 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointNet: Extending Text-to-Image Diffusion for Dense Distribution Modeling
Oct 10, 2023



We introduce JointNet, a novel neural network architecture for modeling the joint distribution of images and an additional dense modality (e.g., depth maps). JointNet is extended from a pre-trained text-to-image diffusion model, where a copy of the original network is created for the new dense modality branch and is densely connected with the RGB branch. The RGB branch is locked during network fine-tuning, which enables efficient learning of the new modality distribution while maintaining the strong generalization ability of the large-scale pre-trained diffusion model. We demonstrate the effectiveness of JointNet by using RGBD diffusion as an example and through extensive experiments, showcasing its applicability in a variety of applications, including joint RGBD generation, dense depth prediction, depth-conditioned image generation, and coherent tile-based 3D panorama generation.
NeILF++: Inter-Reflectable Light Fields for Geometry and Material Estimation
Mar 30, 2023



We present a novel differentiable rendering framework for joint geometry, material, and lighting estimation from multi-view images. In contrast to previous methods which assume a simplified environment map or co-located flashlights, in this work, we formulate the lighting of a static scene as one neural incident light field (NeILF) and one outgoing neural radiance field (NeRF). The key insight of the proposed method is the union of the incident and outgoing light fields through physically-based rendering and inter-reflections between surfaces, making it possible to disentangle the scene geometry, material, and lighting from image observations in a physically-based manner. The proposed incident light and inter-reflection framework can be easily applied to other NeRF systems. We show that our method can not only decompose the outgoing radiance into incident lights and surface materials, but also serve as a surface refinement module that further improves the reconstruction detail of the neural surface. We demonstrate on several datasets that the proposed method is able to achieve state-of-the-art results in terms of geometry reconstruction quality, material estimation accuracy, and the fidelity of novel view rendering.
ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer
Aug 30, 2022
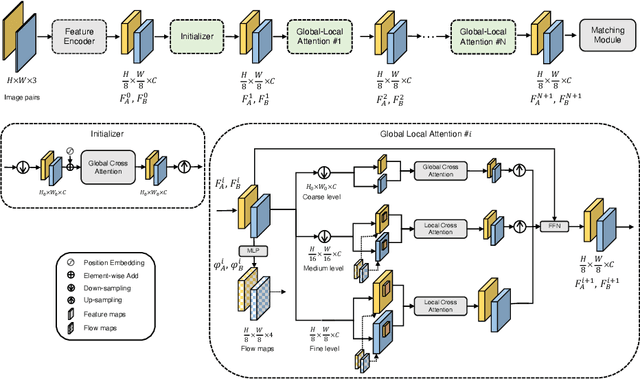
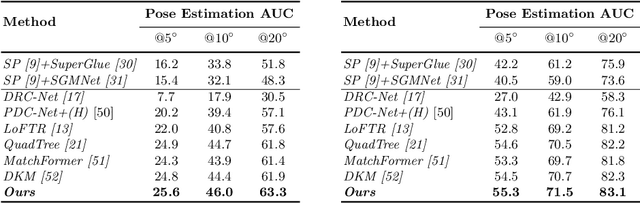

Generating robust and reliable correspondences across images is a fundamental task for a diversity of applications. To capture context at both global and local granularity, we propose ASpanFormer, a Transformer-based detector-free matcher that is built on hierarchical attention structure, adopting a novel attention operation which is capable of adjusting attention span in a self-adaptive manner. To achieve this goal, first, flow maps are regressed in each cross attention phase to locate the center of search region. Next, a sampling grid is generated around the center, whose size, instead of being empirically configured as fixed, is adaptively computed from a pixel uncertainty estimated along with the flow map. Finally, attention is computed across two images within derived regions, referred to as attention span. By these means, we are able to not only maintain long-range dependencies, but also enable fine-grained attention among pixels of high relevance that compensates essential locality and piece-wise smoothness in matching tasks. State-of-the-art accuracy on a wide range of evaluation benchmarks validates the strong matching capability of our method.
Critical Regularizations for Neural Surface Reconstruction in the Wild
Jun 07, 2022
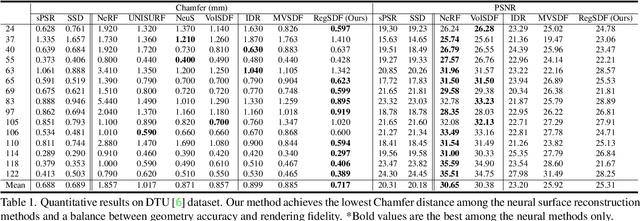

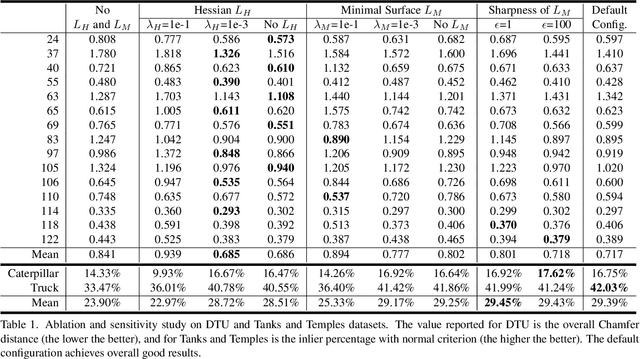
Neural implicit functions have recently shown promising results on surface reconstructions from multiple views. However, current methods still suffer from excessive time complexity and poor robustness when reconstructing unbounded or complex scenes. In this paper, we present RegSDF, which shows that proper point cloud supervisions and geometry regularizations are sufficient to produce high-quality and robust reconstruction results. Specifically, RegSDF takes an additional oriented point cloud as input, and optimizes a signed distance field and a surface light field within a differentiable rendering framework. We also introduce the two critical regularizations for this optimization. The first one is the Hessian regularization that smoothly diffuses the signed distance values to the entire distance field given noisy and incomplete input. And the second one is the minimal surface regularization that compactly interpolates and extrapolates the missing geometry. Extensive experiments are conducted on DTU, BlendedMVS, and Tanks and Temples datasets. Compared with recent neural surface reconstruction approaches, RegSDF is able to reconstruct surfaces with fine details even for open scenes with complex topologies and unstructured camera trajectories.
NeILF: Neural Incident Light Field for Physically-based Material Estimation
Mar 18, 2022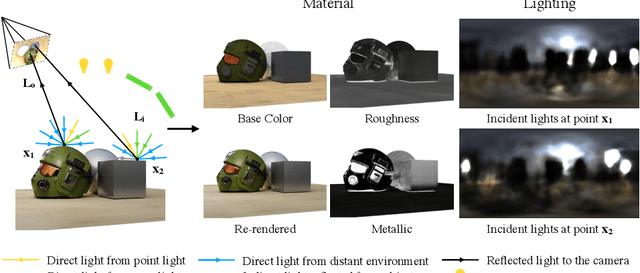
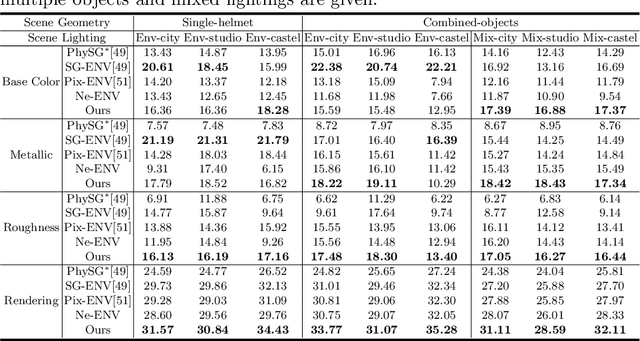
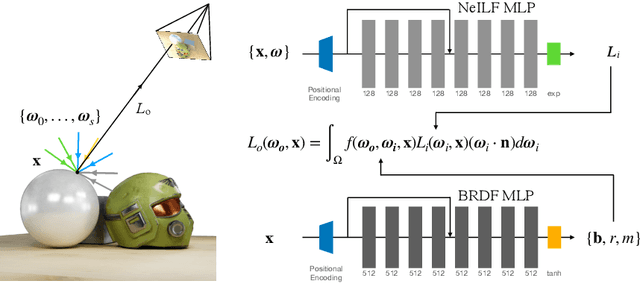

We present a differentiable rendering framework for material and lighting estimation from multi-view images and a reconstructed geometry. In the framework, we represent scene lightings as the Neural Incident Light Field (NeILF) and material properties as the surface BRDF modelled by multi-layer perceptrons. Compared with recent approaches that approximate scene lightings as the 2D environment map, NeILF is a fully 5D light field that is capable of modelling illuminations of any static scenes. In addition, occlusions and indirect lights can be handled naturally by the NeILF representation without requiring multiple bounces of ray tracing, making it possible to estimate material properties even for scenes with complex lightings and geometries. We also propose a smoothness regularization and a Lambertian assumption to reduce the material-lighting ambiguity during the optimization. Our method strictly follows the physically-based rendering equation, and jointly optimizes material and lighting through the differentiable rendering process. We have intensively evaluated the proposed method on our in-house synthetic dataset, the DTU MVS dataset, and real-world BlendedMVS scenes. Our method is able to outperform previous methods by a significant margin in terms of novel view rendering quality, setting a new state-of-the-art for image-based material and lighting estimation.
Learning Signed Distance Field for Multi-view Surface Reconstruction
Aug 23, 2021
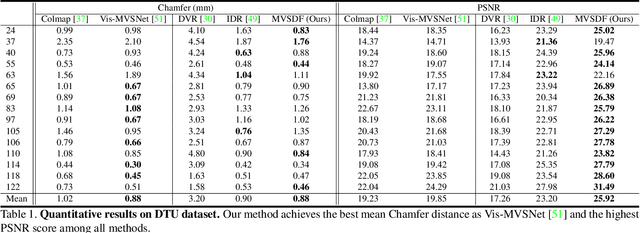
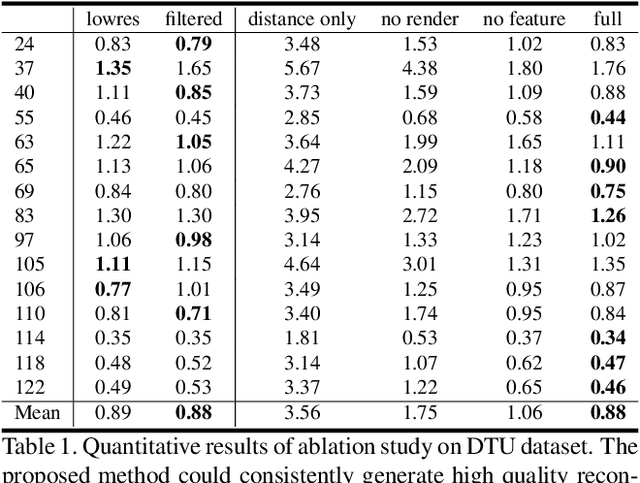

Recent works on implicit neural representations have shown promising results for multi-view surface reconstruction. However, most approaches are limited to relatively simple geometries and usually require clean object masks for reconstructing complex and concave objects. In this work, we introduce a novel neural surface reconstruction framework that leverages the knowledge of stereo matching and feature consistency to optimize the implicit surface representation. More specifically, we apply a signed distance field (SDF) and a surface light field to represent the scene geometry and appearance respectively. The SDF is directly supervised by geometry from stereo matching, and is refined by optimizing the multi-view feature consistency and the fidelity of rendered images. Our method is able to improve the robustness of geometry estimation and support reconstruction of complex scene topologies. Extensive experiments have been conducted on DTU, EPFL and Tanks and Temples datasets. Compared to previous state-of-the-art methods, our method achieves better mesh reconstruction in wide open scenes without masks as input.
Learning to Match Features with Seeded Graph Matching Network
Aug 19, 2021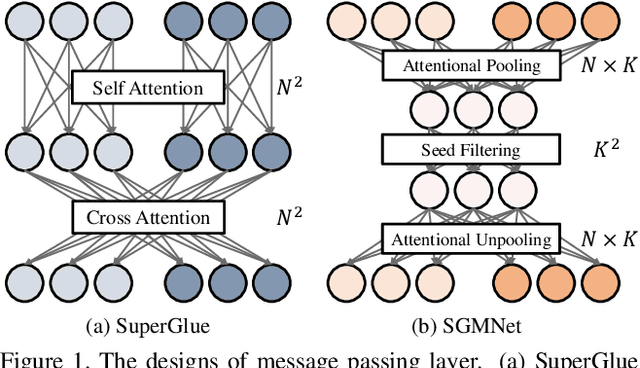
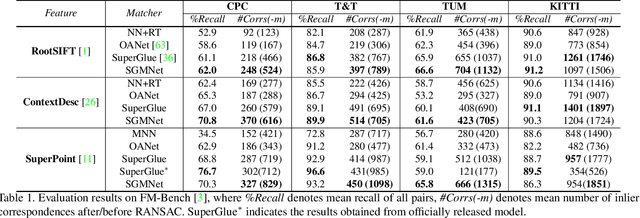
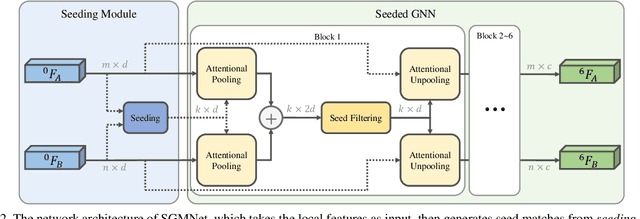
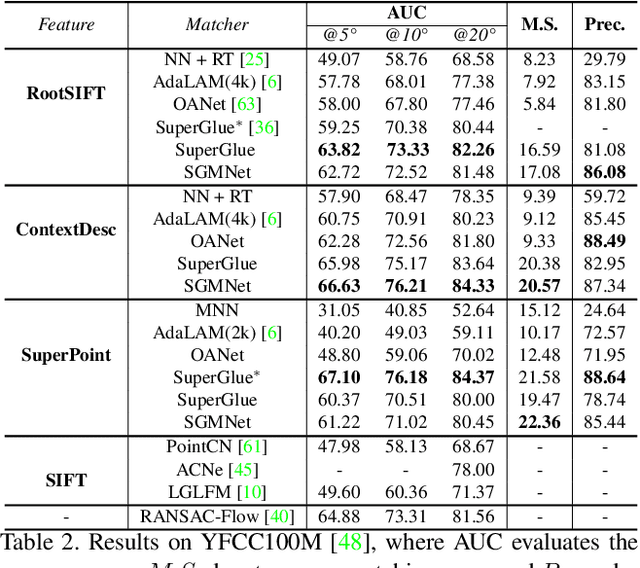
Matching local features across images is a fundamental problem in computer vision. Targeting towards high accuracy and efficiency, we propose Seeded Graph Matching Network, a graph neural network with sparse structure to reduce redundant connectivity and learn compact representation. The network consists of 1) Seeding Module, which initializes the matching by generating a small set of reliable matches as seeds. 2) Seeded Graph Neural Network, which utilizes seed matches to pass messages within/across images and predicts assignment costs. Three novel operations are proposed as basic elements for message passing: 1) Attentional Pooling, which aggregates keypoint features within the image to seed matches. 2) Seed Filtering, which enhances seed features and exchanges messages across images. 3) Attentional Unpooling, which propagates seed features back to original keypoints. Experiments show that our method reduces computational and memory complexity significantly compared with typical attention-based networks while competitive or higher performance is achieved.
Learning Stereo Matchability in Disparity Regression Networks
Aug 11, 2020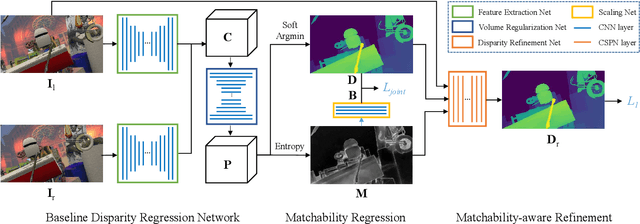

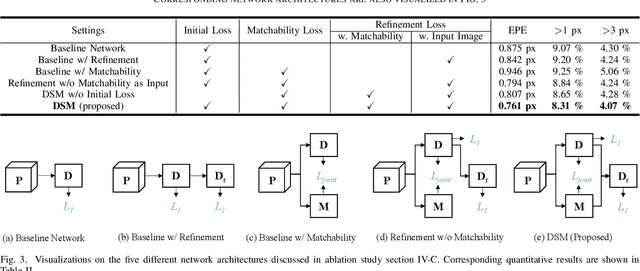

Learning-based stereo matching has recently achieved promising results, yet still suffers difficulties in establishing reliable matches in weakly matchable regions that are textureless, non-Lambertian, or occluded. In this paper, we address this challenge by proposing a stereo matching network that considers pixel-wise matchability. Specifically, the network jointly regresses disparity and matchability maps from 3D probability volume through expectation and entropy operations. Next, a learned attenuation is applied as the robust loss function to alleviate the influence of weakly matchable pixels in the training. Finally, a matchability-aware disparity refinement is introduced to improve the depth inference in weakly matchable regions. The proposed deep stereo matchability (DSM) framework can improve the matching result or accelerate the computation while still guaranteeing the quality. Moreover, the DSM framework is portable to many recent stereo networks. Extensive experiments are conducted on Scene Flow and KITTI stereo datasets to demonstrate the effectiveness of the proposed framework over the state-of-the-art learning-based stereo methods.
Learning Discriminative Feature with CRF for Unsupervised Video Object Segmentation
Aug 04, 2020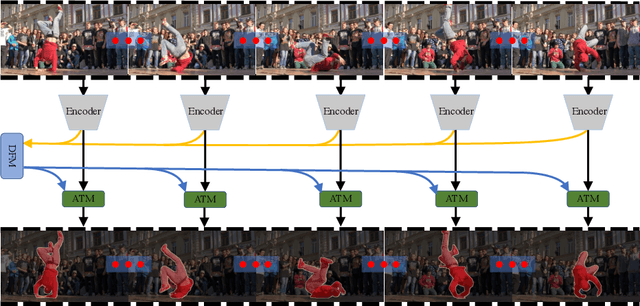
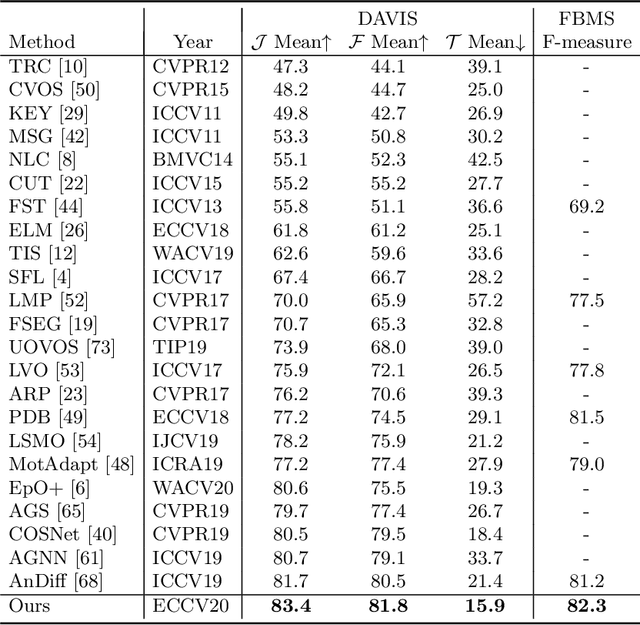
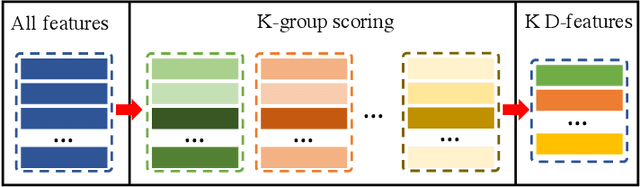
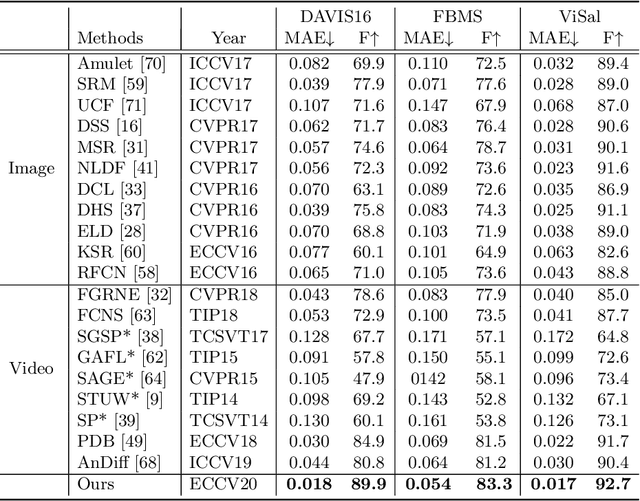
In this paper, we introduce a novel network, called discriminative feature network (DFNet), to address the unsupervised video object segmentation task. To capture the inherent correlation among video frames, we learn discriminative features (D-features) from the input images that reveal feature distribution from a global perspective. The D-features are then used to establish correspondence with all features of test image under conditional random field (CRF) formulation, which is leveraged to enforce consistency between pixels. The experiments verify that DFNet outperforms state-of-the-art methods by a large margin with a mean IoU score of 83.4% and ranks first on the DAVIS-2016 leaderboard while using much fewer parameters and achieving much more efficient performance in the inference phase. We further evaluate DFNet on the FBMS dataset and the video saliency dataset ViSal, reaching a new state-of-the-art. To further demonstrate the generalizability of our framework, DFNet is also applied to the image object co-segmentation task. We perform experiments on a challenging dataset PASCAL-VOC and observe the superiority of DFNet. The thorough experiments verify that DFNet is able to capture and mine the underlying relations of images and discover the common foreground objects.
Stochastic Bundle Adjustment for Efficient and Scalable 3D Reconstruction
Aug 02, 2020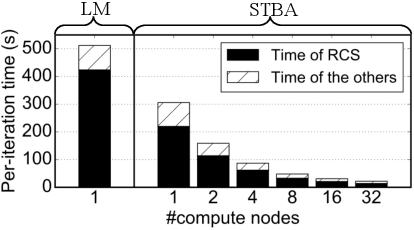
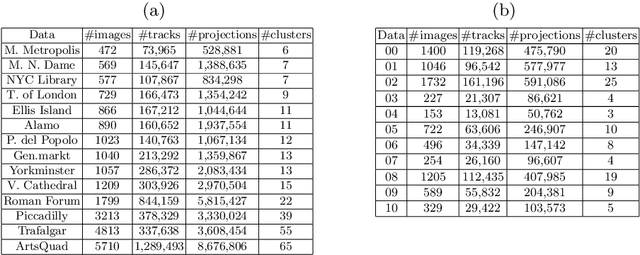
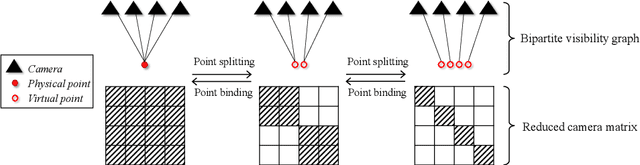

Current bundle adjustment solvers such as the Levenberg-Marquardt (LM) algorithm are limited by the bottleneck in solving the Reduced Camera System (RCS) whose dimension is proportional to the camera number. When the problem is scaled up, this step is neither efficient in computation nor manageable for a single compute node. In this work, we propose a stochastic bundle adjustment algorithm which seeks to decompose the RCS approximately inside the LM iterations to improve the efficiency and scalability. It first reformulates the quadratic programming problem of an LM iteration based on the clustering of the visibility graph by introducing the equality constraints across clusters. Then, we propose to relax it into a chance constrained problem and solve it through sampled convex program. The relaxation is intended to eliminate the interdependence between clusters embodied by the constraints, so that a large RCS can be decomposed into independent linear sub-problems. Numerical experiments on unordered Internet image sets and sequential SLAM image sets, as well as distributed experiments on large-scale datasets, have demonstrated the high efficiency and scalability of the proposed approach. Codes are released at https://github.com/zlthinker/STBA.