 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn ML-based Approach to Predicting Software Change Dependencies: Insights from an Empirical Study on OpenStack
Aug 07, 2025



As software systems grow in complexity, accurately identifying and managing dependencies among changes becomes increasingly critical. For instance, a change that leverages a function must depend on the change that introduces it. Establishing such dependencies allows CI/CD pipelines to build and orchestrate changes effectively, preventing build failures and incomplete feature deployments. In modern software systems, dependencies often span multiple components across teams, creating challenges for development and deployment. They serve various purposes, from enabling new features to managing configurations, and can even involve traditionally independent changes like documentation updates. To address these challenges, we conducted a preliminary study on dependency management in OpenStack, a large-scale software system. Our study revealed that a substantial portion of software changes in OpenStack over the past 10 years are interdependent. Surprisingly, 51.08% of these dependencies are identified during the code review phase-after a median delay of 5.06 hours-rather than at the time of change creation. Developers often spend a median of 57.12 hours identifying dependencies, searching among a median of 463 other changes. To help developers proactively identify dependencies, we propose a semi-automated approach that leverages two ML models. The first model predicts the likelihood of dependencies among changes, while the second identifies the exact pairs of dependent changes. Our proposed models demonstrate strong performance, achieving average AUC scores of 79.33% and 91.89%, and Brier scores of 0.11 and 0.014, respectively. Indeed, the second model has a good top-k recall across all types of pairs, while the top-k precision has room for improvement.
UR-FUNNY: A Multimodal Language Dataset for Understanding Humor
Apr 14, 2019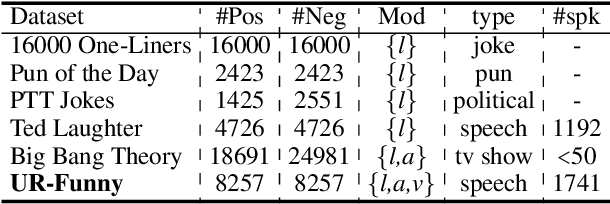
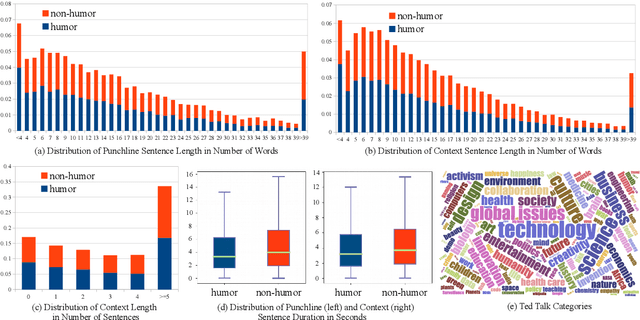
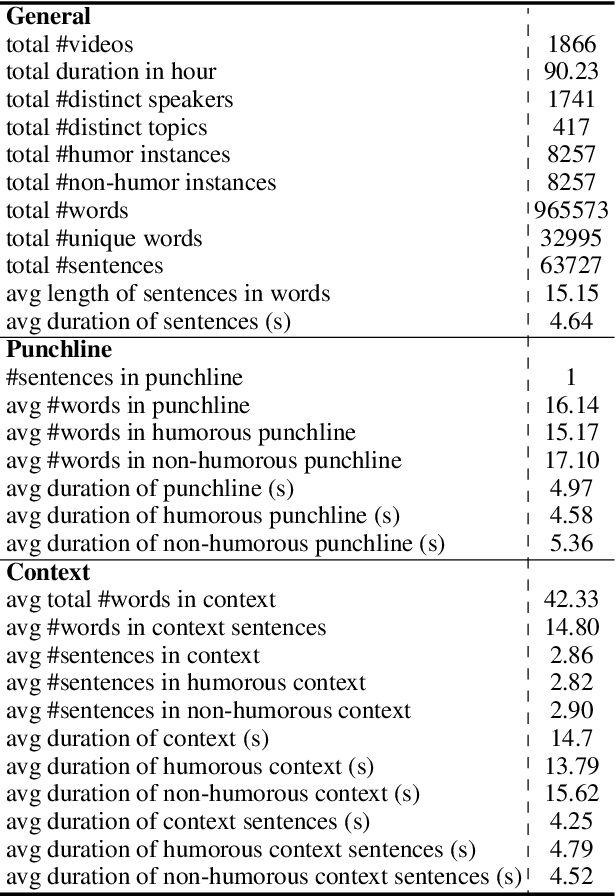
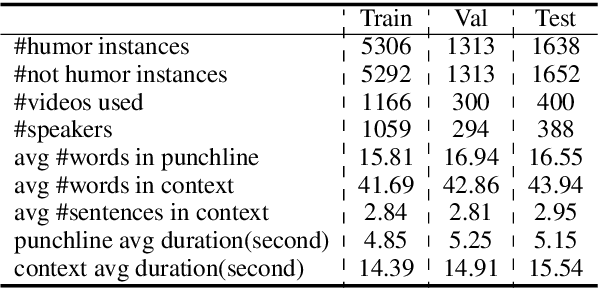
Humor is a unique and creative communicative behavior displayed during social interactions. It is produced in a multimodal manner, through the usage of words (text), gestures (vision) and prosodic cues (acoustic). Understanding humor from these three modalities falls within boundaries of multimodal language; a recent research trend in natural language processing that models natural language as it happens in face-to-face communication. Although humor detection is an established research area in NLP, in a multimodal context it is an understudied area. This paper presents a diverse multimodal dataset, called UR-FUNNY, to open the door to understanding multimodal language used in expressing humor. The dataset and accompanying studies, present a framework in multimodal humor detection for the natural language processing community. UR-FUNNY is publicly available for research.
Automated Analysis and Prediction of Job Interview Performance
Apr 14, 2015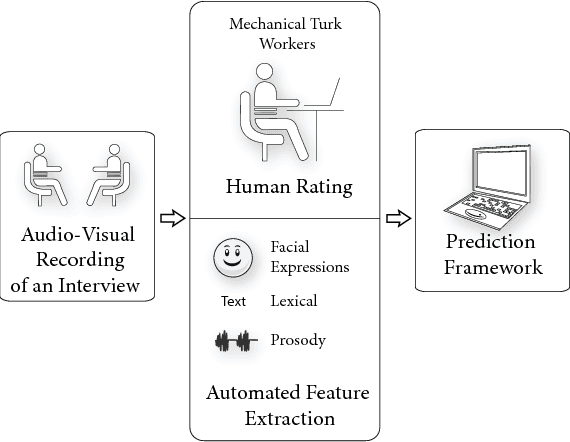
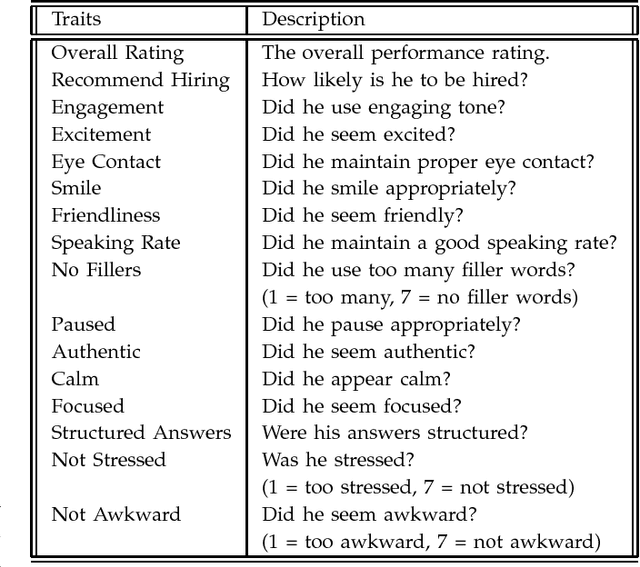


We present a computational framework for automatically quantifying verbal and nonverbal behaviors in the context of job interviews. The proposed framework is trained by analyzing the videos of 138 interview sessions with 69 internship-seeking undergraduates at the Massachusetts Institute of Technology (MIT). Our automated analysis includes facial expressions (e.g., smiles, head gestures, facial tracking points), language (e.g., word counts, topic modeling), and prosodic information (e.g., pitch, intonation, and pauses) of the interviewees. The ground truth labels are derived by taking a weighted average over the ratings of 9 independent judges. Our framework can automatically predict the ratings for interview traits such as excitement, friendliness, and engagement with correlation coefficients of 0.75 or higher, and can quantify the relative importance of prosody, language, and facial expressions. By analyzing the relative feature weights learned by the regression models, our framework recommends to speak more fluently, use less filler words, speak as "we" (vs. "I"), use more unique words, and smile more. We also find that the students who were rated highly while answering the first interview question were also rated highly overall (i.e., first impression matters). Finally, our MIT Interview dataset will be made available to other researchers to further validate and expand our findings.