 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Image Fusion with Spectral-Band and Fusion-Scale Agnosticism
Feb 02, 2026Current deep learning models for Multispectral and Hyperspectral Image Fusion (MS/HS fusion) are typically designed for fixed spectral bands and spatial scales, which limits their transferability across diverse sensors. To address this, we propose SSA, a universal framework for MS/HS fusion with spectral-band and fusion-scale agnosticism. Specifically, we introduce Matryoshka Kernel (MK), a novel operator that enables a single model to adapt to arbitrary numbers of spectral channels. Meanwhile, we build SSA upon an Implicit Neural Representation (INR) backbone that models the HS signal as a continuous function, enabling reconstruction at arbitrary spatial resolutions. Together, these two forms of agnosticism enable a single MS/HS fusion model that generalizes effectively to unseen sensors and spatial scales. Extensive experiments demonstrate that our single model achieves state-of-the-art performance while generalizing well to unseen sensors and scales, paving the way toward future HS foundation models.
Matrix Completion Via Reweighted Logarithmic Norm Minimization
Dec 24, 2025Low-rank matrix completion (LRMC) has demonstrated remarkable success in a wide range of applications. To address the NP-hard nature of the rank minimization problem, the nuclear norm is commonly used as a convex and computationally tractable surrogate for the rank function. However, this approach often yields suboptimal solutions due to the excessive shrinkage of singular values. In this letter, we propose a novel reweighted logarithmic norm as a more effective nonconvex surrogate, which provides a closer approximation than many existing alternatives. We efficiently solve the resulting optimization problem by employing the alternating direction method of multipliers (ADMM). Experimental results on image inpainting demonstrate that the proposed method achieves superior performance compared to state-of-the-art LRMC approaches, both in terms of visual quality and quantitative metrics.
A Knowledge-driven Adaptive Collaboration of LLMs for Enhancing Medical Decision-making
Sep 18, 2025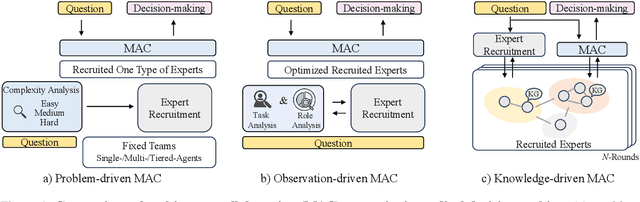
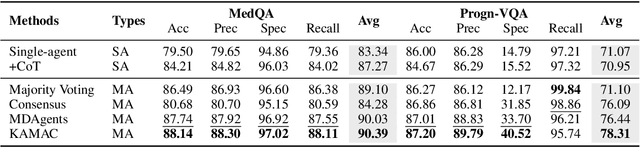
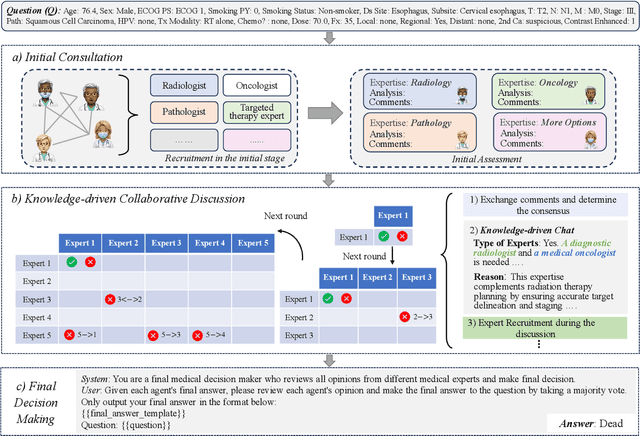
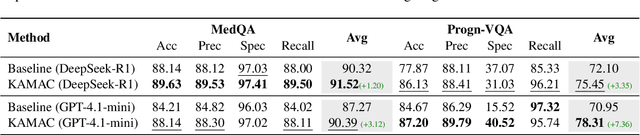
Medical decision-making often involves integrating knowledge from multiple clinical specialties, typically achieved through multidisciplinary teams. Inspired by this collaborative process, recent work has leveraged large language models (LLMs) in multi-agent collaboration frameworks to emulate expert teamwork. While these approaches improve reasoning through agent interaction, they are limited by static, pre-assigned roles, which hinder adaptability and dynamic knowledge integration. To address these limitations, we propose KAMAC, a Knowledge-driven Adaptive Multi-Agent Collaboration framework that enables LLM agents to dynamically form and expand expert teams based on the evolving diagnostic context. KAMAC begins with one or more expert agents and then conducts a knowledge-driven discussion to identify and fill knowledge gaps by recruiting additional specialists as needed. This supports flexible, scalable collaboration in complex clinical scenarios, with decisions finalized through reviewing updated agent comments. Experiments on two real-world medical benchmarks demonstrate that KAMAC significantly outperforms both single-agent and advanced multi-agent methods, particularly in complex clinical scenarios (i.e., cancer prognosis) requiring dynamic, cross-specialty expertise. Our code is publicly available at: https://github.com/XiaoXiao-Woo/KAMAC.
Training and Inference within 1 Second -- Tackle Cross-Sensor Degradation of Real-World Pansharpening with Efficient Residual Feature Tailoring
Aug 10, 2025Deep learning methods for pansharpening have advanced rapidly, yet models pretrained on data from a specific sensor often generalize poorly to data from other sensors. Existing methods to tackle such cross-sensor degradation include retraining model or zero-shot methods, but they are highly time-consuming or even need extra training data. To address these challenges, our method first performs modular decomposition on deep learning-based pansharpening models, revealing a general yet critical interface where high-dimensional fused features begin mapping to the channel space of the final image. % may need revisement A Feature Tailor is then integrated at this interface to address cross-sensor degradation at the feature level, and is trained efficiently with physics-aware unsupervised losses. Moreover, our method operates in a patch-wise manner, training on partial patches and performing parallel inference on all patches to boost efficiency. Our method offers two key advantages: (1) $\textit{Improved Generalization Ability}$: it significantly enhance performance in cross-sensor cases. (2) $\textit{Low Generalization Cost}$: it achieves sub-second training and inference, requiring only partial test inputs and no external data, whereas prior methods often take minutes or even hours. Experiments on the real-world data from multiple datasets demonstrate that our method achieves state-of-the-art quality and efficiency in tackling cross-sensor degradation. For example, training and inference of $512\times512\times8$ image within $\textit{0.2 seconds}$ and $4000\times4000\times8$ image within $\textit{3 seconds}$ at the fastest setting on a commonly used RTX 3090 GPU, which is over 100 times faster than zero-shot methods.
SWIFT: A General Sensitive Weight Identification Framework for Fast Sensor-Transfer Pansharpening
Jul 27, 2025Pansharpening aims to fuse high-resolution panchromatic (PAN) images with low-resolution multispectral (LRMS) images to generate high-resolution multispectral (HRMS) images. Although deep learning-based methods have achieved promising performance, they generally suffer from severe performance degradation when applied to data from unseen sensors. Adapting these models through full-scale retraining or designing more complex architectures is often prohibitively expensive and impractical for real-world deployment. To address this critical challenge, we propose a fast and general-purpose framework for cross-sensor adaptation, SWIFT (Sensitive Weight Identification for Fast Transfer). Specifically, SWIFT employs an unsupervised sampling strategy based on data manifold structures to balance sample selection while mitigating the bias of traditional Farthest Point Sampling, efficiently selecting only 3\% of the most informative samples from the target domain. This subset is then used to probe a source-domain pre-trained model by analyzing the gradient behavior of its parameters, allowing for the quick identification and subsequent update of only the weight subset most sensitive to the domain shift. As a plug-and-play framework, SWIFT can be applied to various existing pansharpening models. Extensive experiments demonstrate that SWIFT reduces the adaptation time from hours to approximately one minute on a single NVIDIA RTX 4090 GPU. The adapted models not only substantially outperform direct-transfer baselines but also achieve performance competitive with, and in some cases superior to, full retraining, establishing a new state-of-the-art on cross-sensor pansharpening tasks for the WorldView-2 and QuickBird datasets.
CAT: A Conditional Adaptation Tailor for Efficient and Effective Instance-Specific Pansharpening on Real-World Data
Apr 14, 2025Pansharpening is a crucial remote sensing technique that fuses low-resolution multispectral (LRMS) images with high-resolution panchromatic (PAN) images to generate high-resolution multispectral (HRMS) imagery. Although deep learning techniques have significantly advanced pansharpening, many existing methods suffer from limited cross-sensor generalization and high computational overhead, restricting their real-time applications. To address these challenges, we propose an efficient framework that quickly adapts to a specific input instance, completing both training and inference in a short time. Our framework splits the input image into multiple patches, selects a subset for unsupervised CAT training, and then performs inference on all patches, stitching them into the final output. The CAT module, integrated between the feature extraction and channel transformation stages of a pre-trained network, tailors the fused features and fixes the parameters for efficient inference, generating improved results. Our approach offers two key advantages: (1) $\textit{Improved Generalization Ability}$: by mitigating cross-sensor degradation, our model--although pre-trained on a specific dataset--achieves superior performance on datasets captured by other sensors; (2) $\textit{Enhanced Computational Efficiency}$: the CAT-enhanced network can swiftly adapt to the test sample using the single LRMS-PAN pair input, without requiring extensive large-scale data retraining. Experiments on the real-world data from WorldView-3 and WorldView-2 datasets demonstrate that our method achieves state-of-the-art performance on cross-sensor real-world data, while achieving both training and inference of $512\times512$ image within $\textit{0.4 seconds}$ and $4000\times4000$ image within $\textit{3 seconds}$ at the fastest setting on a commonly used RTX 3090 GPU.
Taming Flow Matching with Unbalanced Optimal Transport into Fast Pansharpening
Mar 19, 2025



Pansharpening, a pivotal task in remote sensing for fusing high-resolution panchromatic and multispectral imagery, has garnered significant research interest. Recent advancements employing diffusion models based on stochastic differential equations (SDEs) have demonstrated state-of-the-art performance. However, the inherent multi-step sampling process of SDEs imposes substantial computational overhead, hindering practical deployment. While existing methods adopt efficient samplers, knowledge distillation, or retraining to reduce sampling steps (e.g., from 1,000 to fewer steps), such approaches often compromise fusion quality. In this work, we propose the Optimal Transport Flow Matching (OTFM) framework, which integrates the dual formulation of unbalanced optimal transport (UOT) to achieve one-step, high-quality pansharpening. Unlike conventional OT formulations that enforce rigid distribution alignment, UOT relaxes marginal constraints to enhance modeling flexibility, accommodating the intrinsic spectral and spatial disparities in remote sensing data. Furthermore, we incorporate task-specific regularization into the UOT objective, enhancing the robustness of the flow model. The OTFM framework enables simulation-free training and single-step inference while maintaining strict adherence to pansharpening constraints. Experimental evaluations across multiple datasets demonstrate that OTFM matches or exceeds the performance of previous regression-based models and leading diffusion-based methods while only needing one sampling step. Codes are available at https://github.com/294coder/PAN-OTFM.
MMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance
Mar 19, 2025



Image fusion, a fundamental low-level vision task, aims to integrate multiple image sequences into a single output while preserving as much information as possible from the input. However, existing methods face several significant limitations: 1) requiring task- or dataset-specific models; 2) neglecting real-world image degradations (\textit{e.g.}, noise), which causes failure when processing degraded inputs; 3) operating in pixel space, where attention mechanisms are computationally expensive; and 4) lacking user interaction capabilities. To address these challenges, we propose a unified framework for multi-task, multi-degradation, and language-guided image fusion. Our framework includes two key components: 1) a practical degradation pipeline that simulates real-world image degradations and generates interactive prompts to guide the model; 2) an all-in-one Diffusion Transformer (DiT) operating in latent space, which fuses a clean image conditioned on both the degraded inputs and the generated prompts. Furthermore, we introduce principled modifications to the original DiT architecture to better suit the fusion task. Based on this framework, we develop two versions of the model: Regression-based and Flow Matching-based variants. Extensive qualitative and quantitative experiments demonstrate that our approach effectively addresses the aforementioned limitations and outperforms previous restoration+fusion and all-in-one pipelines. Codes are available at https://github.com/294coder/MMAIF.
Exploring the Low-Pass Filtering Behavior in Image Super-Resolution
May 17, 2024



Deep neural networks for image super-resolution (ISR) have shown significant advantages over traditional approaches like the interpolation. However, they are often criticized as 'black boxes' compared to traditional approaches with solid mathematical foundations. In this paper, we attempt to interpret the behavior of deep neural networks in ISR using theories from the field of signal processing. First, we report an intriguing phenomenon, referred to as `the sinc phenomenon.' It occurs when an impulse input is fed to a neural network. Then, building on this observation, we propose a method named Hybrid Response Analysis (HyRA) to analyze the behavior of neural networks in ISR tasks. Specifically, HyRA decomposes a neural network into a parallel connection of a linear system and a non-linear system and demonstrates that the linear system functions as a low-pass filter while the non-linear system injects high-frequency information. Finally, to quantify the injected high-frequency information, we introduce a metric for image-to-image tasks called Frequency Spectrum Distribution Similarity (FSDS). FSDS reflects the distribution similarity of different frequency components and can capture nuances that traditional metrics may overlook. Code, videos and raw experimental results for this paper can be found in: https://github.com/RisingEntropy/LPFInISR.
Fourier-enhanced Implicit Neural Fusion Network for Multispectral and Hyperspectral Image Fusion
Apr 23, 2024



Recently, implicit neural representations (INR) have made significant strides in various vision-related domains, providing a novel solution for Multispectral and Hyperspectral Image Fusion (MHIF) tasks. However, INR is prone to losing high-frequency information and is confined to the lack of global perceptual capabilities. To address these issues, this paper introduces a Fourier-enhanced Implicit Neural Fusion Network (FeINFN) specifically designed for MHIF task, targeting the following phenomena: The Fourier amplitudes of the HR-HSI latent code and LR-HSI are remarkably similar; however, their phases exhibit different patterns. In FeINFN, we innovatively propose a spatial and frequency implicit fusion function (Spa-Fre IFF), helping INR capture high-frequency information and expanding the receptive field. Besides, a new decoder employing a complex Gabor wavelet activation function, called Spatial-Frequency Interactive Decoder (SFID), is invented to enhance the interaction of INR features. Especially, we further theoretically prove that the Gabor wavelet activation possesses a time-frequency tightness property that favors learning the optimal bandwidths in the decoder. Experiments on two benchmark MHIF datasets verify the state-of-the-art (SOTA) performance of the proposed method, both visually and quantitatively. Also, ablation studies demonstrate the mentioned contributions. The code will be available on Anonymous GitHub (https://anonymous.4open.science/r/FeINFN-15C9/) after possible acceptance.