 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Probing for Internal Visual Representations in Multimodal Large Language Models
May 07, 2026Despite the remarkable success of Multimodal Large Language Models (MLLMs) across diverse tasks, the internal mechanisms governing how they encode and ground distinct visual concepts remain poorly understood. To bridge this gap, we propose a causal framework based on activation steering to actively probe and manipulate internal visual representations. Through systematic intervention across four visual concept categories, our results reveal a divergence in concept encoding: entities exhibit distinct localized memorization, whereas abstract concepts are globally distributed across the network. Critically, this divergence uncovers a mechanistic driver of scaling laws: increasing model depth is indispensable for encoding distributed and complex abstract concepts, whereas entity localization remains remarkably invariant to scale. Furthermore, reverse steering uncovers that blocking explicit output triggers a surge in latent activations, exposing a compensatory mechanism between perception and generation. Finally, extending our analysis to visual reasoning, we expose a disconnect between perception and reasoning although MLLMs successfully recognize geometric relations, they treat them merely as static visual features, failing to trigger the procedural execution necessary for abstract problem-solving.
Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception
Feb 16, 2026Multimodal Large Language Models (MLLMs) excel at broad visual understanding but still struggle with fine-grained perception, where decisive evidence is small and easily overwhelmed by global context. Recent "Thinking-with-Images" methods alleviate this by iteratively zooming in and out regions of interest during inference, but incur high latency due to repeated tool calls and visual re-encoding. To address this, we propose Region-to-Image Distillation, which transforms zooming from an inference-time tool into a training-time primitive, thereby internalizing the benefits of agentic zooming into a single forward pass of an MLLM. In particular, we first zoom in to micro-cropped regions to let strong teacher models generate high-quality VQA data, and then distill this region-grounded supervision back to the full image. After training on such data, the smaller student model improves "single-glance" fine-grained perception without tool use. To rigorously evaluate this capability, we further present ZoomBench, a hybrid-annotated benchmark of 845 VQA data spanning six fine-grained perceptual dimensions, together with a dual-view protocol that quantifies the global--regional "zooming gap". Experiments show that our models achieve leading performance across multiple fine-grained perception benchmarks, and also improve general multimodal cognition on benchmarks such as visual reasoning and GUI agents. We further discuss when "Thinking-with-Images" is necessary versus when its gains can be distilled into a single forward pass. Our code is available at https://github.com/inclusionAI/Zooming-without-Zooming.
Attention Incorporate Network: A network can adapt various data size
Jun 06, 2018
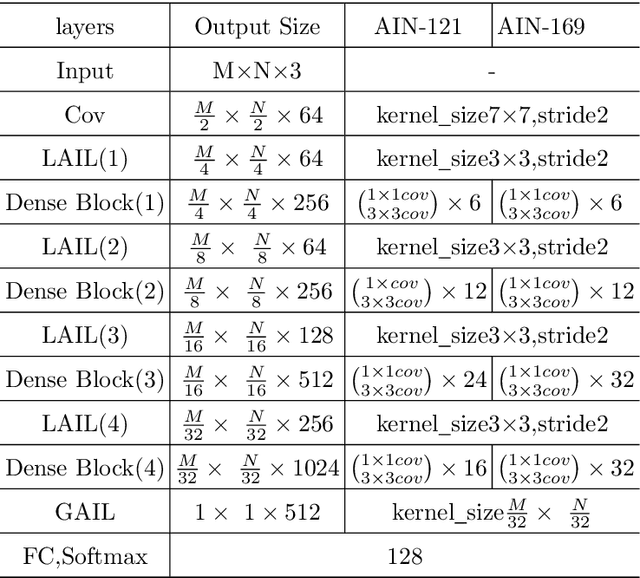


In traditional neural networks for image processing, the inputs of the neural networks should be the same size such as 224*224*3. But how can we train the neural net model with different input size? A common way to do is image deformation which accompany a problem of information loss (e.g. image crop or wrap). Sequence model(RNN, LSTM, etc.) can accept different size of input like text and audio. But one disadvantage for sequence model is that the previous information will become more fragmentary during the transfer in time step, it will make the network hard to train especially for long sequential data. In this paper we propose a new network structure called Attention Incorporate Network(AIN). It solve the problem of different size of inputs including: images, text, audio, and extract the key features of the inputs by attention mechanism, pay different attention depends on the importance of the features not rely on the data size. Experimentally, AIN achieve a higher accuracy, better convergence comparing to the same size of other network structure