 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREBORN: Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR
Feb 06, 2024Unsupervised automatic speech recognition (ASR) aims to learn the mapping between the speech signal and its corresponding textual transcription without the supervision of paired speech-text data. A word/phoneme in the speech signal is represented by a segment of speech signal with variable length and unknown boundary, and this segmental structure makes learning the mapping between speech and text challenging, especially without paired data. In this paper, we propose REBORN, Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR. REBORN alternates between (1) training a segmentation model that predicts the boundaries of the segmental structures in speech signals and (2) training the phoneme prediction model, whose input is a segmental structure segmented by the segmentation model, to predict a phoneme transcription. Since supervised data for training the segmentation model is not available, we use reinforcement learning to train the segmentation model to favor segmentations that yield phoneme sequence predictions with a lower perplexity. We conduct extensive experiments and find that under the same setting, REBORN outperforms all prior unsupervised ASR models on LibriSpeech, TIMIT, and five non-English languages in Multilingual LibriSpeech. We comprehensively analyze why the boundaries learned by REBORN improve the unsupervised ASR performance.
SpeechDPR: End-to-End Spoken Passage Retrieval for Open-Domain Spoken Question Answering
Jan 24, 2024


Spoken Question Answering (SQA) is essential for machines to reply to user's question by finding the answer span within a given spoken passage. SQA has been previously achieved without ASR to avoid recognition errors and Out-of-Vocabulary (OOV) problems. However, the real-world problem of Open-domain SQA (openSQA), in which the machine needs to first retrieve passages that possibly contain the answer from a spoken archive in addition, was never considered. This paper proposes the first known end-to-end framework, Speech Dense Passage Retriever (SpeechDPR), for the retrieval component of the openSQA problem. SpeechDPR learns a sentence-level semantic representation by distilling knowledge from the cascading model of unsupervised ASR (UASR) and text dense retriever (TDR). No manually transcribed speech data is needed. Initial experiments showed performance comparable to the cascading model of UASR and TDR, and significantly better when UASR was poor, verifying this approach is more robust to speech recognition errors.
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering
Mar 26, 2022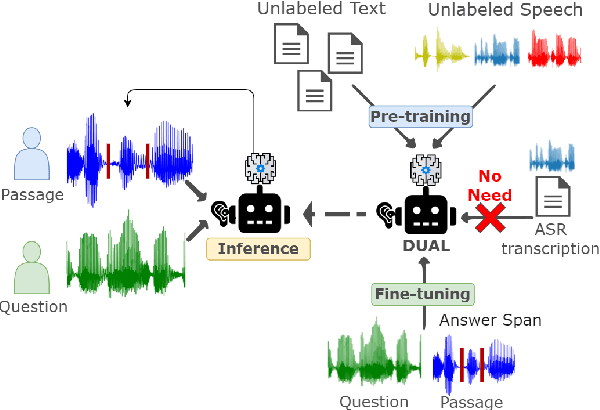
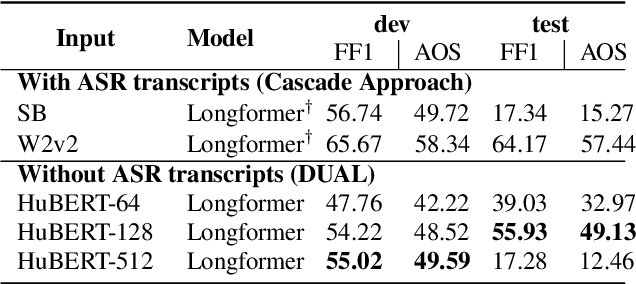
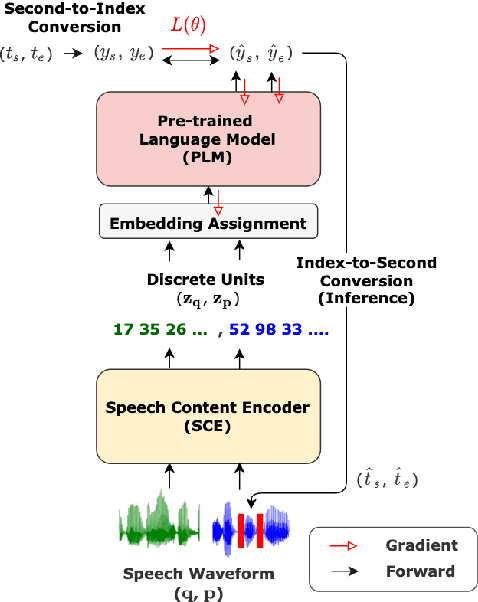
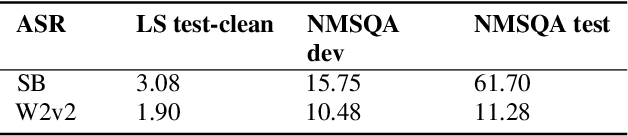
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.
Towards Lifelong Learning of End-to-end ASR
Apr 04, 2021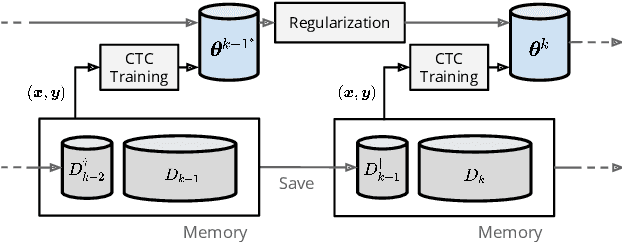

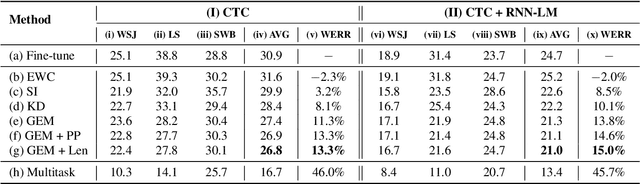
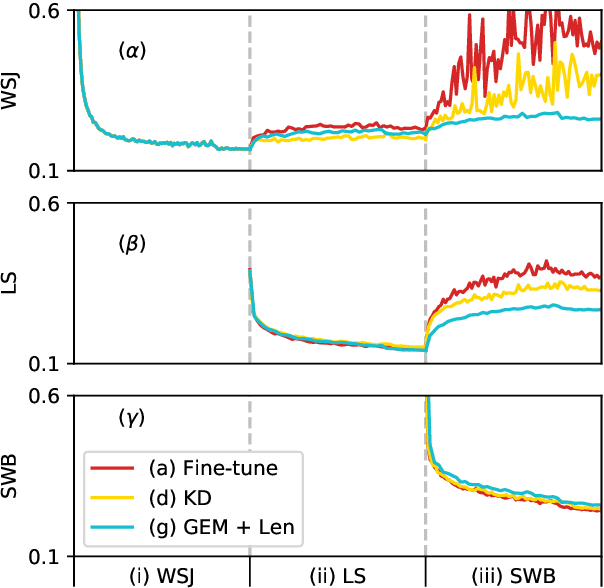
Automatic speech recognition (ASR) technologies today are primarily optimized for given datasets; thus, any changes in the application environment (e.g., acoustic conditions or topic domains) may inevitably degrade the performance. We can collect new data describing the new environment and fine-tune the system, but this naturally leads to higher error rates for the earlier datasets, referred to as catastrophic forgetting. The concept of lifelong learning (LLL) aiming to enable a machine to sequentially learn new tasks from new datasets describing the changing real world without forgetting the previously learned knowledge is thus brought to attention. This paper reports, to our knowledge, the first effort to extensively consider and analyze the use of various approaches of LLL in end-to-end (E2E) ASR, including proposing novel methods in saving data for past domains to mitigate the catastrophic forgetting problem. An overall relative reduction of 28.7% in WER was achieved compared to the fine-tuning baseline when sequentially learning on three very different benchmark corpora. This can be the first step toward the highly desired ASR technologies capable of synchronizing with the continuously changing real world.
FragmentVC: Any-to-Any Voice Conversion by End-to-End Extracting and Fusing Fine-Grained Voice Fragments With Attention
Oct 27, 2020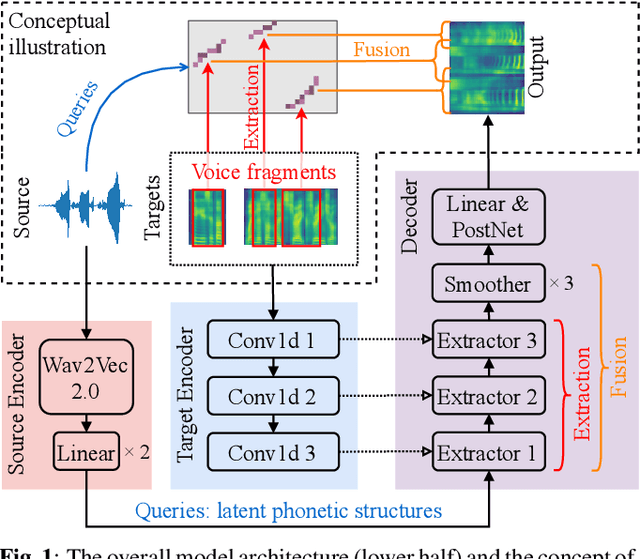

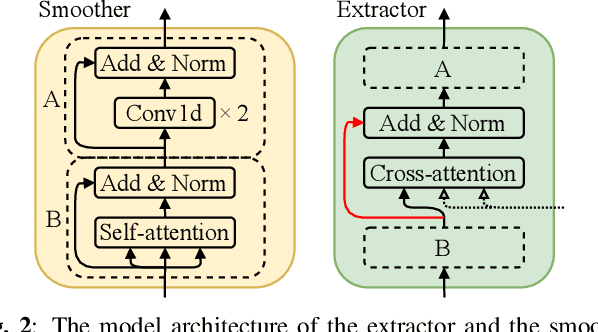

Any-to-any voice conversion aims to convert the voice from and to any speakers even unseen during training, which is much more challenging compared to one-to-one or many-to-many tasks, but much more attractive in real-world scenarios. In this paper we proposed FragmentVC, in which the latent phonetic structure of the utterance from the source speaker is obtained from Wav2Vec 2.0, while the spectral features of the utterance(s) from the target speaker are obtained from log mel-spectrograms. By aligning the hidden structures of the two different feature spaces with a two-stage training process, FragmentVC is able to extract fine-grained voice fragments from the target speaker utterance(s) and fuse them into the desired utterance, all based on the attention mechanism of Transformer as verified with analysis on attention maps, and is accomplished end-to-end. This approach is trained with reconstruction loss only without any disentanglement considerations between content and speaker information and doesn't require parallel data. Objective evaluation based on speaker verification and subjective evaluation with MOS both showed that this approach outperformed SOTA approaches, such as AdaIN-VC and AutoVC.
Defending Your Voice: Adversarial Attack on Voice Conversion
May 18, 2020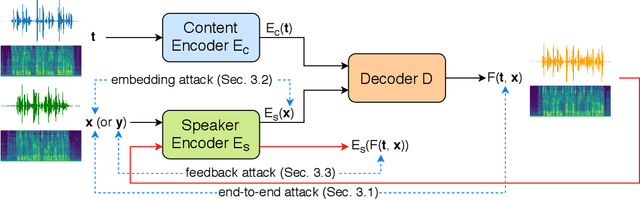
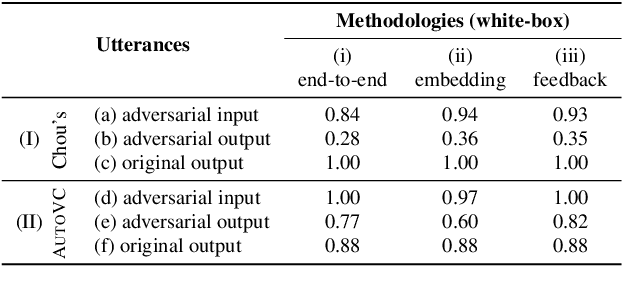
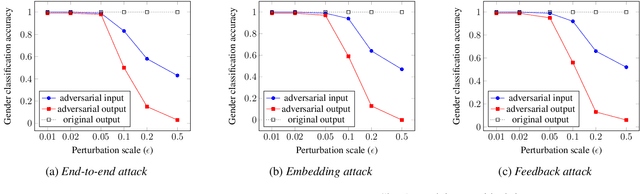
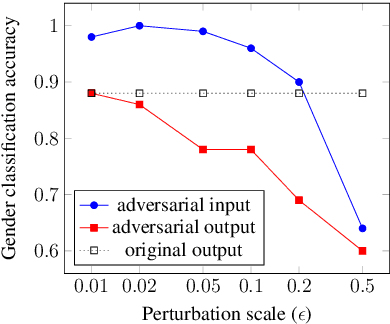
Substantial improvements have been achieved in recent years in voice conversion, which converts the speaker characteristics of an utterance into those of another speaker without changing the linguistic content of the utterance. Nonetheless, the improved conversion technologies also led to concerns about privacy and authentication. It thus becomes highly desired to be able to prevent one's voice from being improperly utilized with such voice conversion technologies. This is why we report in this paper the first known attempt to try to perform adversarial attack on voice conversion. We introduce human imperceptible noise into the utterances of a speaker whose voice is to be defended. Given these adversarial examples, voice conversion models cannot convert other utterances so as to sound like being produced by the defended speaker. Preliminary experiments were conducted on two currently state-of-the-art zero-shot voice conversion models. Objective and subjective evaluation results in both white-box and black-box scenarios are reported. It was shown that the speaker characteristics of the converted utterances were made obviously different from those of the defended speaker, while the adversarial examples of the defended speaker are not distinguishable from the authentic utterances.
End-to-end Whispered Speech Recognition with Frequency-weighted Approaches and Layer-wise Transfer Learning
May 05, 2020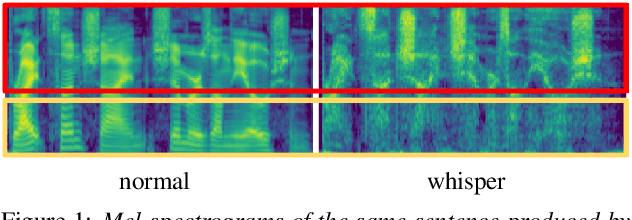
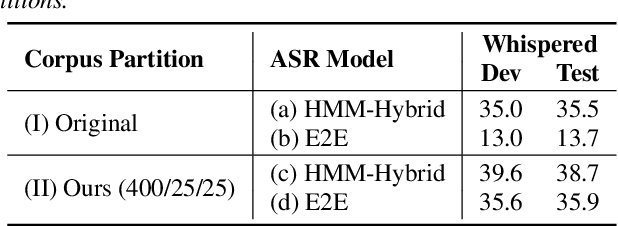
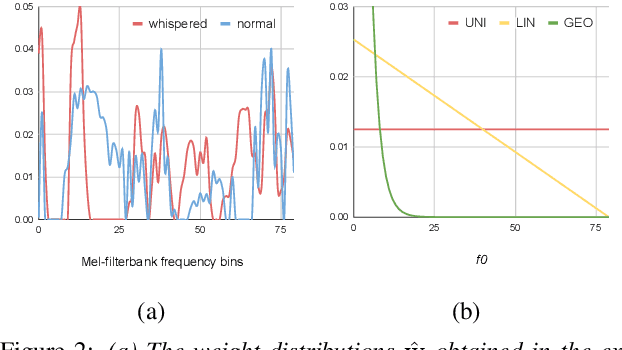
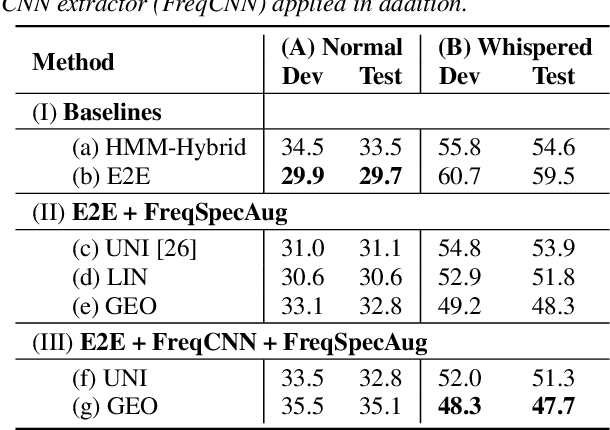
Whispering is an important mode of human speech, but no end-to-end recognition results for it were reported yet, probably due to the scarcity of available whispered speech data. In this paper, we present several approaches for end-to-end (E2E) recognition of whispered speech considering the special characteristics of whispered speech and the scarcity of data. This includes a frequency-weighted SpecAugment policy and a frequency-divided CNN feature extractor for better capturing the high frequency structures of whispered speech, and a layer-wise transfer learning approach to pre-train a model with normal speech then fine-tuning it with whispered speech to bridge the gap between whispered and normal speech. We achieve an overall relative reduction of 19.8% in PER and 31.9% in CER on a relatively small whispered TIMIT corpus. The results indicate as long as we have a good E2E model pre-trained on normal speech, a relatively small set of whispered speech may suffice to obtain a reasonably good E2E whispered speech recognizer.
Sequence-to-sequence Automatic Speech Recognition with Word Embedding Regularization and Fused Decoding
Oct 28, 2019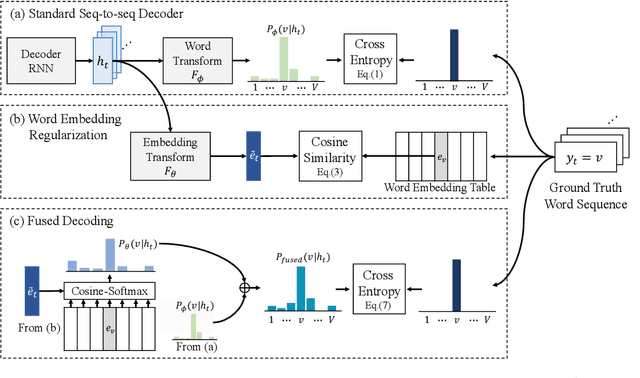
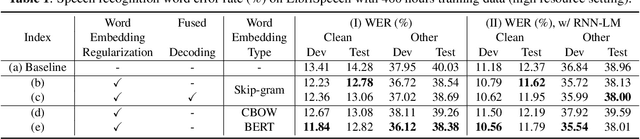
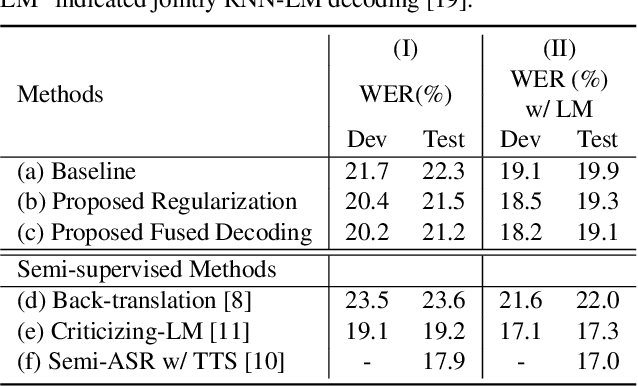
In this paper, we investigate the benefit that off-the-shelf word embedding can bring to the sequence-to-sequence (seq-to-seq) automatic speech recognition (ASR). We first introduced the word embedding regularization by maximizing the cosine similarity between a transformed decoder feature and the target word embedding. Based on the regularized decoder, we further proposed the fused decoding mechanism. This allows the decoder to consider the semantic consistency during decoding by absorbing the information carried by the transformed decoder feature, which is learned to be close to the target word embedding. Initial results on LibriSpeech demonstrated that pre-trained word embedding can significantly lower ASR recognition error with a negligible cost, and the choice of word embedding algorithms among Skip-gram, CBOW and BERT is important.
Towards Unsupervised Speech Recognition and Synthesis with Quantized Speech Representation Learning
Oct 28, 2019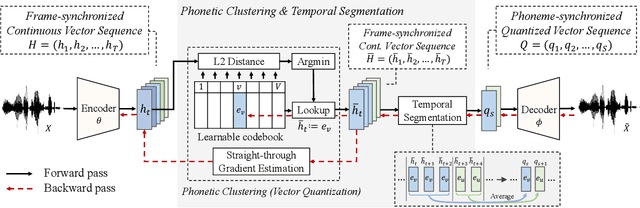
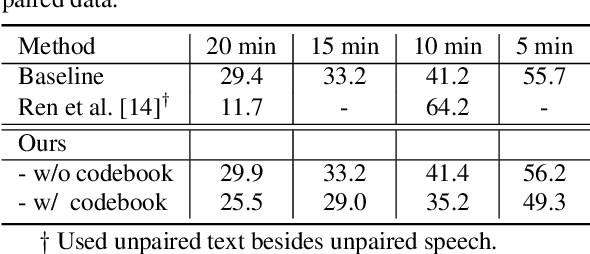
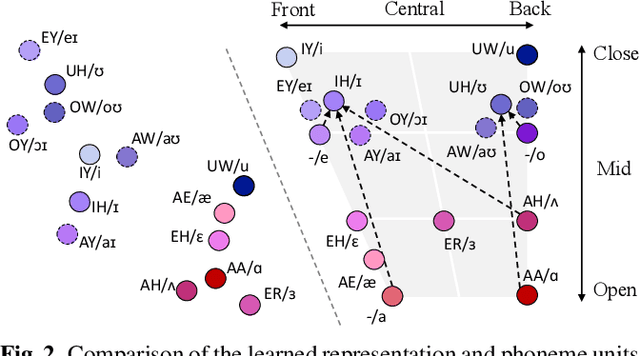
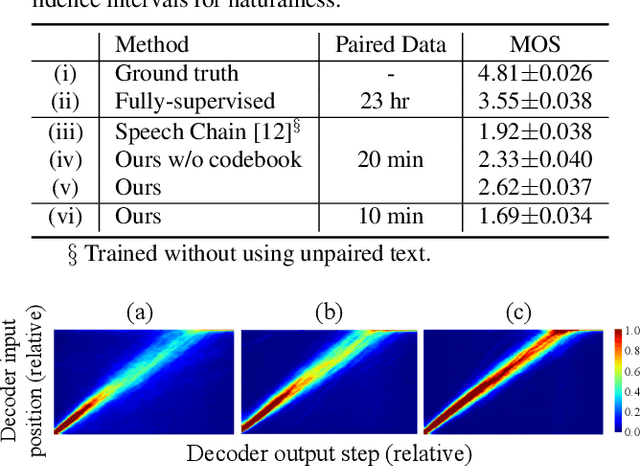
In this paper we propose a Sequential Representation Quantization AutoEncoder (SeqRQ-AE) to learn from primarily unpaired audio data and produce sequences of representations very close to phoneme sequences of speech utterances. This is achieved by proper temporal segmentation to make the representations phoneme-synchronized, and proper phonetic clustering to have total number of distinct representations close to the number of phonemes. Mapping between the distinct representations and phonemes is learned from a small amount of annotated paired data. Preliminary experiments on LJSpeech demonstrated the learned representations for vowels have relative locations in latent space in good parallel to that shown in the IPA vowel chart defined by linguistics experts. With less than 20 minutes of annotated speech, our method outperformed existing methods on phoneme recognition and is able to synthesize intelligible speech that beats our baseline model.
Interrupted and cascaded permutation invariant training for speech separation
Oct 28, 2019
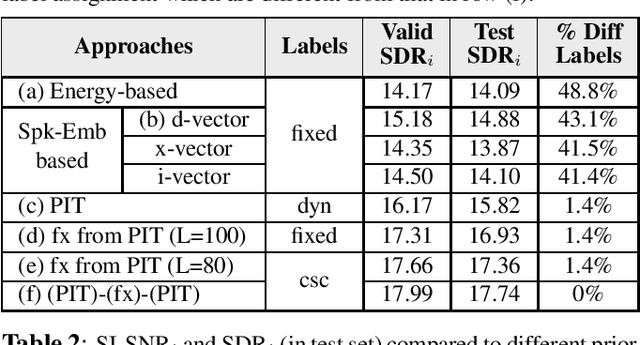
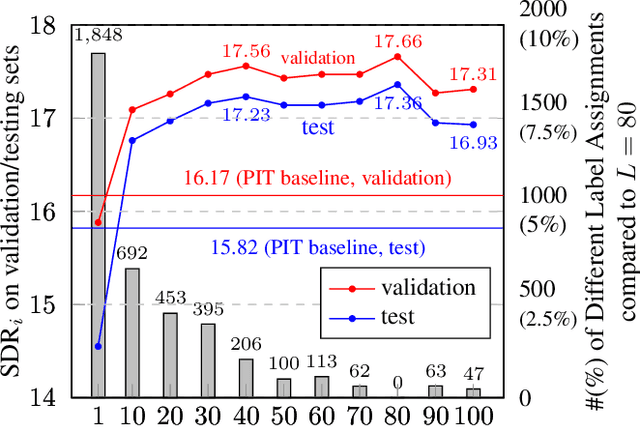
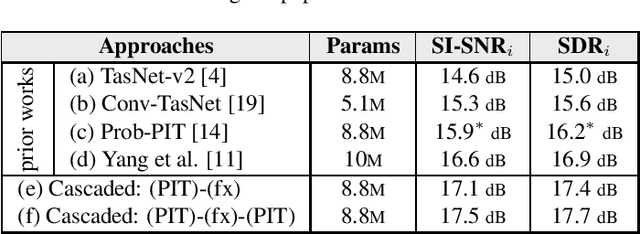
Permutation Invariant Training (PIT) has long been a stepping stone method for training speech separation model in handling the label ambiguity problem. With PIT selecting the minimum cost label assignments dynamically, very few studies considered the separation problem to be optimizing both the model parameters and the label assignments, but focused on searching for good model architecture and parameters. In this paper, we investigate instead for a given model architecture the various flexible label assignment strategies for training the model, rather than directly using PIT. Surprisingly, we discover a significant performance boost compared to PIT is possible if the model is trained with fixed label assignments and a good set of labels is chosen. With fixed label training cascaded between two sections of PIT, we achieved the state-of-the-art performance on WSJ0-2mix without changing the model architecture at all.