 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-World: Controllable Ego-Centric Multi-Camera World Models for Scalable End-to-End Driving
Mar 20, 2026Scalable and reliable evaluation is increasingly critical in the end-to-end era of autonomous driving, where vision--language--action (VLA) policies directly map raw sensor streams to driving actions. Yet, current evaluation pipelines still rely heavily on real-world road testing, which is costly, biased toward limited scenario coverage, and difficult to reproduce. These challenges motivate a real-world simulator that can generate realistic future observations under proposed actions, while remaining controllable and stable over long horizons. We present X-World, an action-conditioned multi-camera generative world model that simulates future observations directly in video space. Given synchronized multi-view camera history and a future action sequence, X-World generates future multi-camera video streams that follow the commanded actions. To ensure reproducible and editable scene rollouts, X-World further supports optional controls over dynamic traffic agents and static road elements, and retains a text-prompt interface for appearance-level control (e.g., weather and time of day). Beyond world simulation, X-World also enables video style transfer by conditioning on appearance prompts while preserving the underlying action and scene dynamics. At the core of X-World is a multi-view latent video generator designed to explicitly encourage cross-view geometric consistency and temporal coherence under diverse control signals. Experiments show that X-World achieves high-quality multi-view video generation with (i) strong view consistency across cameras, (ii) stable temporal dynamics over long rollouts, and (iii) high controllability with strict action following and faithful adherence to optional scene controls. These properties make X-World a practical foundation for scalable and reproducible evaluation.
End-to-End Conversational Search for Online Shopping with Utterance Transfer
Sep 12, 2021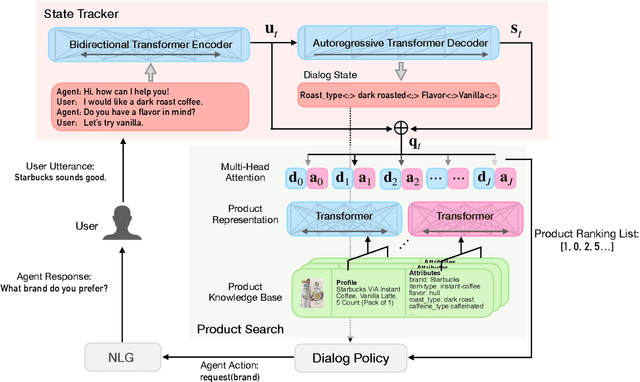
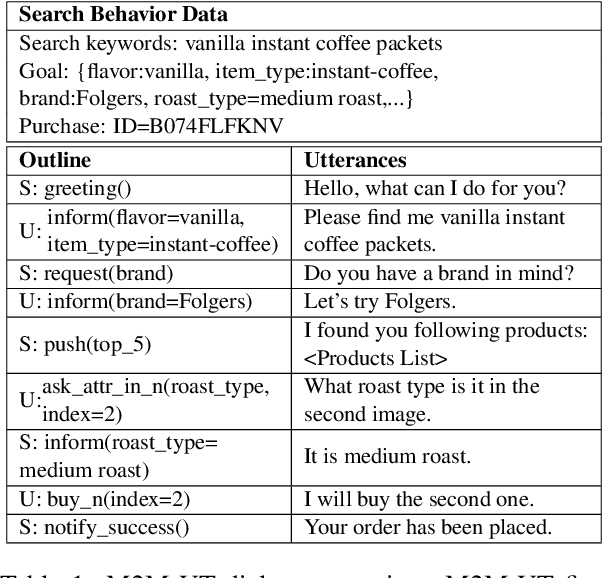
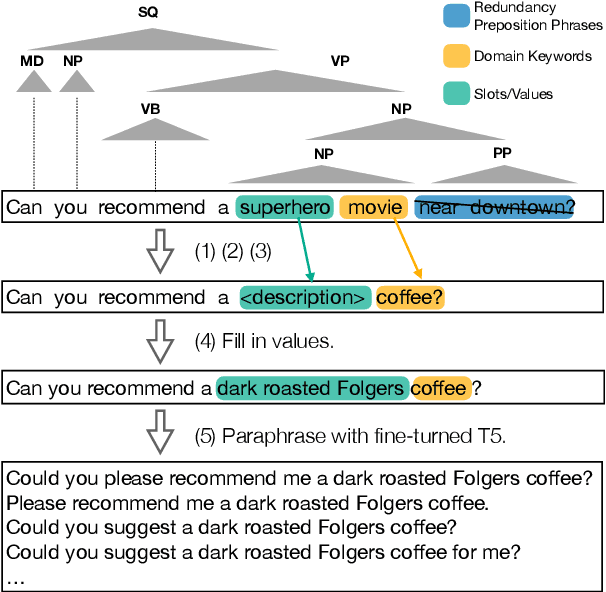

Successful conversational search systems can present natural, adaptive and interactive shopping experience for online shopping customers. However, building such systems from scratch faces real word challenges from both imperfect product schema/knowledge and lack of training dialog data.In this work we first propose ConvSearch, an end-to-end conversational search system that deeply combines the dialog system with search. It leverages the text profile to retrieve products, which is more robust against imperfect product schema/knowledge compared with using product attributes alone. We then address the lack of data challenges by proposing an utterance transfer approach that generates dialogue utterances by using existing dialog from other domains, and leveraging the search behavior data from e-commerce retailer. With utterance transfer, we introduce a new conversational search dataset for online shopping. Experiments show that our utterance transfer method can significantly improve the availability of training dialogue data without crowd-sourcing, and the conversational search system significantly outperformed the best tested baseline.
Multi-Task Label Embedding for Text Classification
Oct 17, 2017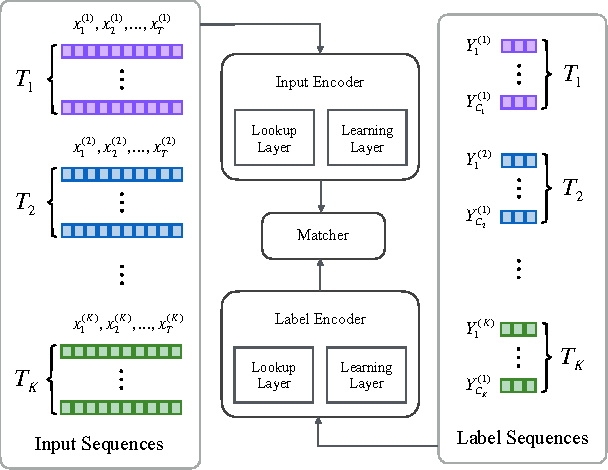
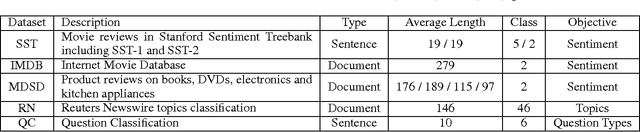

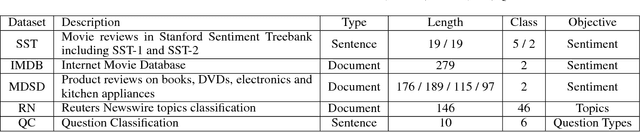
Multi-task learning in text classification leverages implicit correlations among related tasks to extract common features and yield performance gains. However, most previous works treat labels of each task as independent and meaningless one-hot vectors, which cause a loss of potential information and makes it difficult for these models to jointly learn three or more tasks. In this paper, we propose Multi-Task Label Embedding to convert labels in text classification into semantic vectors, thereby turning the original tasks into vector matching tasks. We implement unsupervised, supervised and semi-supervised models of Multi-Task Label Embedding, all utilizing semantic correlations among tasks and making it particularly convenient to scale and transfer as more tasks are involved. Extensive experiments on five benchmark datasets for text classification show that our models can effectively improve performances of related tasks with semantic representations of labels and additional information from each other.
A Generalized Recurrent Neural Architecture for Text Classification with Multi-Task Learning
Jul 10, 2017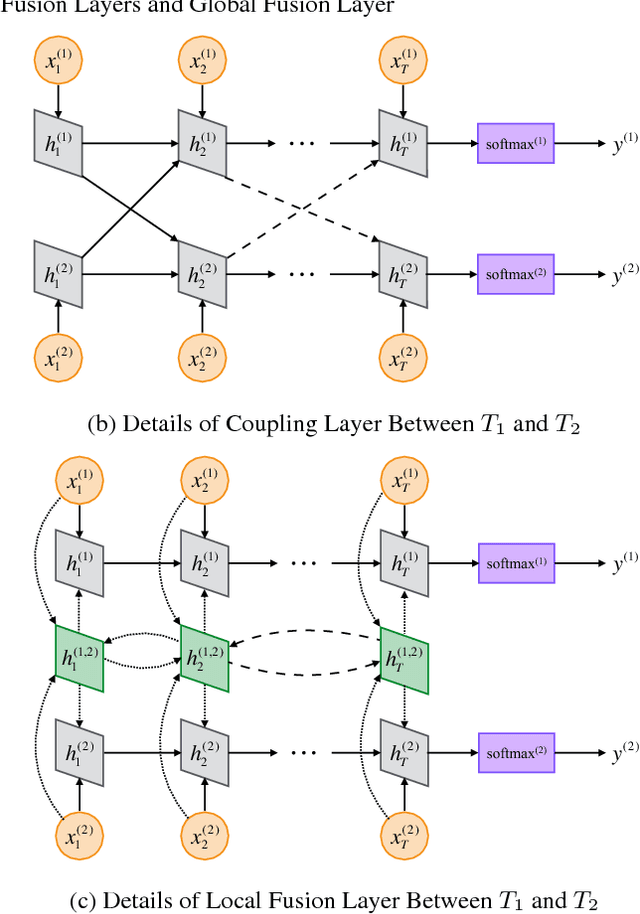
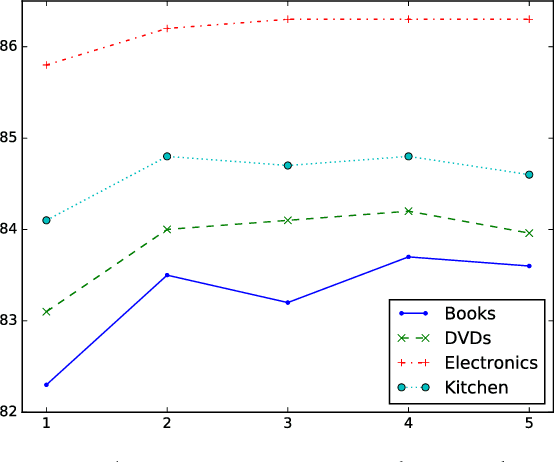

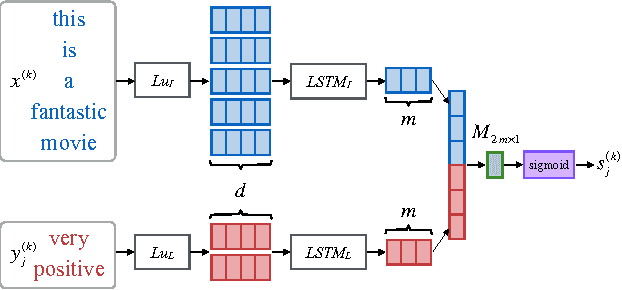
Multi-task learning leverages potential correlations among related tasks to extract common features and yield performance gains. However, most previous works only consider simple or weak interactions, thereby failing to model complex correlations among three or more tasks. In this paper, we propose a multi-task learning architecture with four types of recurrent neural layers to fuse information across multiple related tasks. The architecture is structurally flexible and considers various interactions among tasks, which can be regarded as a generalized case of many previous works. Extensive experiments on five benchmark datasets for text classification show that our model can significantly improve performances of related tasks with additional information from others.