 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAM: Masked Acoustic Modeling for End-to-End Speech-to-Text Translation
Oct 22, 2020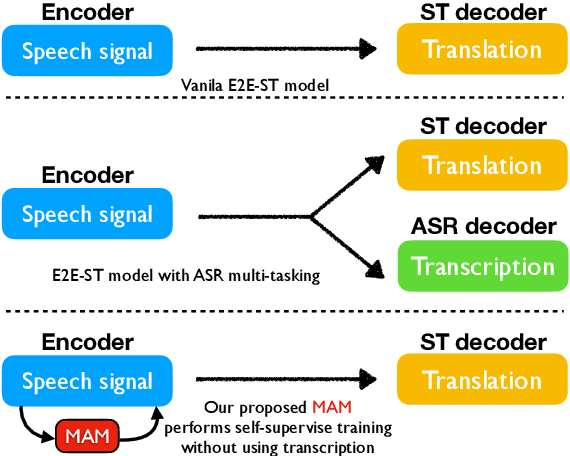
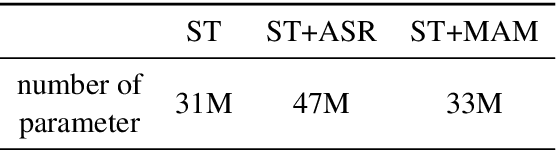

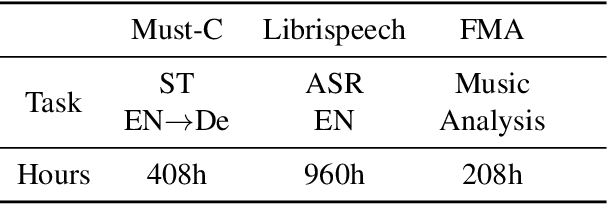
End-to-end Speech-to-text Translation (E2E- ST), which directly translates source language speech to target language text, is widely useful in practice, but traditional cascaded approaches (ASR+MT) often suffer from error propagation in the pipeline. On the other hand, existing end-to-end solutions heavily depend on the source language transcriptions for pre-training or multi-task training with Automatic Speech Recognition (ASR). We instead propose a simple technique to learn a robust speech encoder in a self-supervised fashion only on the speech side, which can utilize speech data without transcription. This technique, termed Masked Acoustic Modeling (MAM), can also perform pre-training, for the first time, on any acoustic signals (including non-speech ones) without annotation. Compared with current state-of-the-art models on ST, our technique achieves +1.4 BLEU improvement without using transcriptions, and +1.2 BLEU using transcriptions. The pre-training of MAM with arbitrary acoustic signals also boosts the downstream speech-related tasks.
Fluent and Low-latency Simultaneous Speech-to-Speech Translation with Self-adaptive Training
Oct 21, 2020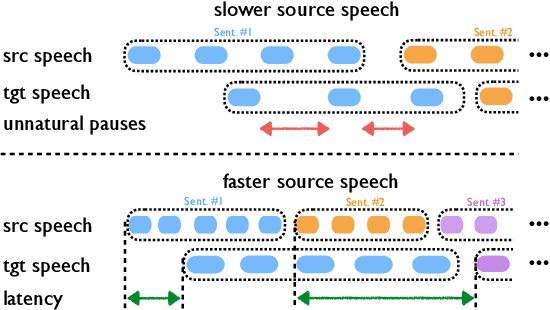
Simultaneous speech-to-speech translation is widely useful but extremely challenging, since it needs to generate target-language speech concurrently with the source-language speech, with only a few seconds delay. In addition, it needs to continuously translate a stream of sentences, but all recent solutions merely focus on the single-sentence scenario. As a result, current approaches accumulate latencies progressively when the speaker talks faster, and introduce unnatural pauses when the speaker talks slower. To overcome these issues, we propose Self-Adaptive Translation (SAT) which flexibly adjusts the length of translations to accommodate different source speech rates. At similar levels of translation quality (as measured by BLEU), our method generates more fluent target speech (as measured by the naturalness metric MOS) with substantially lower latency than the baseline, in both Zh <-> En directions.
* 10 pages, accepted by Findings of EMNLP 2020
Improving Simultaneous Translation with Pseudo References
Oct 21, 2020
Simultaneous translation is vastly different from full-sentence translation, in the sense that it starts translation before the source sentence ends, with only a few words delay. However, due to the lack of large scale and publicly available simultaneous translation datasets, most simultaneous translation systems still train with ordinary full-sentence parallel corpora which are not suitable for the simultaneous scenario due to the existence of unnecessary long-distance reorderings. Instead of expensive, time-consuming annotation, we propose a novel method that rewrites the target side of existing full-sentence corpus into simultaneous-style translation. Experiments on Chinese-to-English translation demonstrate about +2.7 BLEU improvements with the addition of newly generated pseudo references.
The Review Unmanned Surface Vehicle Path Planning: Based on Multi-modality Constraint
Jul 03, 2020
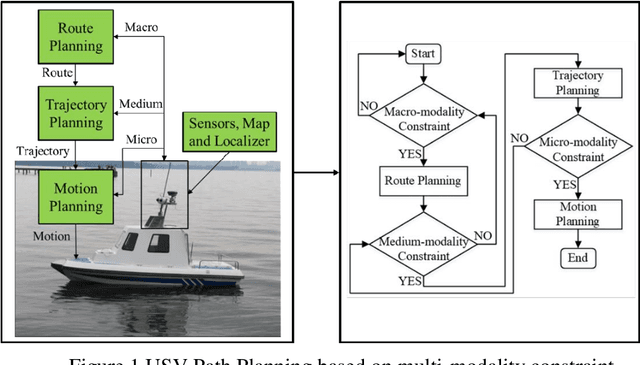

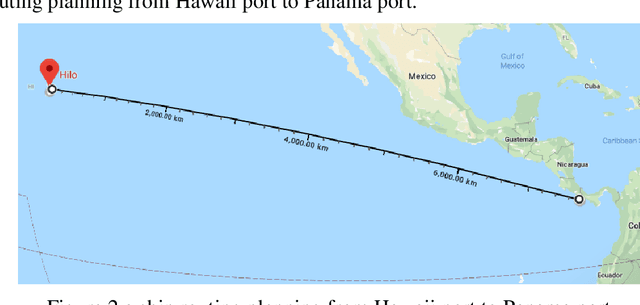
The essence of the path planning problems is multi-modality constraint. However, most of the current literature has not mentioned this issue. This paper introduces the research progress of path planning based on the multi-modality constraint. The path planning of multi-modality constraint research can be classified into three stages in terms of its basic ingredients (such as shape, kinematics and dynamics et al.): Route Planning, Trajectory Planning and Motion Planning. It then reviews the research methods and classical algorithms, especially those applied to the Unmanned Surface Vehicle (USV) in every stage. Finally, the paper points out some existing problems in every stage and suggestions for future research.
NEJM-enzh: A Parallel Corpus for English-Chinese Translation in the Biomedical Domain
May 18, 2020
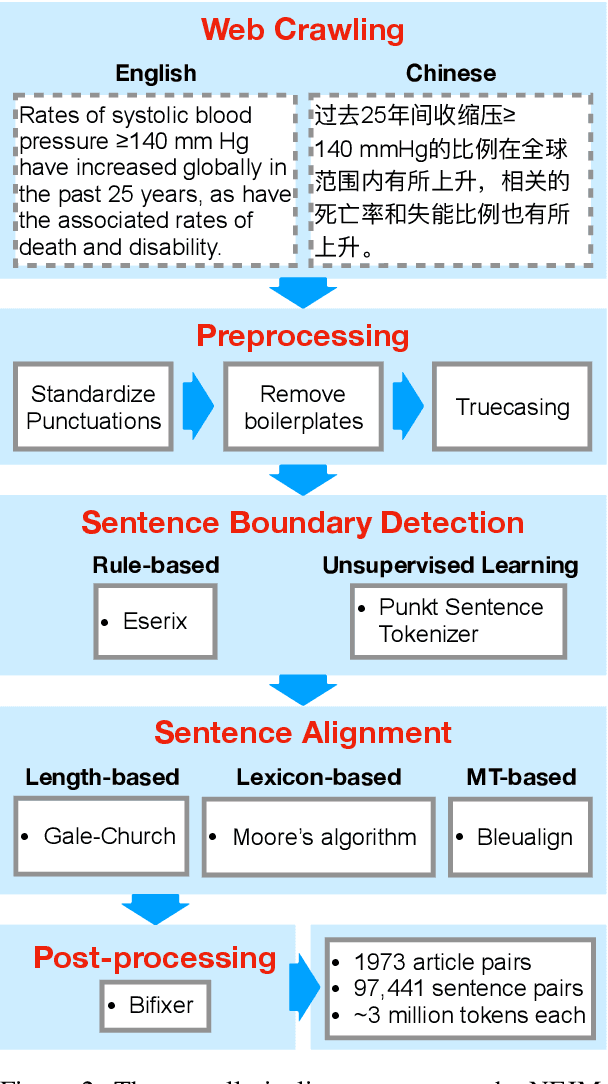
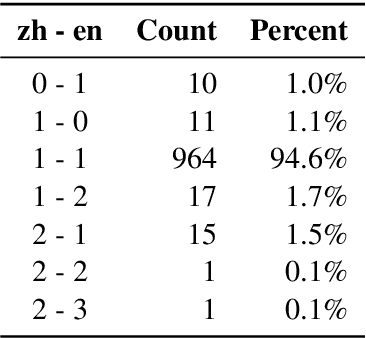
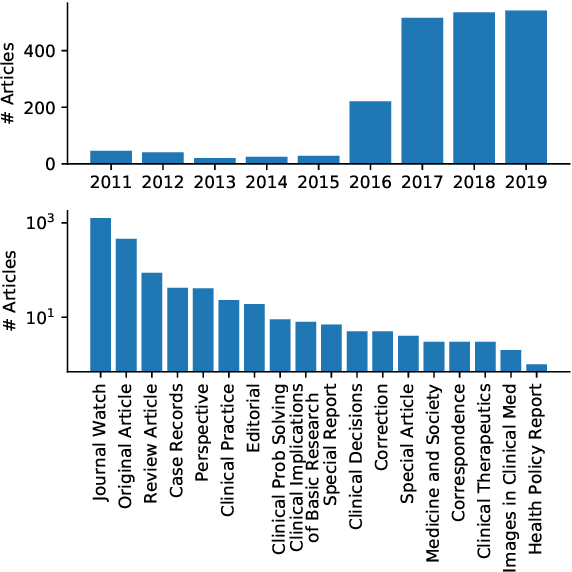
Machine translation requires large amounts of parallel text. While such datasets are abundant in domains such as newswire, they are less accessible in the biomedical domain. Chinese and English are two of the most widely spoken languages, yet to our knowledge a parallel corpus in the biomedical domain does not exist for this language pair. In this study, we develop an effective pipeline to acquire and process an English-Chinese parallel corpus, consisting of about 100,000 sentence pairs and 3,000,000 tokens on each side, from the New England Journal of Medicine (NEJM). We show that training on out-of-domain data and fine-tuning with as few as 4,000 NEJM sentence pairs improve translation quality by 25.3 (13.4) BLEU for en$\to$zh (zh$\to$en) directions. Translation quality continues to improve at a slower pace on larger in-domain datasets, with an increase of 33.0 (24.3) BLEU for en$\to$zh (zh$\to$en) directions on the full dataset.
Visualizing Deep Learning-based Radio Modulation Classifier
May 03, 2020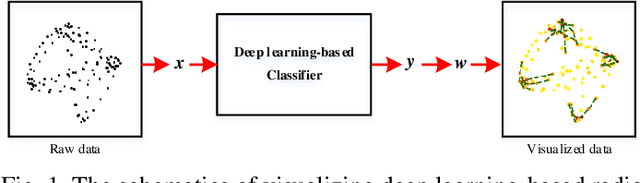
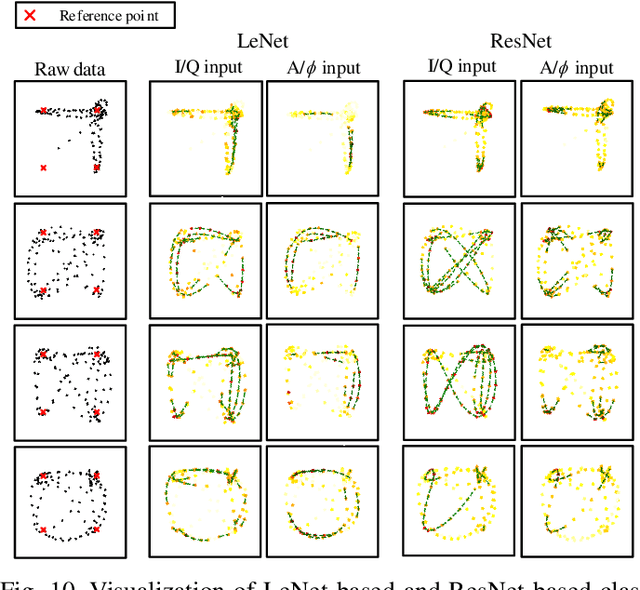
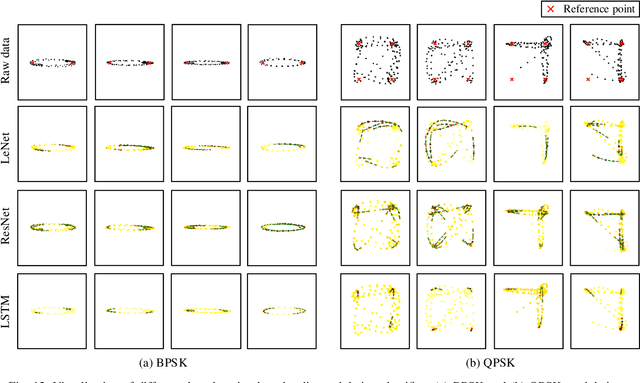
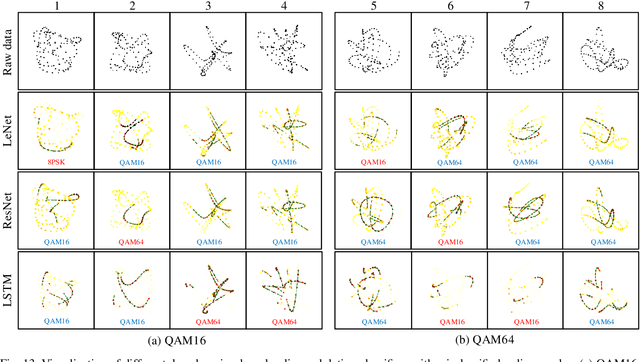
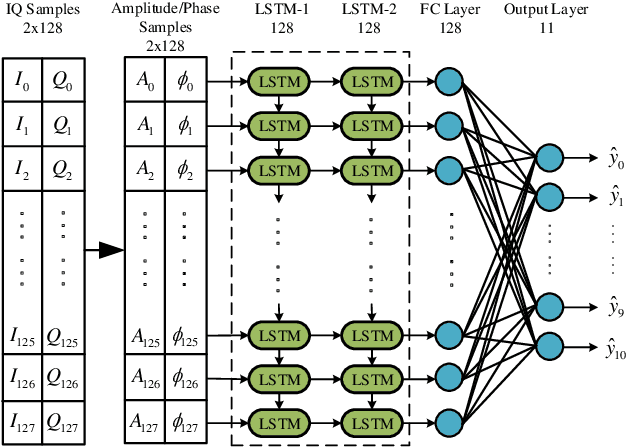
Deep learning has recently been successfully applied in automatic modulation classification by extracting and classifying radio features in an end-to-end way. However, deep learning-based radio modulation classifiers are lack of interpretability, and there is little explanation or visibility into what kinds of radio features are extracted and chosen for classification. In this paper, we visualize different deep learning-based radio modulation classifiers by introducing a class activation vector. Specifically, both convolutional neural networks (CNN) based classifier and long short-term memory (LSTM) based classifier are separately studied, and their extracted radio features are visualized. Extensive numerical results show both the CNN-based classifier and LSTM-based classifier extract similar radio features relating to modulation reference points. In particular, for the LSTM-based classifier, its obtained radio features are similar to the knowledge of human experts. Our numerical results indicate the radio features extracted by deep learning-based classifiers greatly depend on the contents carried by radio signals, and a short radio sample may lead to misclassification.
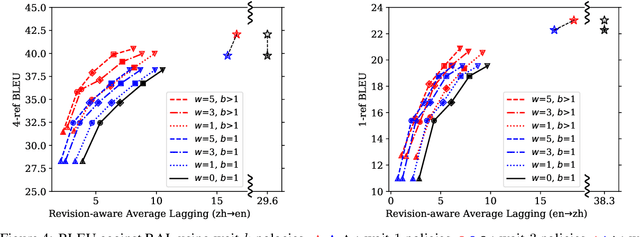
Simultaneous Translation Policies: From Fixed to Adaptive
May 02, 2020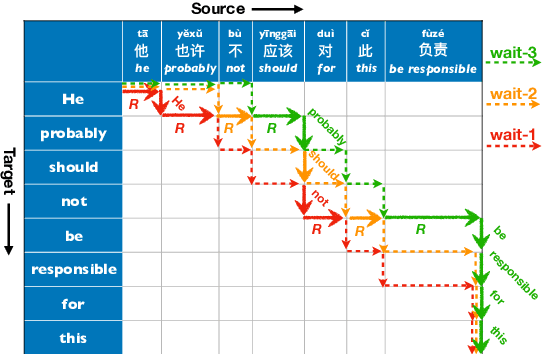

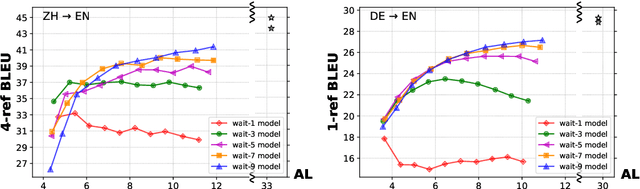

Adaptive policies are better than fixed policies for simultaneous translation, since they can flexibly balance the tradeoff between translation quality and latency based on the current context information. But previous methods on obtaining adaptive policies either rely on complicated training process, or underperform simple fixed policies. We design an algorithm to achieve adaptive policies via a simple heuristic composition of a set of fixed policies. Experiments on Chinese -> English and German -> English show that our adaptive policies can outperform fixed ones by up to 4 BLEU points for the same latency, and more surprisingly, it even surpasses the BLEU score of full-sentence translation in the greedy mode (and very close to beam mode), but with much lower latency.
Opportunistic Decoding with Timely Correction for Simultaneous Translation
May 02, 2020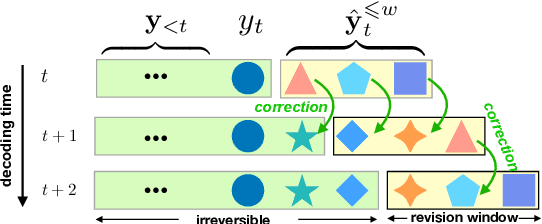

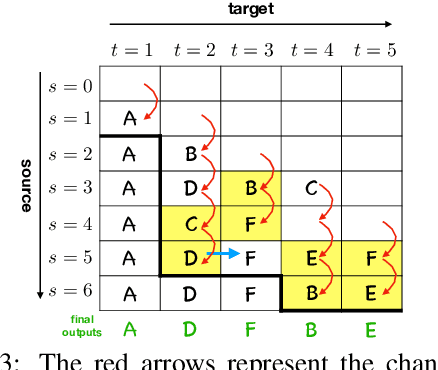
Simultaneous translation has many important application scenarios and attracts much attention from both academia and industry recently. Most existing frameworks, however, have difficulties in balancing between the translation quality and latency, i.e., the decoding policy is usually either too aggressive or too conservative. We propose an opportunistic decoding technique with timely correction ability, which always (over-)generates a certain mount of extra words at each step to keep the audience on track with the latest information. At the same time, it also corrects, in a timely fashion, the mistakes in the former overgenerated words when observing more source context to ensure high translation quality. Experiments show our technique achieves substantial reduction in latency and up to +3.1 increase in BLEU, with revision rate under 8% in Chinese-to-English and English-to-Chinese translation.
Data Augmentation for Deep Learning-based Radio Modulation Classification
Dec 10, 2019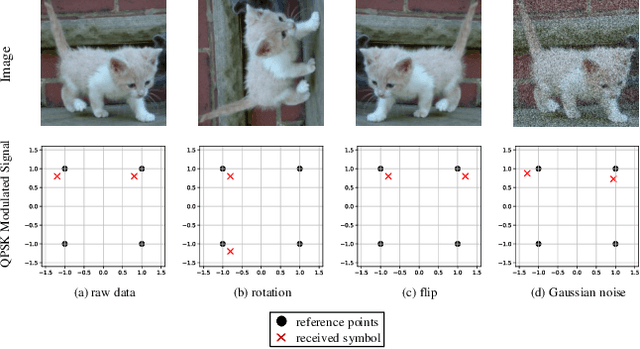

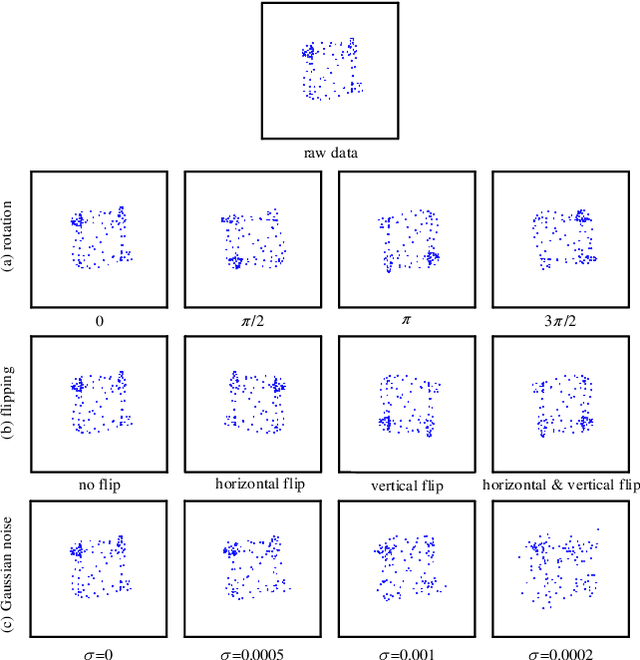
Deep learning has recently been applied to automatically classify the modulation categories of received radio signals without manual experience. However, training deep learning models requires massive volume of data. An insufficient training data will cause serious overfitting problem and degrade the classification accuracy. To cope with small dataset, data augmentation has been widely used in image processing to expand the dataset and improve the robustness of deep learning models. However, in wireless communication areas, the effect of different data augmentation methods on radio modulation classification has not been studied yet. In this paper, we evaluate different data augmentation methods via a state-of-the-art deep learning-based modulation classifier. Based on the characteristics of modulated signals, three augmentation methods are considered, i.e., rotation, flip, and Gaussian noise, which can be applied in both training phase and inference phase of the deep learning algorithm. Numerical results show that all three augmentation methods can improve the classification accuracy. Among which, the rotation augmentation method outperforms the flip method, both of which achieve higher classification accuracy than the Gaussian noise method. Given only 12.5% of training dataset, a joint rotation and flip augmentation policy can achieve even higher classification accuracy than the baseline with initial 100% training dataset without augmentation. Furthermore, with data augmentation, radio modulation categories can be successfully classified using shorter radio samples, leading to a simplified deep learning model and shorter the classification response time.
Incremental Text-to-Speech Synthesis with Prefix-to-Prefix Framework
Nov 07, 2019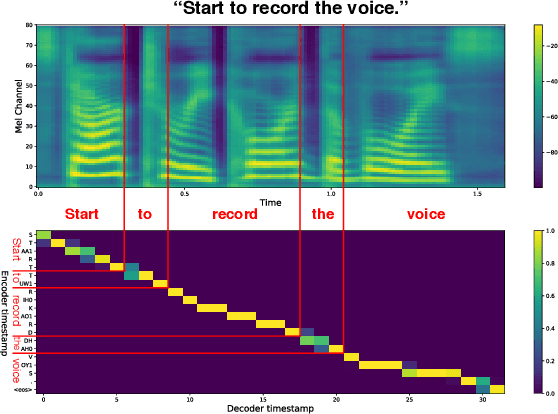
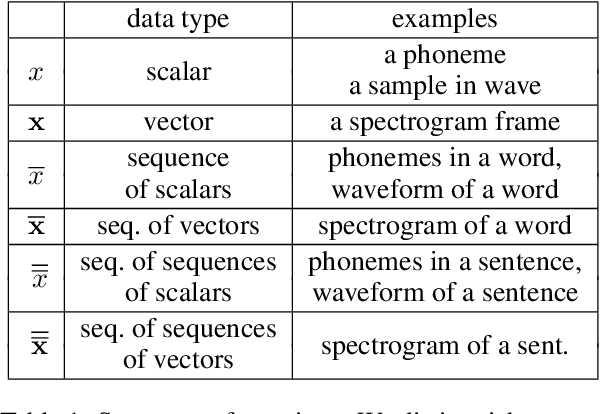
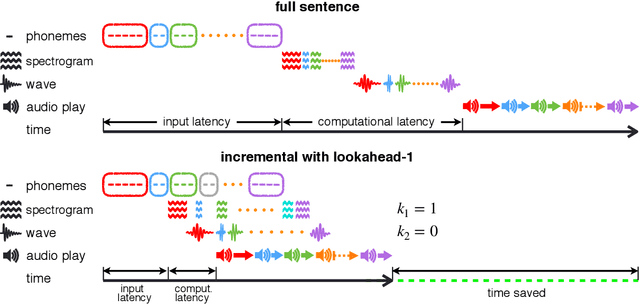
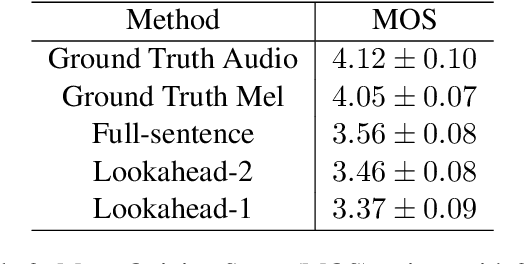
Text-to-speech synthesis (TTS) has witnessed rapid progress in recent years, where neural methods became capable of producing audio with near human-level naturalness. However, these efforts still suffer from two types of latencies: (a) the computational latency (synthesize time), which grows linearly with the sentence length even with parallel approaches, and (b) the input latency in scenarios where the input text is incrementally generated (such as in simultaneous translation, dialog generation, and assistive technologies). To reduce these latencies, we devise the first neural incremental TTS approach based on the recently proposed prefix-to-prefix framework. We synthesize speech in an online fashion, playing a segment of audio while generating the next, resulting in an O(1) rather than O(n) latency. Experiments on English TTS show that our approach achieves similar speech naturalness compared to full sentence methods, but only using a fraction of time and a constant (1 - 2 words) latency.