 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Dissection: An Unified Understanding for Transformer's Attention via the Lens of Kernel
Aug 30, 2019
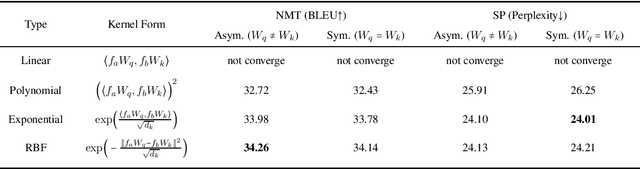

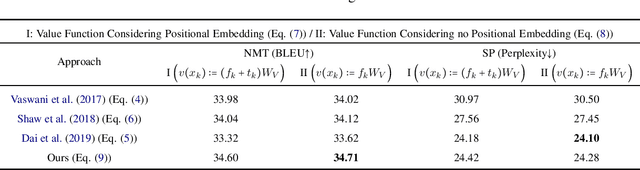
Transformer is a powerful architecture that achieves superior performance on various sequence learning tasks, including neural machine translation, language understanding, and sequence prediction. At the core of the Transformer is the attention mechanism, which concurrently processes all inputs in the streams. In this paper, we present a new formulation of attention via the lens of the kernel. To be more precise, we realize that the attention can be seen as applying kernel smoother over the inputs with the kernel scores being the similarities between inputs. This new formulation gives us a better way to understand individual components of the Transformer's attention, such as the better way to integrate the positional embedding. Another important advantage of our kernel-based formulation is that it paves the way to a larger space of composing Transformer's attention. As an example, we propose a new variant of Transformer's attention which models the input as a product of symmetric kernels. This approach achieves competitive performance to the current state of the art model with less computation. In our experiments, we empirically study different kernel construction strategies on two widely used tasks: neural machine translation and sequence prediction.
M-BERT: Injecting Multimodal Information in the BERT Structure
Aug 15, 2019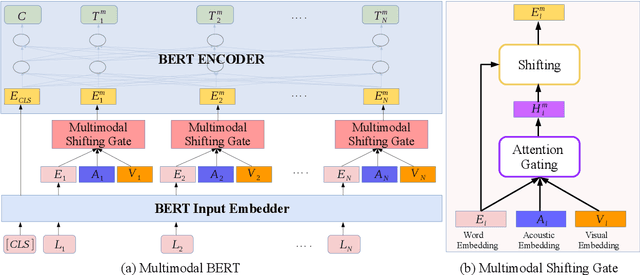
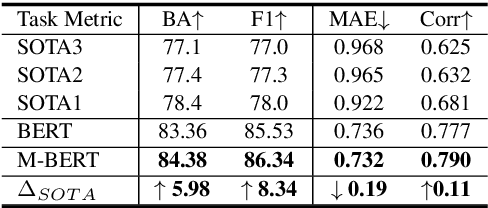
Multimodal language analysis is an emerging research area in natural language processing that models language in a multimodal manner. It aims to understand language from the modalities of text, visual, and acoustic by modeling both intra-modal and cross-modal interactions. BERT (Bidirectional Encoder Representations from Transformers) provides strong contextual language representations after training on large-scale unlabeled corpora. Fine-tuning the vanilla BERT model has shown promising results in building state-of-the-art models for diverse NLP tasks like question answering and language inference. However, fine-tuning BERT in the presence of information from other modalities remains an open research problem. In this paper, we inject multimodal information within the input space of BERT network for modeling multimodal language. The proposed injection method allows BERT to reach a new state of the art of $84.38\%$ binary accuracy on CMU-MOSI dataset (multimodal sentiment analysis) with a gap of 5.98 percent to the previous state of the art and 1.02 percent to the text-only BERT.
Language2Pose: Natural Language Grounded Pose Forecasting
Jul 02, 2019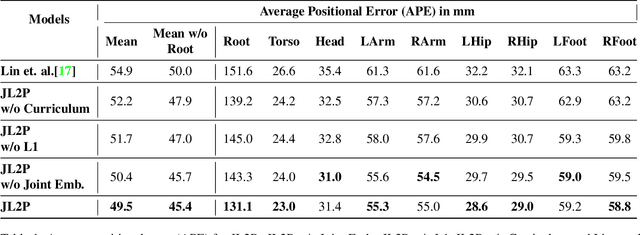
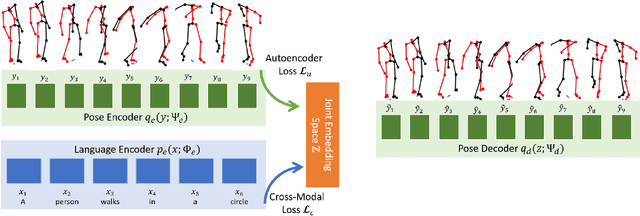
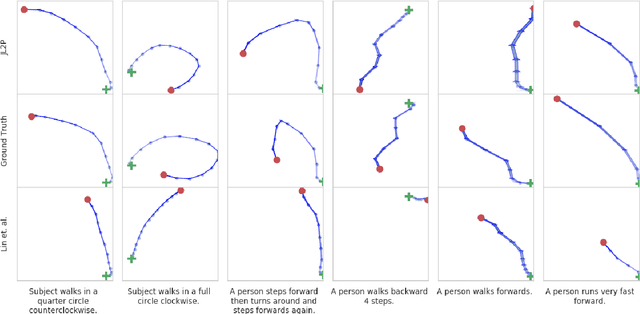
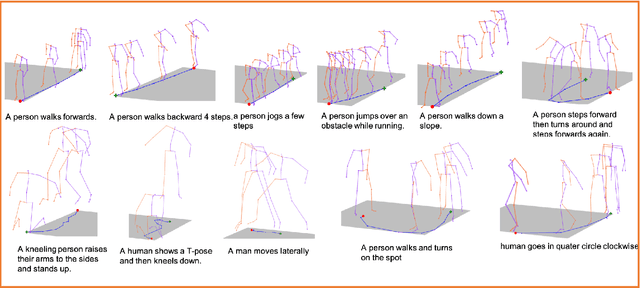
Generating animations from natural language sentences finds its applications in a a number of domains such as movie script visualization, virtual human animation and, robot motion planning. These sentences can describe different kinds of actions, speeds and direction of these actions, and possibly a target destination. The core modeling challenge in this language-to-pose application is how to map linguistic concepts to motion animations. In this paper, we address this multimodal problem by introducing a neural architecture called Joint Language to Pose (or JL2P), which learns a joint embedding of language and pose. This joint embedding space is learned end-to-end using a curriculum learning approach which emphasizes shorter and easier sequences first before moving to longer and harder ones. We evaluate our proposed model on a publicly available corpus of 3D pose data and human-annotated sentences. Both objective metrics and human judgment evaluation confirm that our proposed approach is able to generate more accurate animations and are deemed visually more representative by humans than other data driven approaches.
Learning Representations from Imperfect Time Series Data via Tensor Rank Regularization
Jul 01, 2019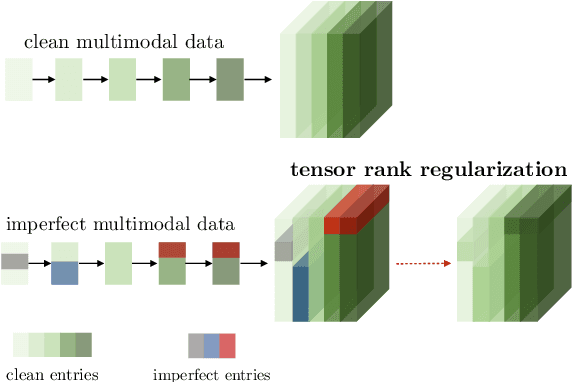
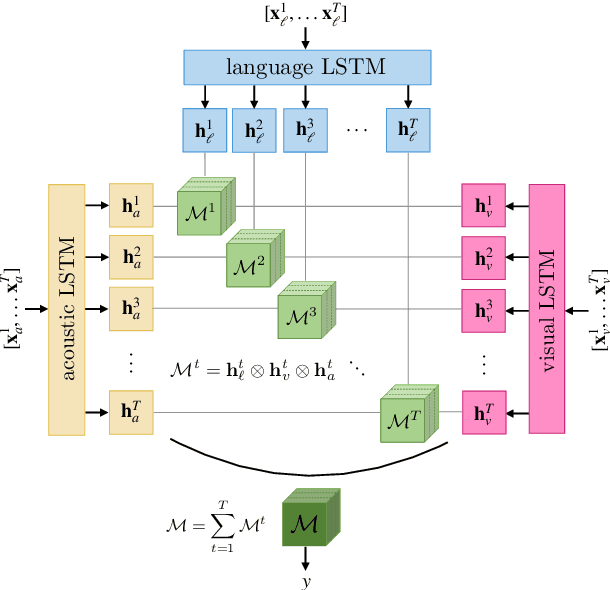
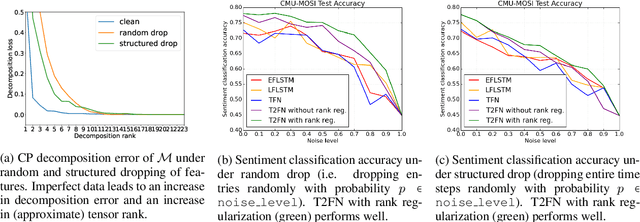
There has been an increased interest in multimodal language processing including multimodal dialog, question answering, sentiment analysis, and speech recognition. However, naturally occurring multimodal data is often imperfect as a result of imperfect modalities, missing entries or noise corruption. To address these concerns, we present a regularization method based on tensor rank minimization. Our method is based on the observation that high-dimensional multimodal time series data often exhibit correlations across time and modalities which leads to low-rank tensor representations. However, the presence of noise or incomplete values breaks these correlations and results in tensor representations of higher rank. We design a model to learn such tensor representations and effectively regularize their rank. Experiments on multimodal language data show that our model achieves good results across various levels of imperfection.
Deep Gamblers: Learning to Abstain with Portfolio Theory
Jun 29, 2019


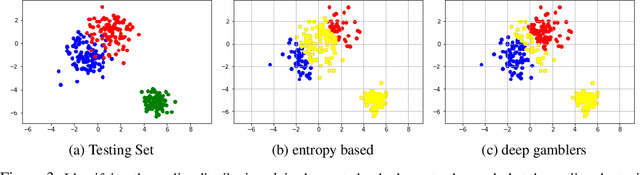
We deal with the \textit{selective classification} problem (supervised-learning problem with a rejection option), where we want to achieve the best performance at a certain level of coverage of the data. We transform the original $m$-class classification problem to $(m+1)$-class where the $(m+1)$-th class represents the model abstaining from making a prediction due to uncertainty. Inspired by portfolio theory, we propose a loss function for the selective classification problem based on the doubling rate of gambling. We show that minimizing this loss function has a natural interpretation as maximizing the return of a \textit{horse race}, where a player aims to balance between betting on an outcome (making a prediction) when confident and reserving one's winnings (abstaining) when not confident. This loss function allows us to train neural networks and characterize the uncertainty of prediction in an end-to-end fashion. In comparison with previous methods, our method requires almost no modification to the model inference algorithm or neural architecture. Experimentally, we show that our method can identify both uncertain and outlier data points, and achieves strong results on SVHN and CIFAR10 at various coverages of the data.
Multimodal Transformer for Unaligned Multimodal Language Sequences
Jun 01, 2019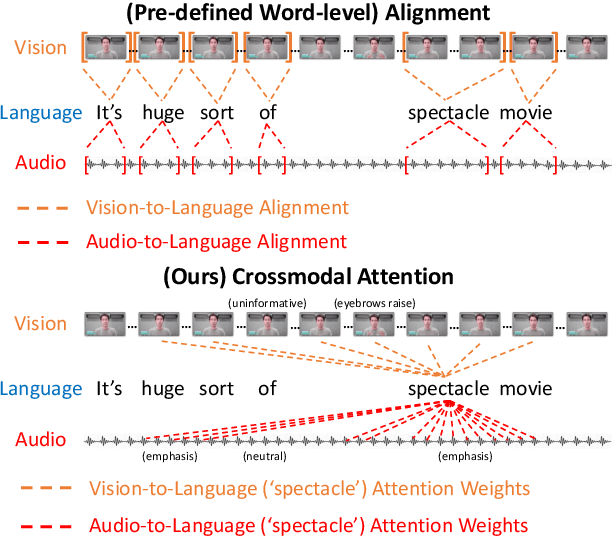
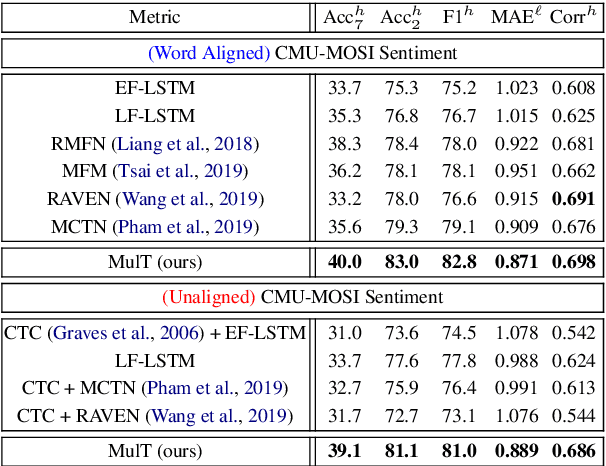
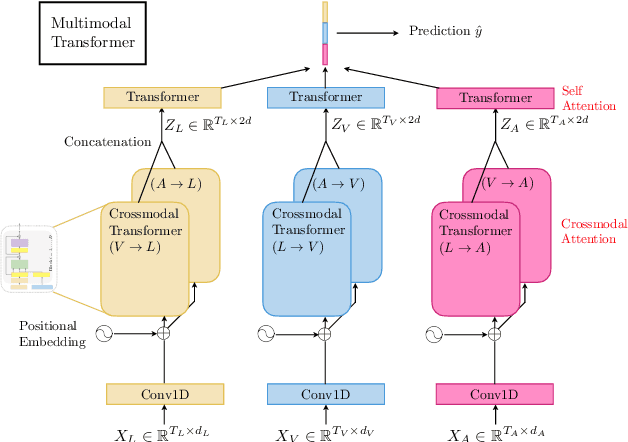
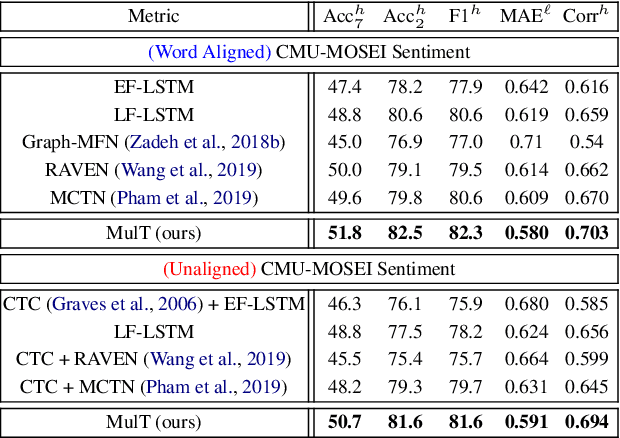
Human language is often multimodal, which comprehends a mixture of natural language, facial gestures, and acoustic behaviors. However, two major challenges in modeling such multimodal human language time-series data exist: 1) inherent data non-alignment due to variable sampling rates for the sequences from each modality; and 2) long-range dependencies between elements across modalities. In this paper, we introduce the Multimodal Transformer (MulT) to generically address the above issues in an end-to-end manner without explicitly aligning the data. At the heart of our model is the directional pairwise crossmodal attention, which attends to interactions between multimodal sequences across distinct time steps and latently adapt streams from one modality to another. Comprehensive experiments on both aligned and non-aligned multimodal time-series show that our model outperforms state-of-the-art methods by a large margin. In addition, empirical analysis suggests that correlated crossmodal signals are able to be captured by the proposed crossmodal attention mechanism in MulT.
Strong and Simple Baselines for Multimodal Utterance Embeddings
May 14, 2019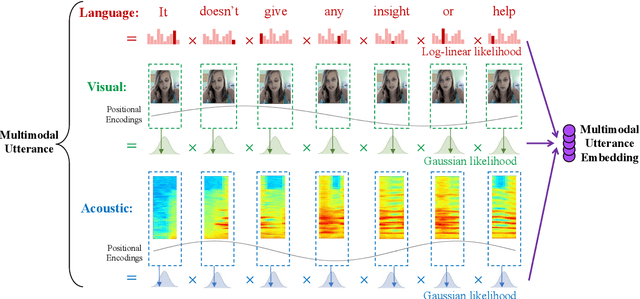
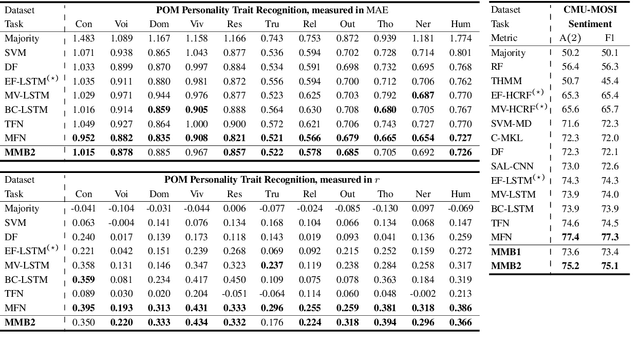
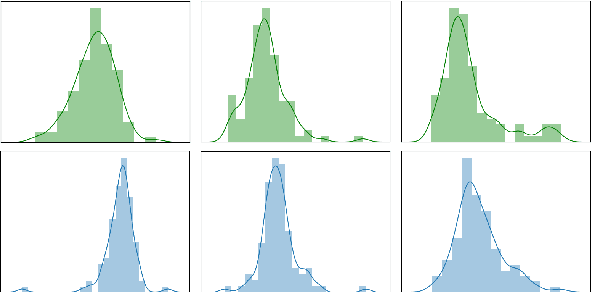
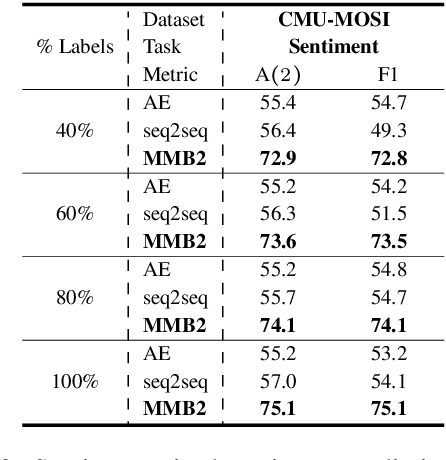
Human language is a rich multimodal signal consisting of spoken words, facial expressions, body gestures, and vocal intonations. Learning representations for these spoken utterances is a complex research problem due to the presence of multiple heterogeneous sources of information. Recent advances in multimodal learning have followed the general trend of building more complex models that utilize various attention, memory and recurrent components. In this paper, we propose two simple but strong baselines to learn embeddings of multimodal utterances. The first baseline assumes a conditional factorization of the utterance into unimodal factors. Each unimodal factor is modeled using the simple form of a likelihood function obtained via a linear transformation of the embedding. We show that the optimal embedding can be derived in closed form by taking a weighted average of the unimodal features. In order to capture richer representations, our second baseline extends the first by factorizing into unimodal, bimodal, and trimodal factors, while retaining simplicity and efficiency during learning and inference. From a set of experiments across two tasks, we show strong performance on both supervised and semi-supervised multimodal prediction, as well as significant (10 times) speedups over neural models during inference. Overall, we believe that our strong baseline models offer new benchmarking options for future research in multimodal learning.
UR-FUNNY: A Multimodal Language Dataset for Understanding Humor
Apr 14, 2019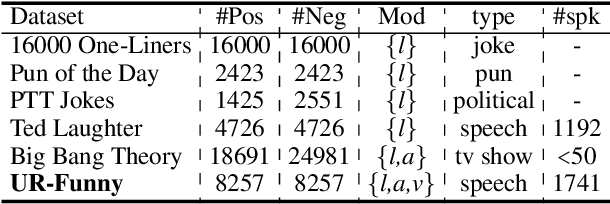
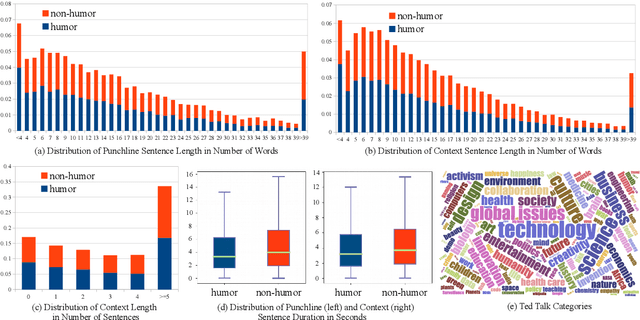
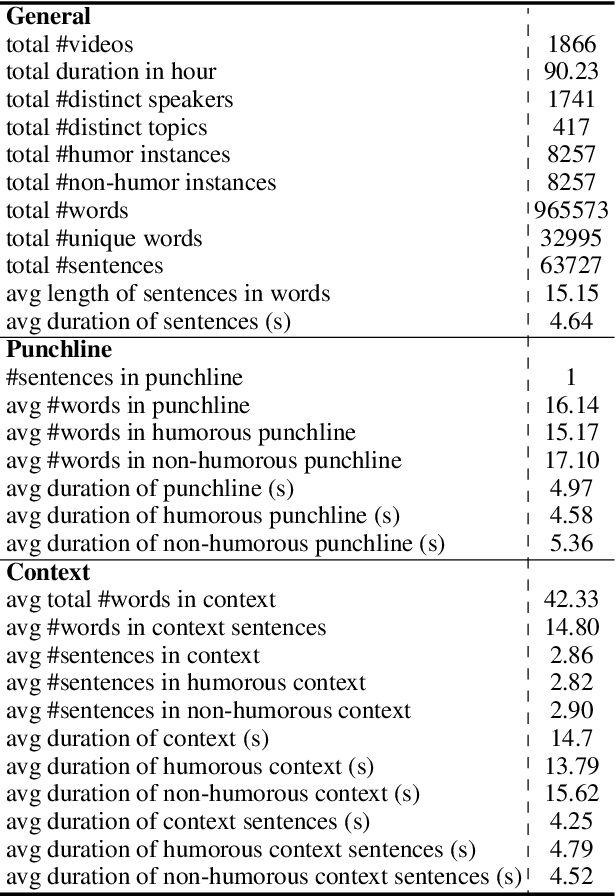
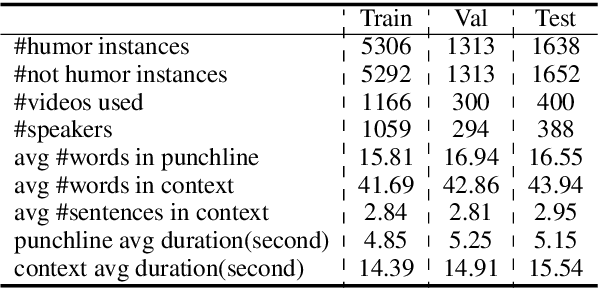
Humor is a unique and creative communicative behavior displayed during social interactions. It is produced in a multimodal manner, through the usage of words (text), gestures (vision) and prosodic cues (acoustic). Understanding humor from these three modalities falls within boundaries of multimodal language; a recent research trend in natural language processing that models natural language as it happens in face-to-face communication. Although humor detection is an established research area in NLP, in a multimodal context it is an understudied area. This paper presents a diverse multimodal dataset, called UR-FUNNY, to open the door to understanding multimodal language used in expressing humor. The dataset and accompanying studies, present a framework in multimodal humor detection for the natural language processing community. UR-FUNNY is publicly available for research.
Variational Auto-Decoder
Apr 03, 2019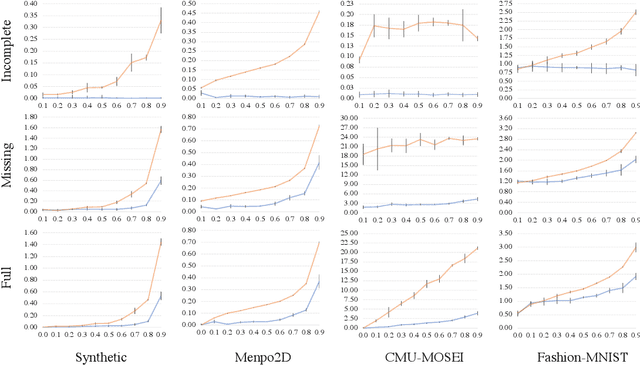
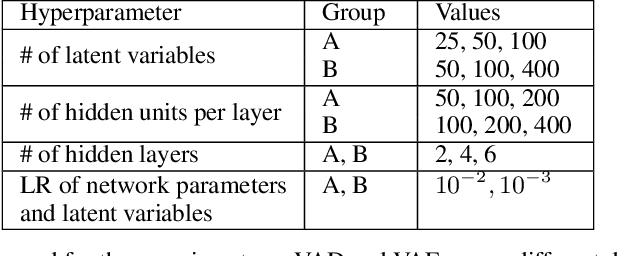
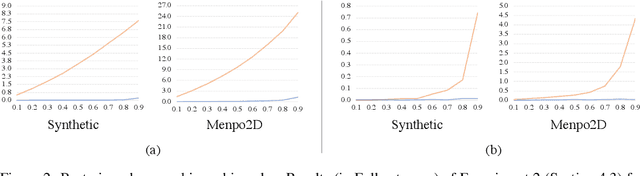
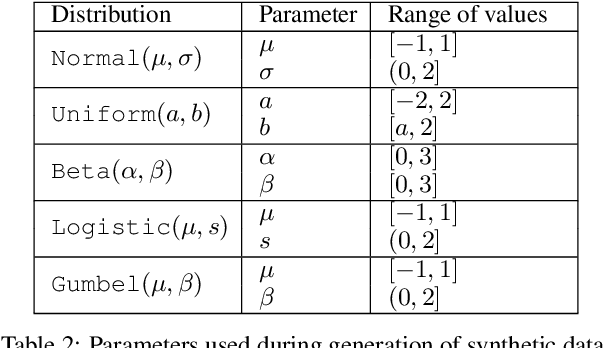
Learning a generative model from partial data (data with missingness) is a challenging area of machine learning research. We study a specific implementation of the Auto-Encoding Variational Bayes (AEVB) algorithm, named in this paper as a Variational Auto-Decoder (VAD). VAD is a generic framework which uses Variational Bayes and Markov Chain Monte Carlo (MCMC) methods to learn a generative model from partial data. The main distinction between VAD and Variational Auto-Encoder (VAE) is the encoder component, as VAD does not have one. Using a proposed efficient inference method from a multivariate Gaussian approximate posterior, VAD models allow inference to be performed via simple gradient ascent rather than MCMC sampling from a probabilistic decoder. This technique reduces the inference computational cost, allows for using more complex optimization techniques during latent space inference (which are shown to be crucial due to a high degree of freedom in the VAD latent space), and keeps the framework simple to implement. Through extensive experiments over several datasets and different missing ratios, we show that encoders cannot efficiently marginalize the input volatility caused by imputed missing values. We study multimodal datasets in this paper, which is a particular area of impact for VAD models.
Video Relationship Reasoning using Gated Spatio-Temporal Energy Graph
Mar 27, 2019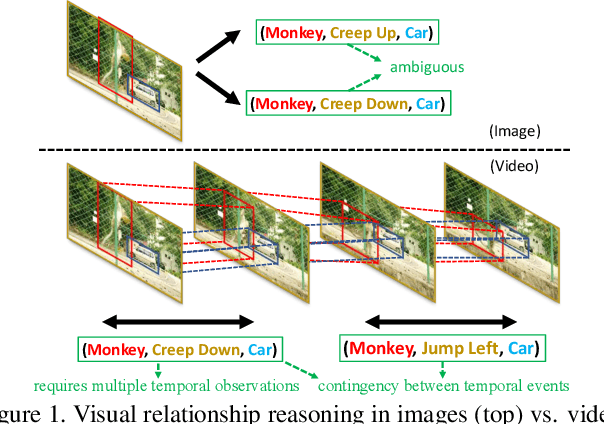
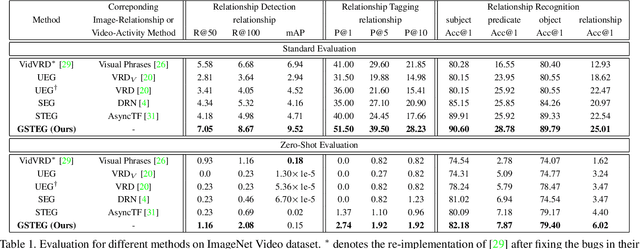
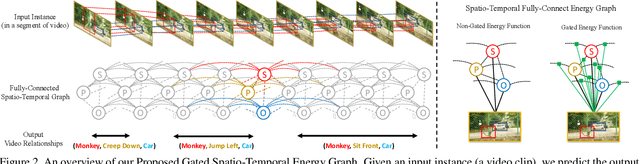
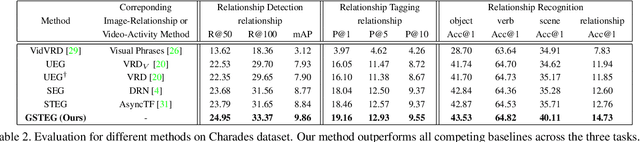
Visual relationship reasoning is a crucial yet challenging task for understanding rich interactions across visual concepts. For example, a relationship 'man, open, door' involves a complex relation 'open' between concrete entities 'man, door'. While much of the existing work has studied this problem in the context of still images, understanding visual relationships in videos has received limited attention. Due to their temporal nature, videos enable us to model and reason about a more comprehensive set of visual relationships, such as those requiring multiple (temporal) observations (e.g., 'man, lift up, box' vs. 'man, put down, box'), as well as relationships that are often correlated through time (e.g., 'woman, pay, money' followed by 'woman, buy, coffee'). In this paper, we construct a Conditional Random Field on a fully-connected spatio-temporal graph that exploits the statistical dependency between relational entities spatially and temporally. We introduce a novel gated energy function parametrization that learns adaptive relations conditioned on visual observations. Our model optimization is computationally efficient, and its space computation complexity is significantly amortized through our proposed parameterization. Experimental results on benchmark video datasets (ImageNet Video and Charades) demonstrate state-of-the-art performance across three standard relationship reasoning tasks: Detection, Tagging, and Recognition.