 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Hyperspectral AI: When Non-Convex Modeling meets Hyperspectral Remote Sensing
Mar 02, 2021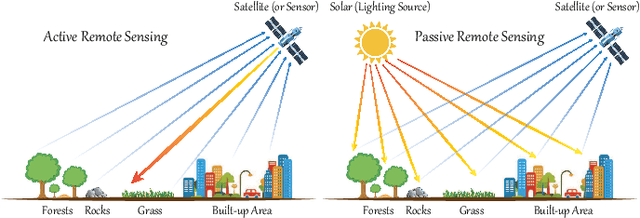


Hyperspectral imaging, also known as image spectrometry, is a landmark technique in geoscience and remote sensing (RS). In the past decade, enormous efforts have been made to process and analyze these hyperspectral (HS) products mainly by means of seasoned experts. However, with the ever-growing volume of data, the bulk of costs in manpower and material resources poses new challenges on reducing the burden of manual labor and improving efficiency. For this reason, it is, therefore, urgent to develop more intelligent and automatic approaches for various HS RS applications. Machine learning (ML) tools with convex optimization have successfully undertaken the tasks of numerous artificial intelligence (AI)-related applications. However, their ability in handling complex practical problems remains limited, particularly for HS data, due to the effects of various spectral variabilities in the process of HS imaging and the complexity and redundancy of higher dimensional HS signals. Compared to the convex models, non-convex modeling, which is capable of characterizing more complex real scenes and providing the model interpretability technically and theoretically, has been proven to be a feasible solution to reduce the gap between challenging HS vision tasks and currently advanced intelligent data processing models.
Physically-Constrained Transfer Learning through Shared Abundance Space for Hyperspectral Image Classification
Aug 30, 2020

Hyperspectral image (HSI) classification is one of the most active research topics and has achieved promising results boosted by the recent development of deep learning. However, most state-of-the-art approaches tend to perform poorly when the training and testing images are on different domains, e.g., source domain and target domain, respectively, due to the spectral variability caused by different acquisition conditions. Transfer learning-based methods address this problem by pre-training in the source domain and fine-tuning on the target domain. Nonetheless, a considerable amount of data on the target domain has to be labeled and non-negligible computational resources are required to retrain the whole network. In this paper, we propose a new transfer learning scheme to bridge the gap between the source and target domains by projecting the HSI data from the source and target domains into a shared abundance space based on their own physical characteristics. In this way, the domain discrepancy would be largely reduced such that the model trained on the source domain could be applied on the target domain without extra efforts for data labeling or network retraining. The proposed method is referred to as physically-constrained transfer learning through shared abundance space (PCTL-SAS). Extensive experimental results demonstrate the superiority of the proposed method as compared to the state-of-the-art. The success of this endeavor would largely facilitate the deployment of HSI classification for real-world sensing scenarios.
More Diverse Means Better: Multimodal Deep Learning Meets Remote Sensing Imagery Classification
Aug 12, 2020
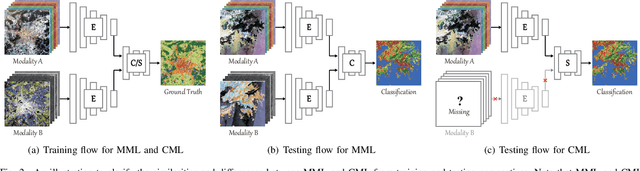
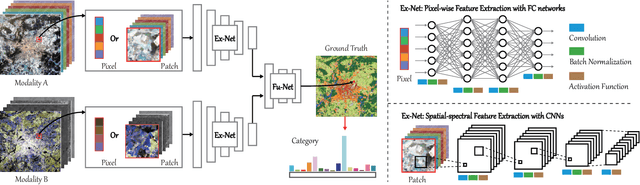
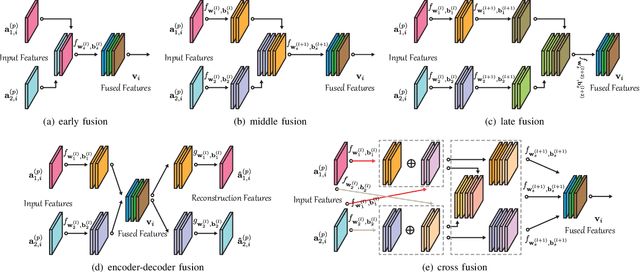
Classification and identification of the materials lying over or beneath the Earth's surface have long been a fundamental but challenging research topic in geoscience and remote sensing (RS) and have garnered a growing concern owing to the recent advancements of deep learning techniques. Although deep networks have been successfully applied in single-modality-dominated classification tasks, yet their performance inevitably meets the bottleneck in complex scenes that need to be finely classified, due to the limitation of information diversity. In this work, we provide a baseline solution to the aforementioned difficulty by developing a general multimodal deep learning (MDL) framework. In particular, we also investigate a special case of multi-modality learning (MML) -- cross-modality learning (CML) that exists widely in RS image classification applications. By focusing on "what", "where", and "how" to fuse, we show different fusion strategies as well as how to train deep networks and build the network architecture. Specifically, five fusion architectures are introduced and developed, further being unified in our MDL framework. More significantly, our framework is not only limited to pixel-wise classification tasks but also applicable to spatial information modeling with convolutional neural networks (CNNs). To validate the effectiveness and superiority of the MDL framework, extensive experiments related to the settings of MML and CML are conducted on two different multimodal RS datasets. Furthermore, the codes and datasets will be available at https://github.com/danfenghong/IEEE_TGRS_MDL-RS, contributing to the RS community.
Graph Convolutional Networks for Hyperspectral Image Classification
Aug 06, 2020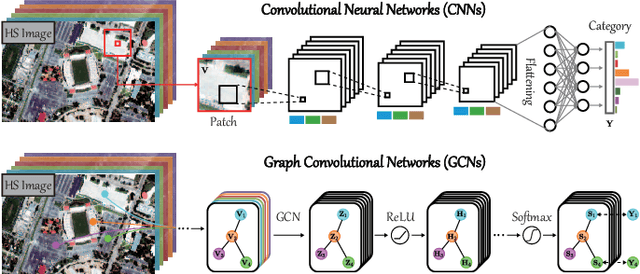
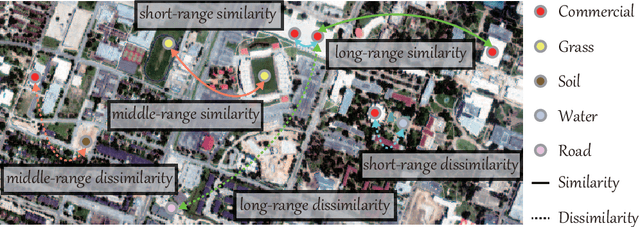
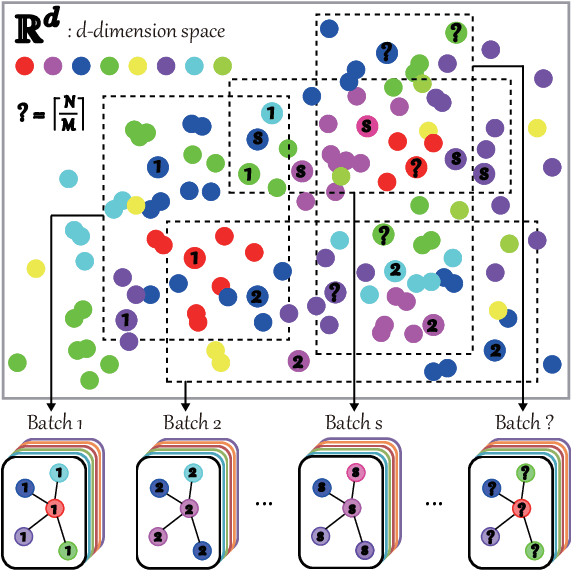
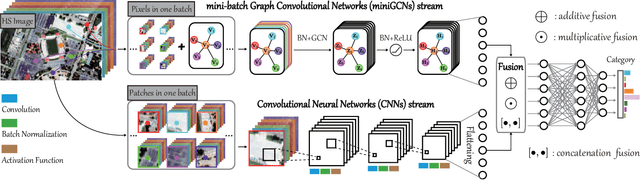
Convolutional neural networks (CNNs) have been attracting increasing attention in hyperspectral (HS) image classification, owing to their ability to capture spatial-spectral feature representations. Nevertheless, their ability in modeling relations between samples remains limited. Beyond the limitations of grid sampling, graph convolutional networks (GCNs) have been recently proposed and successfully applied in irregular (or non-grid) data representation and analysis. In this paper, we thoroughly investigate CNNs and GCNs (qualitatively and quantitatively) in terms of HS image classification. Due to the construction of the adjacency matrix on all the data, traditional GCNs usually suffer from a huge computational cost, particularly in large-scale remote sensing (RS) problems. To this end, we develop a new mini-batch GCN (called miniGCN hereinafter) which allows to train large-scale GCNs in a mini-batch fashion. More significantly, our miniGCN is capable of inferring out-of-sample data without re-training networks and improving classification performance. Furthermore, as CNNs and GCNs can extract different types of HS features, an intuitive solution to break the performance bottleneck of a single model is to fuse them. Since miniGCNs can perform batch-wise network training (enabling the combination of CNNs and GCNs) we explore three fusion strategies: additive fusion, element-wise multiplicative fusion, and concatenation fusion to measure the obtained performance gain. Extensive experiments, conducted on three HS datasets, demonstrate the advantages of miniGCNs over GCNs and the superiority of the tested fusion strategies with regards to the single CNN or GCN models. The codes of this work will be available at https://github.com/danfenghong/IEEE_TGRS_GCN for the sake of reproducibility.
Coupled Convolutional Neural Network with Adaptive Response Function Learning for Unsupervised Hyperspectral Super-Resolution
Jul 28, 2020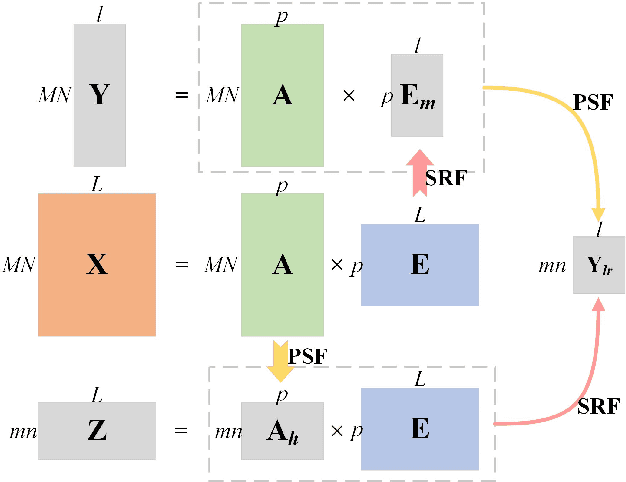
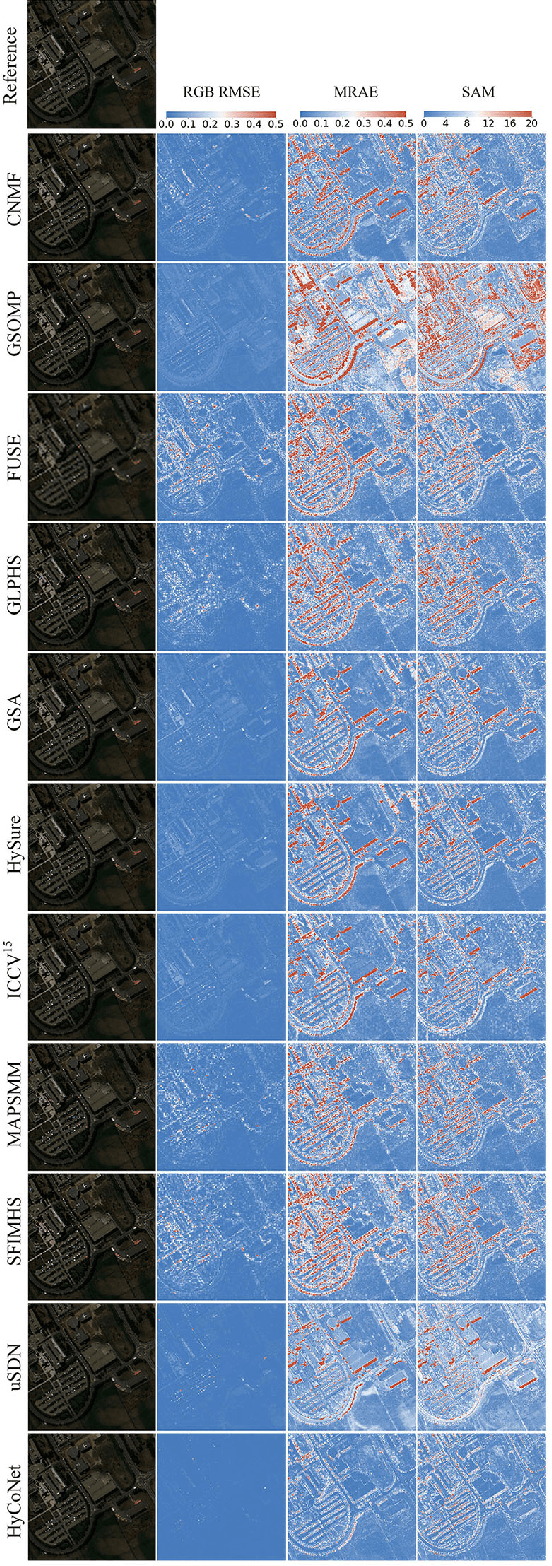
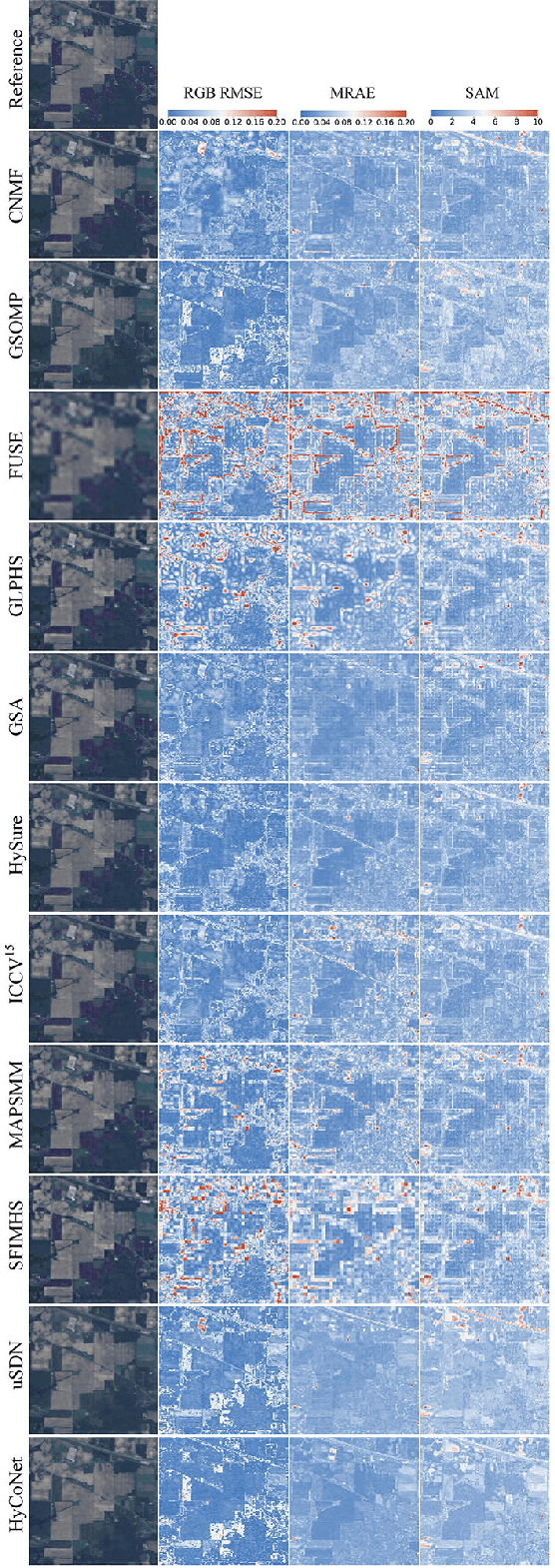
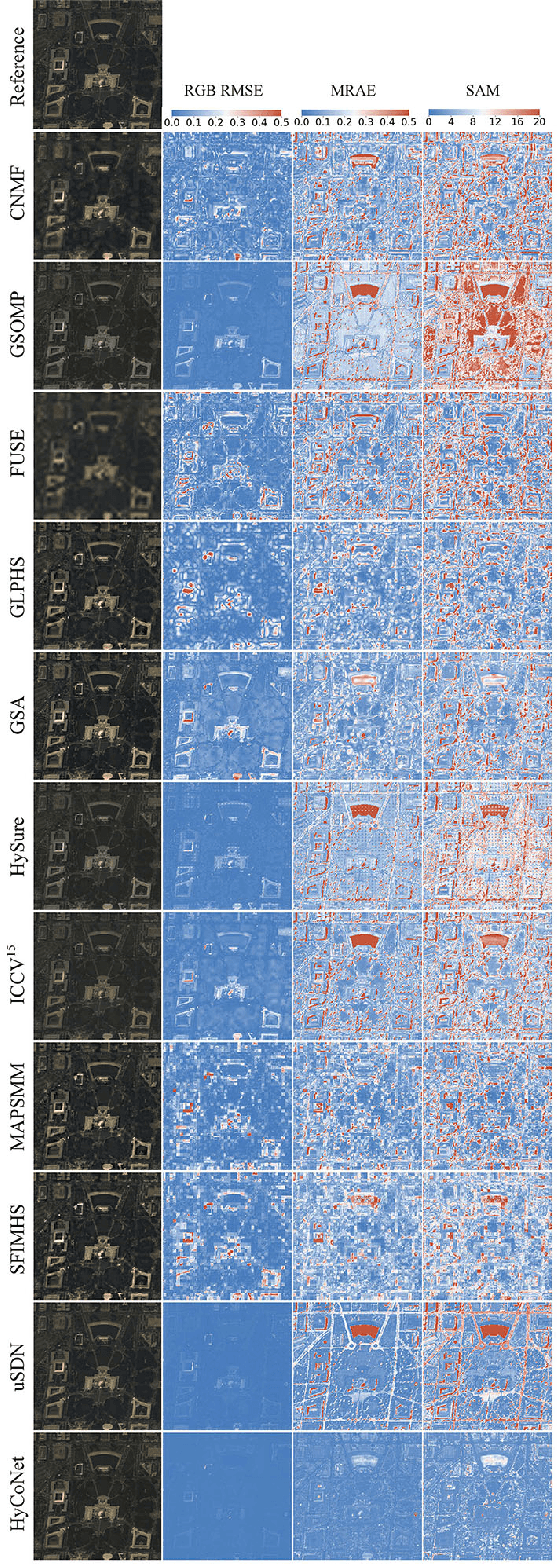
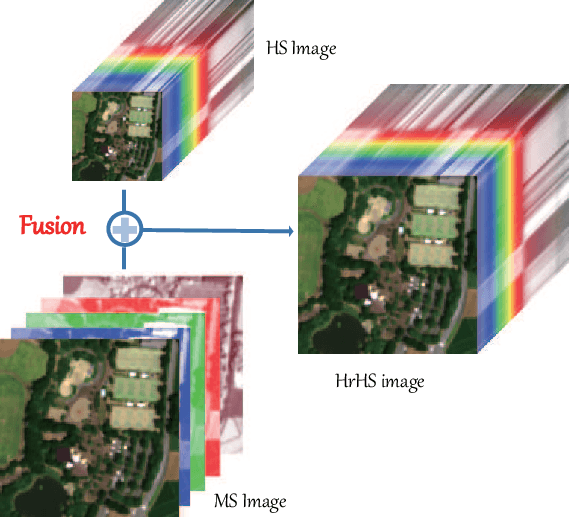
Due to the limitations of hyperspectral imaging systems, hyperspectral imagery (HSI) often suffers from poor spatial resolution, thus hampering many applications of the imagery. Hyperspectral super-resolution refers to fusing HSI and MSI to generate an image with both high spatial and high spectral resolutions. Recently, several new methods have been proposed to solve this fusion problem, and most of these methods assume that the prior information of the Point Spread Function (PSF) and Spectral Response Function (SRF) are known. However, in practice, this information is often limited or unavailable. In this work, an unsupervised deep learning-based fusion method - HyCoNet - that can solve the problems in HSI-MSI fusion without the prior PSF and SRF information is proposed. HyCoNet consists of three coupled autoencoder nets in which the HSI and MSI are unmixed into endmembers and abundances based on the linear unmixing model. Two special convolutional layers are designed to act as a bridge that coordinates with the three autoencoder nets, and the PSF and SRF parameters are learned adaptively in the two convolution layers during the training process. Furthermore, driven by the joint loss function, the proposed method is straightforward and easily implemented in an end-to-end training manner. The experiments performed in the study demonstrate that the proposed method performs well and produces robust results for different datasets and arbitrary PSFs and SRFs.
Spectral Superresolution of Multispectral Imagery with Joint Sparse and Low-Rank Learning
Jul 28, 2020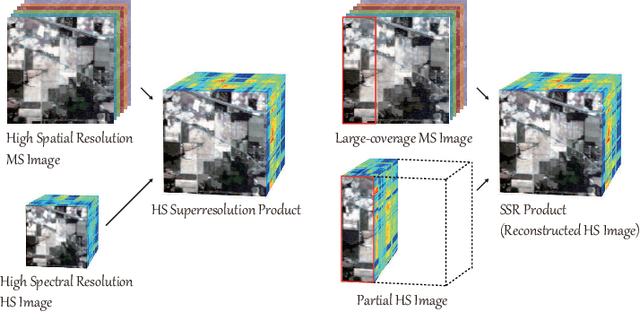
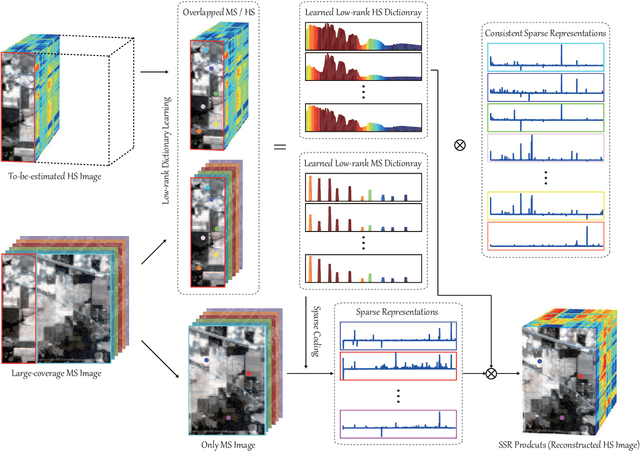

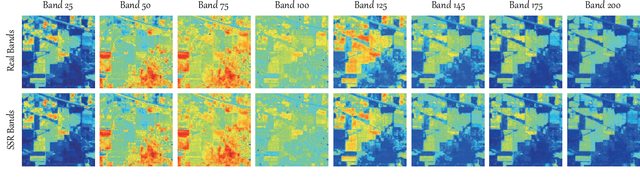
Extensive attention has been widely paid to enhance the spatial resolution of hyperspectral (HS) images with the aid of multispectral (MS) images in remote sensing. However, the ability in the fusion of HS and MS images remains to be improved, particularly in large-scale scenes, due to the limited acquisition of HS images. Alternatively, we super-resolve MS images in the spectral domain by the means of partially overlapped HS images, yielding a novel and promising topic: spectral superresolution (SSR) of MS imagery. This is challenging and less investigated task due to its high ill-posedness in inverse imaging. To this end, we develop a simple but effective method, called joint sparse and low-rank learning (J-SLoL), to spectrally enhance MS images by jointly learning low-rank HS-MS dictionary pairs from overlapped regions. J-SLoL infers and recovers the unknown hyperspectral signals over a larger coverage by sparse coding on the learned dictionary pair. Furthermore, we validate the SSR performance on three HS-MS datasets (two for classification and one for unmixing) in terms of reconstruction, classification, and unmixing by comparing with several existing state-of-the-art baselines, showing the effectiveness and superiority of the proposed J-SLoL algorithm. Furthermore, the codes and datasets will be available at: https://github.com/danfenghong/IEEE\_TGRS\_J-SLoL, contributing to the RS community.