 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MuSe 2021 Multimodal Sentiment Analysis Challenge: Sentiment, Emotion, Physiological-Emotion, and Stress
Apr 14, 2021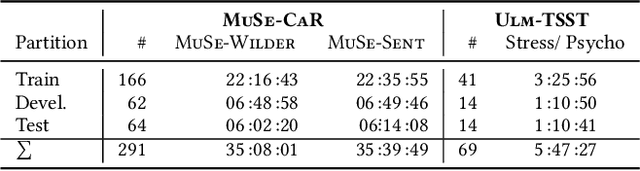
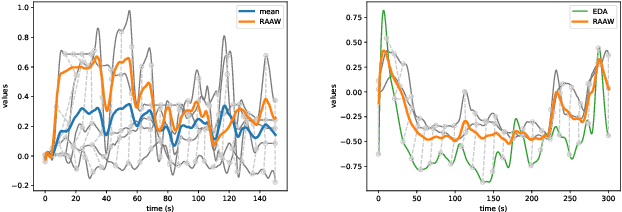

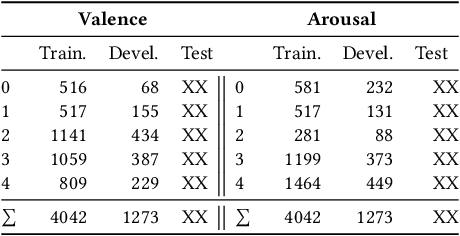
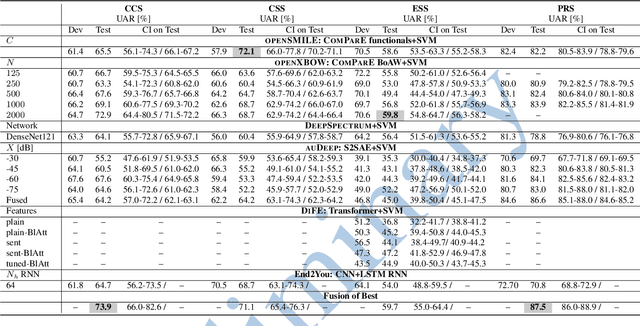
Multimodal Sentiment Analysis (MuSe) 2021 is a challenge focusing on the tasks of sentiment and emotion, as well as physiological-emotion and emotion-based stress recognition through more comprehensively integrating the audio-visual, language, and biological signal modalities. The purpose of MuSe 2021 is to bring together communities from different disciplines; mainly, the audio-visual emotion recognition community (signal-based), the sentiment analysis community (symbol-based), and the health informatics community. We present four distinct sub-challenges: MuSe-Wilder and MuSe-Stress which focus on continuous emotion (valence and arousal) prediction; MuSe-Sent, in which participants recognise five classes each for valence and arousal; and MuSe-Physio, in which the novel aspect of `physiological-emotion' is to be predicted. For this years' challenge, we utilise the MuSe-CaR dataset focusing on user-generated reviews and introduce the Ulm-TSST dataset, which displays people in stressful depositions. This paper also provides detail on the state-of-the-art feature sets extracted from these datasets for utilisation by our baseline model, a Long Short-Term Memory-Recurrent Neural Network. For each sub-challenge, a competitive baseline for participants is set; namely, on test, we report a Concordance Correlation Coefficient (CCC) of .4616 CCC for MuSe-Wilder; .4717 CCC for MuSe-Stress, and .4606 CCC for MuSe-Physio. For MuSe-Sent an F1 score of 32.82 % is obtained.
The INTERSPEECH 2021 Computational Paralinguistics Challenge: COVID-19 Cough, COVID-19 Speech, Escalation & Primates
Feb 24, 2021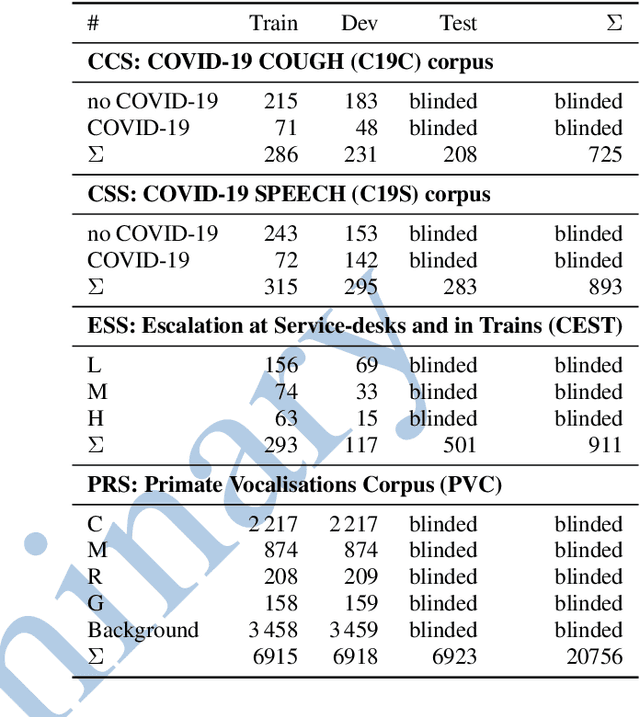
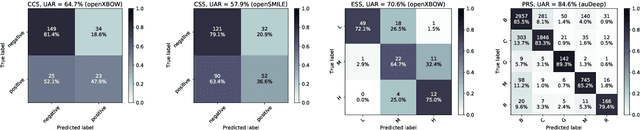
The INTERSPEECH 2021 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the COVID-19 Cough and COVID-19 Speech Sub-Challenges, a binary classification on COVID-19 infection has to be made based on coughing sounds and speech; in the Escalation SubChallenge, a three-way assessment of the level of escalation in a dialogue is featured; and in the Primates Sub-Challenge, four species vs background need to be classified. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the 'usual' COMPARE and BoAW features as well as deep unsupervised representation learning using the AuDeep toolkit, and deep feature extraction from pre-trained CNNs using the Deep Spectrum toolkit; in addition, we add deep end-to-end sequential modelling, and partially linguistic analysis.
The Multimodal Sentiment Analysis in Car Reviews (MuSe-CaR) Dataset: Collection, Insights and Improvements
Jan 15, 2021

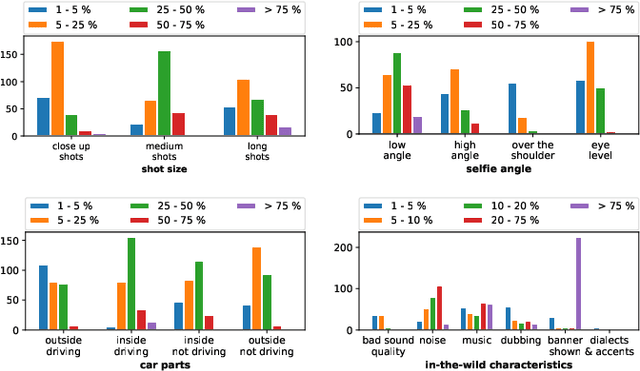
Truly real-life data presents a strong, but exciting challenge for sentiment and emotion research. The high variety of possible `in-the-wild' properties makes large datasets such as these indispensable with respect to building robust machine learning models. A sufficient quantity of data covering a deep variety in the challenges of each modality to force the exploratory analysis of the interplay of all modalities has not yet been made available in this context. In this contribution, we present MuSe-CaR, a first of its kind multimodal dataset. The data is publicly available as it recently served as the testing bed for the 1st Multimodal Sentiment Analysis Challenge, and focused on the tasks of emotion, emotion-target engagement, and trustworthiness recognition by means of comprehensively integrating the audio-visual and language modalities. Furthermore, we give a thorough overview of the dataset in terms of collection and annotation, including annotation tiers not used in this year's MuSe 2020. In addition, for one of the sub-challenges - predicting the level of trustworthiness - no participant outperformed the baseline model, and so we propose a simple, but highly efficient Multi-Head-Attention network that exceeds using multimodal fusion the baseline by around 0.2 CCC (almost 50 % improvement).
Go-CaRD -- Generic, Optical Car Part Recognition and Detection: Collection, Insights, and Applications
Jun 15, 2020
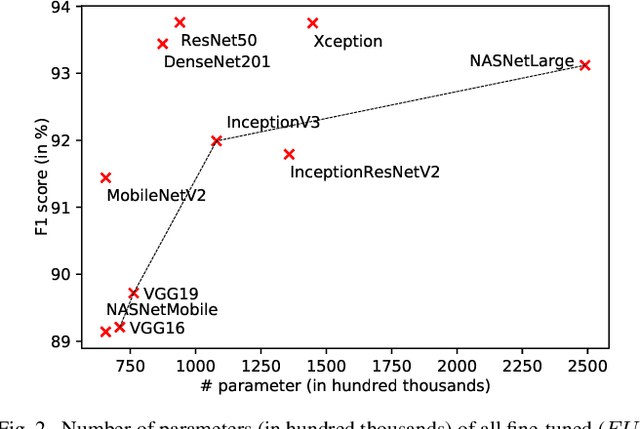

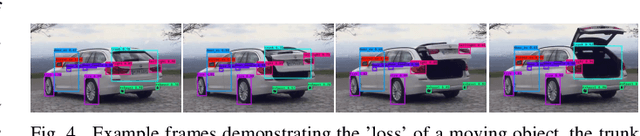
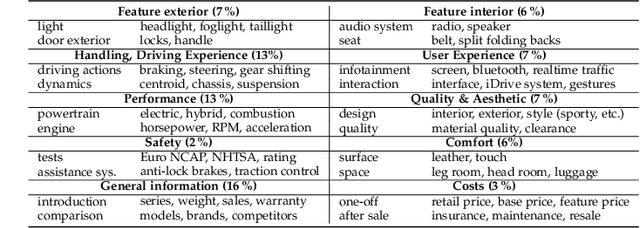
Systems for the automatic recognition and detection of automotive parts are crucial in several emerging research areas in the development of intelligent vehicles. They enable, for example, the detection and modelling of interactions between human and the vehicle. In this paper, we present three suitable datasets as well as quantitatively and qualitatively explore the efficacy of state-of-the-art deep learning architectures for the localisation of 29 interior and exterior vehicle regions, independent of brand, model, and environment. A ResNet50 model achieved an F1 score of 93.67 % for recognition, while our best Darknet model achieved an mAP of 58.20 % for detection. We also experiment with joint and transfer learning approaches and point out potential applications of our systems.
MuSe 2020 -- The First International Multimodal Sentiment Analysis in Real-life Media Challenge and Workshop
Apr 30, 2020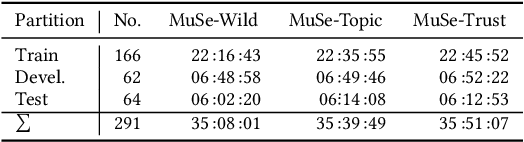
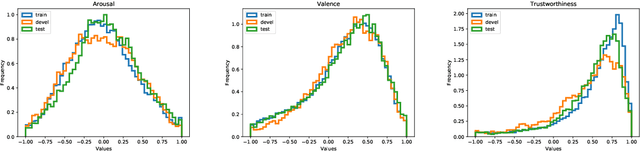
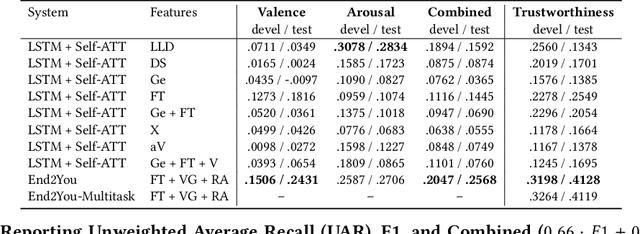
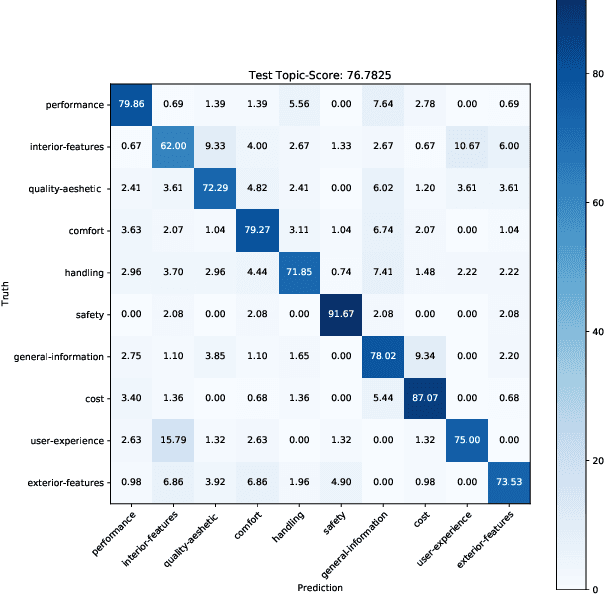
Multimodal Sentiment Analysis in Real-life Media (MuSe) 2020 is a Challenge-based Workshop focusing on the tasks of sentiment recognition, as well as emotion-target engagement and trustworthiness detection by means of more comprehensively integrating the audio-visual and language modalities. The purpose of MuSe 2020 is to bring together communities from different disciplines; mainly, the audio-visual emotion recognition community (signal-based), and the sentiment analysis community (symbol-based). We present three distinct sub-challenges: MuSe-Wild, which focuses on continuous emotion (arousal and valence) prediction; MuSe-Topic, in which participants recognise domain-specific topics as the target of 3-class (low, medium, high) emotions; and MuSe-Trust, in which the novel aspect of trustworthiness is to be predicted. In this paper, we provide detailed information on MuSe-CaR, the first of its kind in-the-wild database, which is utilised for the challenge, as well as the state-of-the-art features and modelling approaches applied. For each sub-challenge, a competitive baseline for participants is set; namely, on test we report for MuSe-Wild a combined (valence and arousal) CCC of .2568, for MuSe-Topic a score (computed as 0.34$\cdot$ UAR + 0.66$\cdot$F1) of 76.78 % on the 10-class topic and 40.64 % on the 3-class emotion prediction, and for MuSe-Trust a CCC of .4359.
Cross-lingual Zero- and Few-shot Hate Speech Detection Utilising Frozen Transformer Language Models and AXEL
Apr 13, 2020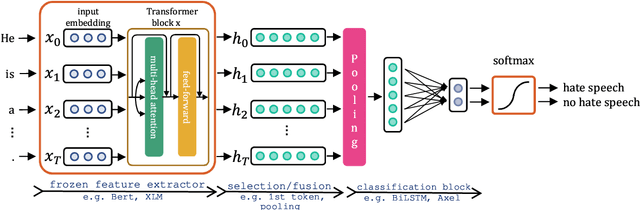
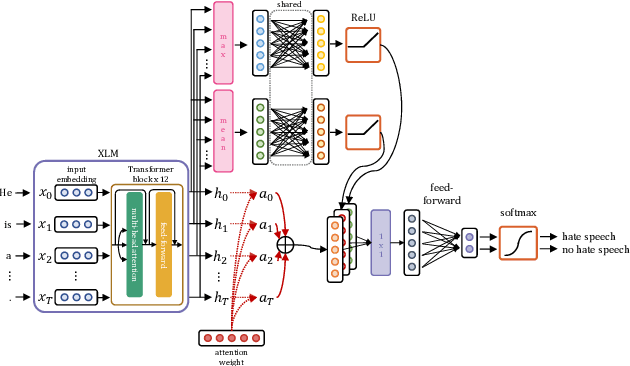
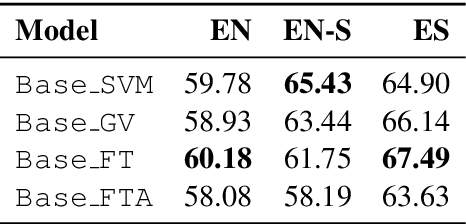
Detecting hate speech, especially in low-resource languages, is a non-trivial challenge. To tackle this, we developed a tailored architecture based on frozen, pre-trained Transformers to examine cross-lingual zero-shot and few-shot learning, in addition to uni-lingual learning, on the HatEval challenge data set. With our novel attention-based classification block AXEL, we demonstrate highly competitive results on the English and Spanish subsets. We also re-sample the English subset, enabling additional, meaningful comparisons in the future.
On Classifying Sepsis Heterogeneity in the ICU: Insight Using Machine Learning
Dec 03, 2019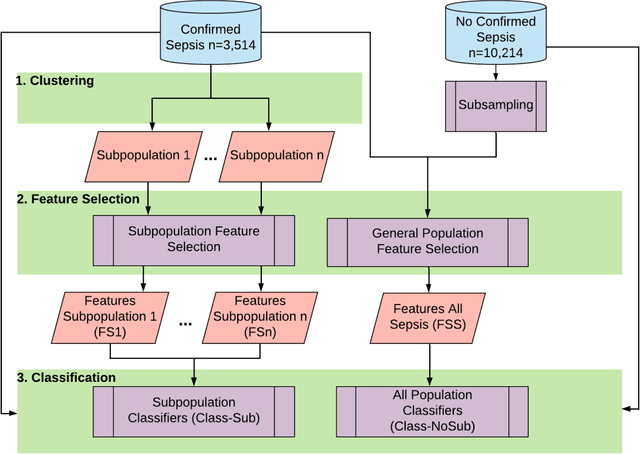
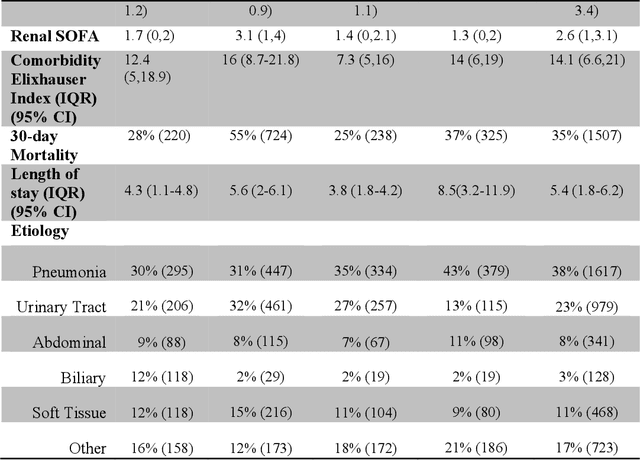
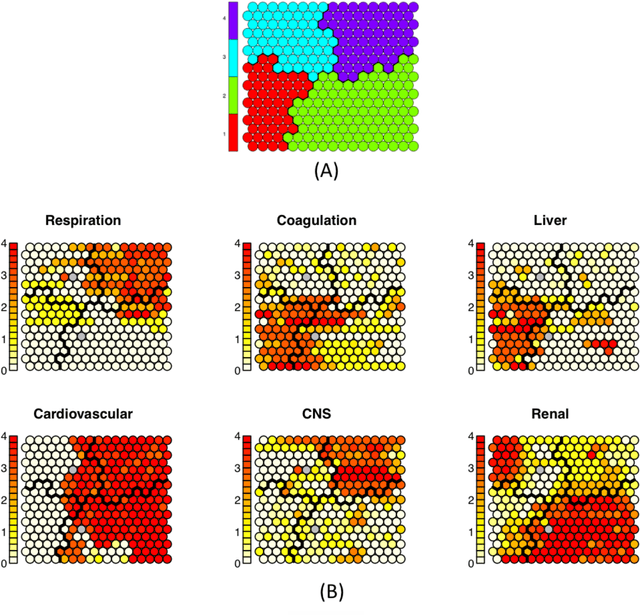
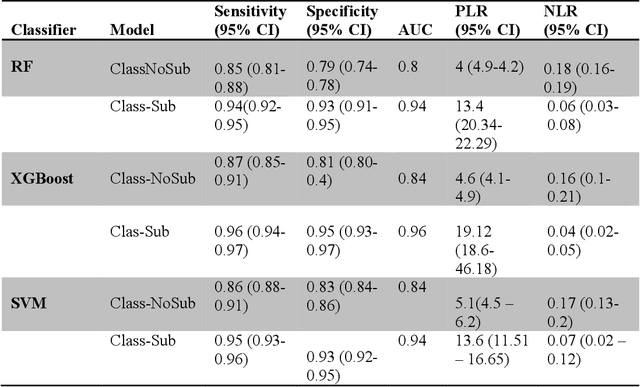
Current machine learning models aiming to predict sepsis from Electronic Health Records (EHR) do not account for the heterogeneity of the condition, despite its emerging importance in prognosis and treatment. This work demonstrates the added value of stratifying the types of organ dysfunction observed in patients who develop sepsis in the ICU in improving the ability to recognise patients at risk of sepsis from their EHR data. Using an ICU dataset of 13,728 records, we identify clinically significant sepsis subpopulations with distinct organ dysfunction patterns. Classification experiments using Random Forest, Gradient Boost Trees and Support Vector Machines, aiming to distinguish patients who develop sepsis in the ICU from those who do not, show that features selected using sepsis subpopulations as background knowledge yield a superior performance regardless of the classification model used. Our findings can steer machine learning efforts towards more personalised models for complex conditions including sepsis.