 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Iteration Complexity of Hypergradient Computation
Jul 10, 2020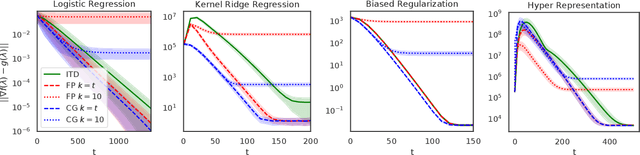

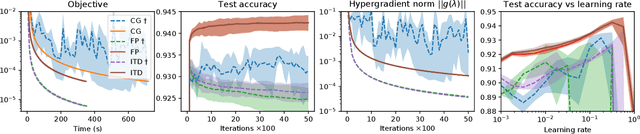
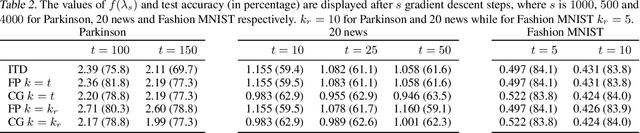
We study a general class of bilevel problems, consisting in the minimization of an upper-level objective which depends on the solution to a parametric fixed-point equation. Important instances arising in machine learning include hyperparameter optimization, meta-learning, and certain graph and recurrent neural networks. Typically the gradient of the upper-level objective (hypergradient) is hard or even impossible to compute exactly, which has raised the interest in approximation methods. We investigate some popular approaches to compute the hypergradient, based on reverse mode iterative differentiation and approximate implicit differentiation. Under the hypothesis that the fixed point equation is defined by a contraction mapping, we present a unified analysis which allows for the first time to quantitatively compare these methods, providing explicit bounds for their iteration complexity. This analysis suggests a hierarchy in terms of computational efficiency among the above methods, with approximate implicit differentiation based on conjugate gradient performing best. We present an extensive experimental comparison among the methods which confirm the theoretical findings.
Scheduling the Learning Rate via Hypergradients: New Insights and a New Algorithm
Oct 18, 2019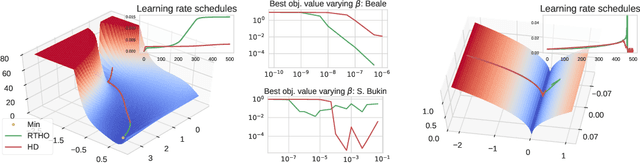
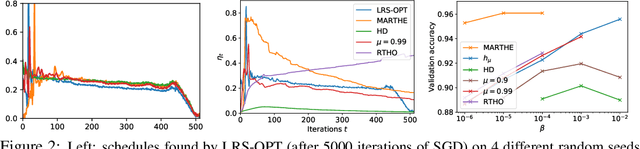
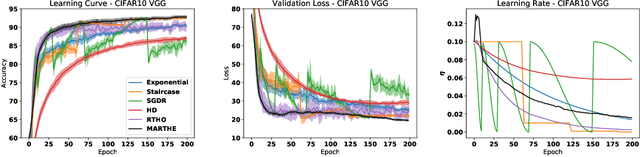
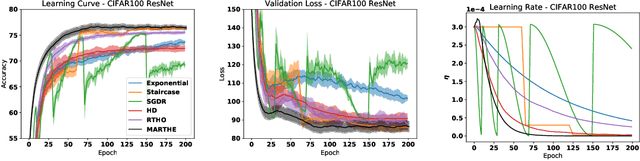
We study the problem of fitting task-specific learning rate schedules from the perspective of hyperparameter optimization. This allows us to explicitly search for schedules that achieve good generalization. We describe the structure of the gradient of a validation error w.r.t. the learning rate, the hypergradient, and based on this we introduce a novel online algorithm. Our method adaptively interpolates between the recently proposed techniques of Franceschi et al. (2017) and Baydin et al. (2017), featuring increased stability and faster convergence. We show empirically that the proposed method compares favourably with baselines and related methods in terms of final test accuracy.
Learning Discrete Structures for Graph Neural Networks
May 17, 2019
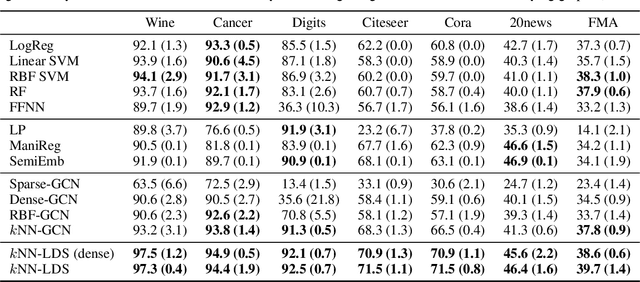
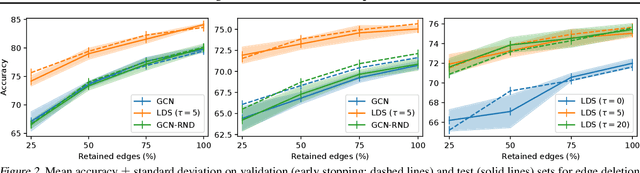
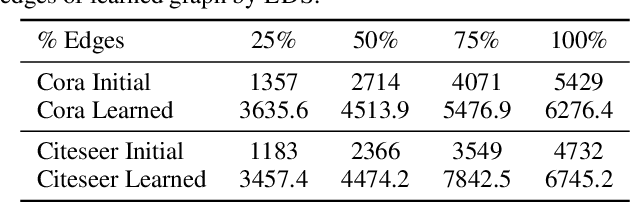
Graph neural networks (GNNs) are a popular class of machine learning models whose major advantage is their ability to incorporate a sparse and discrete dependency structure between data points. Unfortunately, GNNs can only be used when such a graph-structure is available. In practice, however, real-world graphs are often noisy and incomplete or might not be available at all. With this work, we propose to jointly learn the graph structure and the parameters of graph convolutional networks (GCNs) by approximately solving a bilevel program that learns a discrete probability distribution on the edges of the graph. This allows one to apply GCNs not only in scenarios where the given graph is incomplete or corrupted but also in those where a graph is not available. We conduct a series of experiments that analyze the behavior of the proposed method and demonstrate that it outperforms related methods by a significant margin.
Fast and Continuous Foothold Adaptation for Dynamic Locomotion through CNNs
Feb 15, 2019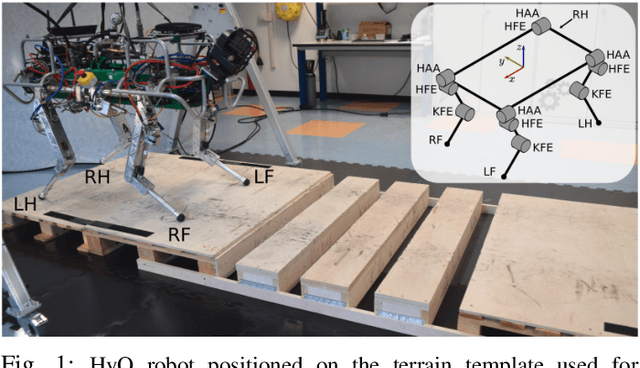


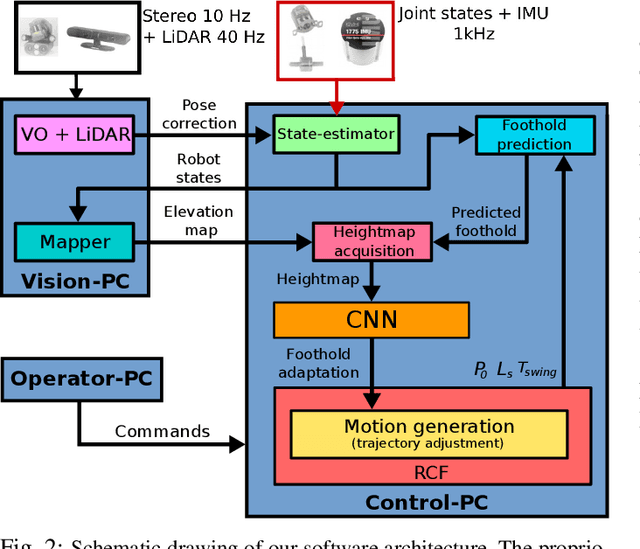
Legged robots can outperform wheeled machines for most navigation tasks across unknown and rough terrains. For such tasks, visual feedback is a fundamental asset to provide robots with terrain-awareness. However, robust dynamic locomotion on difficult terrains with real-time performance guarantees remains a challenge. We present here a real-time, dynamic foothold adaptation strategy based on visual feedback. Our method adjusts the landing position of the feet in a fully reactive manner, using only on-board computers and sensors. The correction is computed and executed continuously along the swing phase trajectory of each leg. To efficiently adapt the landing position, we implement a self-supervised foothold classifier based on a Convolutional Neural Network (CNN). Our method results in an up to 200 times faster computation with respect to the full-blown heuristics. Our goal is to react to visual stimuli from the environment, bridging the gap between blind reactive locomotion and purely vision-based planning strategies. We assess the performance of our method on the dynamic quadruped robot HyQ, executing static and dynamic gaits (at speeds up to 0.5 m/s) in both simulated and real scenarios; the benefit of safe foothold adaptation is clearly demonstrated by the overall robot behavior.
Bilevel Programming for Hyperparameter Optimization and Meta-Learning
Jul 03, 2018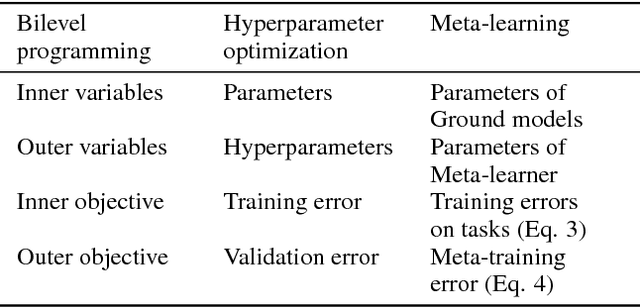
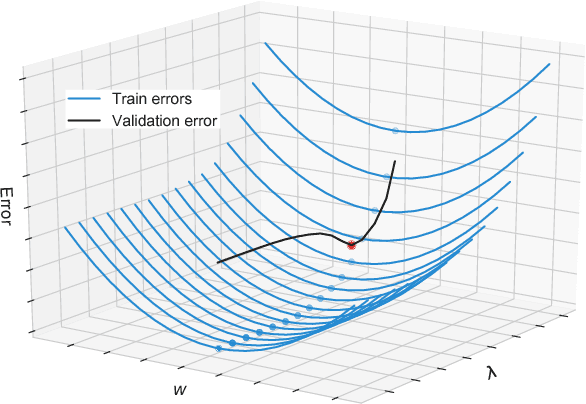
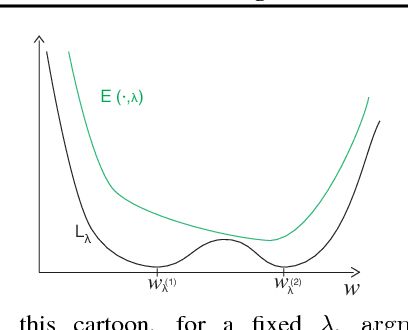
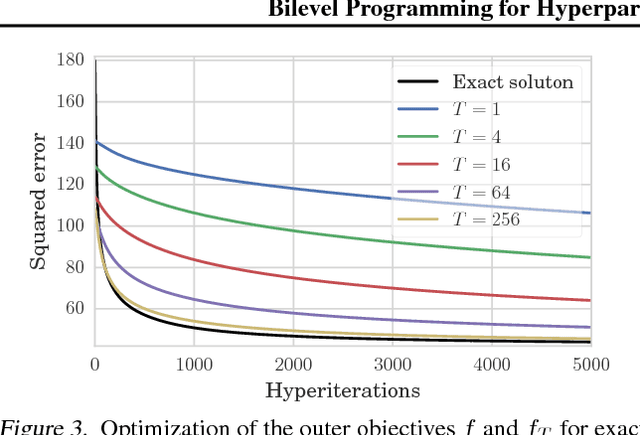
We introduce a framework based on bilevel programming that unifies gradient-based hyperparameter optimization and meta-learning. We show that an approximate version of the bilevel problem can be solved by taking into explicit account the optimization dynamics for the inner objective. Depending on the specific setting, the outer variables take either the meaning of hyperparameters in a supervised learning problem or parameters of a meta-learner. We provide sufficient conditions under which solutions of the approximate problem converge to those of the exact problem. We instantiate our approach for meta-learning in the case of deep learning where representation layers are treated as hyperparameters shared across a set of training episodes. In experiments, we confirm our theoretical findings, present encouraging results for few-shot learning and contrast the bilevel approach against classical approaches for learning-to-learn.
Far-HO: A Bilevel Programming Package for Hyperparameter Optimization and Meta-Learning
Jun 13, 2018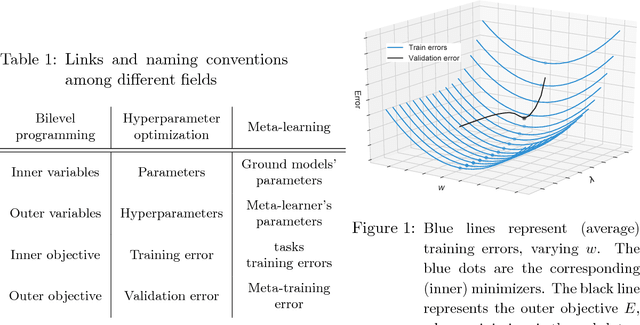
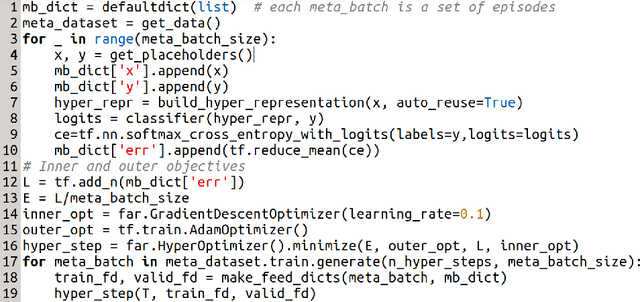
In (Franceschi et al., 2018) we proposed a unified mathematical framework, grounded on bilevel programming, that encompasses gradient-based hyperparameter optimization and meta-learning. We formulated an approximate version of the problem where the inner objective is solved iteratively, and gave sufficient conditions ensuring convergence to the exact problem. In this work we show how to optimize learning rates, automatically weight the loss of single examples and learn hyper-representations with Far-HO, a software package based on the popular deep learning framework TensorFlow that allows to seamlessly tackle both HO and ML problems.
A Bridge Between Hyperparameter Optimization and Larning-to-learn
Feb 04, 2018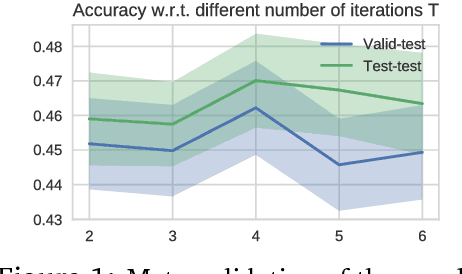
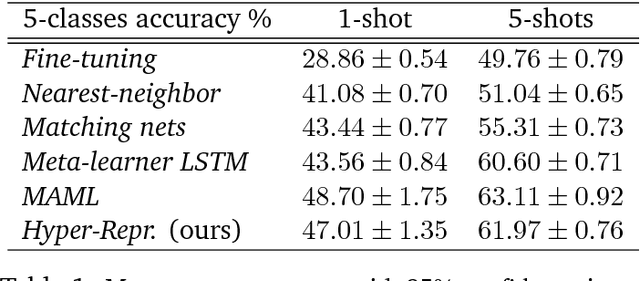
We consider a class of a nested optimization problems involving inner and outer objectives. We observe that by taking into explicit account the optimization dynamics for the inner objective it is possible to derive a general framework that unifies gradient-based hyperparameter optimization and meta-learning (or learning-to-learn). Depending on the specific setting, the variables of the outer objective take either the meaning of hyperparameters in a supervised learning problem or parameters of a meta-learner. We show that some recently proposed methods in the latter setting can be instantiated in our framework and tackled with the same gradient-based algorithms. Finally, we discuss possible design patterns for learning-to-learn and present encouraging preliminary experiments for few-shot learning.
Forward and Reverse Gradient-Based Hyperparameter Optimization
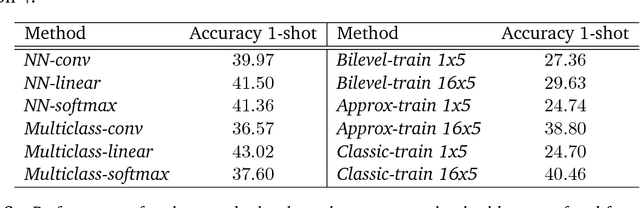
Dec 12, 2017
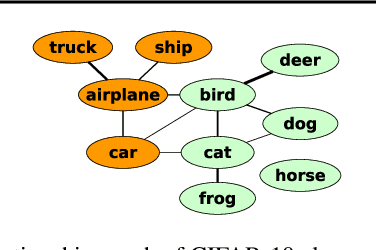
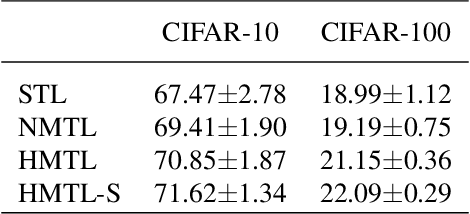
We study two procedures (reverse-mode and forward-mode) for computing the gradient of the validation error with respect to the hyperparameters of any iterative learning algorithm such as stochastic gradient descent. These procedures mirror two methods of computing gradients for recurrent neural networks and have different trade-offs in terms of running time and space requirements. Our formulation of the reverse-mode procedure is linked to previous work by Maclaurin et al. [2015] but does not require reversible dynamics. The forward-mode procedure is suitable for real-time hyperparameter updates, which may significantly speed up hyperparameter optimization on large datasets. We present experiments on data cleaning and on learning task interactions. We also present one large-scale experiment where the use of previous gradient-based methods would be prohibitive.
* - Posted the ICML Camera Ready version. - Added a link to a newer package implementation of the algorithms