 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAST: A Dual-tier Few-Shot Learning Paradigm for Whole Slide Image Classification
Sep 29, 2024



The expensive fine-grained annotation and data scarcity have become the primary obstacles for the widespread adoption of deep learning-based Whole Slide Images (WSI) classification algorithms in clinical practice. Unlike few-shot learning methods in natural images that can leverage the labels of each image, existing few-shot WSI classification methods only utilize a small number of fine-grained labels or weakly supervised slide labels for training in order to avoid expensive fine-grained annotation. They lack sufficient mining of available WSIs, severely limiting WSI classification performance. To address the above issues, we propose a novel and efficient dual-tier few-shot learning paradigm for WSI classification, named FAST. FAST consists of a dual-level annotation strategy and a dual-branch classification framework. Firstly, to avoid expensive fine-grained annotation, we collect a very small number of WSIs at the slide level, and annotate an extremely small number of patches. Then, to fully mining the available WSIs, we use all the patches and available patch labels to build a cache branch, which utilizes the labeled patches to learn the labels of unlabeled patches and through knowledge retrieval for patch classification. In addition to the cache branch, we also construct a prior branch that includes learnable prompt vectors, using the text encoder of visual-language models for patch classification. Finally, we integrate the results from both branches to achieve WSI classification. Extensive experiments on binary and multi-class datasets demonstrate that our proposed method significantly surpasses existing few-shot classification methods and approaches the accuracy of fully supervised methods with only 0.22$\%$ annotation costs. All codes and models will be publicly available on https://github.com/fukexue/FAST.
Data and Model Poisoning Backdoor Attacks on Wireless Federated Learning, and the Defense Mechanisms: A Comprehensive Survey
Dec 14, 2023



Due to the greatly improved capabilities of devices, massive data, and increasing concern about data privacy, Federated Learning (FL) has been increasingly considered for applications to wireless communication networks (WCNs). Wireless FL (WFL) is a distributed method of training a global deep learning model in which a large number of participants each train a local model on their training datasets and then upload the local model updates to a central server. However, in general, non-independent and identically distributed (non-IID) data of WCNs raises concerns about robustness, as a malicious participant could potentially inject a "backdoor" into the global model by uploading poisoned data or models over WCN. This could cause the model to misclassify malicious inputs as a specific target class while behaving normally with benign inputs. This survey provides a comprehensive review of the latest backdoor attacks and defense mechanisms. It classifies them according to their targets (data poisoning or model poisoning), the attack phase (local data collection, training, or aggregation), and defense stage (local training, before aggregation, during aggregation, or after aggregation). The strengths and limitations of existing attack strategies and defense mechanisms are analyzed in detail. Comparisons of existing attack methods and defense designs are carried out, pointing to noteworthy findings, open challenges, and potential future research directions related to security and privacy of WFL.
Learning to Learn for Few-shot Continual Active Learning
Nov 07, 2023



Continual learning strives to ensure stability in solving previously seen tasks while demonstrating plasticity in a novel domain. Recent advances in CL are mostly confined to a supervised learning setting, especially in NLP domain. In this work, we consider a few-shot continual active learning (CAL) setting where labeled data is inadequate, and unlabeled data is abundant but with a limited annotation budget. We propose a simple but efficient method, called Meta-Continual Active Learning. Specifically, we employ meta-learning and experience replay to address the trade-off between stability and plasticity. As a result, it finds an optimal initialization that efficiently utilizes annotated information for fast adaptation while preventing catastrophic forgetting of past tasks. We conduct extensive experiments to validate the effectiveness of the proposed method and analyze the effect of various active learning strategies and memory sample selection methods in a few-shot CAL setup. Our experiment results demonstrate that random sampling is the best default strategy for both active learning and memory sample selection to solve few-shot CAL problems.
Trustworthy Sensor Fusion against Inaudible Command Attacks in Advanced Driver-Assistance System
May 30, 2023



There are increasing concerns about malicious attacks on autonomous vehicles. In particular, inaudible voice command attacks pose a significant threat as voice commands become available in autonomous driving systems. How to empirically defend against these inaudible attacks remains an open question. Previous research investigates utilizing deep learning-based multimodal fusion for defense, without considering the model uncertainty in trustworthiness. As deep learning has been applied to increasingly sensitive tasks, uncertainty measurement is crucial in helping improve model robustness, especially in mission-critical scenarios. In this paper, we propose the Multimodal Fusion Framework (MFF) as an intelligent security system to defend against inaudible voice command attacks. MFF fuses heterogeneous audio-vision modalities using VGG family neural networks and achieves the detection accuracy of 92.25% in the comparative fusion method empirical study. Additionally, extensive experiments on audio-vision tasks reveal the model's uncertainty. Using Expected Calibration Errors, we measure calibration errors and Monte-Carlo Dropout to estimate the predictive distribution for the proposed models. Our findings show empirically to train robust multimodal models, improve standard accuracy and provide a further step toward interpretability. Finally, we discuss the pros and cons of our approach and its applicability for Advanced Driver Assistance Systems.
From Wide to Deep: Dimension Lifting Network for Parameter-efficient Knowledge Graph Embedding
Mar 22, 2023



Knowledge graph embedding (KGE) that maps entities and relations into vector representations is essential for downstream tasks. Conventional KGE methods require relatively high-dimensional entity representations to preserve the structural information of knowledge graph, but lead to oversized model parameters. Recent methods reduce model parameters by adopting low-dimensional entity representations, while developing techniques (e.g., knowledge distillation) to compensate for the reduced dimension. However, such operations produce degraded model accuracy and limited reduction of model parameters. Specifically, we view the concatenation of all entity representations as an embedding layer, and then conventional KGE methods that adopt high-dimensional entity representations equal to enlarging the width of the embedding layer to gain expressiveness. To achieve parameter efficiency without sacrificing accuracy, we instead increase the depth and propose a deeper embedding network for entity representations, i.e., a narrow embedding layer and a multi-layer dimension lifting network (LiftNet). Experiments on three public datasets show that the proposed method (implemented based on TransE and DistMult) with 4-dimensional entity representations achieves more accurate link prediction results than counterpart parameter-efficient KGE methods and strong KGE baselines, including TransE and DistMult with 512-dimensional entity representations.
Hybrid Variational Autoencoder for Time Series Forecasting
Mar 13, 2023



Variational autoencoders (VAE) are powerful generative models that learn the latent representations of input data as random variables. Recent studies show that VAE can flexibly learn the complex temporal dynamics of time series and achieve more promising forecasting results than deterministic models. However, a major limitation of existing works is that they fail to jointly learn the local patterns (e.g., seasonality and trend) and temporal dynamics of time series for forecasting. Accordingly, we propose a novel hybrid variational autoencoder (HyVAE) to integrate the learning of local patterns and temporal dynamics by variational inference for time series forecasting. Experimental results on four real-world datasets show that the proposed HyVAE achieves better forecasting results than various counterpart methods, as well as two HyVAE variants that only learn the local patterns or temporal dynamics of time series, respectively.
An Efficient and Reliable Asynchronous Federated Learning Scheme for Smart Public Transportation
Aug 30, 2022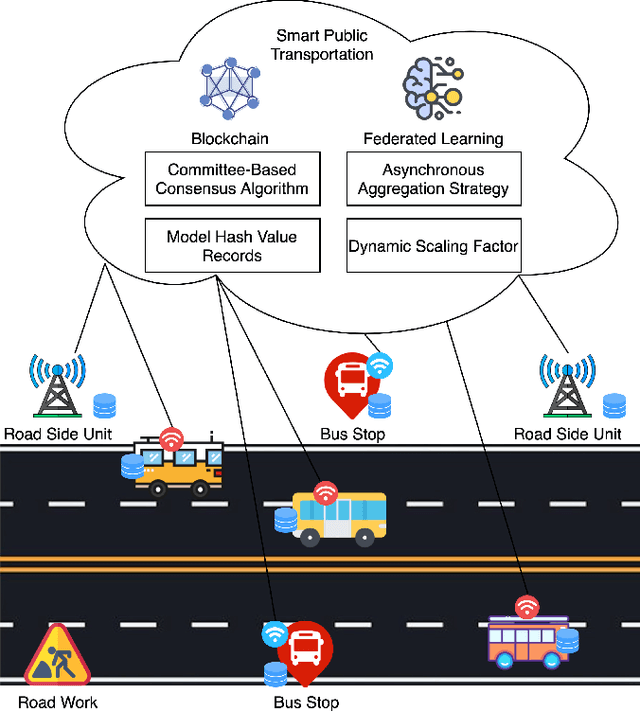
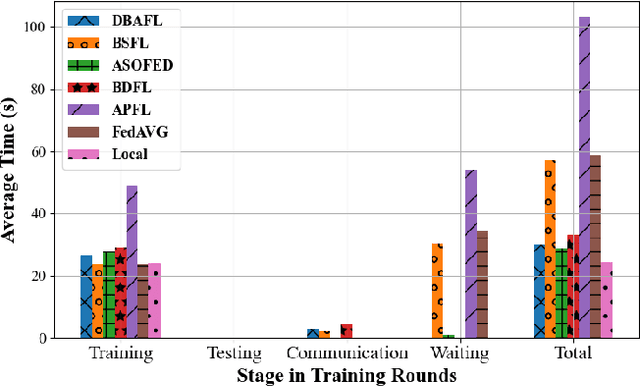
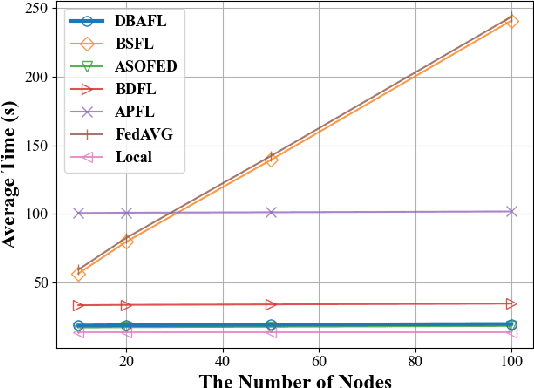
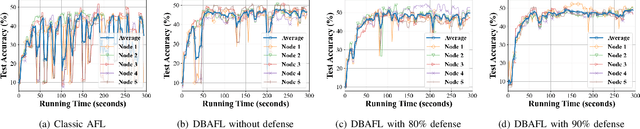
Since the traffic conditions change over time, machine learning models that predict traffic flows must be updated continuously and efficiently in smart public transportation. Federated learning (FL) is a distributed machine learning scheme that allows buses to receive model updates without waiting for model training on the cloud. However, FL is vulnerable to poisoning or DDoS attacks since buses travel in public. Some work introduces blockchain to improve reliability, but the additional latency from the consensus process reduces the efficiency of FL. Asynchronous Federated Learning (AFL) is a scheme that reduces the latency of aggregation to improve efficiency, but the learning performance is unstable due to unreasonably weighted local models. To address the above challenges, this paper offers a blockchain-based asynchronous federated learning scheme with a dynamic scaling factor (DBAFL). Specifically, the novel committee-based consensus algorithm for blockchain improves reliability at the lowest possible cost of time. Meanwhile, the devised dynamic scaling factor allows AFL to assign reasonable weights to stale local models. Extensive experiments conducted on heterogeneous devices validate outperformed learning performance, efficiency, and reliability of DBAFL.
Attention Distraction: Watermark Removal Through Continual Learning with Selective Forgetting
Apr 05, 2022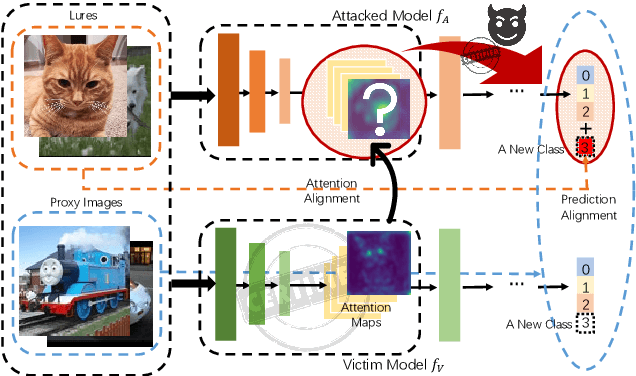
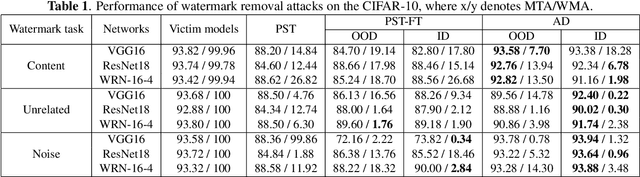
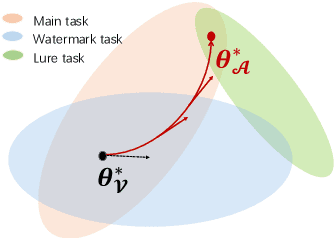

Fine-tuning attacks are effective in removing the embedded watermarks in deep learning models. However, when the source data is unavailable, it is challenging to just erase the watermark without jeopardizing the model performance. In this context, we introduce Attention Distraction (AD), a novel source data-free watermark removal attack, to make the model selectively forget the embedded watermarks by customizing continual learning. In particular, AD first anchors the model's attention on the main task using some unlabeled data. Then, through continual learning, a small number of \textit{lures} (randomly selected natural images) that are assigned a new label distract the model's attention away from the watermarks. Experimental results from different datasets and networks corroborate that AD can thoroughly remove the watermark with a small resource budget without compromising the model's performance on the main task, which outperforms the state-of-the-art works.
Temporal Knowledge Graph Completion: A Survey
Jan 16, 2022
Knowledge graph completion (KGC) can predict missing links and is crucial for real-world knowledge graphs, which widely suffer from incompleteness. KGC methods assume a knowledge graph is static, but that may lead to inaccurate prediction results because many facts in the knowledge graphs change over time. Recently, emerging methods have shown improved predictive results by further incorporating the timestamps of facts; namely, temporal knowledge graph completion (TKGC). With this temporal information, TKGC methods can learn the dynamic evolution of the knowledge graph that KGC methods fail to capture. In this paper, for the first time, we summarize the recent advances in TKGC research. First, we detail the background of TKGC, including the problem definition, benchmark datasets, and evaluation metrics. Then, we summarize existing TKGC methods based on how timestamps of facts are used to capture the temporal dynamics. Finally, we conclude the paper and present future research directions of TKGC.
Learning Based Task Offloading in Digital Twin Empowered Internet of Vehicles
Dec 28, 2021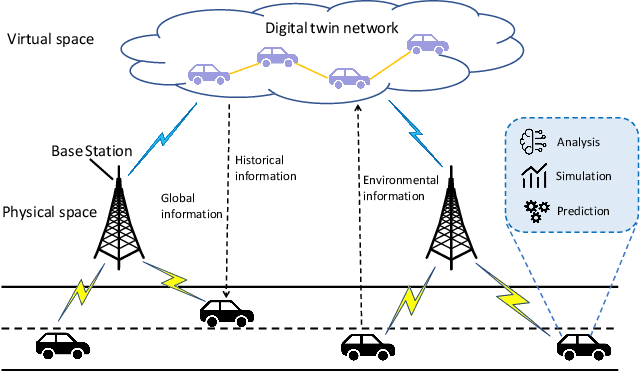
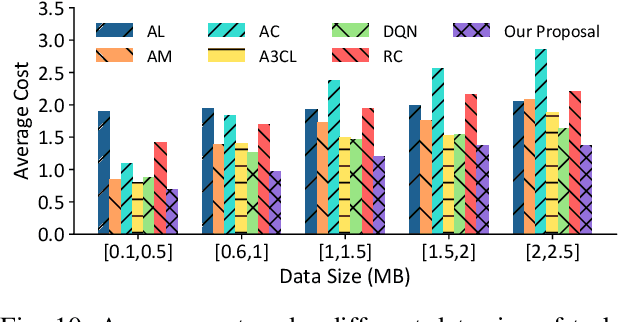

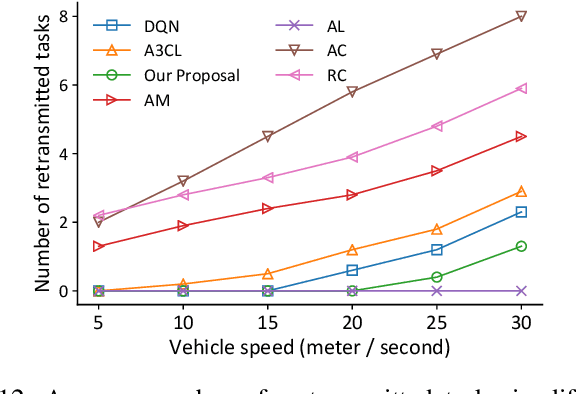
Mobile edge computing has become an effective and fundamental paradigm for futuristic autonomous vehicles to offload computing tasks. However, due to the high mobility of vehicles, the dynamics of the wireless conditions, and the uncertainty of the arrival computing tasks, it is difficult for a single vehicle to determine the optimal offloading strategy. In this paper, we propose a Digital Twin (DT) empowered task offloading framework for Internet of Vehicles. As a software agent residing in the cloud, a DT can obtain both global network information by using communications among DTs, and historical information of a vehicle by using the communications within the twin. The global network information and historical vehicular information can significantly facilitate the offloading. In specific, to preserve the precious computing resource at different levels for most appropriate computing tasks, we integrate a learning scheme based on the prediction of futuristic computing tasks in DT. Accordingly, we model the offloading scheduling process as a Markov Decision Process (MDP) to minimize the long-term cost in terms of a trade off between task latency, energy consumption, and renting cost of clouds. Simulation results demonstrate that our algorithm can effectively find the optimal offloading strategy, as well as achieve the fast convergence speed and high performance, compared with other existing approaches.