 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSituated, Dynamic, and Subjective: Envisioning the Design of Theory-of-Mind-Enabled Everyday AI with Industry Practitioners
Feb 11, 2026Theory of Mind (ToM) -- the ability to infer what others are thinking (e.g., intentions) from observable cues -- is traditionally considered fundamental to human social interactions. This has sparked growing efforts in building and benchmarking AI's ToM capability, yet little is known about how such capability could translate into the design and experience of everyday user-facing AI products and services. We conducted 13 co-design sessions with 26 U.S.-based AI practitioners to envision, reflect, and distill design recommendations for ToM-enabled everyday AI products and services that are both future-looking and grounded in the realities of AI design and development practices. Analysis revealed three interrelated design recommendations: ToM-enabled AI should 1) be situated in the social context that shape users' mental states, 2) be responsive to the dynamic nature of mental states, and 3) be attuned to subjective individual differences. We surface design tensions within each recommendation that reveal a broader gap between practitioners' envisioned futures of ToM-enabled AI and the realities of current AI design and development practices. These findings point toward the need to move beyond static, inference-driven approach to ToM and toward designing ToM as a pervasive capability that supports continuous human-AI interaction loops.
* 16 pages, preprint for ACM CHI 2026 Conference
Meta-GPT: Decoding the Metasurface Genome with Generative Artificial Intelligence
Dec 15, 2025



Advancing artificial intelligence for physical sciences requires representations that are both interpretable and compatible with the underlying laws of nature. We introduce METASTRINGS, a symbolic language for photonics that expresses nanostructures as textual sequences encoding materials, geometries, and lattice configurations. Analogous to molecular textual representations in chemistry, METASTRINGS provides a framework connecting human interpretability with computational design by capturing the structural hierarchy of photonic metasurfaces. Building on this representation, we develop Meta-GPT, a foundation transformer model trained on METASTRINGS and finetuned with physics-informed supervised, reinforcement, and chain-of-thought learning. Across various design tasks, the model achieves <3% mean-squared spectral error and maintains >98% syntactic validity, generating diverse metasurface prototypes whose experimentally measured optical responses match their target spectra. These results demonstrate that Meta-GPT can learn the compositional rules of light-matter interactions through METASTRINGS, laying a rigorous foundation for AI-driven photonics and representing an important step toward a metasurface genome project.
Can You Keep a Secret? Exploring AI for Care Coordination in Cognitive Decline
Dec 14, 2025The increasing number of older adults who experience cognitive decline places a burden on informal caregivers, whose support with tasks of daily living determines whether older adults can remain in their homes. To explore how agents might help lower-SES older adults to age-in-place, we interviewed ten pairs of older adults experiencing cognitive decline and their informal caregivers. We explored how they coordinate care, manage burdens, and sustain autonomy and privacy. Older adults exercised control by delegating tasks to specific caregivers, keeping information about all the care they received from their adult children. Many abandoned some tasks of daily living, lowering their quality of life to ease caregiver burden. One effective strategy, piggybacking, uses spontaneous overlaps in errands to get more work done with less caregiver effort. This raises the questions: (i) Can agents help with piggyback coordination? (ii) Would it keep older adults in their homes longer, while not increasing caregiver burden?
Quantum Computing for Climate Resilience and Sustainability Challenges
Jul 23, 2024


The escalating impacts of climate change and the increasing demand for sustainable development and natural resource management necessitate innovative technological solutions. Quantum computing (QC) has emerged as a promising tool with the potential to revolutionize these critical areas. This review explores the application of quantum machine learning and optimization techniques for climate change prediction and enhancing sustainable development. Traditional computational methods often fall short in handling the scale and complexity of climate models and natural resource management. Quantum advancements, however, offer significant improvements in computational efficiency and problem-solving capabilities. By synthesizing the latest research and developments, this paper highlights how QC and quantum machine learning can optimize multi-infrastructure systems towards climate neutrality. The paper also evaluates the performance of current quantum algorithms and hardware in practical applications and presents realistic cases, i.e., waste-to-energy in anaerobic digestion, disaster prevention in flooding prediction, and new material development for carbon capture. The integration of these quantum technologies promises to drive significant advancements in achieving climate resilience and sustainable development.
Classification of complex local environments in systems of particle shapes through shape-symmetry encoded data augmentation
Dec 19, 2023



Detecting and analyzing the local environment is crucial for investigating the dynamical processes of crystal nucleation and shape colloidal particle self-assembly. Recent developments in machine learning provide a promising avenue for better order parameters in complex systems that are challenging to study using traditional approaches. However, the application of machine learning to self-assembly on systems of particle shapes is still underexplored. To address this gap, we propose a simple, physics-agnostic, yet powerful approach that involves training a multilayer perceptron (MLP) as a local environment classifier for systems of particle shapes, using input features such as particle distances and orientations. Our MLP classifier is trained in a supervised manner with a shape symmetry-encoded data augmentation technique without the need for any conventional roto-translations invariant symmetry functions. We evaluate the performance of our classifiers on four different scenarios involving self-assembly of cubic structures, 2-dimensional and 3-dimensional patchy particle shape systems, hexagonal bipyramids with varying aspect ratios, and truncated shapes with different degrees of truncation. The proposed training process and data augmentation technique are both straightforward and flexible, enabling easy application of the classifier to other processes involving particle orientations. Our work thus presents a valuable tool for investigating self-assembly processes on systems of particle shapes, with potential applications in structure identification of any particle-based or molecular system where orientations can be defined.
"It's a Fair Game'', or Is It? Examining How Users Navigate Disclosure Risks and Benefits When Using LLM-Based Conversational Agents
Sep 20, 2023The widespread use of Large Language Model (LLM)-based conversational agents (CAs), especially in high-stakes domains, raises many privacy concerns. Building ethical LLM-based CAs that respect user privacy requires an in-depth understanding of the privacy risks that concern users the most. However, existing research, primarily model-centered, does not provide insight into users' perspectives. To bridge this gap, we analyzed sensitive disclosures in real-world ChatGPT conversations and conducted semi-structured interviews with 19 LLM-based CA users. We found that users are constantly faced with trade-offs between privacy, utility, and convenience when using LLM-based CAs. However, users' erroneous mental models and the dark patterns in system design limited their awareness and comprehension of the privacy risks. Additionally, the human-like interactions encouraged more sensitive disclosures, which complicated users' ability to navigate the trade-offs. We discuss practical design guidelines and the needs for paradigmatic shifts to protect the privacy of LLM-based CA users.
Stochastic Assignment for Deploying Multiple Marsupial Robots
Oct 19, 2021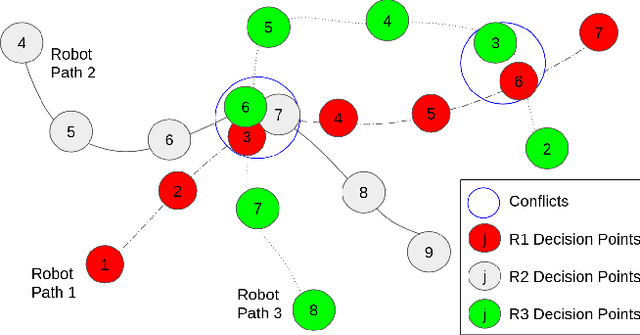
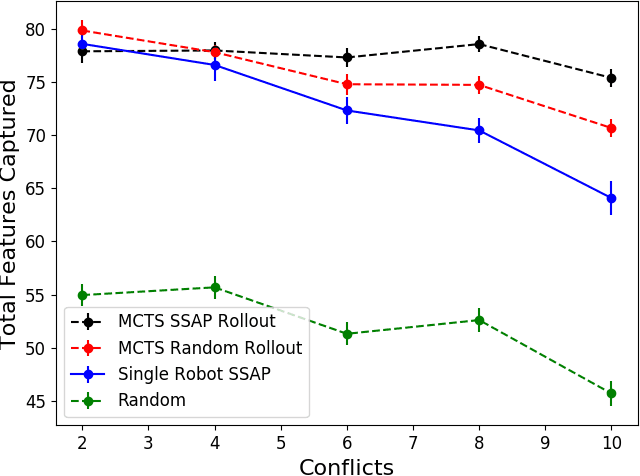
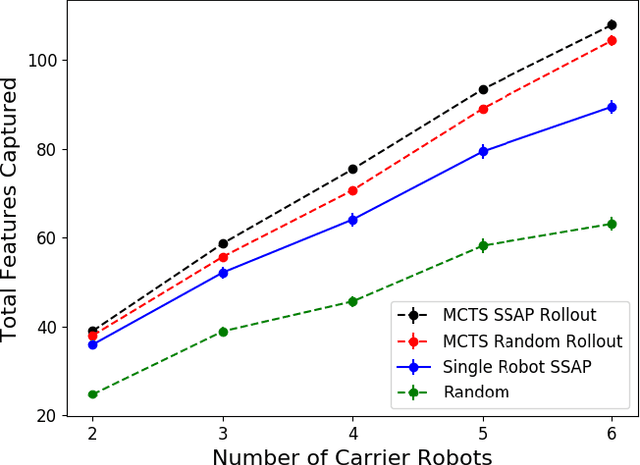
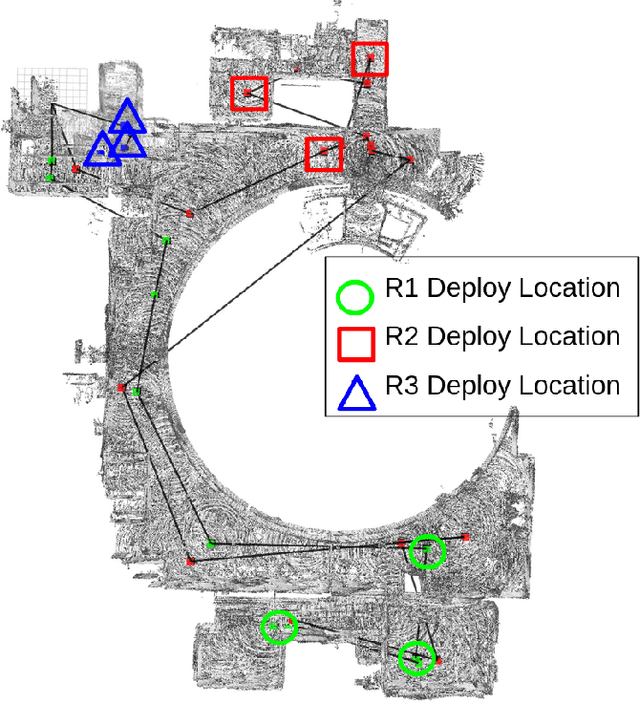
Marsupial robot teams consist of carrier robots that transport and deploy multiple passenger robots, such as a team of ground robots that carry and deploy multiple aerial robots, to rapidly explore complex environments. We specifically address the problem of planning the deployment times and locations of the carrier robots to best meet the objectives of a mission while reasoning over uncertain future observations and rewards. While prior work proposed optimal, polynomial-time solutions to single-carrier robot systems, the multiple-carrier robot deployment problem is fundamentally harder as it requires addressing conflicts and dependencies between deployments of multiple passenger robots. We propose a centralized heuristic search algorithm for the multiple-carrier robot deployment problem that combines Monte Carlo Tree Search with a dynamic programming-based solution to the Sequential Stochastic Assignment Problem as a rollout action-selection policy. Our results with both procedurally-generated data and data drawn from the DARPA Subterranean Challenge Urban Circuit show the viability of our approach and substantial exploration performance improvements over alternative algorithms.
Optimal Sequential Stochastic Deployment of Multiple Passenger Robots
Oct 19, 2021
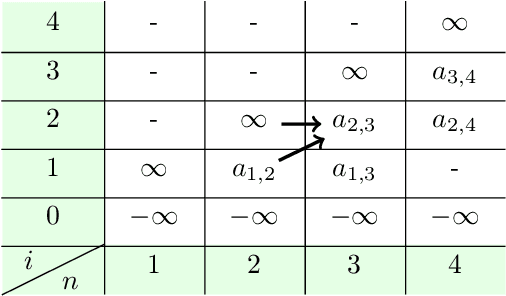
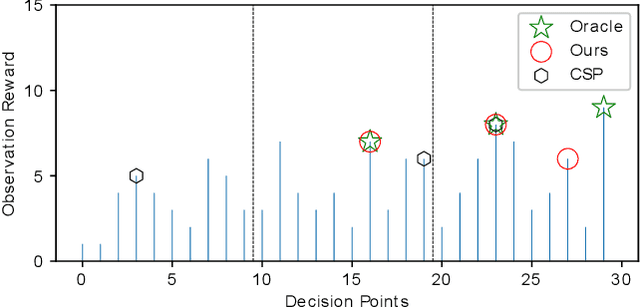
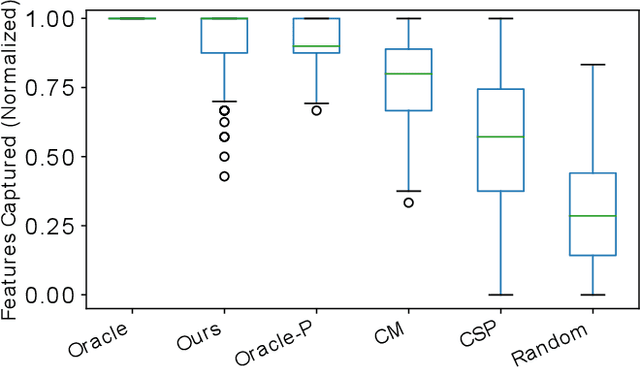
We present a new algorithm for deploying passenger robots in marsupial robot systems. A marsupial robot system consists of a carrier robot (e.g., a ground vehicle), which is highly capable and has a long mission duration, and at least one passenger robot (e.g., a short-duration aerial vehicle) transported by the carrier. We optimize the performance of passenger robot deployment by proposing an algorithm that reasons over uncertainty by exploiting information about the prior probability distribution of features of interest in the environment. Our algorithm is formulated as a solution to a sequential stochastic assignment problem (SSAP). The key feature of the algorithm is a recurrence relationship that defines a set of observation thresholds that are used to decide when to deploy passenger robots. Our algorithm computes the optimal policy in $O(NR)$ time, where $N$ is the number of deployment decision points and $R$ is the number of passenger robots to be deployed. We conducted drone deployment exploration experiments on real-world data from the DARPA Subterranean challenge to test the SSAP algorithm. Our results show that our deployment algorithm outperforms other competing algorithms, such as the classic secretary approach and baseline partitioning methods, and is comparable to an offline oracle algorithm.