 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Gradient Estimation in Unrolled Computation Graphs with Persistent Evolution Strategies
Dec 27, 2021
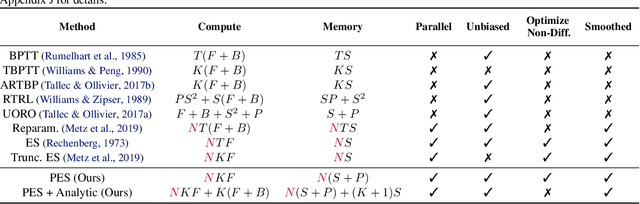
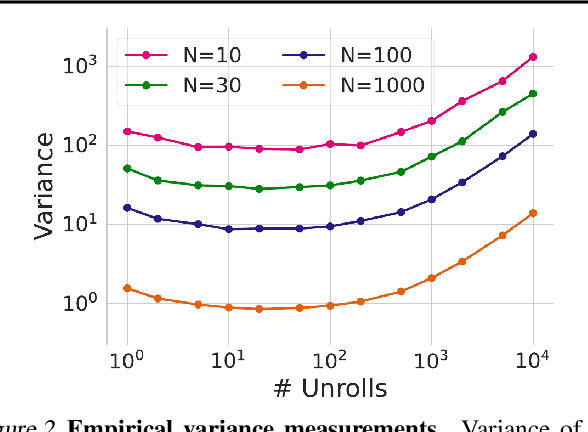

Unrolled computation graphs arise in many scenarios, including training RNNs, tuning hyperparameters through unrolled optimization, and training learned optimizers. Current approaches to optimizing parameters in such computation graphs suffer from high variance gradients, bias, slow updates, or large memory usage. We introduce a method called Persistent Evolution Strategies (PES), which divides the computation graph into a series of truncated unrolls, and performs an evolution strategies-based update step after each unroll. PES eliminates bias from these truncations by accumulating correction terms over the entire sequence of unrolls. PES allows for rapid parameter updates, has low memory usage, is unbiased, and has reasonable variance characteristics. We experimentally demonstrate the advantages of PES compared to several other methods for gradient estimation on synthetic tasks, and show its applicability to training learned optimizers and tuning hyperparameters.
Lyapunov Exponents for Diversity in Differentiable Games
Dec 24, 2021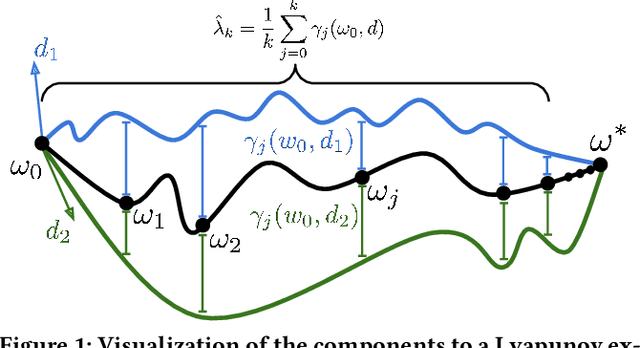

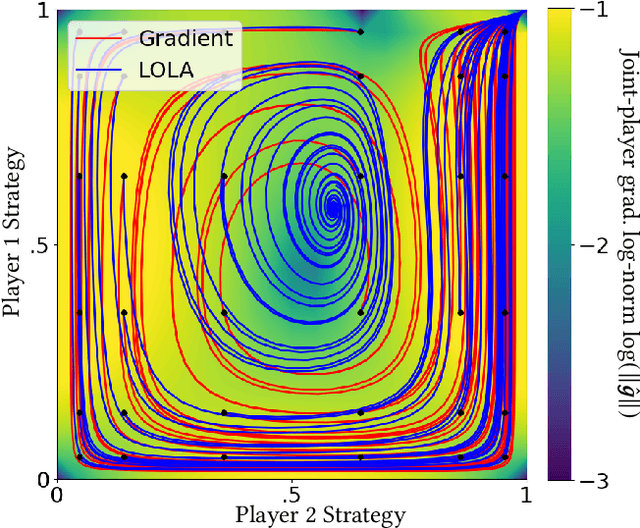
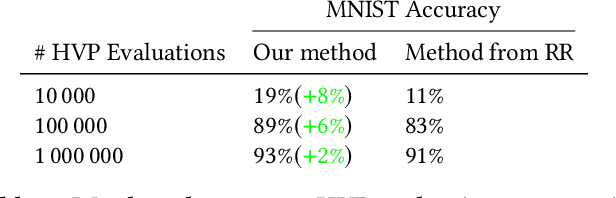
Ridge Rider (RR) is an algorithm for finding diverse solutions to optimization problems by following eigenvectors of the Hessian ("ridges"). RR is designed for conservative gradient systems (i.e., settings involving a single loss function), where it branches at saddles - easy-to-find bifurcation points. We generalize this idea to non-conservative, multi-agent gradient systems by proposing a method - denoted Generalized Ridge Rider (GRR) - for finding arbitrary bifurcation points. We give theoretical motivation for our method by leveraging machinery from the field of dynamical systems. We construct novel toy problems where we can visualize new phenomena while giving insight into high-dimensional problems of interest. Finally, we empirically evaluate our method by finding diverse solutions in the iterated prisoners' dilemma and relevant machine learning problems including generative adversarial networks.
Gradients are Not All You Need
Nov 10, 2021
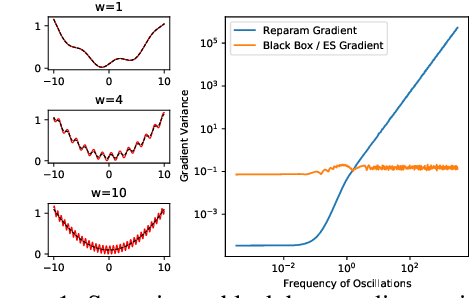
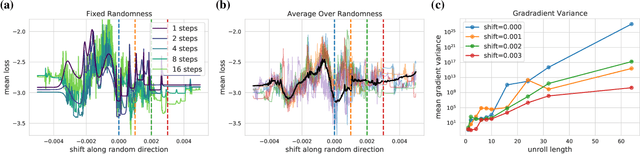
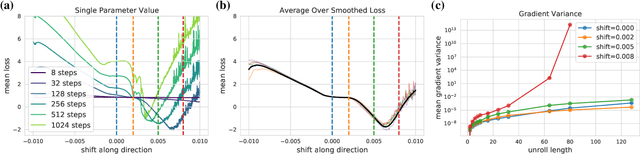
Differentiable programming techniques are widely used in the community and are responsible for the machine learning renaissance of the past several decades. While these methods are powerful, they have limits. In this short report, we discuss a common chaos based failure mode which appears in a variety of differentiable circumstances, ranging from recurrent neural networks and numerical physics simulation to training learned optimizers. We trace this failure to the spectrum of the Jacobian of the system under study, and provide criteria for when a practitioner might expect this failure to spoil their differentiation based optimization algorithms.
Learn2Hop: Learned Optimization on Rough Landscapes
Jul 20, 2021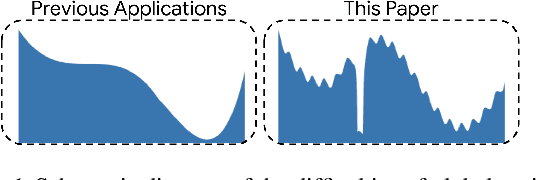

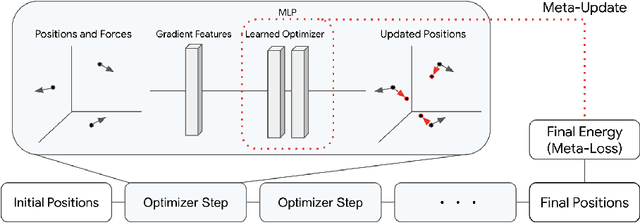
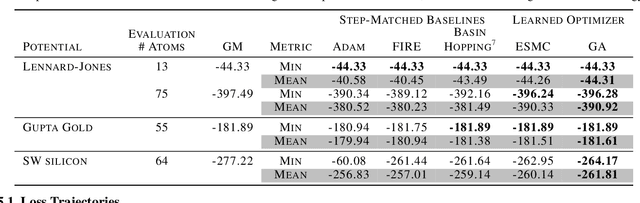
Optimization of non-convex loss surfaces containing many local minima remains a critical problem in a variety of domains, including operations research, informatics, and material design. Yet, current techniques either require extremely high iteration counts or a large number of random restarts for good performance. In this work, we propose adapting recent developments in meta-learning to these many-minima problems by learning the optimization algorithm for various loss landscapes. We focus on problems from atomic structural optimization--finding low energy configurations of many-atom systems--including widely studied models such as bimetallic clusters and disordered silicon. We find that our optimizer learns a 'hopping' behavior which enables efficient exploration and improves the rate of low energy minima discovery. Finally, our learned optimizers show promising generalization with efficiency gains on never before seen tasks (e.g. new elements or compositions). Code will be made available shortly.
Training Learned Optimizers with Randomly Initialized Learned Optimizers
Jan 14, 2021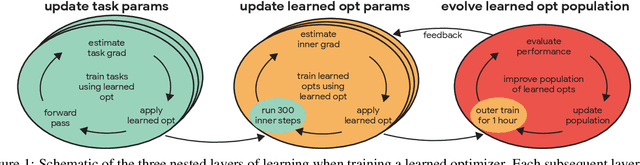
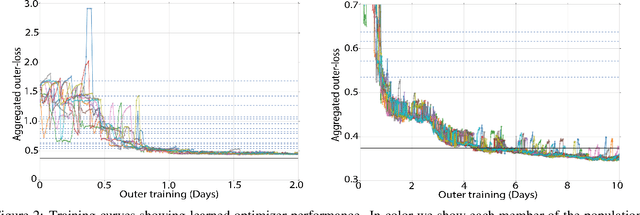
Learned optimizers are increasingly effective, with performance exceeding that of hand designed optimizers such as Adam~\citep{kingma2014adam} on specific tasks \citep{metz2019understanding}. Despite the potential gains available, in current work the meta-training (or `outer-training') of the learned optimizer is performed by a hand-designed optimizer, or by an optimizer trained by a hand-designed optimizer \citep{metz2020tasks}. We show that a population of randomly initialized learned optimizers can be used to train themselves from scratch in an online fashion, without resorting to a hand designed optimizer in any part of the process. A form of population based training is used to orchestrate this self-training. Although the randomly initialized optimizers initially make slow progress, as they improve they experience a positive feedback loop, and become rapidly more effective at training themselves. We believe feedback loops of this type, where an optimizer improves itself, will be important and powerful in the future of machine learning. These methods not only provide a path towards increased performance, but more importantly relieve research and engineering effort.
Parallel Training of Deep Networks with Local Updates
Dec 07, 2020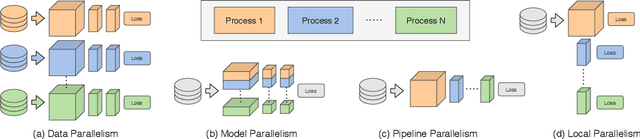
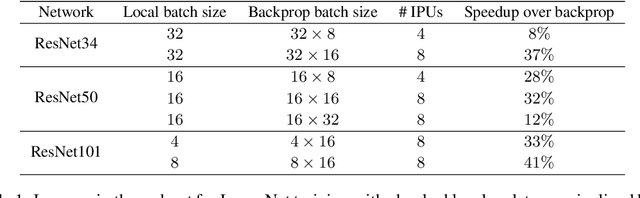
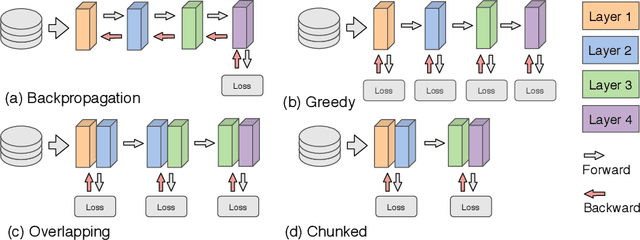
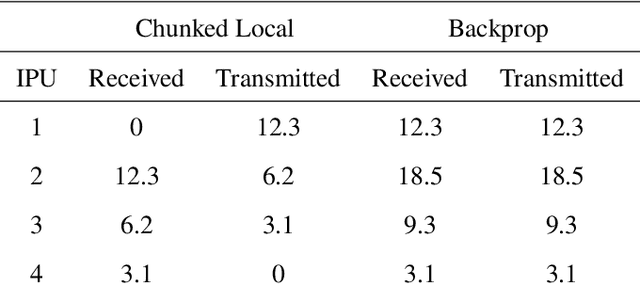
Deep learning models trained on large data sets have been widely successful in both vision and language domains. As state-of-the-art deep learning architectures have continued to grow in parameter count so have the compute budgets and times required to train them, increasing the need for compute-efficient methods that parallelize training. Two common approaches to parallelize the training of deep networks have been data and model parallelism. While useful, data and model parallelism suffer from diminishing returns in terms of compute efficiency for large batch sizes. In this paper, we investigate how to continue scaling compute efficiently beyond the point of diminishing returns for large batches through local parallelism, a framework which parallelizes training of individual layers in deep networks by replacing global backpropagation with truncated layer-wise backpropagation. Local parallelism enables fully asynchronous layer-wise parallelism with a low memory footprint, and requires little communication overhead compared with model parallelism. We show results in both vision and language domains across a diverse set of architectures, and find that local parallelism is particularly effective in the high-compute regime.
Ridge Rider: Finding Diverse Solutions by Following Eigenvectors of the Hessian
Nov 12, 2020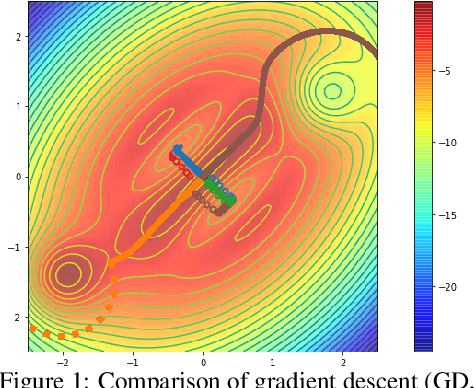
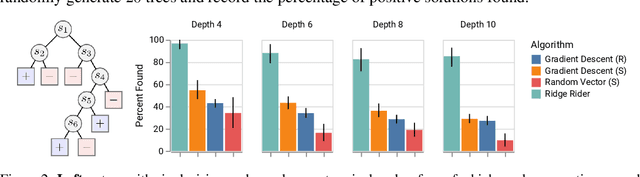
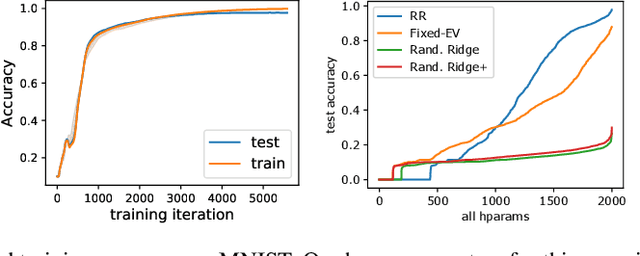
Over the last decade, a single algorithm has changed many facets of our lives - Stochastic Gradient Descent (SGD). In the era of ever decreasing loss functions, SGD and its various offspring have become the go-to optimization tool in machine learning and are a key component of the success of deep neural networks (DNNs). While SGD is guaranteed to converge to a local optimum (under loose assumptions), in some cases it may matter which local optimum is found, and this is often context-dependent. Examples frequently arise in machine learning, from shape-versus-texture-features to ensemble methods and zero-shot coordination. In these settings, there are desired solutions which SGD on 'standard' loss functions will not find, since it instead converges to the 'easy' solutions. In this paper, we present a different approach. Rather than following the gradient, which corresponds to a locally greedy direction, we instead follow the eigenvectors of the Hessian, which we call "ridges". By iteratively following and branching amongst the ridges, we effectively span the loss surface to find qualitatively different solutions. We show both theoretically and experimentally that our method, called Ridge Rider (RR), offers a promising direction for a variety of challenging problems.
Reverse engineering learned optimizers reveals known and novel mechanisms
Nov 04, 2020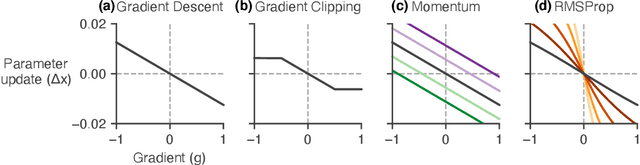
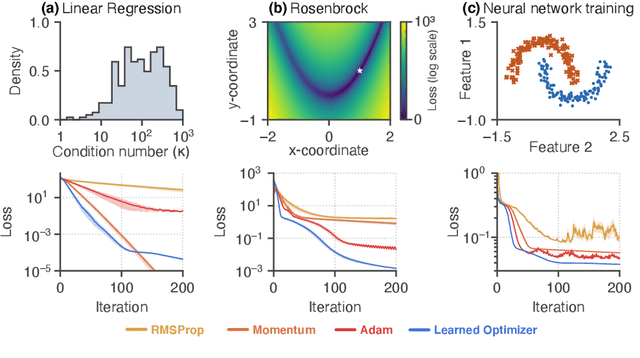
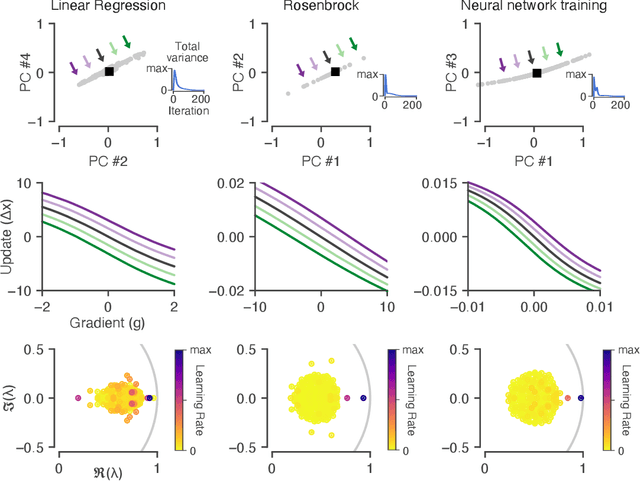
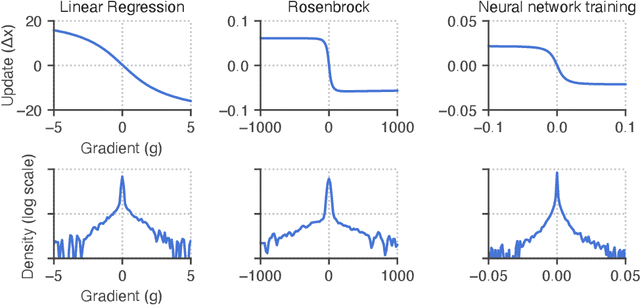
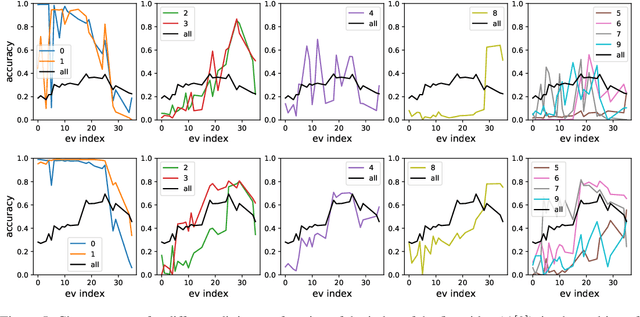
Learned optimizers are algorithms that can themselves be trained to solve optimization problems. In contrast to baseline optimizers (such as momentum or Adam) that use simple update rules derived from theoretical principles, learned optimizers use flexible, high-dimensional, nonlinear parameterizations. Although this can lead to better performance in certain settings, their inner workings remain a mystery. How is a learned optimizer able to outperform a well tuned baseline? Has it learned a sophisticated combination of existing optimization techniques, or is it implementing completely new behavior? In this work, we address these questions by careful analysis and visualization of learned optimizers. We study learned optimizers trained from scratch on three disparate tasks, and discover that they have learned interpretable mechanisms, including: momentum, gradient clipping, learning rate schedules, and a new form of learning rate adaptation. Moreover, we show how the dynamics of learned optimizers enables these behaviors. Our results help elucidate the previously murky understanding of how learned optimizers work, and establish tools for interpreting future learned optimizers.
Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves
Sep 23, 2020
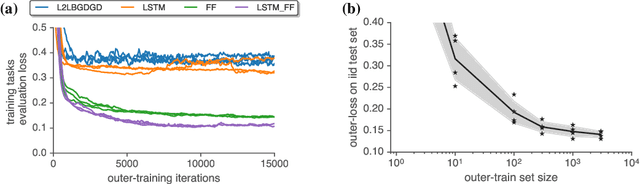
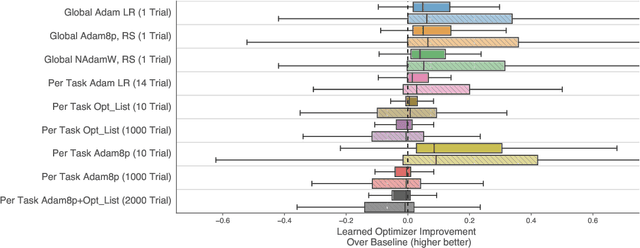
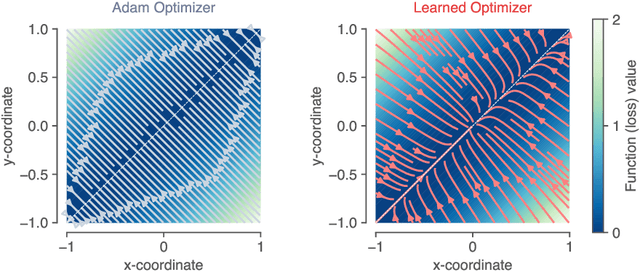
Much as replacing hand-designed features with learned functions has revolutionized how we solve perceptual tasks, we believe learned algorithms will transform how we train models. In this work we focus on general-purpose learned optimizers capable of training a wide variety of problems with no user-specified hyperparameters. We introduce a new, neural network parameterized, hierarchical optimizer with access to additional features such as validation loss to enable automatic regularization. Most learned optimizers have been trained on only a single task, or a small number of tasks. We train our optimizers on thousands of tasks, making use of orders of magnitude more compute, resulting in optimizers that generalize better to unseen tasks. The learned optimizers not only perform well, but learn behaviors that are distinct from existing first order optimizers. For instance, they generate update steps that have implicit regularization and adapt as the problem hyperparameters (e.g. batch size) or architecture (e.g. neural network width) change. Finally, these learned optimizers show evidence of being useful for out of distribution tasks such as training themselves from scratch.
On Linear Identifiability of Learned Representations
Jul 08, 2020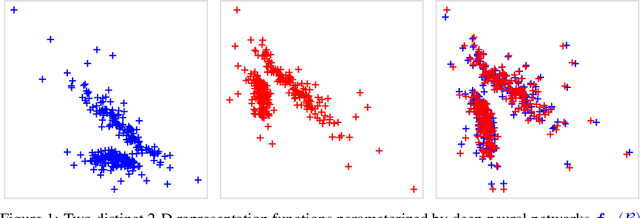
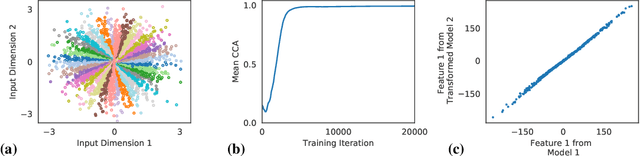
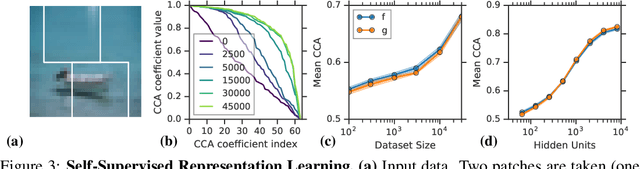
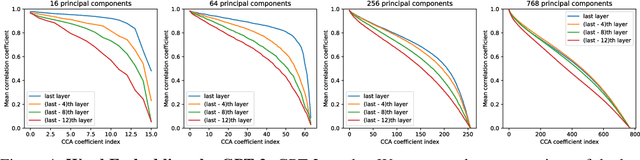
Identifiability is a desirable property of a statistical model: it implies that the true model parameters may be estimated to any desired precision, given sufficient computational resources and data. We study identifiability in the context of representation learning: discovering nonlinear data representations that are optimal with respect to some downstream task. When parameterized as deep neural networks, such representation functions typically lack identifiability in parameter space, because they are overparameterized by design. In this paper, building on recent advances in nonlinear ICA, we aim to rehabilitate identifiability by showing that a large family of discriminative models are in fact identifiable in function space, up to a linear indeterminacy. Many models for representation learning in a wide variety of domains have been identifiable in this sense, including text, images and audio, state-of-the-art at time of publication. We derive sufficient conditions for linear identifiability and provide empirical support for the result on both simulated and real-world data.