 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification and Reconstruction of High-Dimensional Signals from Low-Dimensional Features in the Presence of Side Information
Mar 17, 2016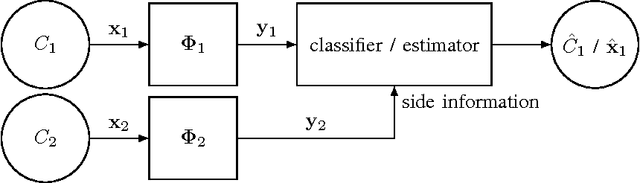


This paper offers a characterization of fundamental limits on the classification and reconstruction of high-dimensional signals from low-dimensional features, in the presence of side information. We consider a scenario where a decoder has access both to linear features of the signal of interest and to linear features of the side information signal; while the side information may be in a compressed form, the objective is recovery or classification of the primary signal, not the side information. The signal of interest and the side information are each assumed to have (distinct) latent discrete labels; conditioned on these two labels, the signal of interest and side information are drawn from a multivariate Gaussian distribution. With joint probabilities on the latent labels, the overall signal-(side information) representation is defined by a Gaussian mixture model. We then provide sharp sufficient and/or necessary conditions for these quantities to approach zero when the covariance matrices of the Gaussians are nearly low-rank. These conditions, which are reminiscent of the well-known Slepian-Wolf and Wyner-Ziv conditions, are a function of the number of linear features extracted from the signal of interest, the number of linear features extracted from the side information signal, and the geometry of these signals and their interplay. Moreover, on assuming that the signal of interest and the side information obey such an approximately low-rank model, we derive expansions of the reconstruction error as a function of the deviation from an exactly low-rank model; such expansions also allow identification of operational regimes where the impact of side information on signal reconstruction is most relevant. Our framework, which offers a principled mechanism to integrate side information in high-dimensional data problems, is also tested in the context of imaging applications.
Spectrally Grouped Total Variation Reconstruction for Scatter Imaging Using ADMM
Jan 29, 2016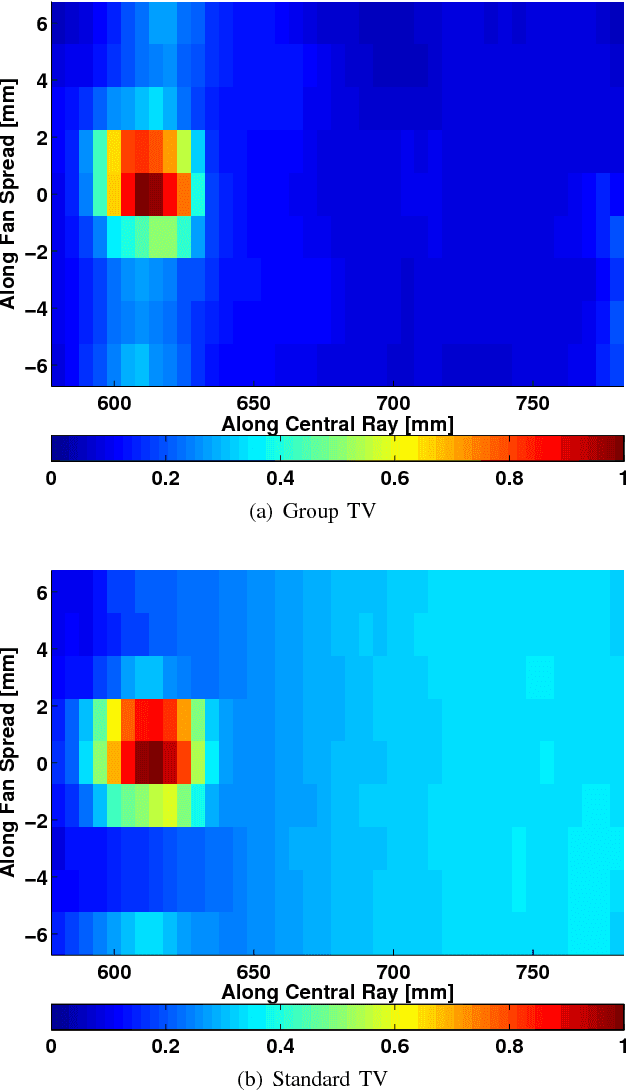
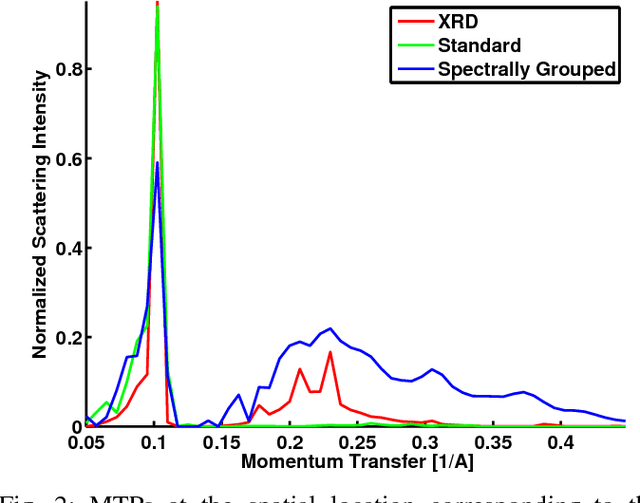
We consider X-ray coherent scatter imaging, where the goal is to reconstruct momentum transfer profiles (spectral distributions) at each spatial location from multiplexed measurements of scatter. Each material is characterized by a unique momentum transfer profile (MTP) which can be used to discriminate between different materials. We propose an iterative image reconstruction algorithm based on a Poisson noise model that can account for photon-limited measurements as well as various second order statistics of the data. To improve image quality, previous approaches use edge-preserving regularizers to promote piecewise constancy of the image in the spatial domain while treating each spectral bin separately. Instead, we propose spectrally grouped regularization that promotes piecewise constant images along the spatial directions but also ensures that the MTPs of neighboring spatial bins are similar, if they contain the same material. We demonstrate that this group regularization results in improvement of both spectral and spatial image quality. We pursue an optimization transfer approach where convex decompositions are used to lift the problem such that all hyper-voxels can be updated in parallel and in closed-form. The group penalty introduces a challenge since it is not directly amendable to these decompositions. We use the alternating directions method of multipliers (ADMM) to replace the original problem with an equivalent sequence of sub-problems that are amendable to convex decompositions, leading to a highly parallel algorithm. We demonstrate the performance on real data.
Joint System and Algorithm Design for Computationally Efficient Fan Beam Coded Aperture X-ray Coherent Scatter Imaging
Jan 29, 2016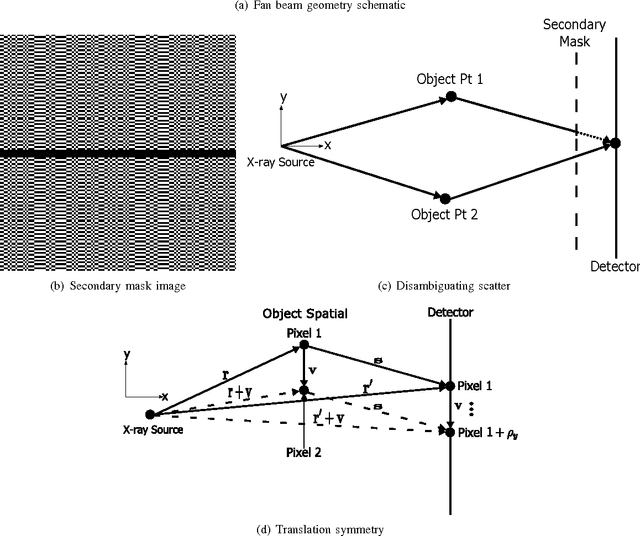
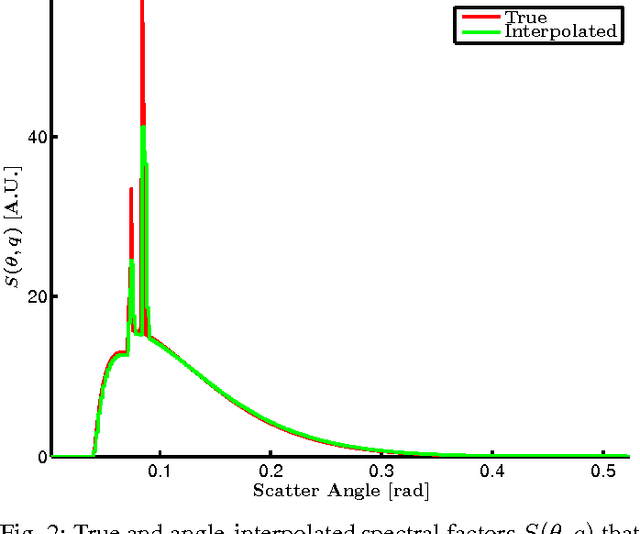
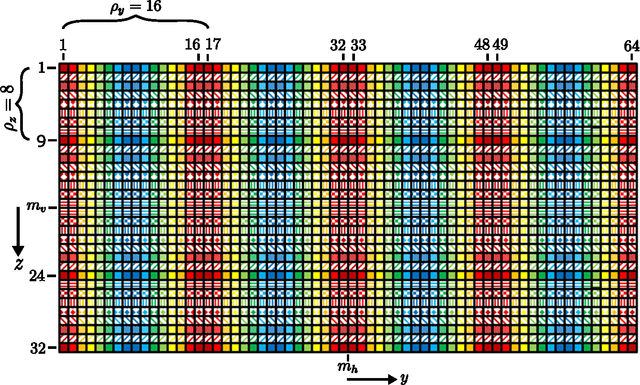
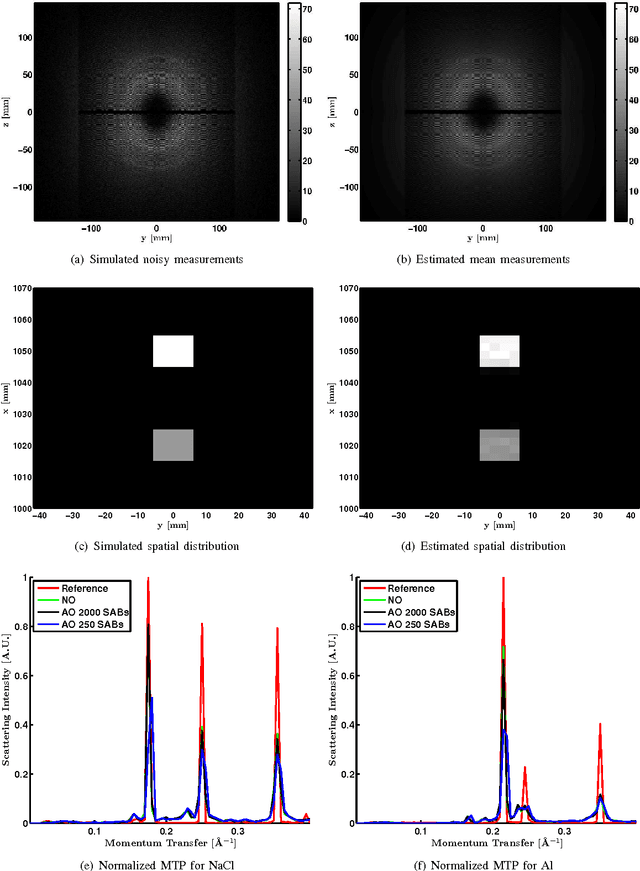
In x-ray coherent scatter tomography, tomographic measurements of the forward scatter distribution are used to infer scatter densities within a volume. A radiopaque 2D pattern placed between the object and the detector array enables the disambiguation between different scatter events. The use of a fan beam source illumination to speed up data acquisition relative to a pencil beam presents computational challenges. To facilitate the use of iterative algorithms based on a penalized Poisson log-likelihood function, efficient computational implementation of the forward and backward models are needed. Our proposed implementation exploits physical symmetries and structural properties of the system and suggests a joint system-algorithm design, where the system design choices are influenced by computational considerations, and in turn lead to reduced reconstruction time. Computational-time speedups of approximately 146 and 32 are achieved in the computation of the forward and backward models, respectively. Results validating the forward model and reconstruction algorithm are presented on simulated analytic and Monte Carlo data.
Preconditioned Stochastic Gradient Langevin Dynamics for Deep Neural Networks
Dec 23, 2015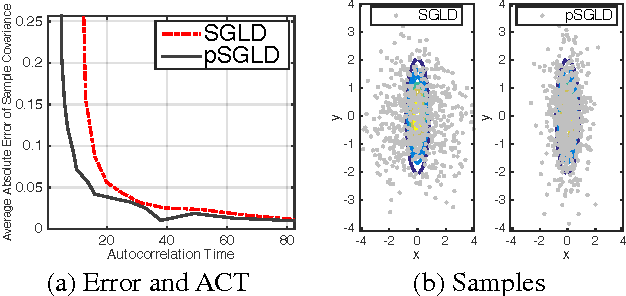
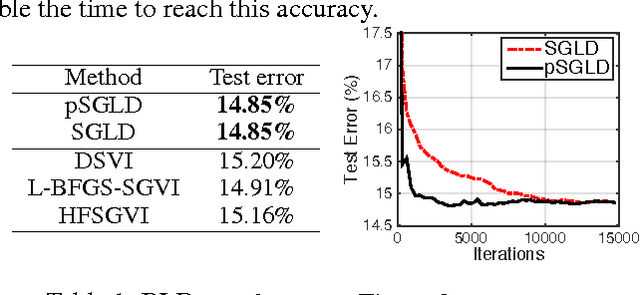
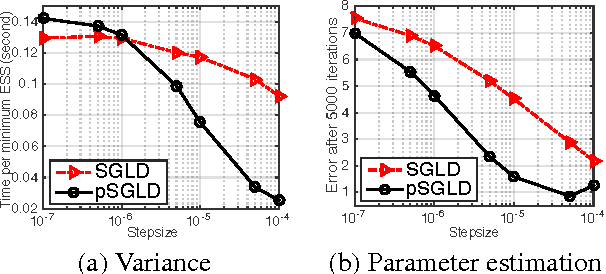
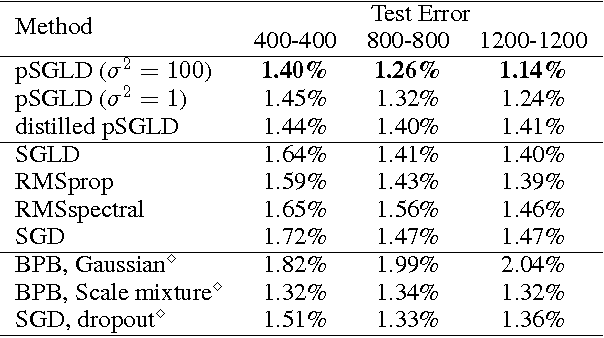
Effective training of deep neural networks suffers from two main issues. The first is that the parameter spaces of these models exhibit pathological curvature. Recent methods address this problem by using adaptive preconditioning for Stochastic Gradient Descent (SGD). These methods improve convergence by adapting to the local geometry of parameter space. A second issue is overfitting, which is typically addressed by early stopping. However, recent work has demonstrated that Bayesian model averaging mitigates this problem. The posterior can be sampled by using Stochastic Gradient Langevin Dynamics (SGLD). However, the rapidly changing curvature renders default SGLD methods inefficient. Here, we propose combining adaptive preconditioners with SGLD. In support of this idea, we give theoretical properties on asymptotic convergence and predictive risk. We also provide empirical results for Logistic Regression, Feedforward Neural Nets, and Convolutional Neural Nets, demonstrating that our preconditioned SGLD method gives state-of-the-art performance on these models.
High-Order Stochastic Gradient Thermostats for Bayesian Learning of Deep Models
Dec 23, 2015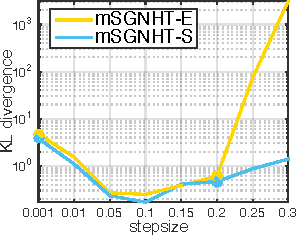
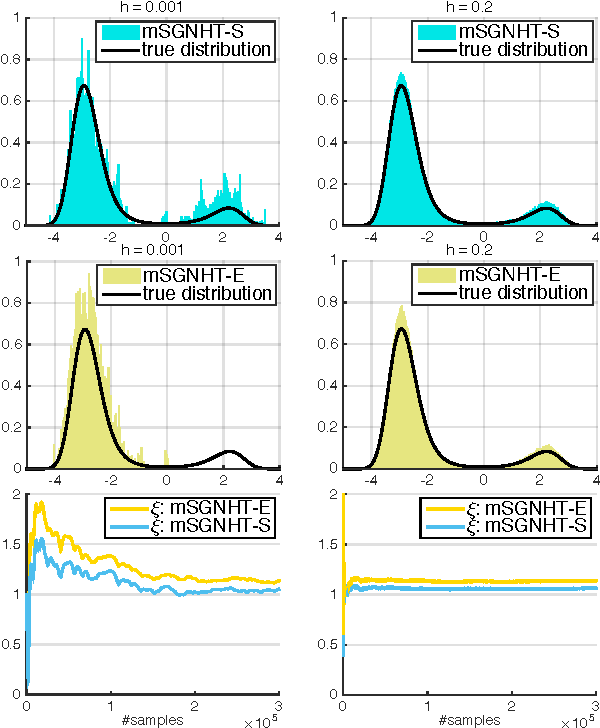
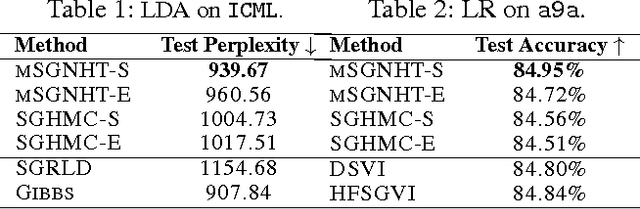
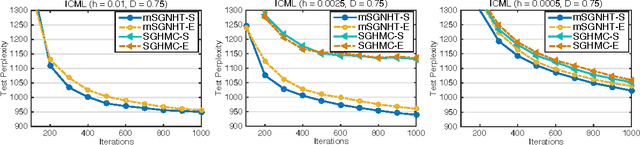
Learning in deep models using Bayesian methods has generated significant attention recently. This is largely because of the feasibility of modern Bayesian methods to yield scalable learning and inference, while maintaining a measure of uncertainty in the model parameters. Stochastic gradient MCMC algorithms (SG-MCMC) are a family of diffusion-based sampling methods for large-scale Bayesian learning. In SG-MCMC, multivariate stochastic gradient thermostats (mSGNHT) augment each parameter of interest, with a momentum and a thermostat variable to maintain stationary distributions as target posterior distributions. As the number of variables in a continuous-time diffusion increases, its numerical approximation error becomes a practical bottleneck, so better use of a numerical integrator is desirable. To this end, we propose use of an efficient symmetric splitting integrator in mSGNHT, instead of the traditional Euler integrator. We demonstrate that the proposed scheme is more accurate, robust, and converges faster. These properties are demonstrated to be desirable in Bayesian deep learning. Extensive experiments on two canonical models and their deep extensions demonstrate that the proposed scheme improves general Bayesian posterior sampling, particularly for deep models.
A Deep Generative Deconvolutional Image Model
Dec 23, 2015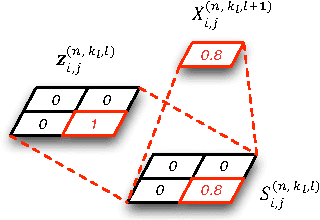
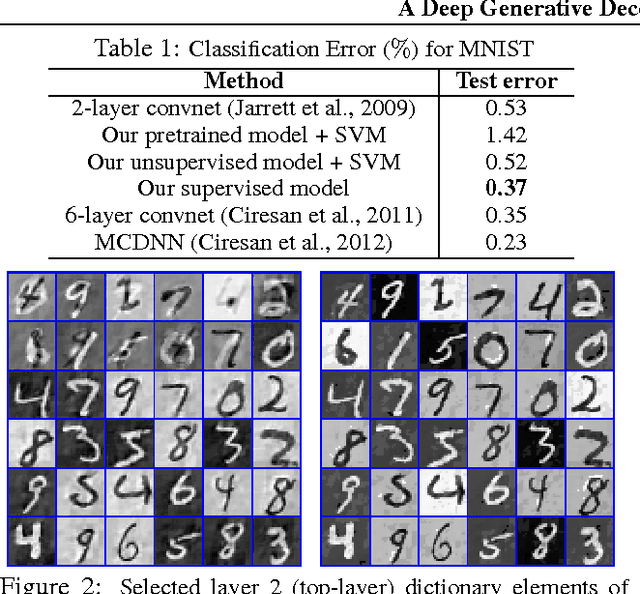
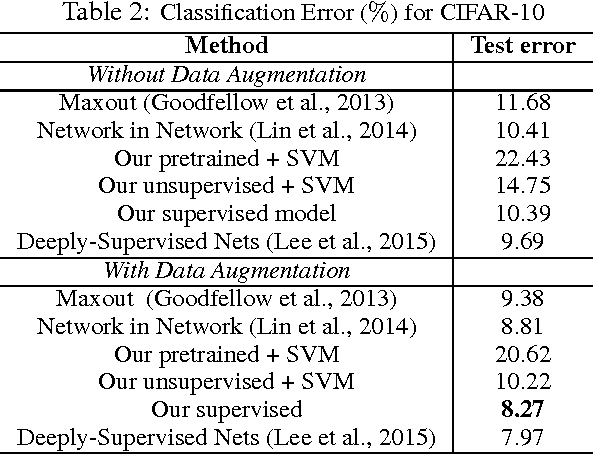

A deep generative model is developed for representation and analysis of images, based on a hierarchical convolutional dictionary-learning framework. Stochastic {\em unpooling} is employed to link consecutive layers in the model, yielding top-down image generation. A Bayesian support vector machine is linked to the top-layer features, yielding max-margin discrimination. Deep deconvolutional inference is employed when testing, to infer the latent features, and the top-layer features are connected with the max-margin classifier for discrimination tasks. The model is efficiently trained using a Monte Carlo expectation-maximization (MCEM) algorithm, with implementation on graphical processor units (GPUs) for efficient large-scale learning, and fast testing. Excellent results are obtained on several benchmark datasets, including ImageNet, demonstrating that the proposed model achieves results that are highly competitive with similarly sized convolutional neural networks.
Learning a Hybrid Architecture for Sequence Regression and Annotation
Dec 16, 2015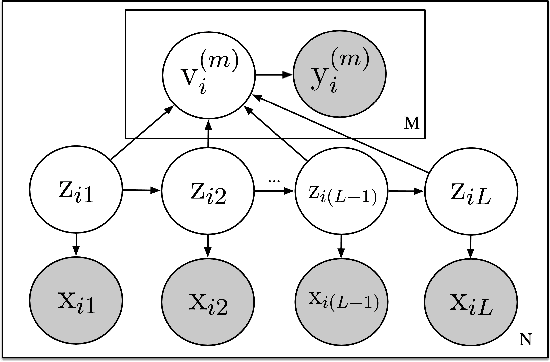


When learning a hidden Markov model (HMM), sequen- tial observations can often be complemented by real-valued summary response variables generated from the path of hid- den states. Such settings arise in numerous domains, includ- ing many applications in biology, like motif discovery and genome annotation. In this paper, we present a flexible frame- work for jointly modeling both latent sequence features and the functional mapping that relates the summary response variables to the hidden state sequence. The algorithm is com- patible with a rich set of mapping functions. Results show that the availability of additional continuous response vari- ables can simultaneously improve the annotation of the se- quential observations and yield good prediction performance in both synthetic data and real-world datasets.
Stick-Breaking Policy Learning in Dec-POMDPs
Nov 23, 2015
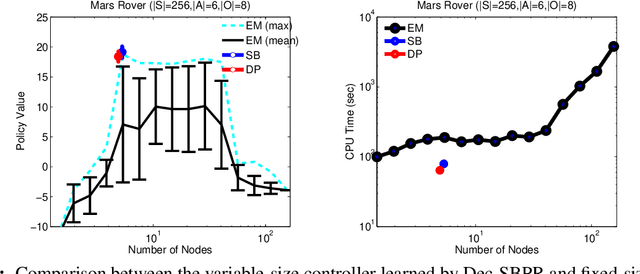

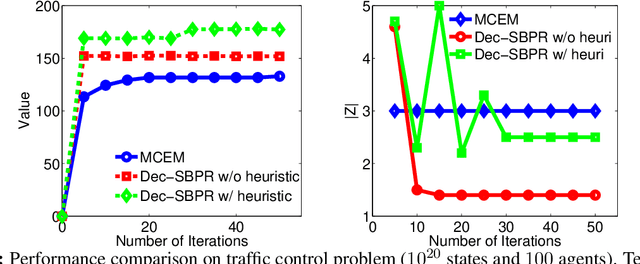
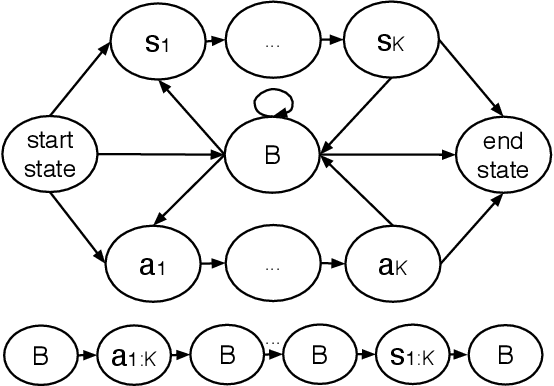
Expectation maximization (EM) has recently been shown to be an efficient algorithm for learning finite-state controllers (FSCs) in large decentralized POMDPs (Dec-POMDPs). However, current methods use fixed-size FSCs and often converge to maxima that are far from optimal. This paper considers a variable-size FSC to represent the local policy of each agent. These variable-size FSCs are constructed using a stick-breaking prior, leading to a new framework called \emph{decentralized stick-breaking policy representation} (Dec-SBPR). This approach learns the controller parameters with a variational Bayesian algorithm without having to assume that the Dec-POMDP model is available. The performance of Dec-SBPR is demonstrated on several benchmark problems, showing that the algorithm scales to large problems while outperforming other state-of-the-art methods.
Deep Temporal Sigmoid Belief Networks for Sequence Modeling
Sep 23, 2015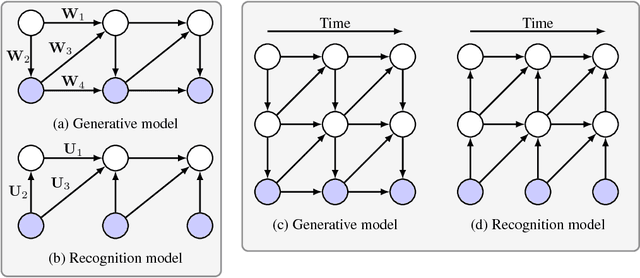

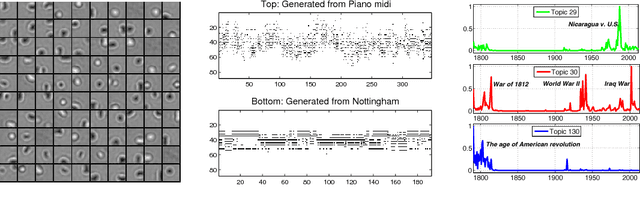
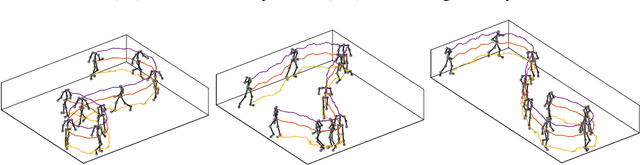
Deep dynamic generative models are developed to learn sequential dependencies in time-series data. The multi-layered model is designed by constructing a hierarchy of temporal sigmoid belief networks (TSBNs), defined as a sequential stack of sigmoid belief networks (SBNs). Each SBN has a contextual hidden state, inherited from the previous SBNs in the sequence, and is used to regulate its hidden bias. Scalable learning and inference algorithms are derived by introducing a recognition model that yields fast sampling from the variational posterior. This recognition model is trained jointly with the generative model, by maximizing its variational lower bound on the log-likelihood. Experimental results on bouncing balls, polyphonic music, motion capture, and text streams show that the proposed approach achieves state-of-the-art predictive performance, and has the capacity to synthesize various sequences.
Scalable Bayesian Non-Negative Tensor Factorization for Massive Count Data
Aug 18, 2015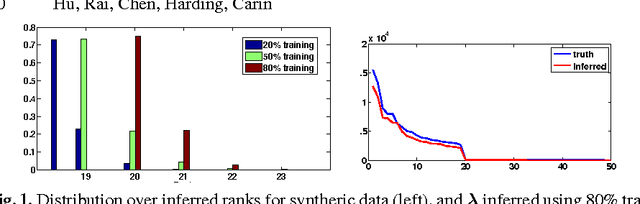
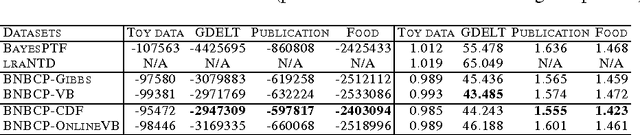

We present a Bayesian non-negative tensor factorization model for count-valued tensor data, and develop scalable inference algorithms (both batch and online) for dealing with massive tensors. Our generative model can handle overdispersed counts as well as infer the rank of the decomposition. Moreover, leveraging a reparameterization of the Poisson distribution as a multinomial facilitates conjugacy in the model and enables simple and efficient Gibbs sampling and variational Bayes (VB) inference updates, with a computational cost that only depends on the number of nonzeros in the tensor. The model also provides a nice interpretability for the factors; in our model, each factor corresponds to a "topic". We develop a set of online inference algorithms that allow further scaling up the model to massive tensors, for which batch inference methods may be infeasible. We apply our framework on diverse real-world applications, such as \emph{multiway} topic modeling on a scientific publications database, analyzing a political science data set, and analyzing a massive household transactions data set.