 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurst2Vec: An Adversarial Multi-Task Approach for Predicting Emotion, Age, and Origin from Vocal Bursts
Jun 24, 2022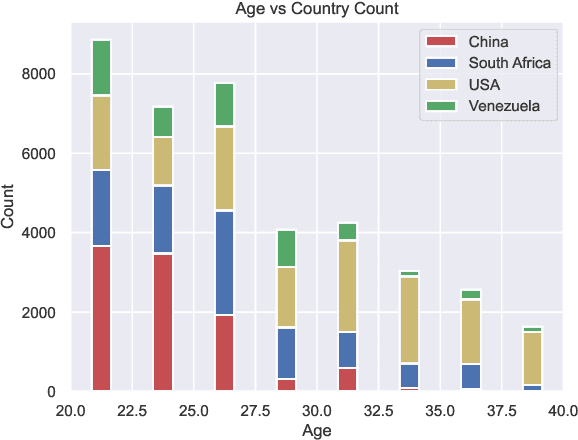
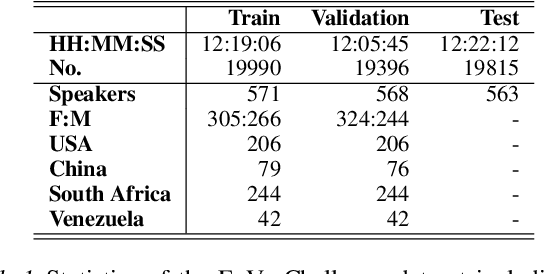
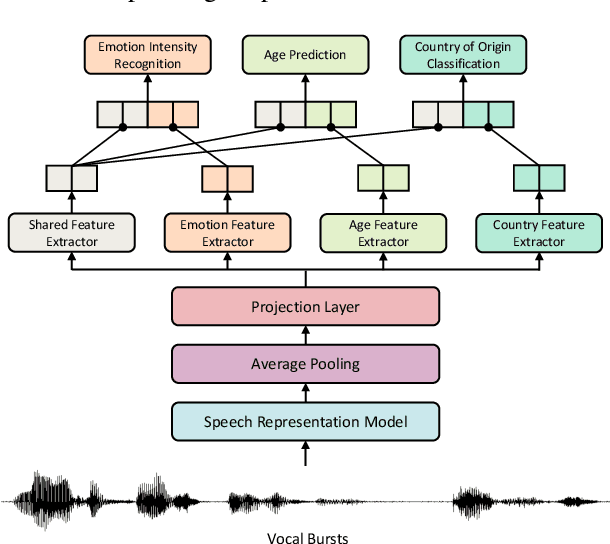
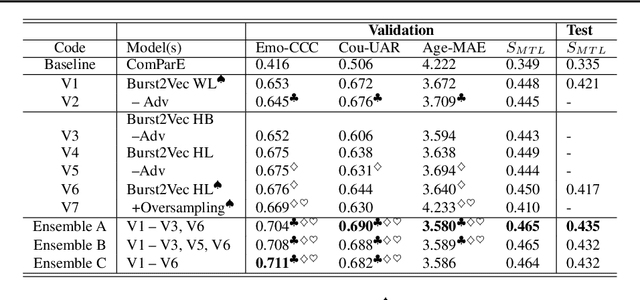
We present Burst2Vec, our multi-task learning approach to predict emotion, age, and origin (i.e., native country/language) from vocal bursts. Burst2Vec utilises pre-trained speech representations to capture acoustic information from raw waveforms and incorporates the concept of model debiasing via adversarial training. Our models achieve a relative 30 % performance gain over baselines using pre-extracted features and score the highest amongst all participants in the ICML ExVo 2022 Multi-Task Challenge.
Logically Consistent Adversarial Attacks for Soft Theorem Provers
Apr 29, 2022
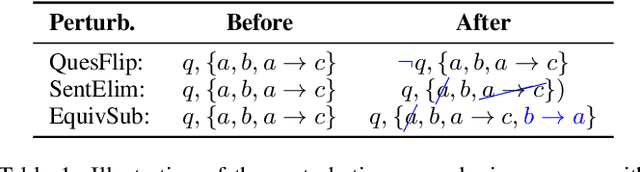
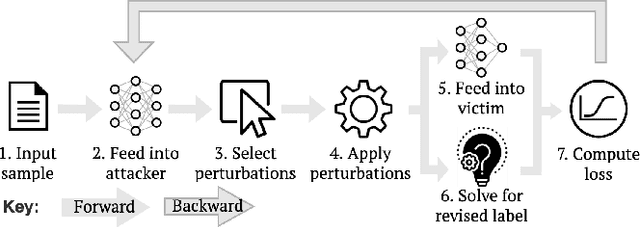
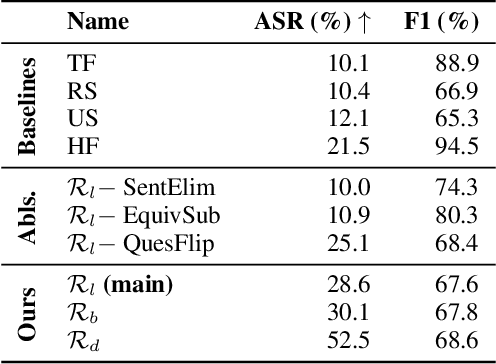
Recent efforts within the AI community have yielded impressive results towards "soft theorem proving" over natural language sentences using language models. We propose a novel, generative adversarial framework for probing and improving these models' reasoning capabilities. Adversarial attacks in this domain suffer from the logical inconsistency problem, whereby perturbations to the input may alter the label. Our Logically consistent AdVersarial Attacker, LAVA, addresses this by combining a structured generative process with a symbolic solver, guaranteeing logical consistency. Our framework successfully generates adversarial attacks and identifies global weaknesses common across multiple target models. Our analyses reveal naive heuristics and vulnerabilities in these models' reasoning capabilities, exposing an incomplete grasp of logical deduction under logic programs. Finally, in addition to effective probing of these models, we show that training on the generated samples improves the target model's performance.
Supervised Visual Attention for Simultaneous Multimodal Machine Translation
Jan 23, 2022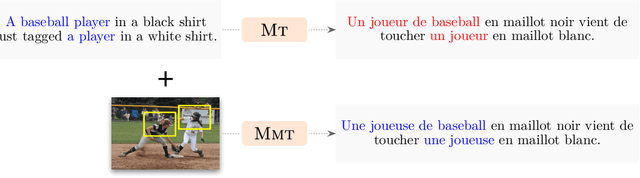
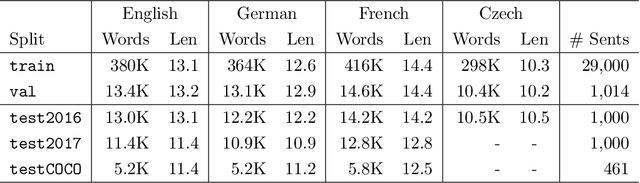
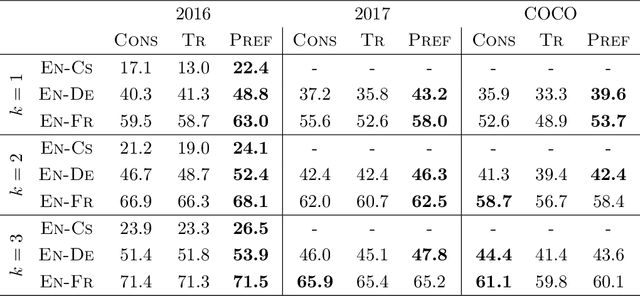
Recently, there has been a surge in research in multimodal machine translation (MMT), where additional modalities such as images are used to improve translation quality of textual systems. A particular use for such multimodal systems is the task of simultaneous machine translation, where visual context has been shown to complement the partial information provided by the source sentence, especially in the early phases of translation (Caglayanet al., 2020a; Imankulova et al., 2020). In this paper, we propose the first Transformer-based simultaneous MMT architecture, which has not been previously explored in the field. Additionally, we extend this model with an auxiliary supervision signal that guides its visual attention mechanism using labelled phrase-region alignments. We perform comprehensive experiments on three language directions and conduct thorough quantitative and qualitative analyses using both automatic metrics and manual inspection. Our results show that (i) supervised visual attention consistently improves the translation quality of the MMT models, and (ii) fine-tuning the MMT with supervision loss enabled leads to better performance than training the MMT from scratch. Compared to the state-of-the-art, our proposed model achieves improvements of up to 2.3 BLEU and 3.5 METEOR points.
Revisiting Contextual Toxicity Detection in Conversations
Nov 30, 2021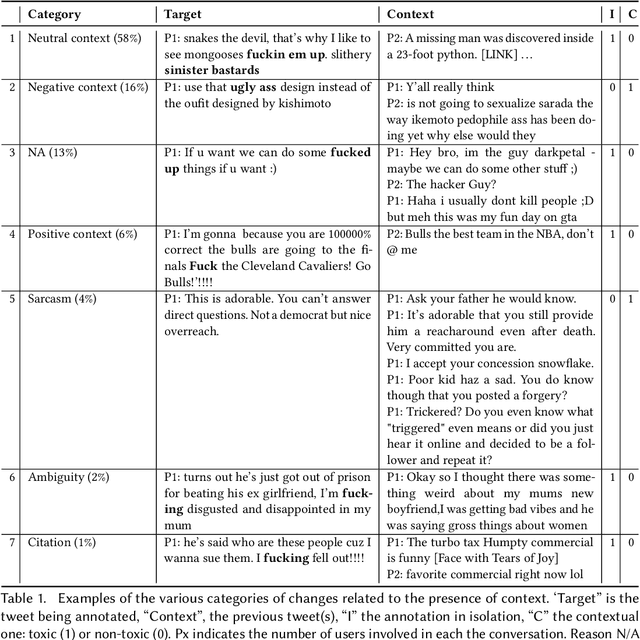
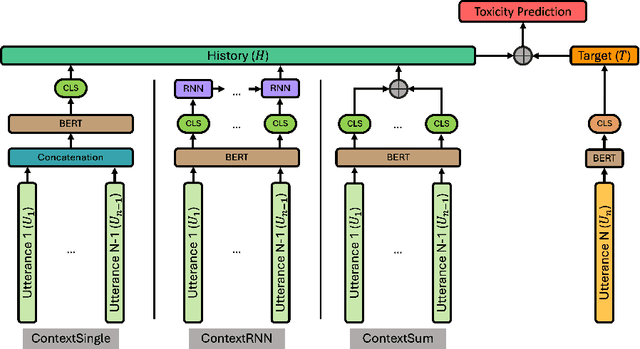

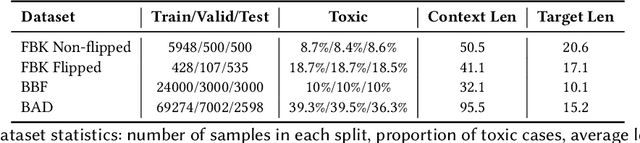
Understanding toxicity in user conversations is undoubtedly an important problem. As it has been argued in previous work, addressing "covert" or implicit cases of toxicity is particularly hard and requires context. Very few previous studies have analysed the influence of conversational context in human perception or in automated detection models. We dive deeper into both these directions. We start by analysing existing contextual datasets and come to the conclusion that toxicity labelling by humans is in general influenced by the conversational structure, polarity and topic of the context. We then propose to bring these findings into computational detection models by introducing (a) neural architectures for contextual toxicity detection that are aware of the conversational structure, and (b) data augmentation strategies that can help model contextual toxicity detection. Our results have shown the encouraging potential of neural architectures that are aware of the conversation structure. We have also demonstrated that such models can benefit from synthetic data, especially in the social media domain.
Guiding Visual Question Generation
Oct 15, 2021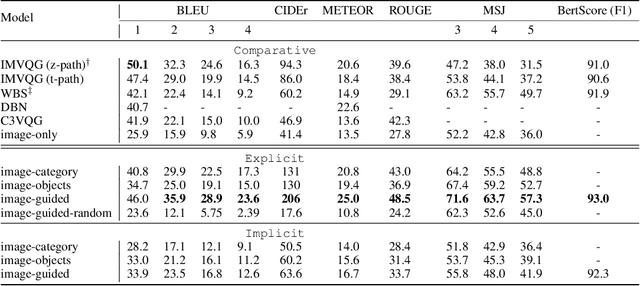
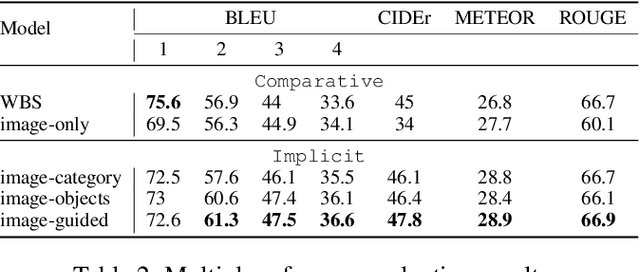


In traditional Visual Question Generation (VQG), most images have multiple concepts (e.g. objects and categories) for which a question could be generated, but models are trained to mimic an arbitrary choice of concept as given in their training data. This makes training difficult and also poses issues for evaluation -- multiple valid questions exist for most images but only one or a few are captured by the human references. We present Guiding Visual Question Generation - a variant of VQG which conditions the question generator on categorical information based on expectations on the type of question and the objects it should explore. We propose two variants: (i) an explicitly guided model that enables an actor (human or automated) to select which objects and categories to generate a question for; and (ii) an implicitly guided model that learns which objects and categories to condition on, based on discrete latent variables. The proposed models are evaluated on an answer-category augmented VQA dataset and our quantitative results show a substantial improvement over the current state of the art (over 9 BLEU-4 increase). Human evaluation validates that guidance helps the generation of questions that are grammatically coherent and relevant to the given image and objects.
Pushing the Right Buttons: Adversarial Evaluation of Quality Estimation
Sep 22, 2021
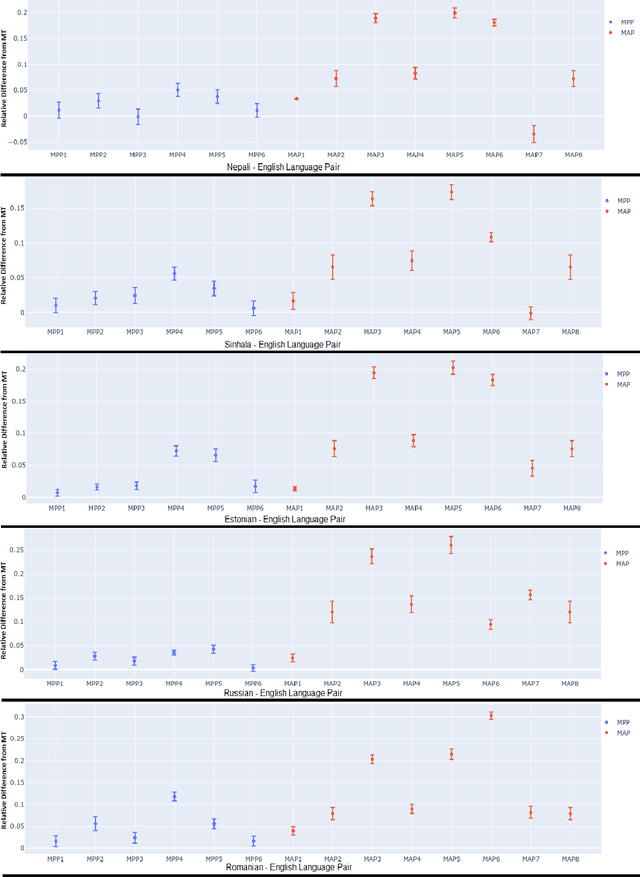

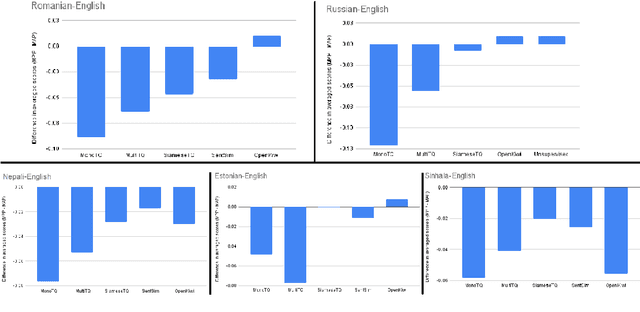
Current Machine Translation (MT) systems achieve very good results on a growing variety of language pairs and datasets. However, they are known to produce fluent translation outputs that can contain important meaning errors, thus undermining their reliability in practice. Quality Estimation (QE) is the task of automatically assessing the performance of MT systems at test time. Thus, in order to be useful, QE systems should be able to detect such errors. However, this ability is yet to be tested in the current evaluation practices, where QE systems are assessed only in terms of their correlation with human judgements. In this work, we bridge this gap by proposing a general methodology for adversarial testing of QE for MT. First, we show that despite a high correlation with human judgements achieved by the recent SOTA, certain types of meaning errors are still problematic for QE to detect. Second, we show that on average, the ability of a given model to discriminate between meaning-preserving and meaning-altering perturbations is predictive of its overall performance, thus potentially allowing for comparing QE systems without relying on manual quality annotation.
Classification-based Quality Estimation: Small and Efficient Models for Real-world Applications
Sep 17, 2021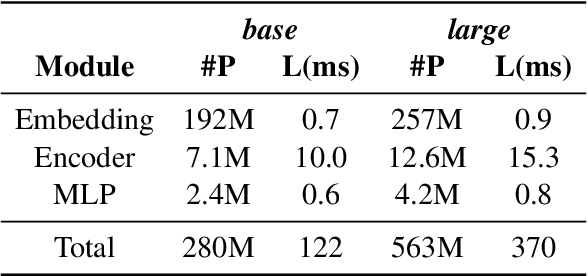
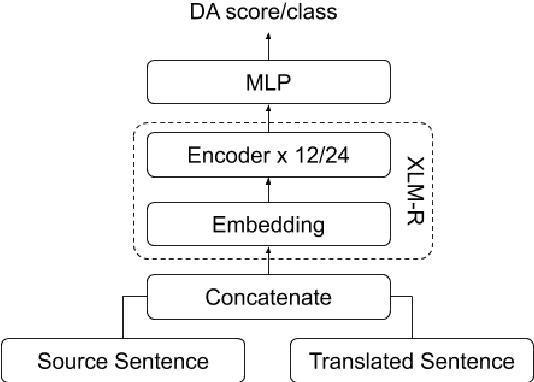
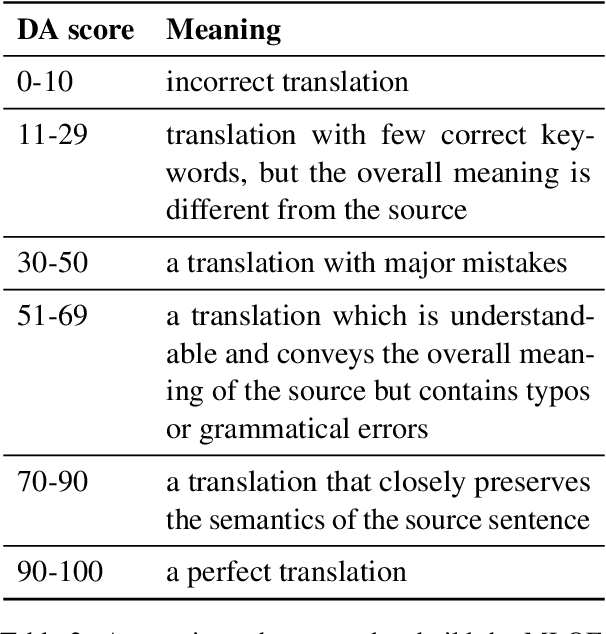
Sentence-level Quality estimation (QE) of machine translation is traditionally formulated as a regression task, and the performance of QE models is typically measured by Pearson correlation with human labels. Recent QE models have achieved previously-unseen levels of correlation with human judgments, but they rely on large multilingual contextualized language models that are computationally expensive and make them infeasible for real-world applications. In this work, we evaluate several model compression techniques for QE and find that, despite their popularity in other NLP tasks, they lead to poor performance in this regression setting. We observe that a full model parameterization is required to achieve SoTA results in a regression task. However, we argue that the level of expressiveness of a model in a continuous range is unnecessary given the downstream applications of QE, and show that reframing QE as a classification problem and evaluating QE models using classification metrics would better reflect their actual performance in real-world applications.
A Survey of Online Hate Speech through the Causal Lens
Sep 16, 2021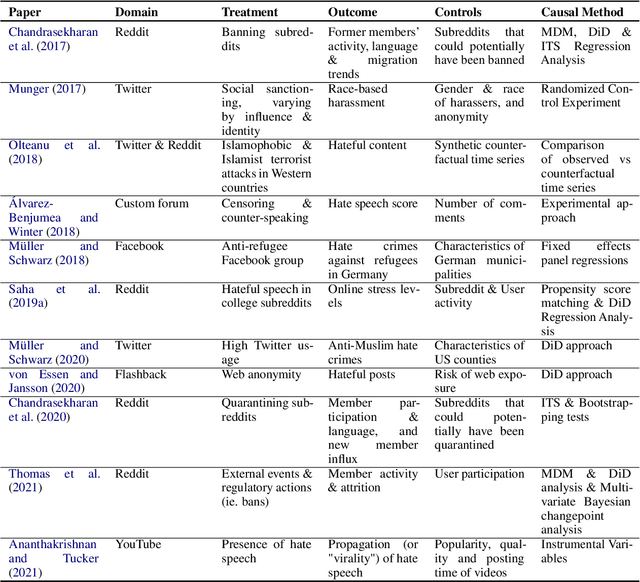
The societal issue of digital hostility has previously attracted a lot of attention. The topic counts an ample body of literature, yet remains prominent and challenging as ever due to its subjective nature. We posit that a better understanding of this problem will require the use of causal inference frameworks. This survey summarises the relevant research that revolves around estimations of causal effects related to online hate speech. Initially, we provide an argumentation as to why re-establishing the exploration of hate speech in causal terms is of the essence. Following that, we give an overview of the leading studies classified with respect to the direction of their outcomes, as well as an outline of all related research, and a summary of open research problems that can influence future work on the topic.
Translation Error Detection as Rationale Extraction
Aug 27, 2021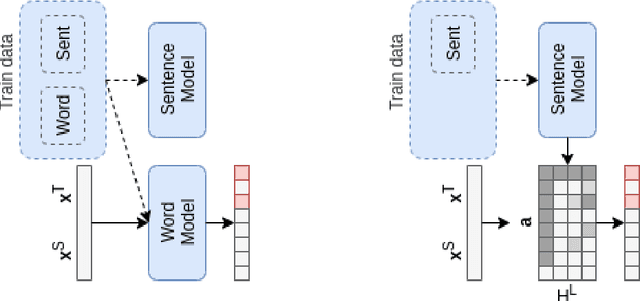
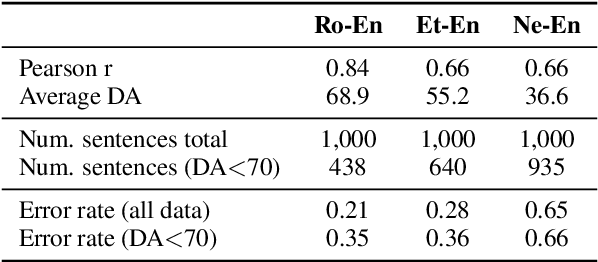
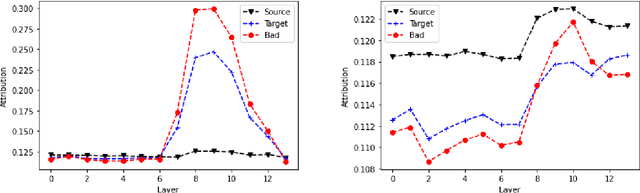
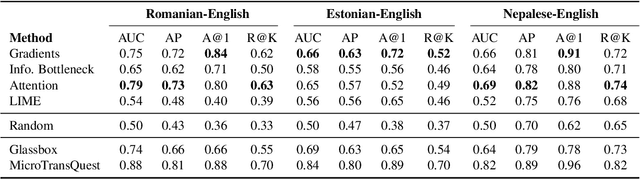
Recent Quality Estimation (QE) models based on multilingual pre-trained representations have achieved very competitive results when predicting the overall quality of translated sentences. Predicting translation errors, i.e. detecting specifically which words are incorrect, is a more challenging task, especially with limited amounts of training data. We hypothesize that, not unlike humans, successful QE models rely on translation errors to predict overall sentence quality. By exploring a set of feature attribution methods that assign relevance scores to the inputs to explain model predictions, we study the behaviour of state-of-the-art sentence-level QE models and show that explanations (i.e. rationales) extracted from these models can indeed be used to detect translation errors. We therefore (i) introduce a novel semi-supervised method for word-level QE and (ii) propose to use the QE task as a new benchmark for evaluating the plausibility of feature attribution, i.e. how interpretable model explanations are to humans.
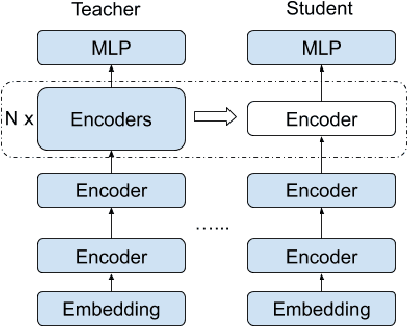
Knowledge Distillation for Quality Estimation
Jul 01, 2021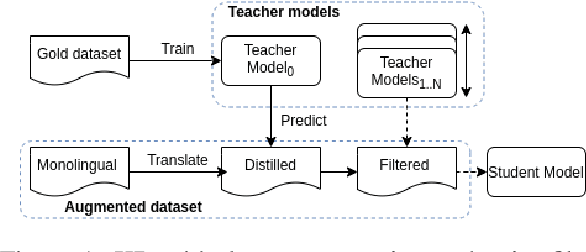
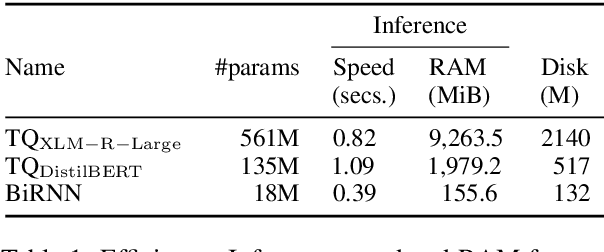
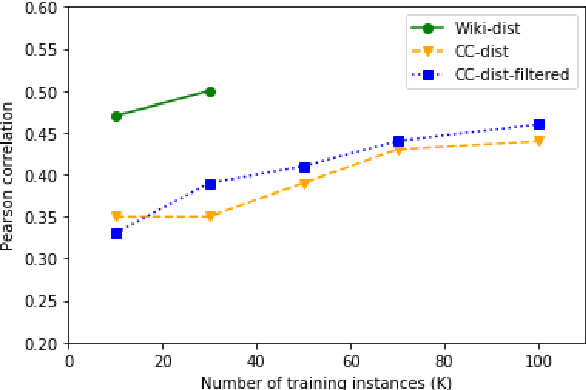
Quality Estimation (QE) is the task of automatically predicting Machine Translation quality in the absence of reference translations, making it applicable in real-time settings, such as translating online social media conversations. Recent success in QE stems from the use of multilingual pre-trained representations, where very large models lead to impressive results. However, the inference time, disk and memory requirements of such models do not allow for wide usage in the real world. Models trained on distilled pre-trained representations remain prohibitively large for many usage scenarios. We instead propose to directly transfer knowledge from a strong QE teacher model to a much smaller model with a different, shallower architecture. We show that this approach, in combination with data augmentation, leads to light-weight QE models that perform competitively with distilled pre-trained representations with 8x fewer parameters.