advance, followed by prompt retrieval that retrieves task examples from the annotated pool at test time. Based on this framework, we propose an unsupervised, graph-based selective annotation method, voke-k, to select diverse, representative examples to annotate. Extensive experiments on 10 datasets (covering classification, commonsense reasoning, dialogue, and text/code generation) demonstrate that our selective annotation method improves the task performance by a large margin. On average, vote-k achieves a 12.9%/11.4% relative gain under an annotation budget of 18/100, as compared to randomly selecting examples to annotate. Compared to state-of-the-art supervised finetuning approaches, it yields similar performance with 10-100x less annotation cost across 10 tasks. We further analyze the effectiveness of our framework in various scenarios: language models with varying sizes, alternative selective annotation methods, and cases where there is a test data domain shift. We hope that our studies will serve as a basis for data annotations as large language models are increasingly applied to new tasks. Our code is available at https://github.com/HKUNLP/icl-selective-annotation.
LLM.int8: 8-bit Matrix Multiplication for Transformers at Scale
Aug 15, 2022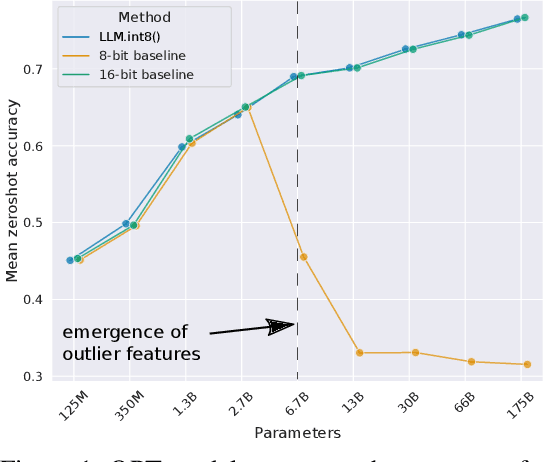
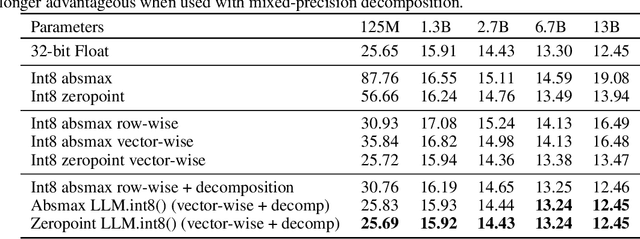
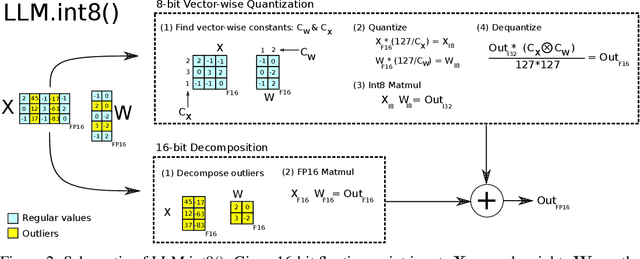

Large language models have been widely adopted but require significant GPU memory for inference. We develop a procedure for Int8 matrix multiplication for feed-forward and attention projection layers in transformers, which cut the memory needed for inference by half while retaining full precision performance. With our method, a 175B parameter 16/32-bit checkpoint can be loaded, converted to Int8, and used immediately without performance degradation. This is made possible by understanding and working around properties of highly systematic emergent features in transformer language models that dominate attention and transformer predictive performance. To cope with these features, we develop a two-part quantization procedure, LLM.int8(). We first use vector-wise quantization with separate normalization constants for each inner product in the matrix multiplication, to quantize most of the features. However, for the emergent outliers, we also include a new mixed-precision decomposition scheme, which isolates the outlier feature dimensions into a 16-bit matrix multiplication while still more than 99.9% of values are multiplied in 8-bit. Using LLM.int8(), we show empirically it is possible to perform inference in LLMs with up to 175B parameters without any performance degradation. This result makes such models much more accessible, for example making it possible to use OPT-175B/BLOOM on a single server with consumer GPUs.