 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Word Embeddings to New Languages with Morphological and Phonological Subword Representations
Aug 28, 2018
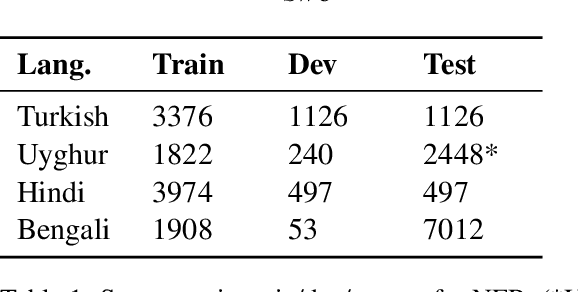
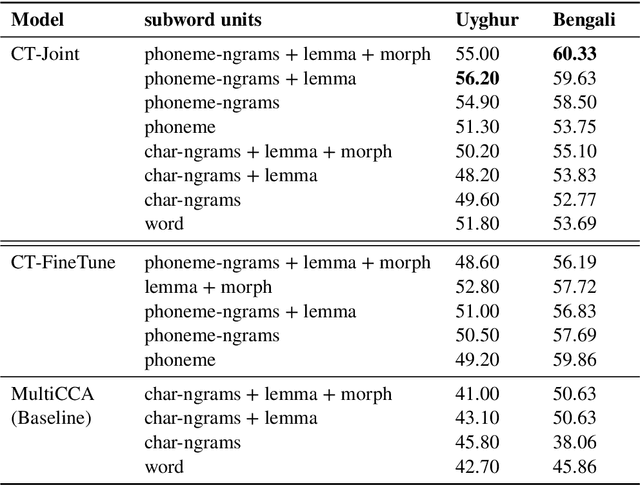
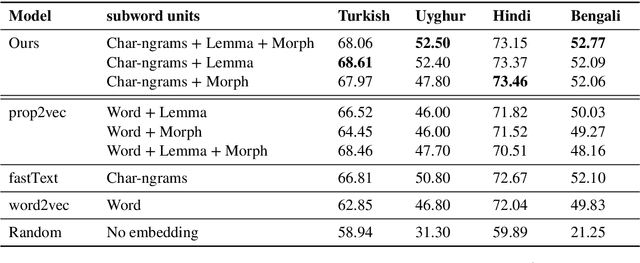
Much work in Natural Language Processing (NLP) has been for resource-rich languages, making generalization to new, less-resourced languages challenging. We present two approaches for improving generalization to low-resourced languages by adapting continuous word representations using linguistically motivated subword units: phonemes, morphemes and graphemes. Our method requires neither parallel corpora nor bilingual dictionaries and provides a significant gain in performance over previous methods relying on these resources. We demonstrate the effectiveness of our approaches on Named Entity Recognition for four languages, namely Uyghur, Turkish, Bengali and Hindi, of which Uyghur and Bengali are low resource languages, and also perform experiments on Machine Translation. Exploiting subwords with transfer learning gives us a boost of +15.2 NER F1 for Uyghur and +9.7 F1 for Bengali. We also show improvements in the monolingual setting where we achieve (avg.) +3 F1 and (avg.) +1.35 BLEU.
Polyglot Neural Language Models: A Case Study in Cross-Lingual Phonetic Representation Learning
May 12, 2016



We introduce polyglot language models, recurrent neural network models trained to predict symbol sequences in many different languages using shared representations of symbols and conditioning on typological information about the language to be predicted. We apply these to the problem of modeling phone sequences---a domain in which universal symbol inventories and cross-linguistically shared feature representations are a natural fit. Intrinsic evaluation on held-out perplexity, qualitative analysis of the learned representations, and extrinsic evaluation in two downstream applications that make use of phonetic features show (i) that polyglot models better generalize to held-out data than comparable monolingual models and (ii) that polyglot phonetic feature representations are of higher quality than those learned monolingually.
Unsupervised POS Induction with Word Embeddings
Mar 23, 2015
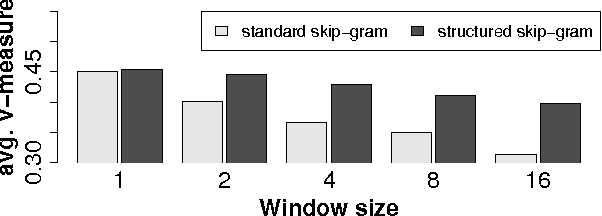
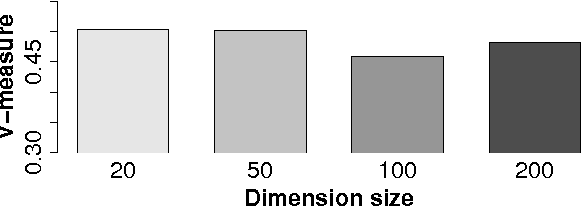
Unsupervised word embeddings have been shown to be valuable as features in supervised learning problems; however, their role in unsupervised problems has been less thoroughly explored. In this paper, we show that embeddings can likewise add value to the problem of unsupervised POS induction. In two representative models of POS induction, we replace multinomial distributions over the vocabulary with multivariate Gaussian distributions over word embeddings and observe consistent improvements in eight languages. We also analyze the effect of various choices while inducing word embeddings on "downstream" POS induction results.
Statistical modality tagging from rule-based annotations and crowdsourcing
Mar 04, 2015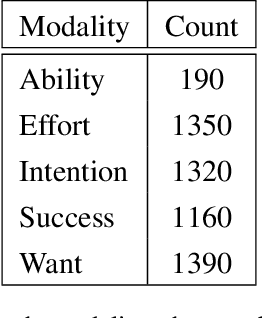
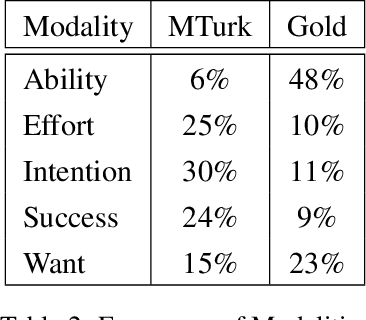
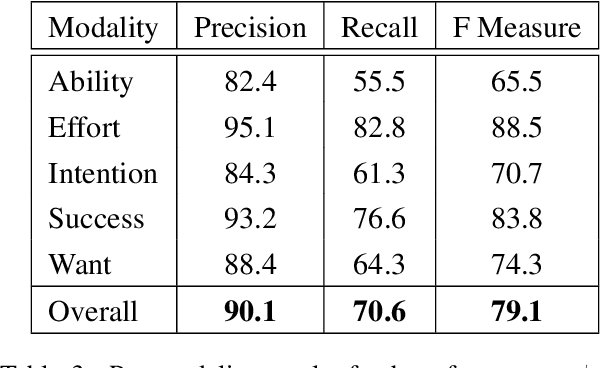
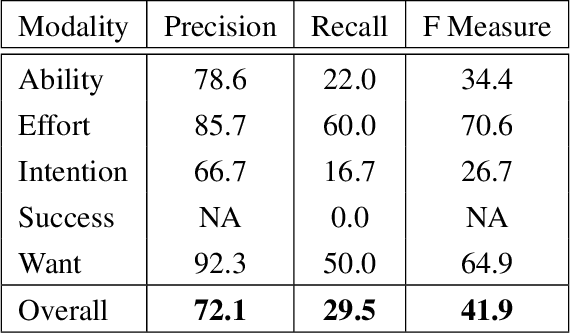
We explore training an automatic modality tagger. Modality is the attitude that a speaker might have toward an event or state. One of the main hurdles for training a linguistic tagger is gathering training data. This is particularly problematic for training a tagger for modality because modality triggers are sparse for the overwhelming majority of sentences. We investigate an approach to automatically training a modality tagger where we first gathered sentences based on a high-recall simple rule-based modality tagger and then provided these sentences to Mechanical Turk annotators for further annotation. We used the resulting set of training data to train a precise modality tagger using a multi-class SVM that delivers good performance.
* 8 pages, 6 tables; appeared in Proceedings of the Workshop on Extra-Propositional Aspects of Meaning in Computational Linguistics, July 2012; In Proceedings of the Workshop on Extra-Propositional Aspects of Meaning in Computational Linguistics, pages 57-64, Jeju, Republic of Korea, July 2012. Association for Computational Linguistics
Use of Modality and Negation in Semantically-Informed Syntactic MT
Feb 05, 2015This paper describes the resource- and system-building efforts of an eight-week Johns Hopkins University Human Language Technology Center of Excellence Summer Camp for Applied Language Exploration (SCALE-2009) on Semantically-Informed Machine Translation (SIMT). We describe a new modality/negation (MN) annotation scheme, the creation of a (publicly available) MN lexicon, and two automated MN taggers that we built using the annotation scheme and lexicon. Our annotation scheme isolates three components of modality and negation: a trigger (a word that conveys modality or negation), a target (an action associated with modality or negation) and a holder (an experiencer of modality). We describe how our MN lexicon was semi-automatically produced and we demonstrate that a structure-based MN tagger results in precision around 86% (depending on genre) for tagging of a standard LDC data set. We apply our MN annotation scheme to statistical machine translation using a syntactic framework that supports the inclusion of semantic annotations. Syntactic tags enriched with semantic annotations are assigned to parse trees in the target-language training texts through a process of tree grafting. While the focus of our work is modality and negation, the tree grafting procedure is general and supports other types of semantic information. We exploit this capability by including named entities, produced by a pre-existing tagger, in addition to the MN elements produced by the taggers described in this paper. The resulting system significantly outperformed a linguistically naive baseline model (Hiero), and reached the highest scores yet reported on the NIST 2009 Urdu-English test set. This finding supports the hypothesis that both syntactic and semantic information can improve translation quality.
* 28 pages, 13 figures, 2 tables; appeared in Computational Linguistics, 38(2):411-438, 2012
A Modality Lexicon and its use in Automatic Tagging
Oct 17, 2014

This paper describes our resource-building results for an eight-week JHU Human Language Technology Center of Excellence Summer Camp for Applied Language Exploration (SCALE-2009) on Semantically-Informed Machine Translation. Specifically, we describe the construction of a modality annotation scheme, a modality lexicon, and two automated modality taggers that were built using the lexicon and annotation scheme. Our annotation scheme is based on identifying three components of modality: a trigger, a target and a holder. We describe how our modality lexicon was produced semi-automatically, expanding from an initial hand-selected list of modality trigger words and phrases. The resulting expanded modality lexicon is being made publicly available. We demonstrate that one tagger---a structure-based tagger---results in precision around 86% (depending on genre) for tagging of a standard LDC data set. In a machine translation application, using the structure-based tagger to annotate English modalities on an English-Urdu training corpus improved the translation quality score for Urdu by 0.3 Bleu points in the face of sparse training data.
* 6 pages, 5 figures; appeared in Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC'10), May 2010
Semantically-Informed Syntactic Machine Translation: A Tree-Grafting Approach
Sep 24, 2014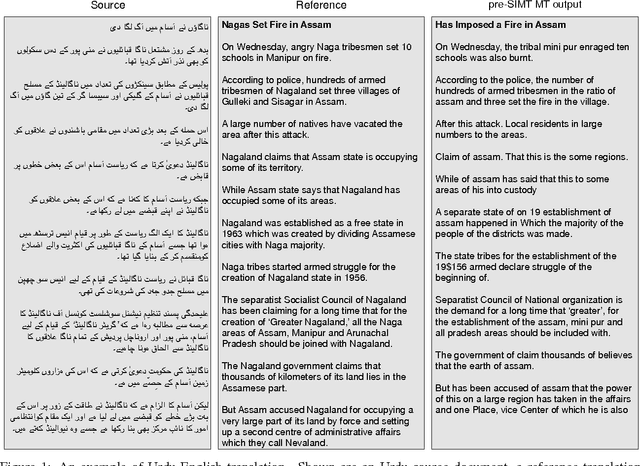
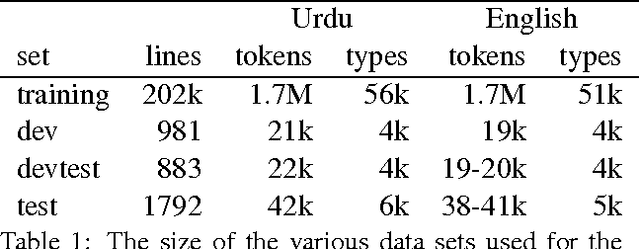
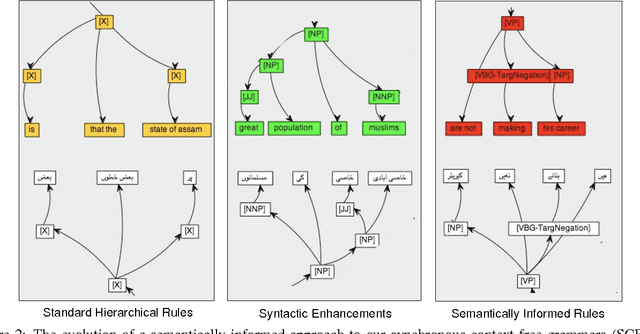

We describe a unified and coherent syntactic framework for supporting a semantically-informed syntactic approach to statistical machine translation. Semantically enriched syntactic tags assigned to the target-language training texts improved translation quality. The resulting system significantly outperformed a linguistically naive baseline model (Hiero), and reached the highest scores yet reported on the NIST 2009 Urdu-English translation task. This finding supports the hypothesis (posed by many researchers in the MT community, e.g., in DARPA GALE) that both syntactic and semantic information are critical for improving translation quality---and further demonstrates that large gains can be achieved for low-resource languages with different word order than English.
* 10 pages, 7 figures, 3 tables; appeared in Proceedings of the Ninth Conference of the Association for Machine Translation in the Americas (AMTA), October 2010