 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD5P4: Partition Determinantal Point Process for Diversity in Parallel Discrete Diffusion Decoding
Mar 19, 2026Discrete diffusion models are promising alternatives to autoregressive approaches for text generation, yet their decoding methods remain under-studied. Standard decoding methods for autoregressive models, such as beam search, do not directly apply to iterative denoising, and existing diffusion decoding techniques provide limited control over in-batch diversity. To bridge this gap, we introduce a generalized beam-search framework for discrete diffusion that generates candidates in parallel and supports modular beam-selection objectives. As a diversity-focused instantiation, we propose D5P4, which formulates the selection step as MAP inference over a Determinantal Point Process. Leveraging a scalable greedy solver, D5P4 maintains multi-GPU compatibility and enables an explicit trade-off between model probability and target diversity with near-zero compute overhead. Experiments on free-form generation and question answering demonstrate that D5P4 improves diversity over strong baselines while maintaining competitive generation quality.
Residual Connections and the Causal Shift: Uncovering a Structural Misalignment in Transformers
Feb 16, 2026Large Language Models (LLMs) are trained with next-token prediction, implemented in autoregressive Transformers via causal masking for parallelism. This creates a subtle misalignment: residual connections tie activations to the current token, while supervision targets the next token, potentially propagating mismatched information if the current token is not the most informative for prediction. In this work, we empirically localize this input-output alignment shift in pretrained LLMs, using decoding trajectories over tied embedding spaces and similarity-based metrics. Our experiments reveal that the hidden token representations switch from input alignment to output alignment deep within the network. Motivated by this observation, we propose a lightweight residual-path mitigation based on residual attenuation, implemented either as a fixed-layer intervention or as a learnable gating mechanism. Experiments on multiple benchmarks show that these strategies alleviate the representation misalignment and yield improvements, providing an efficient and general architectural enhancement for autoregressive Transformers.
Inner Loop Inference for Pretrained Transformers: Unlocking Latent Capabilities Without Training
Feb 16, 2026Deep Learning architectures, and in particular Transformers, are conventionally viewed as a composition of layers. These layers are actually often obtained as the sum of two contributions: a residual path that copies the input and the output of a Transformer block. As a consequence, the inner representations (i.e. the input of these blocks) can be interpreted as iterative refinement of a propagated latent representation. Under this lens, many works suggest that the inner space is shared across layers, meaning that tokens can be decoded at early stages. Mechanistic interpretability even goes further by conjecturing that some layers act as refinement layers. Following this path, we propose inference-time inner looping, which prolongs refinement in pretrained off-the-shelf language models by repeatedly re-applying a selected block range. Across multiple benchmarks, inner looping yields modest but consistent accuracy improvements. Analyses of the resulting latent trajectories suggest more stable state evolution and continued semantic refinement. Overall, our results suggest that additional refinement can be obtained through simple test-time looping, extending computation in frozen pretrained models.
On multi-token prediction for efficient LLM inference
Feb 13, 2025
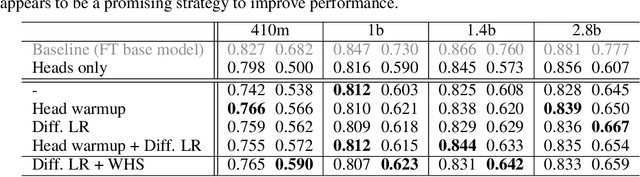

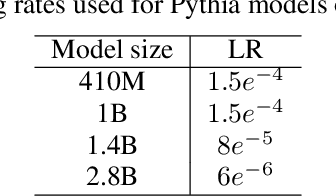
We systematically investigate multi-token prediction (MTP) capabilities within LLMs pre-trained for next-token prediction (NTP). We first show that such models inherently possess MTP capabilities via numerical marginalization over intermediate token probabilities, though performance is data-dependent and improves with model scale. Furthermore, we explore the challenges of integrating MTP heads into frozen LLMs and find that their hidden layers are strongly specialized for NTP, making adaptation non-trivial. Finally, we show that while joint training of MTP heads with the backbone improves performance, it cannot fully overcome this barrier, prompting further research in this direction. Our findings provide a deeper understanding of MTP applied to pretrained LLMs, informing strategies for accelerating inference through parallel token prediction.
Schemato -- An LLM for Netlist-to-Schematic Conversion
Nov 21, 2024



Machine learning models are advancing circuit design, particularly in analog circuits. They typically generate netlists that lack human interpretability. This is a problem as human designers heavily rely on the interpretability of circuit diagrams or schematics to intuitively understand, troubleshoot, and develop designs. Hence, to integrate domain knowledge effectively, it is crucial to translate ML-generated netlists into interpretable schematics quickly and accurately. We propose Schemato, a large language model (LLM) for netlist-to-schematic conversion. In particular, we consider our approach in the two settings of converting netlists to .asc files for LTSpice and LATEX files for CircuiTikz schematics. Experiments on our circuit dataset show that Schemato achieves up to 93% compilation success rate for the netlist-to-LaTeX conversion task, surpassing the 26% rate scored by the state-of-the-art LLMs. Furthermore, our experiments show that Schemato generates schematics with a mean structural similarity index measure that is 3xhigher than the best performing LLMs, therefore closer to the reference human design.
SAFT: Towards Out-of-Distribution Generalization in Fine-Tuning
Jul 03, 2024



Handling distribution shifts from training data, known as out-of-distribution (OOD) generalization, poses a significant challenge in the field of machine learning. While a pre-trained vision-language model like CLIP has demonstrated remarkable zero-shot performance, further adaptation of the model to downstream tasks leads to undesirable degradation for OOD data. In this work, we introduce Sparse Adaptation for Fine-Tuning (SAFT), a method that prevents fine-tuning from forgetting the general knowledge in the pre-trained model. SAFT only updates a small subset of important parameters whose gradient magnitude is large, while keeping the other parameters frozen. SAFT is straightforward to implement and conceptually simple. Extensive experiments show that with only 0.1% of the model parameters, SAFT can significantly improve the performance of CLIP. It consistently outperforms baseline methods across several benchmarks. On the few-shot learning benchmark of ImageNet and its variants, SAFT gives a gain of 5.15% on average over the conventional fine-tuning method in OOD settings.
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Apr 02, 2024We consider the problem of zero-shot one-class visual classification. In this setting, only the label of the target class is available, and the goal is to discriminate between positive and negative query samples without requiring any validation example from the target task. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. Our work shows that it is possible to discriminate between a single category and other semantically related ones using only its label
A Novel Benchmark for Few-Shot Semantic Segmentation in the Era of Foundation Models
Jan 20, 2024



In recent years, the rapid evolution of computer vision has seen the emergence of various vision foundation models, each tailored to specific data types and tasks. While large language models often share a common pretext task, the diversity in vision foundation models arises from their varying training objectives. In this study, we delve into the quest for identifying the most effective vision foundation models for few-shot semantic segmentation, a critical task in computer vision. Specifically, we conduct a comprehensive comparative analysis of four prominent foundation models: DINO V2, Segment Anything, CLIP, Masked AutoEncoders, and a straightforward ResNet50 pre-trained on the COCO dataset. Our investigation focuses on their adaptability to new semantic segmentation tasks, leveraging only a limited number of segmented images. Our experimental findings reveal that DINO V2 consistently outperforms the other considered foundation models across a diverse range of datasets and adaptation methods. This outcome underscores DINO V2's superior capability to adapt to semantic segmentation tasks compared to its counterparts. Furthermore, our observations indicate that various adapter methods exhibit similar performance, emphasizing the paramount importance of selecting a robust feature extractor over the intricacies of the adaptation technique itself. This insight sheds light on the critical role of feature extraction in the context of few-shot semantic segmentation. This research not only contributes valuable insights into the comparative performance of vision foundation models in the realm of few-shot semantic segmentation but also highlights the significance of a robust feature extractor in this domain.
Inferring Latent Class Statistics from Text for Robust Visual Few-Shot Learning
Nov 24, 2023



In the realm of few-shot learning, foundation models like CLIP have proven effective but exhibit limitations in cross-domain robustness especially in few-shot settings. Recent works add text as an extra modality to enhance the performance of these models. Most of these approaches treat text as an auxiliary modality without fully exploring its potential to elucidate the underlying class visual features distribution. In this paper, we present a novel approach that leverages text-derived statistics to predict the mean and covariance of the visual feature distribution for each class. This predictive framework enriches the latent space, yielding more robust and generalizable few-shot learning models. We demonstrate the efficacy of incorporating both mean and covariance statistics in improving few-shot classification performance across various datasets. Our method shows that we can use text to predict the mean and covariance of the distribution offering promising improvements in few-shot learning scenarios.
Order-Preserving GFlowNets
Sep 30, 2023Generative Flow Networks (GFlowNets) have been introduced as a method to sample a diverse set of candidates with probabilities proportional to a given reward. However, GFlowNets can only be used with a predefined scalar reward, which can be either computationally expensive or not directly accessible, in the case of multi-objective optimization (MOO) tasks for example. Moreover, to prioritize identifying high-reward candidates, the conventional practice is to raise the reward to a higher exponent, the optimal choice of which may vary across different environments. To address these issues, we propose Order-Preserving GFlowNets (OP-GFNs), which sample with probabilities in proportion to a learned reward function that is consistent with a provided (partial) order on the candidates, thus eliminating the need for an explicit formulation of the reward function. We theoretically prove that the training process of OP-GFNs gradually sparsifies the learned reward landscape in single-objective maximization tasks. The sparsification concentrates on candidates of a higher hierarchy in the ordering, ensuring exploration at the beginning and exploitation towards the end of the training. We demonstrate OP-GFN's state-of-the-art performance in single-objective maximization (totally ordered) and multi-objective Pareto front approximation (partially ordered) tasks, including synthetic datasets, molecule generation, and neural architecture search.