 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking-head Generation with Rhythmic Head Motion
Jul 16, 2020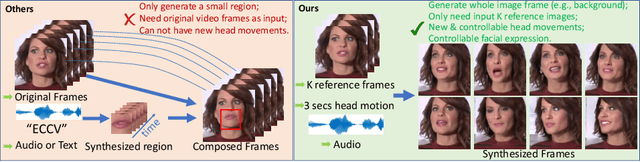
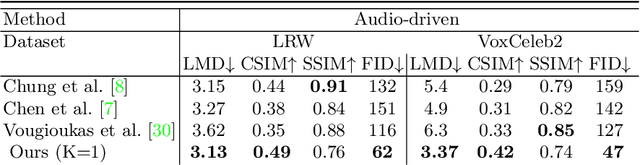
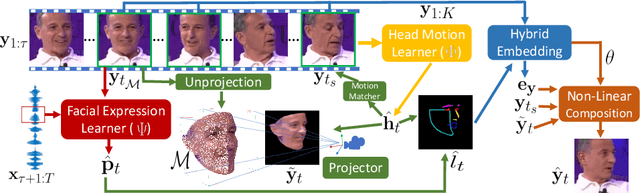
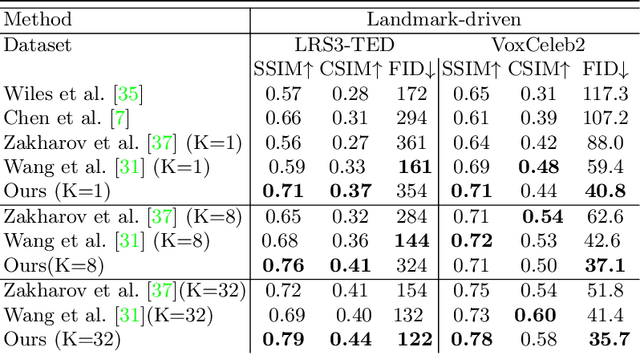
When people deliver a speech, they naturally move heads, and this rhythmic head motion conveys prosodic information. However, generating a lip-synced video while moving head naturally is challenging. While remarkably successful, existing works either generate still talkingface videos or rely on landmark/video frames as sparse/dense mapping guidance to generate head movements, which leads to unrealistic or uncontrollable video synthesis. To overcome the limitations, we propose a 3D-aware generative network along with a hybrid embedding module and a non-linear composition module. Through modeling the head motion and facial expressions1 explicitly, manipulating 3D animation carefully, and embedding reference images dynamically, our approach achieves controllable, photo-realistic, and temporally coherent talking-head videos with natural head movements. Thoughtful experiments on several standard benchmarks demonstrate that our method achieves significantly better results than the state-of-the-art methods in both quantitative and qualitative comparisons. The code is available on https://github.com/ lelechen63/Talking-head-Generation-with-Rhythmic-Head-Motion.
What comprises a good talking-head video generation?: A Survey and Benchmark
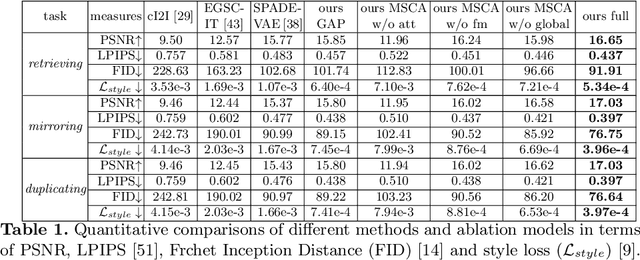
May 07, 2020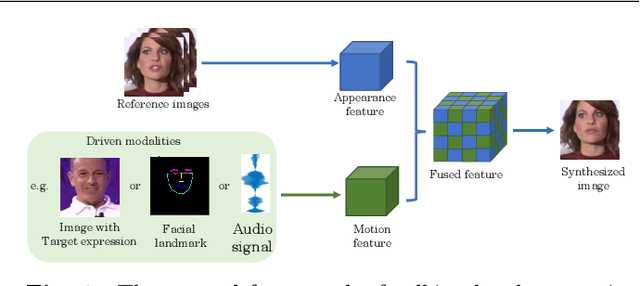
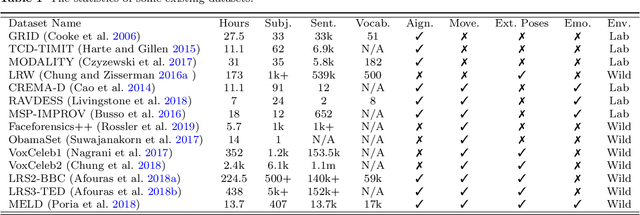
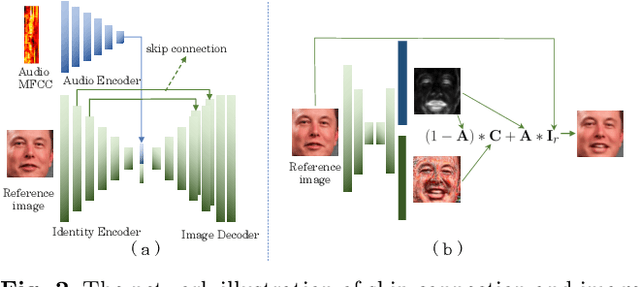

Over the years, performance evaluation has become essential in computer vision, enabling tangible progress in many sub-fields. While talking-head video generation has become an emerging research topic, existing evaluations on this topic present many limitations. For example, most approaches use human subjects (e.g., via Amazon MTurk) to evaluate their research claims directly. This subjective evaluation is cumbersome, unreproducible, and may impend the evolution of new research. In this work, we present a carefully-designed benchmark for evaluating talking-head video generation with standardized dataset pre-processing strategies. As for evaluation, we either propose new metrics or select the most appropriate ones to evaluate results in what we consider as desired properties for a good talking-head video, namely, identity preserving, lip synchronization, high video quality, and natural-spontaneous motion. By conducting a thoughtful analysis across several state-of-the-art talking-head generation approaches, we aim to uncover the merits and drawbacks of current methods and point out promising directions for future work. All the evaluation code is available at: https://github.com/lelechen63/talking-head-generation-survey.
Example-Guided Image Synthesis across Arbitrary Scenes using Masked Spatial-Channel Attention and Self-Supervision
Apr 18, 2020
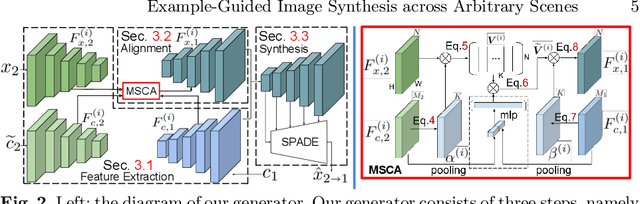

Example-guided image synthesis has recently been attempted to synthesize an image from a semantic label map and an exemplary image. In the task, the additional exemplar image provides the style guidance that controls the appearance of the synthesized output. Despite the controllability advantage, the existing models are designed on datasets with specific and roughly aligned objects. In this paper, we tackle a more challenging and general task, where the exemplar is an arbitrary scene image that is semantically different from the given label map. To this end, we first propose a Masked Spatial-Channel Attention (MSCA) module which models the correspondence between two arbitrary scenes via efficient decoupled attention. Next, we propose an end-to-end network for joint global and local feature alignment and synthesis. Finally, we propose a novel self-supervision task to enable training. Experiments on the large-scale and more diverse COCO-stuff dataset show significant improvements over the existing methods. Moreover, our approach provides interpretability and can be readily extended to other content manipulation tasks including style and spatial interpolation or extrapolation.
TailorGAN: Making User-Defined Fashion Designs
Jan 20, 2020

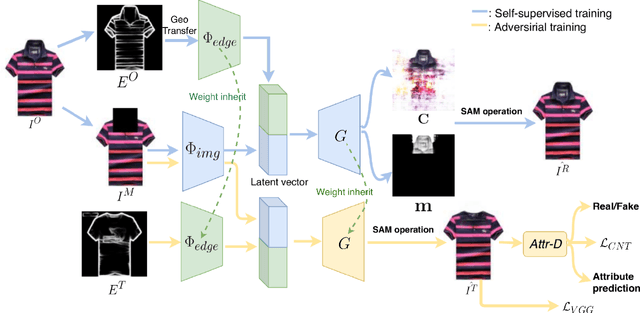

Attribute editing has become an important and emerging topic of computer vision. In this paper, we consider a task: given a reference garment image A and another image B with target attribute (collar/sleeve), generate a photo-realistic image which combines the texture from reference A and the new attribute from reference B. The highly convoluted attributes and the lack of paired data are the main challenges to the task. To overcome those limitations, we propose a novel self-supervised model to synthesize garment images with disentangled attributes (e.g., collar and sleeves) without paired data. Our method consists of a reconstruction learning step and an adversarial learning step. The model learns texture and location information through reconstruction learning. And, the model's capability is generalized to achieve single-attribute manipulation by adversarial learning. Meanwhile, we compose a new dataset, named GarmentSet, with annotation of landmarks of collars and sleeves on clean garment images. Extensive experiments on this dataset and real-world samples demonstrate that our method can synthesize much better results than the state-of-the-art methods in both quantitative and qualitative comparisons.
* fashion
Example-Guided Scene Image Synthesis using Masked Spatial-Channel Attention and Patch-Based Self-Supervision
Nov 27, 2019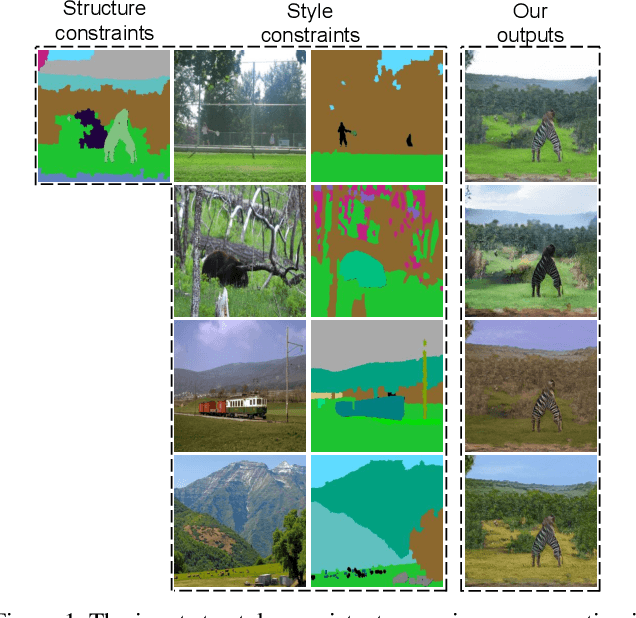
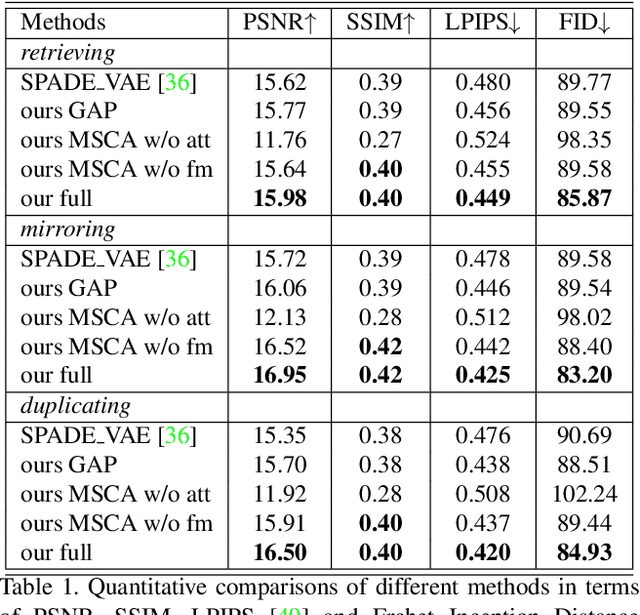
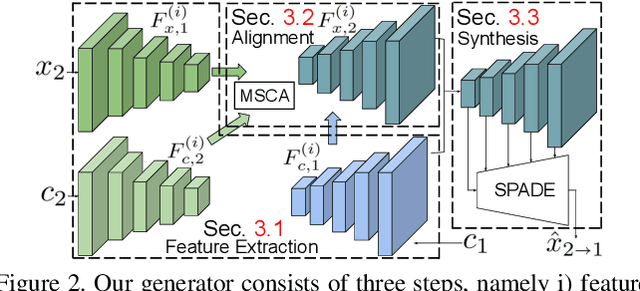
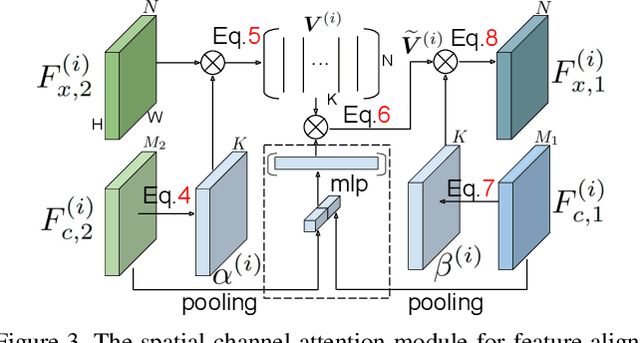
Example-guided image synthesis has been recently attempted to synthesize an image from a semantic label map and an exemplary image. In the task, the additional exemplary image serves to provide style guidance that controls the appearance of the synthesized output. Despite the controllability advantage, the previous models are designed on datasets with specific and roughly aligned objects. In this paper, we tackle a more challenging and general task, where the exemplar is an arbitrary scene image that is semantically unaligned to the given label map. To this end, we first propose a new Masked Spatial-Channel Attention (MSCA) module which models the correspondence between two unstructured scenes via cross-attention. Next, we propose an end-to-end network for joint global and local feature alignment and synthesis. In addition, we propose a novel patch-based self-supervision scheme to enable training. Experiments on the large-scale CCOO-stuff dataset show significant improvements over existing methods. Moreover, our approach provides interpretability and can be readily extended to other tasks including style and spatial interpolation or extrapolation, as well as other content manipulation.
Unsupervised Pose Flow Learning for Pose Guided Synthesis
Sep 30, 2019


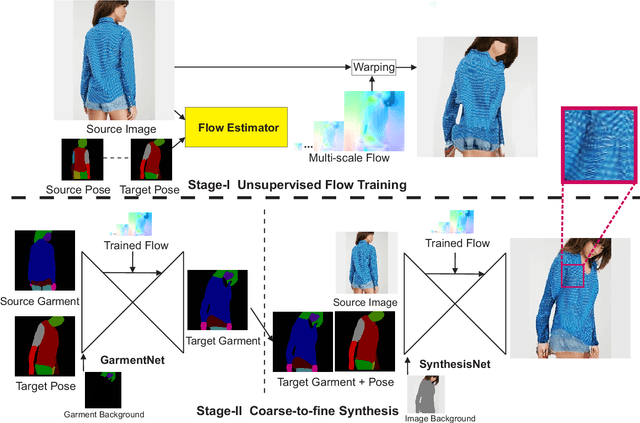
Pose guided synthesis aims to generate a new image in an arbitrary target pose while preserving the appearance details from the source image. Existing approaches rely on either hard-coded spatial transformations or 3D body modeling. They often overlook complex non-rigid pose deformation or unmatched occluded regions, thus fail to effectively preserve appearance information. In this paper, we propose an unsupervised pose flow learning scheme that learns to transfer the appearance details from the source image. Based on such learned pose flow, we proposed GarmentNet and SynthesisNet, both of which use multi-scale feature-domain alignment for coarse-to-fine synthesis. Experiments on the DeepFashion, MVC dataset and additional real-world datasets demonstrate that our approach compares favorably with the state-of-the-art methods and generalizes to unseen poses and clothing styles.
Hierarchical Cross-Modal Talking Face Generationwith Dynamic Pixel-Wise Loss
May 09, 2019

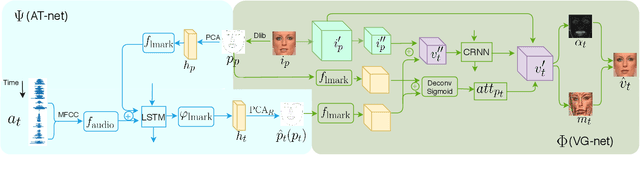
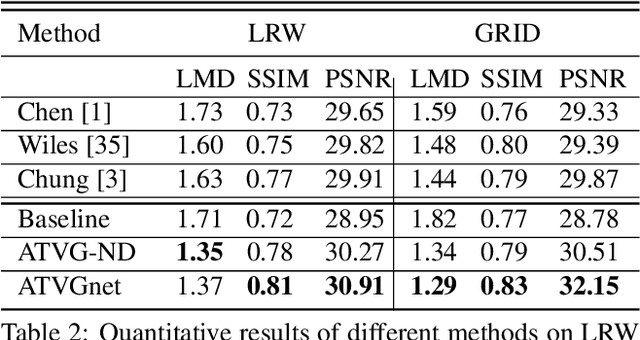
We devise a cascade GAN approach to generate talking face video, which is robust to different face shapes, view angles, facial characteristics, and noisy audio conditions. Instead of learning a direct mapping from audio to video frames, we propose first to transfer audio to high-level structure, i.e., the facial landmarks, and then to generate video frames conditioned on the landmarks. Compared to a direct audio-to-image approach, our cascade approach avoids fitting spurious correlations between audiovisual signals that are irrelevant to the speech content. We, humans, are sensitive to temporal discontinuities and subtle artifacts in video. To avoid those pixel jittering problems and to enforce the network to focus on audiovisual-correlated regions, we propose a novel dynamically adjustable pixel-wise loss with an attention mechanism. Furthermore, to generate a sharper image with well-synchronized facial movements, we propose a novel regression-based discriminator structure, which considers sequence-level information along with frame-level information. Thoughtful experiments on several datasets and real-world samples demonstrate significantly better results obtained by our method than the state-of-the-art methods in both quantitative and qualitative comparisons.
Lip Movements Generation at a Glance
May 21, 2018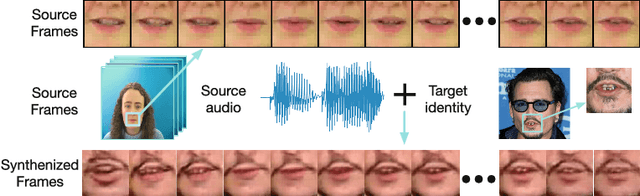
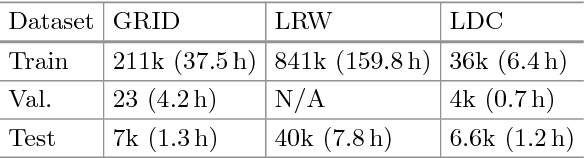
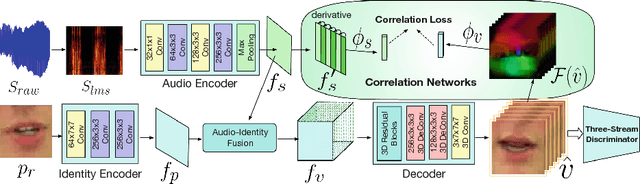
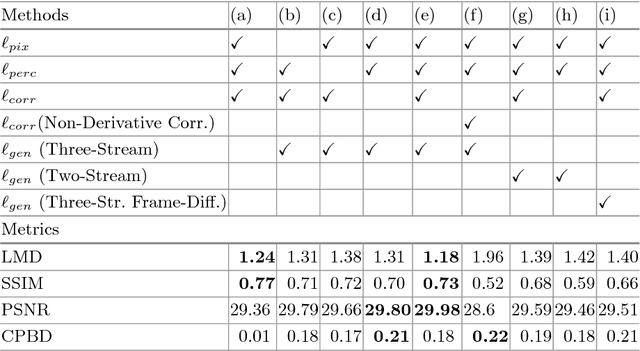
Cross-modality generation is an emerging topic that aims to synthesize data in one modality based on information in a different modality. In this paper, we consider a task of such: given an arbitrary audio speech and one lip image of arbitrary target identity, generate synthesized lip movements of the target identity saying the speech. To perform well in this task, it inevitably requires a model to not only consider the retention of target identity, photo-realistic of synthesized images, consistency and smoothness of lip images in a sequence, but more importantly, learn the correlations between audio speech and lip movements. To solve the collective problems, we explore the best modeling of the audio-visual correlations in building and training a lip-movement generator network. Specifically, we devise a method to fuse audio and image embeddings to generate multiple lip images at once and propose a novel correlation loss to synchronize lip changes and speech changes. Our final model utilizes a combination of four losses for a comprehensive consideration in generating lip movements; it is trained in an end-to-end fashion and is robust to lip shapes, view angles and different facial characteristics. Thoughtful experiments on three datasets ranging from lab-recorded to lips in-the-wild show that our model significantly outperforms other state-of-the-art methods extended to this task.
MRI Tumor Segmentation with Densely Connected 3D CNN
Feb 09, 2018Glioma is one of the most common and aggressive types of primary brain tumors. The accurate segmentation of subcortical brain structures is crucial to the study of gliomas in that it helps the monitoring of the progression of gliomas and aids the evaluation of treatment outcomes. However, the large amount of required human labor makes it difficult to obtain the manually segmented Magnetic Resonance Imaging (MRI) data, limiting the use of precise quantitative measurements in the clinical practice. In this work, we try to address this problem by developing a 3D Convolutional Neural Network~(3D CNN) based model to automatically segment gliomas. The major difficulty of our segmentation model comes with the fact that the location, structure, and shape of gliomas vary significantly among different patients. In order to accurately classify each voxel, our model captures multi-scale contextual information by extracting features from two scales of receptive fields. To fully exploit the tumor structure, we propose a novel architecture that hierarchically segments different lesion regions of the necrotic and non-enhancing tumor~(NCR/NET), peritumoral edema~(ED) and GD-enhancing tumor~(ET). Additionally, we utilize densely connected convolutional blocks to further boost the performance. We train our model with a patch-wise training schema to mitigate the class imbalance problem. The proposed method is validated on the BraTS 2017 dataset and it achieves Dice scores of 0.72, 0.83 and 0.81 for the complete tumor, tumor core and enhancing tumor, respectively. These results are comparable to the reported state-of-the-art results, and our method is better than existing 3D-based methods in terms of compactness, time and space efficiency.
Deep Cross-Modal Audio-Visual Generation
Apr 26, 2017
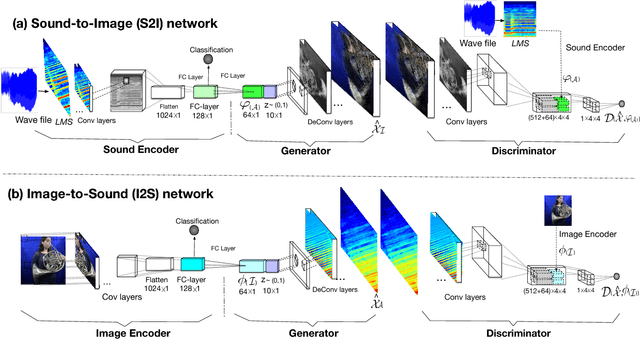
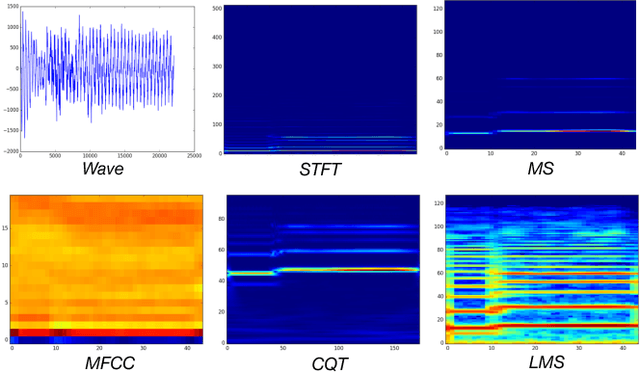

Cross-modal audio-visual perception has been a long-lasting topic in psychology and neurology, and various studies have discovered strong correlations in human perception of auditory and visual stimuli. Despite works in computational multimodal modeling, the problem of cross-modal audio-visual generation has not been systematically studied in the literature. In this paper, we make the first attempt to solve this cross-modal generation problem leveraging the power of deep generative adversarial training. Specifically, we use conditional generative adversarial networks to achieve cross-modal audio-visual generation of musical performances. We explore different encoding methods for audio and visual signals, and work on two scenarios: instrument-oriented generation and pose-oriented generation. Being the first to explore this new problem, we compose two new datasets with pairs of images and sounds of musical performances of different instruments. Our experiments using both classification and human evaluations demonstrate that our model has the ability to generate one modality, i.e., audio/visual, from the other modality, i.e., visual/audio, to a good extent. Our experiments on various design choices along with the datasets will facilitate future research in this new problem space.