 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation
May 13, 2026Omni-modal language models are intended to jointly understand audio, visual inputs, and language, but benchmark gains can be inflated when visual evidence alone is enough to answer a query. We study whether current omni-modal benchmarks separate visual shortcuts from genuine audio-visual-language evidence integration, and how post-training behaves under a visually debiased evaluation setting. We audit nine omni-modal benchmarks with visual-only probing, remove visually solvable queries, and retain full subsets when filtering is undefined or would make comparisons unstable. This yields OmniClean, a cleaned evaluation view with 8,551 retained queries from 16,968 audited queries. On OmniClean, we evaluate OmniBoost, a three-stage post-training recipe based on Qwen2.5-Omni-3B: mixed bi-modal SFT, mixed-modality RLVR, and SFT on self-distilled data. Balanced bi-modal SFT gives limited and uneven gains, RLVR provides the first broad improvement, and self-distillation reshapes the benchmark profile. After SFT on self-distilled data, the 3B model reaches performance comparable to, and in aggregate slightly above, Qwen3-Omni-30B-A3B-Instruct without using a stronger omni-modal teacher. These results show that omni-modal progress is easier to interpret when evaluation controls visual leakage, and that small omni-modal models can benefit from staged post-training with self-distilled omni-query supervision. Project page: https://cheliu-computation.github.io/omni/
Towards Full Automated Drive in Urban Environments: A Demonstration in GoMentum Station, California
May 02, 2017
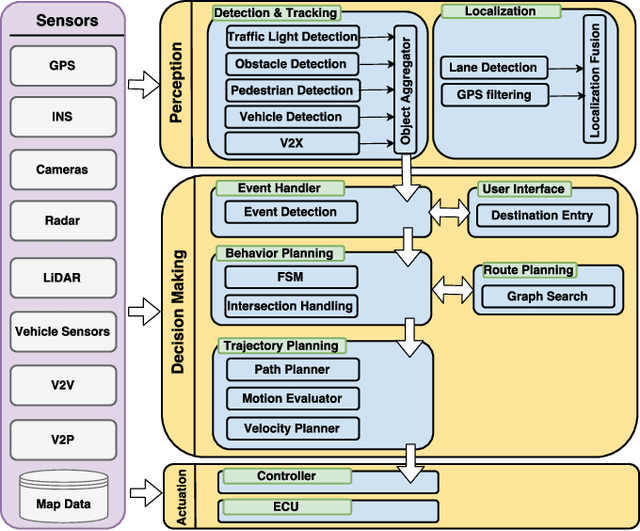
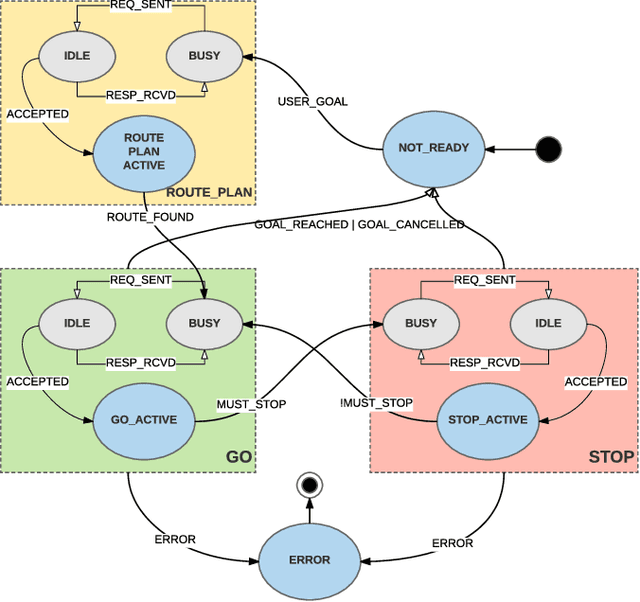

Each year, millions of motor vehicle traffic accidents all over the world cause a large number of fatalities, injuries and significant material loss. Automated Driving (AD) has potential to drastically reduce such accidents. In this work, we focus on the technical challenges that arise from AD in urban environments. We present the overall architecture of an AD system and describe in detail the perception and planning modules. The AD system, built on a modified Acura RLX, was demonstrated in a course in GoMentum Station in California. We demonstrated autonomous handling of 4 scenarios: traffic lights, cross-traffic at intersections, construction zones and pedestrians. The AD vehicle displayed safe behavior and performed consistently in repeated demonstrations with slight variations in conditions. Overall, we completed 44 runs, encompassing 110km of automated driving with only 3 cases where the driver intervened the control of the vehicle, mostly due to error in GPS positioning. Our demonstration showed that robust and consistent behavior in urban scenarios is possible, yet more investigation is necessary for full scale roll-out on public roads.