 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Logs to Language: Learning Optimal Verbalization for LLM-Based Recommendation in Production
Feb 24, 2026Large language models (LLMs) are promising backbones for generative recommender systems, yet a key challenge remains underexplored: verbalization, i.e., converting structured user interaction logs into effective natural language inputs. Existing methods rely on rigid templates that simply concatenate fields, yielding suboptimal representations for recommendation. We propose a data-centric framework that learns verbalization for LLM-based recommendation. Using reinforcement learning, a verbalization agent transforms raw interaction histories into optimized textual contexts, with recommendation accuracy as the training signal. This agent learns to filter noise, incorporate relevant metadata, and reorganize information to improve downstream predictions. Experiments on a large-scale industrial streaming dataset show that learned verbalization delivers up to 93% relative improvement in discovery item recommendation accuracy over template-based baselines. Further analysis reveals emergent strategies such as user interest summarization, noise removal, and syntax normalization, offering insights into effective context construction for LLM-based recommender systems.
Session-based Recommendations with Recurrent Neural Networks
Mar 29, 2016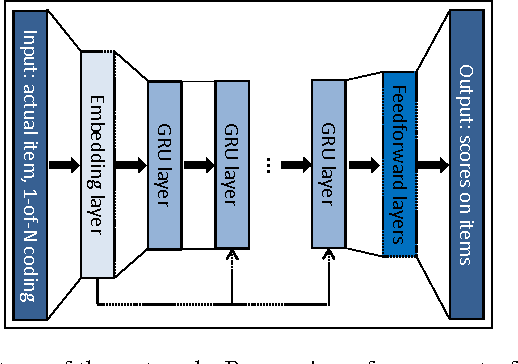
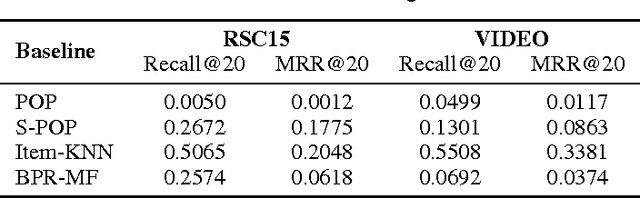
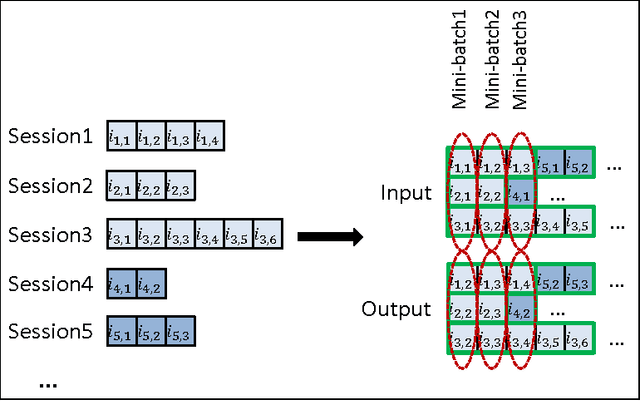
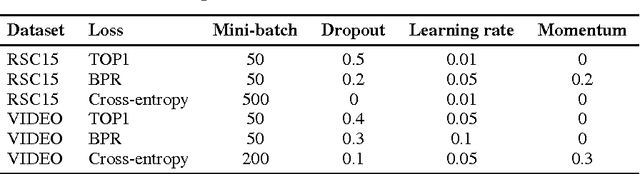
We apply recurrent neural networks (RNN) on a new domain, namely recommender systems. Real-life recommender systems often face the problem of having to base recommendations only on short session-based data (e.g. a small sportsware website) instead of long user histories (as in the case of Netflix). In this situation the frequently praised matrix factorization approaches are not accurate. This problem is usually overcome in practice by resorting to item-to-item recommendations, i.e. recommending similar items. We argue that by modeling the whole session, more accurate recommendations can be provided. We therefore propose an RNN-based approach for session-based recommendations. Our approach also considers practical aspects of the task and introduces several modifications to classic RNNs such as a ranking loss function that make it more viable for this specific problem. Experimental results on two data-sets show marked improvements over widely used approaches.