 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Passage Retrieval for Open-Domain Question Answering
May 02, 2020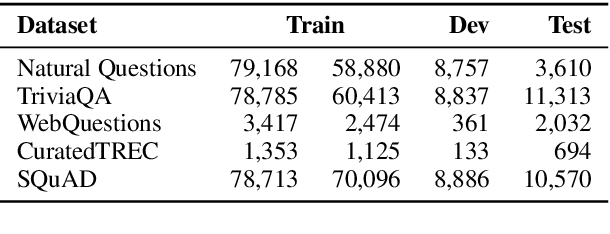
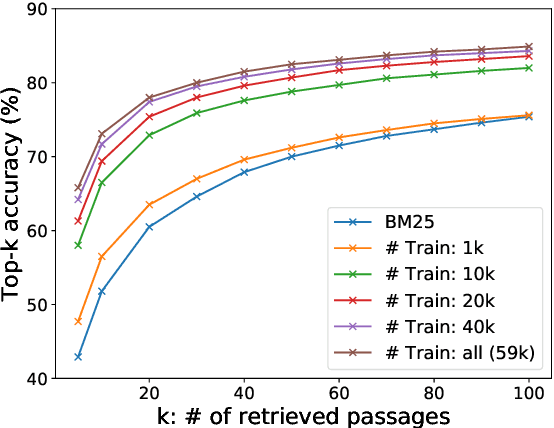
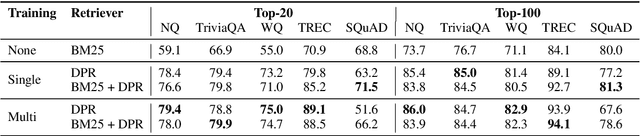
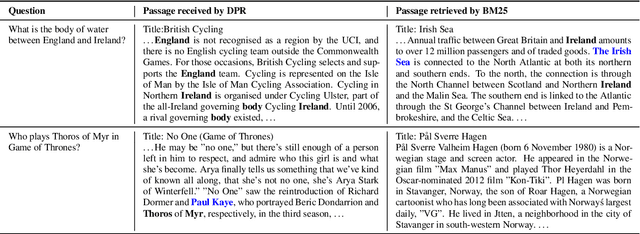
Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implemented using dense representations alone, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks.
Multi-Dimensional Gender Bias Classification
May 01, 2020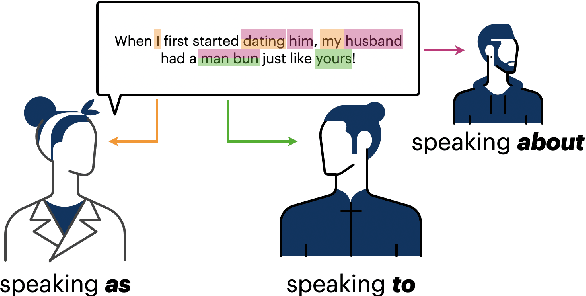
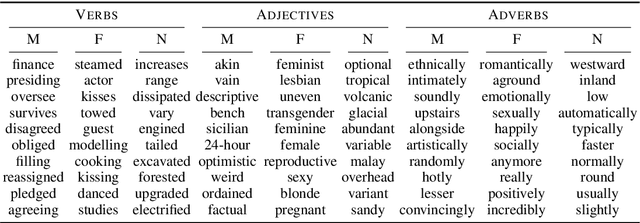
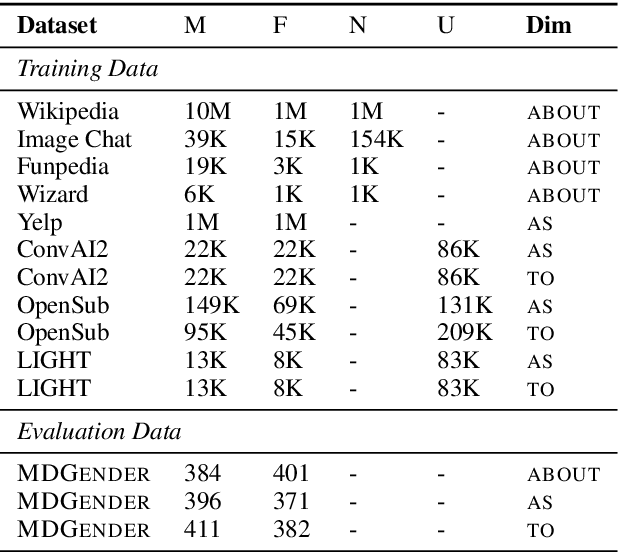
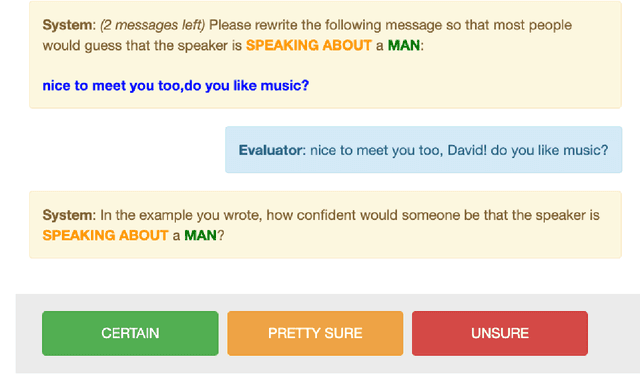
Machine learning models are trained to find patterns in data. NLP models can inadvertently learn socially undesirable patterns when training on gender biased text. In this work, we propose a general framework that decomposes gender bias in text along several pragmatic and semantic dimensions: bias from the gender of the person being spoken about, bias from the gender of the person being spoken to, and bias from the gender of the speaker. Using this fine-grained framework, we automatically annotate eight large scale datasets with gender information. In addition, we collect a novel, crowdsourced evaluation benchmark of utterance-level gender rewrites. Distinguishing between gender bias along multiple dimensions is important, as it enables us to train finer-grained gender bias classifiers. We show our classifiers prove valuable for a variety of important applications, such as controlling for gender bias in generative models, detecting gender bias in arbitrary text, and shed light on offensive language in terms of genderedness.
Zero-shot Entity Linking with Dense Entity Retrieval
Nov 10, 2019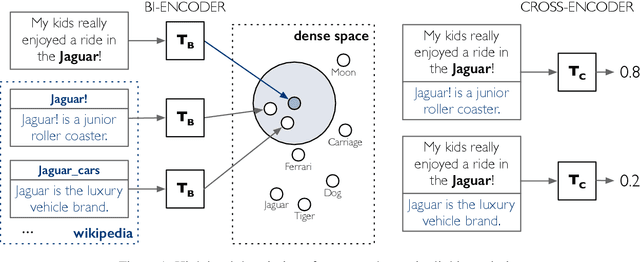

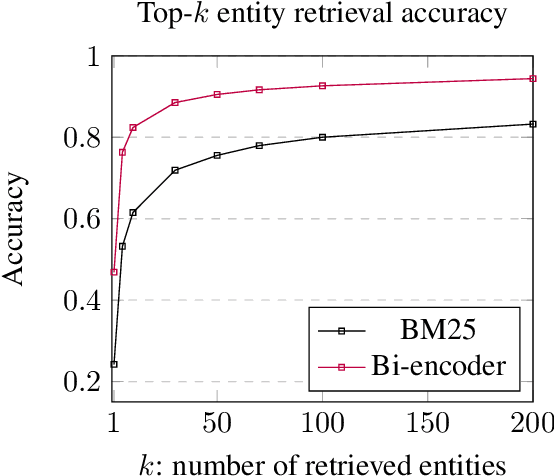

We consider the zero-shot entity-linking challenge where each entity is defined by a short textual description, and the model must read these descriptions together with the mention context to make the final linking decisions. In this setting, retrieving entity candidates can be particularly challenging, since many of the common linking cues such as entity alias tables and link popularity are not available. In this paper, we introduce a simple and effective two stage approach for zero-shot linking, based on fine-tuned BERT architectures. In the first stage, we do retrieval in a dense space defined by a bi-encoder that independently embeds the mention context and the entity descriptions. Each candidate is then examined more carefully with a cross-encoder, that concatenates the mention and entity text. Our approach achieves a nearly 5 point absolute gain on a recently introduced zero-shot entity linking benchmark, driven largely by improvements over previous IR-based candidate retrieval. We also show that it performs well in the non-zero-shot setting, obtaining the state-of-the-art result on TACKBP-2010.
PyTorch-BigGraph: A Large-scale Graph Embedding System
Apr 09, 2019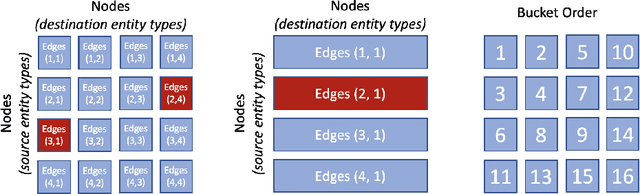
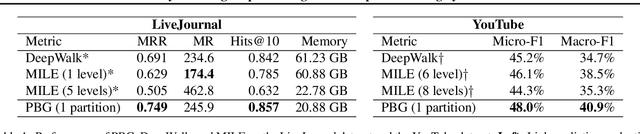
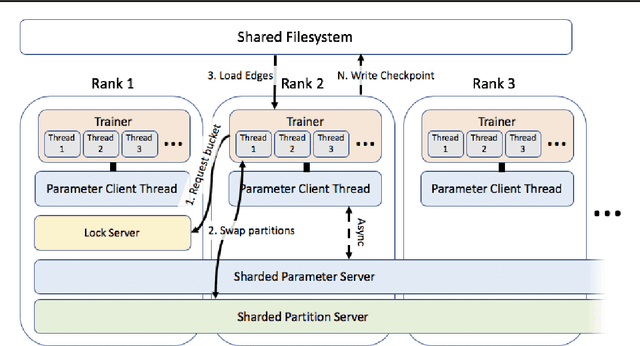
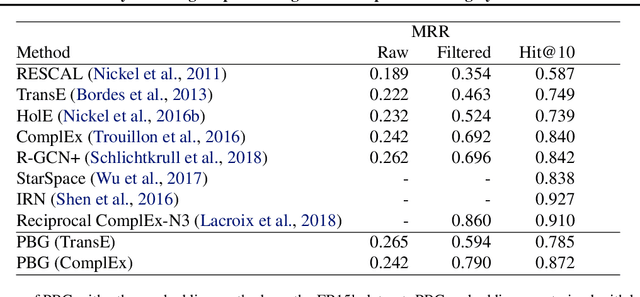
Graph embedding methods produce unsupervised node features from graphs that can then be used for a variety of machine learning tasks. Modern graphs, particularly in industrial applications, contain billions of nodes and trillions of edges, which exceeds the capability of existing embedding systems. We present PyTorch-BigGraph (PBG), an embedding system that incorporates several modifications to traditional multi-relation embedding systems that allow it to scale to graphs with billions of nodes and trillions of edges. PBG uses graph partitioning to train arbitrarily large embeddings on either a single machine or in a distributed environment. We demonstrate comparable performance with existing embedding systems on common benchmarks, while allowing for scaling to arbitrarily large graphs and parallelization on multiple machines. We train and evaluate embeddings on several large social network graphs as well as the full Freebase dataset, which contains over 100 million nodes and 2 billion edges.
StarSpace: Embed All The Things!
Nov 21, 2017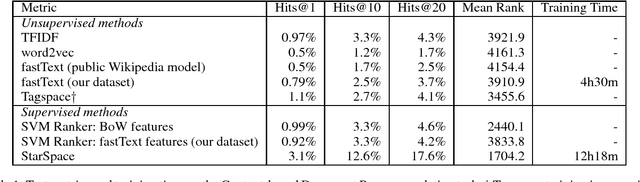
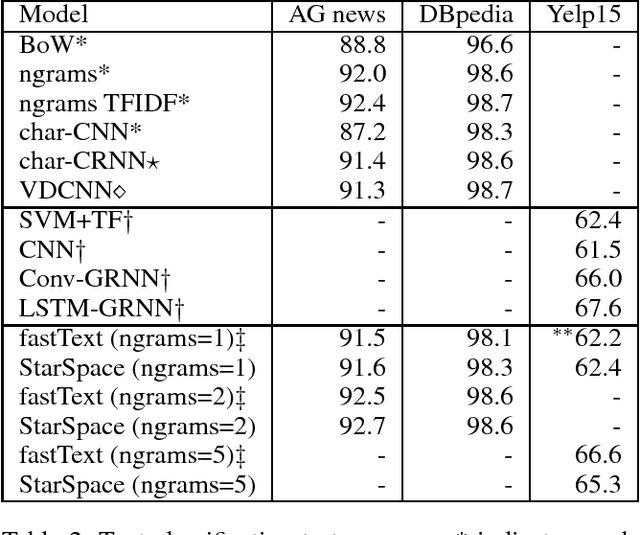

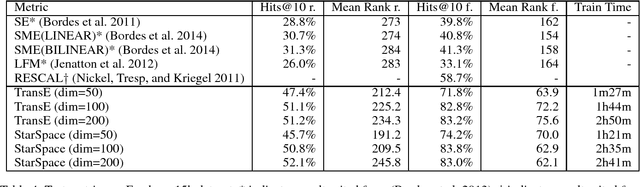
We present StarSpace, a general-purpose neural embedding model that can solve a wide variety of problems: labeling tasks such as text classification, ranking tasks such as information retrieval/web search, collaborative filtering-based or content-based recommendation, embedding of multi-relational graphs, and learning word, sentence or document level embeddings. In each case the model works by embedding those entities comprised of discrete features and comparing them against each other -- learning similarities dependent on the task. Empirical results on a number of tasks show that StarSpace is highly competitive with existing methods, whilst also being generally applicable to new cases where those methods are not.