 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 6th AI City Challenge
Apr 21, 2022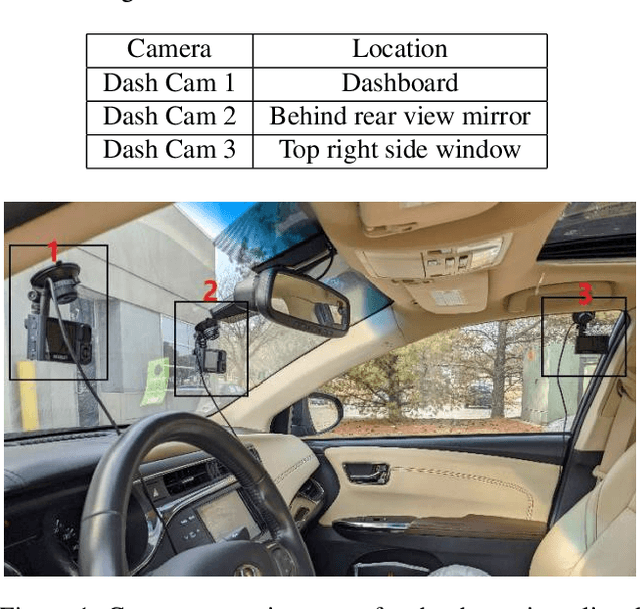
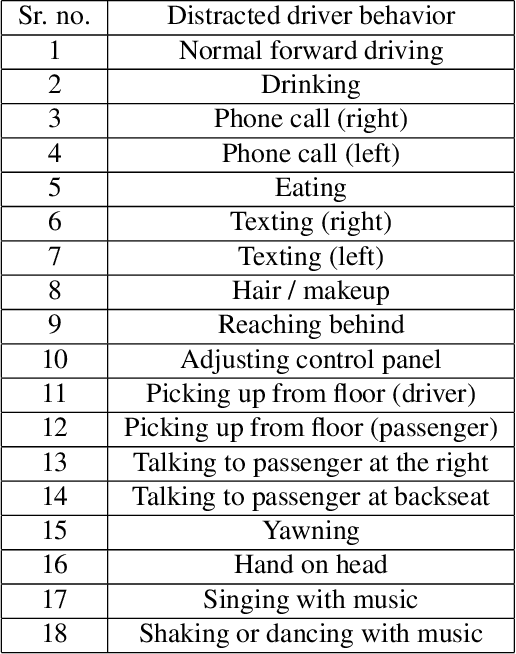
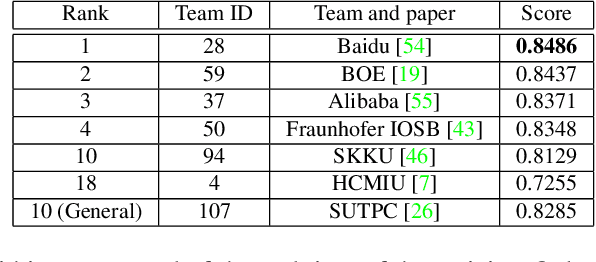
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
Attribute Descent: Simulating Object-Centric Datasets on the Content Level and Beyond
Feb 28, 2022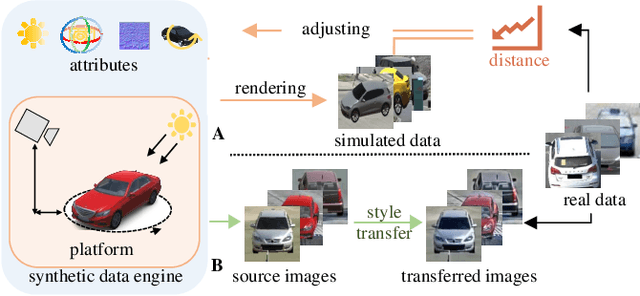
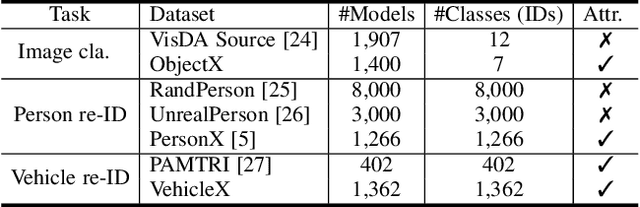

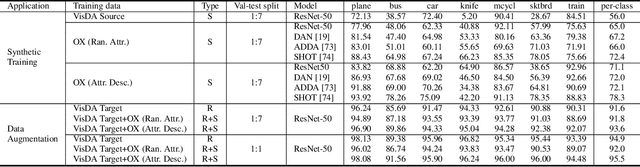
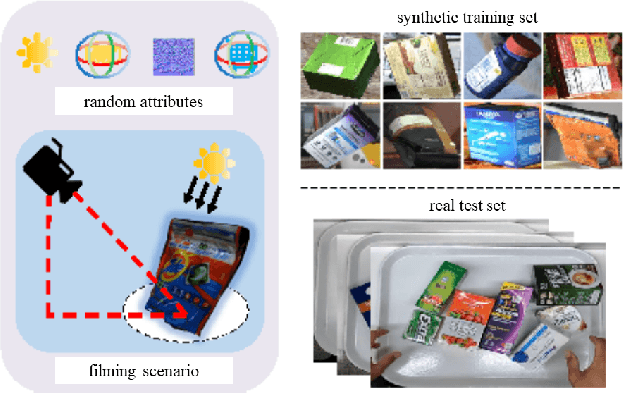
This article aims to use graphic engines to simulate a large number of training data that have free annotations and possibly strongly resemble to real-world data. Between synthetic and real, a two-level domain gap exists, involving content level and appearance level. While the latter is concerned with appearance style, the former problem arises from a different mechanism, i.e., content mismatch in attributes such as camera viewpoint, object placement and lighting conditions. In contrast to the widely-studied appearance-level gap, the content-level discrepancy has not been broadly studied. To address the content-level misalignment, we propose an attribute descent approach that automatically optimizes engine attributes to enable synthetic data to approximate real-world data. We verify our method on object-centric tasks, wherein an object takes up a major portion of an image. In these tasks, the search space is relatively small, and the optimization of each attribute yields sufficiently obvious supervision signals. We collect a new synthetic asset VehicleX, and reformat and reuse existing the synthetic assets ObjectX and PersonX. Extensive experiments on image classification and object re-identification confirm that adapted synthetic data can be effectively used in three scenarios: training with synthetic data only, training data augmentation and numerically understanding dataset content.
Intelli-Paint: Towards Developing Human-like Painting Agents
Dec 16, 2021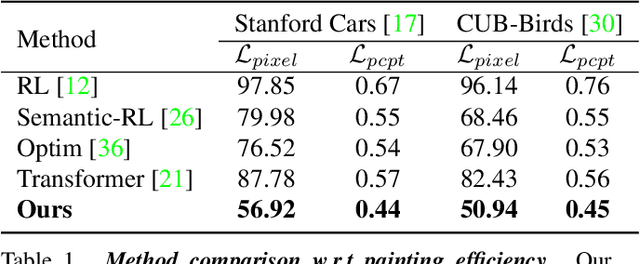
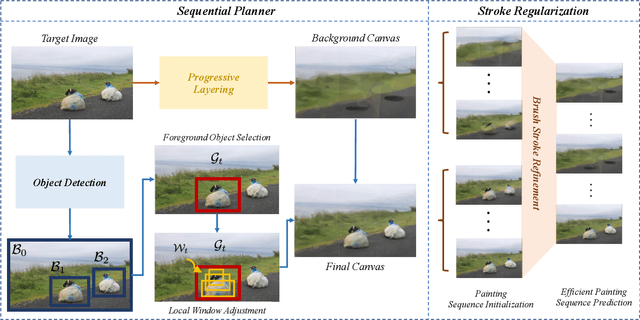


The generation of well-designed artwork is often quite time-consuming and assumes a high degree of proficiency on part of the human painter. In order to facilitate the human painting process, substantial research efforts have been made on teaching machines how to "paint like a human", and then using the trained agent as a painting assistant tool for human users. However, current research in this direction is often reliant on a progressive grid-based division strategy wherein the agent divides the overall image into successively finer grids, and then proceeds to paint each of them in parallel. This inevitably leads to artificial painting sequences which are not easily intelligible to human users. To address this, we propose a novel painting approach which learns to generate output canvases while exhibiting a more human-like painting style. The proposed painting pipeline Intelli-Paint consists of 1) a progressive layering strategy which allows the agent to first paint a natural background scene representation before adding in each of the foreground objects in a progressive fashion. 2) We also introduce a novel sequential brushstroke guidance strategy which helps the painting agent to shift its attention between different image regions in a semantic-aware manner. 3) Finally, we propose a brushstroke regularization strategy which allows for ~60-80% reduction in the total number of required brushstrokes without any perceivable differences in the quality of the generated canvases. Through both quantitative and qualitative results, we show that the resulting agents not only show enhanced efficiency in output canvas generation but also exhibit a more natural-looking painting style which would better assist human users express their ideas through digital artwork.
Adaptive Affinity for Associations in Multi-Target Multi-Camera Tracking
Dec 14, 2021
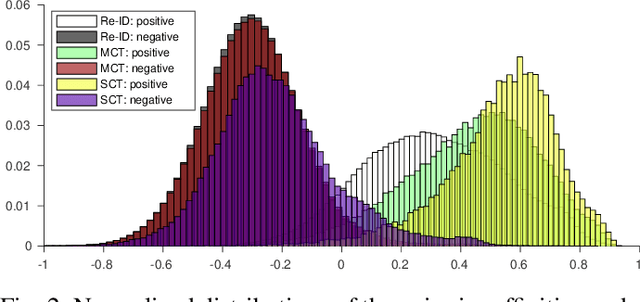
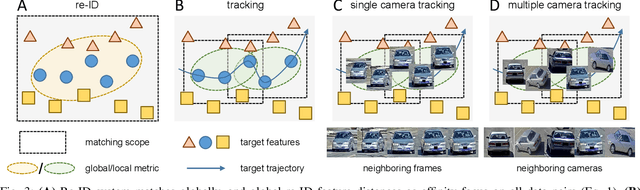
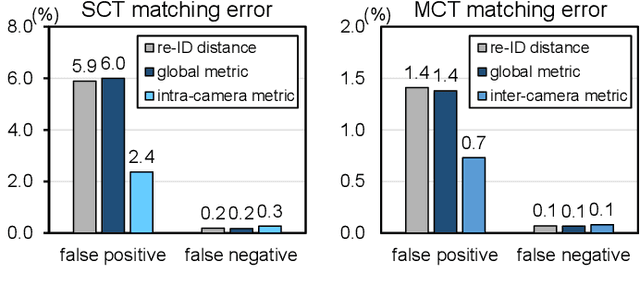
Data associations in multi-target multi-camera tracking (MTMCT) usually estimate affinity directly from re-identification (re-ID) feature distances. However, we argue that it might not be the best choice given the difference in matching scopes between re-ID and MTMCT problems. Re-ID systems focus on global matching, which retrieves targets from all cameras and all times. In contrast, data association in tracking is a local matching problem, since its candidates only come from neighboring locations and time frames. In this paper, we design experiments to verify such misfit between global re-ID feature distances and local matching in tracking, and propose a simple yet effective approach to adapt affinity estimations to corresponding matching scopes in MTMCT. Instead of trying to deal with all appearance changes, we tailor the affinity metric to specialize in ones that might emerge during data associations. To this end, we introduce a new data sampling scheme with temporal windows originally used for data associations in tracking. Minimizing the mismatch, the adaptive affinity module brings significant improvements over global re-ID distance, and produces competitive performance on CityFlow and DukeMTMC datasets.
Action Units That Constitute Trainable Micro-expressions (and A Large-scale Synthetic Dataset)
Dec 10, 2021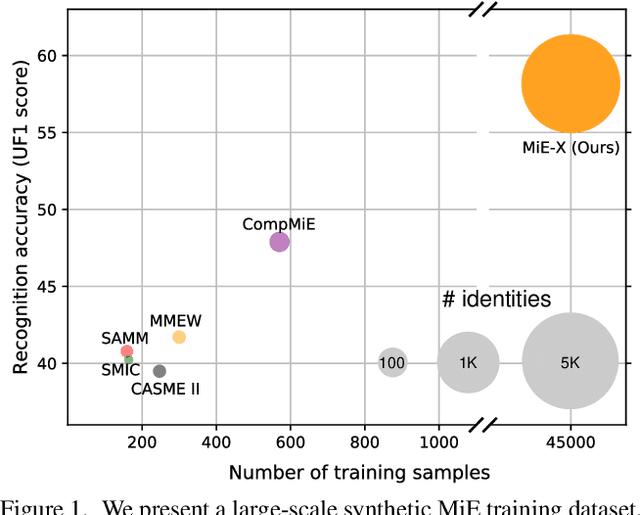
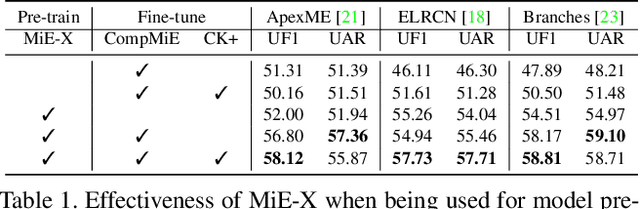
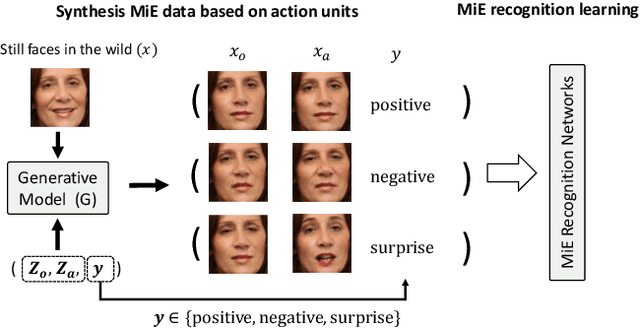
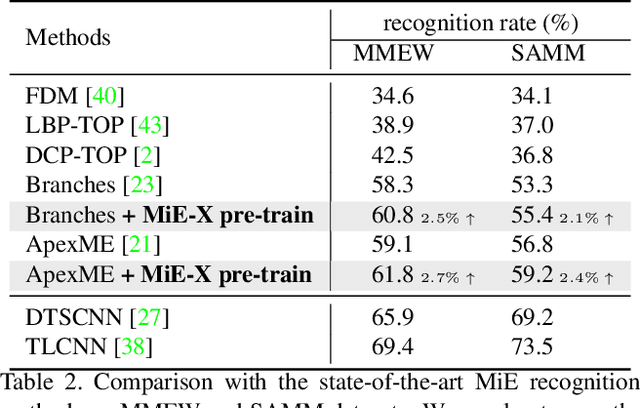
Due to the expensive data collection process, micro-expression datasets are generally much smaller in scale than those in other computer vision fields, rendering large-scale training less stable and feasible. In this paper, we aim to develop a protocol to automatically synthesize micro-expression training data that 1) are on a large scale and 2) allow us to train recognition models with strong accuracy on real-world test sets. Specifically, we discover three types of Action Units (AUs) that can well constitute trainable micro-expressions. These AUs come from real-world micro-expressions, early frames of macro-expressions, and the relationship between AUs and expression labels defined by human knowledge. With these AUs, our protocol then employs large numbers of face images with various identities and an existing face generation method for micro-expression synthesis. Micro-expression recognition models are trained on the generated micro-expression datasets and evaluated on real-world test sets, where very competitive and stable performance is obtained. The experimental results not only validate the effectiveness of these AUs and our dataset synthesis protocol but also reveal some critical properties of micro-expressions: they generalize across faces, are close to early-stage macro-expressions, and can be manually defined.
Voxelized 3D Feature Aggregation for Multiview Detection
Dec 07, 2021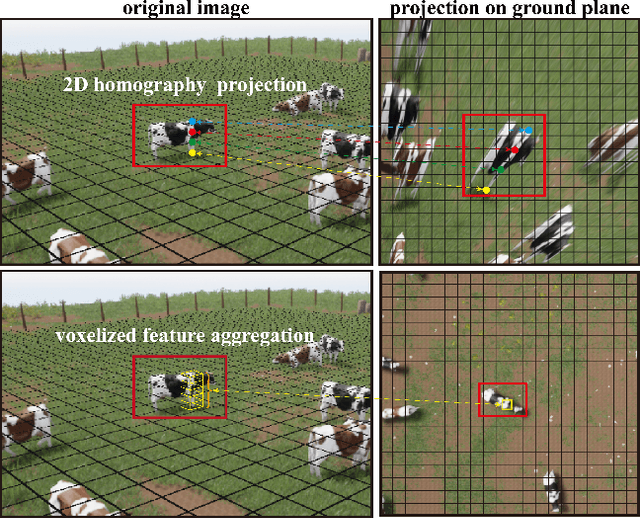
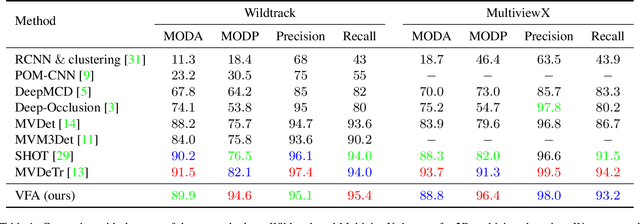
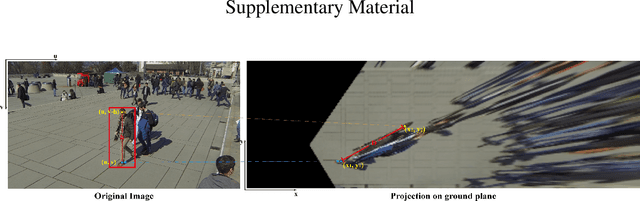

Multi-view detection incorporates multiple camera views to alleviate occlusion in crowded scenes, where the state-of-the-art approaches adopt homography transformations to project multi-view features to the ground plane. However, we find that these 2D transformations do not take into account the object's height, and with this neglection features along the vertical direction of same object are likely not projected onto the same ground plane point, leading to impure ground-plane features. To solve this problem, we propose VFA, voxelized 3D feature aggregation, for feature transformation and aggregation in multi-view detection. Specifically, we voxelize the 3D space, project the voxels onto each camera view, and associate 2D features with these projected voxels. This allows us to identify and then aggregate 2D features along the same vertical line, alleviating projection distortions to a large extent. Additionally, because different kinds of objects (human vs. cattle) have different shapes on the ground plane, we introduce the oriented Gaussian encoding to match such shapes, leading to increased accuracy and efficiency. We perform experiments on multiview 2D detection and multiview 3D detection problems. Results on four datasets (including a newly introduced MultiviewC dataset) show that our system is very competitive compared with the state-of-the-art approaches. %Our code and data will be open-sourced.Code and MultiviewC are released at https://github.com/Robert-Mar/VFA.
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Dec 01, 2021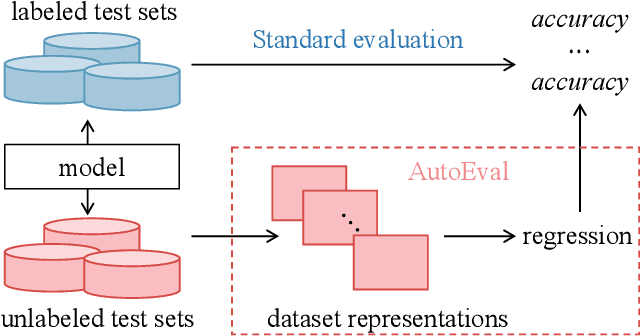
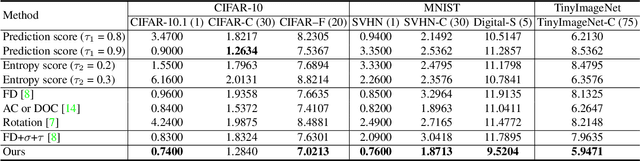


Label-free model evaluation, or AutoEval, estimates model accuracy on unlabeled test sets, and is critical for understanding model behaviors in various unseen environments. In the absence of image labels, based on dataset representations, we estimate model performance for AutoEval with regression. On the one hand, image feature is a straightforward choice for such representations, but it hampers regression learning due to being unstructured (\ie no specific meanings for component at certain location) and of large-scale. On the other hand, previous methods adopt simple structured representations (like average confidence or average feature), but insufficient to capture the data characteristics given their limited dimensions. In this work, we take the best of both worlds and propose a new semi-structured dataset representation that is manageable for regression learning while containing rich information for AutoEval. Based on image features, we integrate distribution shapes, clusters, and representative samples for a semi-structured dataset representation. Besides the structured overall description with distribution shapes, the unstructured description with clusters and representative samples include additional fine-grained information facilitating the AutoEval task. On three existing datasets and 25 newly introduced ones, we experimentally show that the proposed representation achieves competitive results. Code and dataset are available at https://github.com/sxzrt/Semi-Structured-Dataset-Representations.
Hierarchical Image Classification with A Literally Toy Dataset
Nov 01, 2021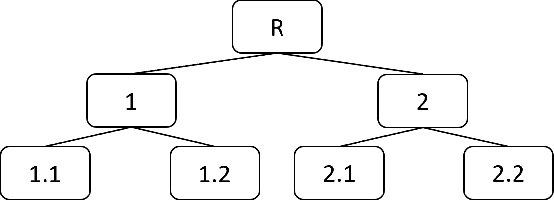
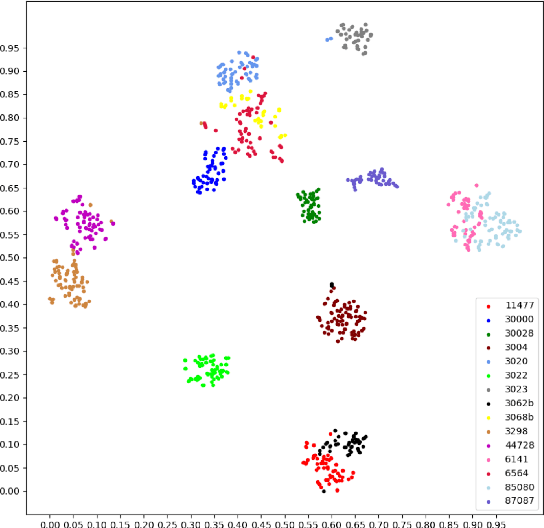
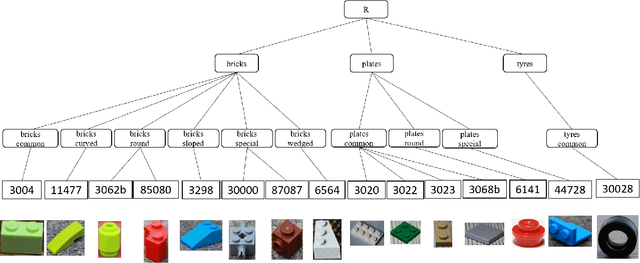
Unsupervised domain adaptation (UDA) in image classification remains a big challenge. In existing UDA image dataset, classes are usually organized in a flattened way, where a plain classifier can be trained. Yet in some scenarios, the flat categories originate from some base classes. For example, buggies belong to the class bird. We define the classification task where classes have characteristics above and the flat classes and the base classes are organized hierarchically as hierarchical image classification. Intuitively, leveraging such hierarchical structure will benefit hierarchical image classification, e.g., two easily confusing classes may belong to entirely different base classes. In this paper, we improve the performance of classification by fusing features learned from a hierarchy of labels. Specifically, we train feature extractors supervised by hierarchical labels and with UDA technology, which will output multiple features for an input image. The features are subsequently concatenated to predict the finest-grained class. This study is conducted with a new dataset named Lego-15. Consisting of synthetic images and real images of the Lego bricks, the Lego-15 dataset contains 15 classes of bricks. Each class originates from a coarse-level label and a middle-level label. For example, class "85080" is associated with bricks (coarse) and bricks round (middle). In this dataset, we demonstrate that our method brings about consistent improvement over the baseline in UDA in hierarchical image classification. Extensive ablation and variant studies provide insights into the new dataset and the investigated algorithm.
Ranking Models in Unlabeled New Environments
Sep 06, 2021
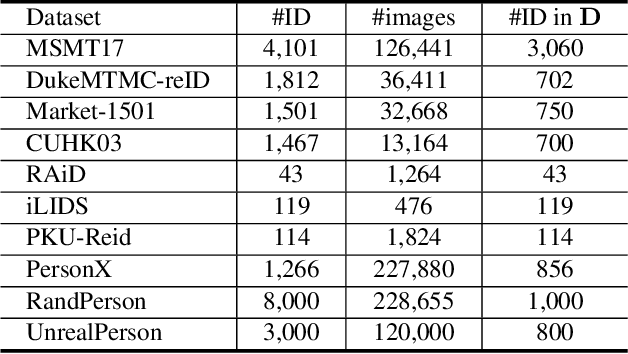
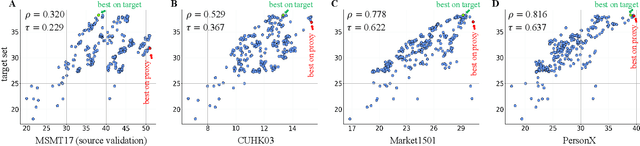
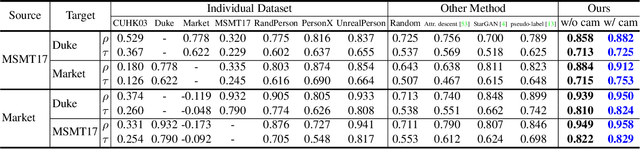
Consider a scenario where we are supplied with a number of ready-to-use models trained on a certain source domain and hope to directly apply the most appropriate ones to different target domains based on the models' relative performance. Ideally we should annotate a validation set for model performance assessment on each new target environment, but such annotations are often very expensive. Under this circumstance, we introduce the problem of ranking models in unlabeled new environments. For this problem, we propose to adopt a proxy dataset that 1) is fully labeled and 2) well reflects the true model rankings in a given target environment, and use the performance rankings on the proxy sets as surrogates. We first select labeled datasets as the proxy. Specifically, datasets that are more similar to the unlabeled target domain are found to better preserve the relative performance rankings. Motivated by this, we further propose to search the proxy set by sampling images from various datasets that have similar distributions as the target. We analyze the problem and its solutions on the person re-identification (re-ID) task, for which sufficient datasets are publicly available, and show that a carefully constructed proxy set effectively captures relative performance ranking in new environments. Code is available at \url{https://github.com/sxzrt/Proxy-Set}.
Memory-Free Generative Replay For Class-Incremental Learning
Sep 01, 2021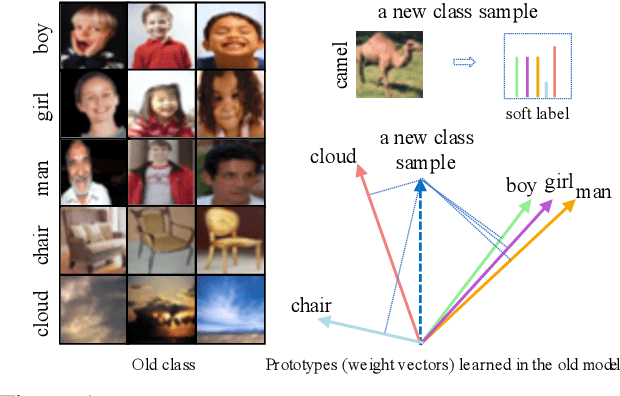

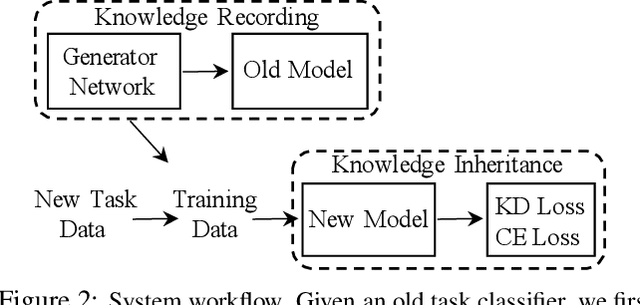

Regularization-based methods are beneficial to alleviate the catastrophic forgetting problem in class-incremental learning. With the absence of old task images, they often assume that old knowledge is well preserved if the classifier produces similar output on new images. In this paper, we find that their effectiveness largely depends on the nature of old classes: they work well on classes that are easily distinguishable between each other but may fail on more fine-grained ones, e.g., boy and girl. In spirit, such methods project new data onto the feature space spanned by the weight vectors in the fully connected layer, corresponding to old classes. The resulting projections would be similar on fine-grained old classes, and as a consequence the new classifier will gradually lose the discriminative ability on these classes. To address this issue, we propose a memory-free generative replay strategy to preserve the fine-grained old classes characteristics by generating representative old images directly from the old classifier and combined with new data for new classifier training. To solve the homogenization problem of the generated samples, we also propose a diversity loss that maximizes Kullback Leibler (KL) divergence between generated samples. Our method is best complemented by prior regularization-based methods proved to be effective for easily distinguishable old classes. We validate the above design and insights on CUB-200-2011, Caltech-101, CIFAR-100 and Tiny ImageNet and show that our strategy outperforms existing memory-free methods with a clear margin. Code is available at https://github.com/xmengxin/MFGR